Extracting objects and facts from texts in Yandex. Lecture for the Small ShAD
The report describes how we extract entities (for example, names of people and place names) from texts and queries. And also about extracting facts, i.e. connections between objects. We will consider several approaches to solving these problems: the formulation of rules, the compilation of dictionaries of various objects, machine learning.
The lecture is designed for high school students - students of the Small ShAD, but adults can use it to fill in some of the gaps.
http://video.yandex.ru/users/e1coyot/view/4/
Extracting objects and facts from texts is part of NLP (Natural Language Processing). The ultimate goal - to teach the machine to fully understand the usual human text. And we have just begun the movement towards this goal.
Today NLP is successfully used for several purposes:
')
Extracting structured information from unstructured text is called text mining. The main part of this process is devoted to the definition of objects, their relationships and properties in tests. Text Mining can be divided into several major tasks:
So, for a start we will mark the named entities in the text. In the example, the names of companies are highlighted in red and the names of people in green. This selection corresponds to the desired behavior of the algorithm. After that, you can proceed to the resolution of coreference.

Coreference is an attempt to link several different references in the text to one real object.

One example of coreference is anaphora - reference to an object using special pointers. In our case, these are pronouns.
The second example of coreference is synonymy. It can be expressed in different ways:
Coreference must be taken into account when analyzing the text in order to avoid extracting unnecessary facts and entities that are not tied to real objects.
Facts can be presented as rows in a table, in the columns of which there are objects and relations between them. The result of the fact extraction process looks something like this:

We usually use IE to extract the following types of objects: dates, addresses, phone numbers, full names, names of goods, companies, etc. Useful facts are most often events, opinions and reviews, contact details and announcements.
So, at the entrance we have a text in natural language. It is necessary to analyze it immediately on all linguistic levels:
The text is divided into paragraphs, sentences, words. Then the words are normalized - their initial form is highlighted. Next, a full or partial syntactic analysis is carried out, the dependencies and connections between words in sentences are determined.
At first glance, it seems that breaking the text into sentences is not difficult. You just need to focus on the punctuation marks that mark the end of the sentence. But this method does not always work. After all, for example, a dot may indicate abbreviations, used in fractional numbers or URLs. Any punctuation mark can be used in company or service names. For example, Yahoo! Or Yandex.Market.
With the selection of the initial form is also not so simple. Of course, in most cases it can be obtained with the help of a morphological dictionary. But this is not always applicable. For example, how to define the dictionary form of the word "glass"? This can be either a noun or a verb. And before turning to the morphological dictionary, you need to remove homonyms. This is solved with the help of the corpus of a language in which all words are marked in parts of speech, and homonymy is removed. Thus, based on the context and statistics of the use of the word in the body, it is possible to decide which part of speech a particular word belongs to.
The next stage is full or partial syntactic parsing. Builds a graph of dependencies and relationships between words within a sentence. Here is an example of a syntax tree that can be built with a parser :
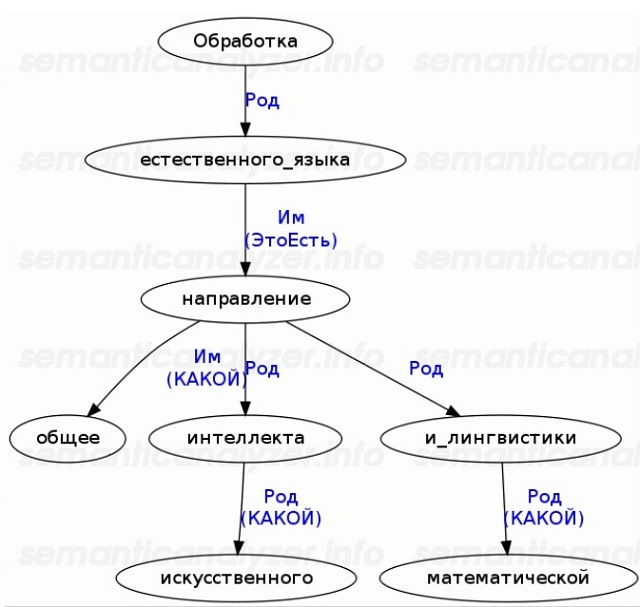
Algorithms that under any conditions can build a complete syntax graph without errors do not exist. However, for most applications, Text Mining suffices a partial analysis.
In addition to the morphological homonymy, about which we spoke above, there is also syntactic and “object” homonymy. As an example of syntactic homonymy, let us give an example: "He saw their family with his own eyes." Both ways of reading will be syntactically correct: someone saw someone with their own eyes, or someone seven-eyed saw someone. To solve such a problem, it is necessary to involve already semantic analysis.
“Object” homonymy suggests that two different real objects may have the same name. For example, in Russia there are just two famous people by the name of Mikhail Zadornov: a humorist and a former finance minister. If you do not teach the system to distinguish between these people, when trying to extract facts about them, various incidents can occur.
When all these steps are completed, you can proceed directly to the extraction of facts. With the help of special algorithms, we want to get a text from an unstructured passage, in which all the objects and facts we need will be marked and categorized. You can visualize this as follows:

Conventionally, there are three main approaches used in the extraction of facts:
In our case, ontologies are “conceptual dictionaries”, which are structures in which certain concepts and / or objects are described, the relations between them, as well as their characteristics.
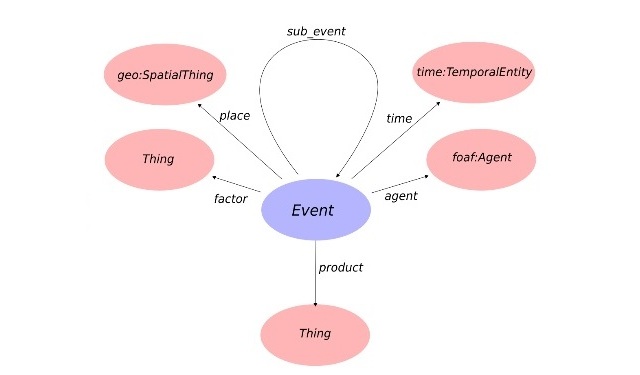
Ontologies can be universal (they attempt to describe the widest possible set of objects), industry-specific (with information on subject areas), and highly specialized (designed to solve a particular problem). Object ontologies (knowledge bases) can also be used. The most vivid example of a knowledge base is Wikipedia.
So, we have some ontology. Based on contexts and already existing lists of objects, it is possible to build hypotheses in relation to objects and facts in the text, and further to verify or reject these hypotheses. On the left is the text in which objects are marked in color, about which I would like to extract some information. Wikipedia is applicable as an ontology. By sending there inquiries for all the keywords from our text, we will get a list of articles located on the right. Red in it marked articles related to several objects.

Now our goal is to cut off the wrong hypotheses. This can be done in different ways. The most commonly used machine learning, various contextual and syntactic factors.
Extraction of information using ontologies allows to obtain a sufficiently high accuracy of NER and the absence of random responses. The removal of homonymy also occurs with high accuracy. The disadvantages of this approach are low completeness, because you can only extract what is already in ontology. And in the ontology, you need to either add objects by hand, or build a procedure for automatic addition.
Another approach - machine learning - requires a large amount of input data. It is necessary to cover as much as possible with the linguistic information the training selection of texts: mark up all the morphology, syntax, semantics, ontological links. The advantages of this approach are that it does not require manual labor other than creating a marked body. No need to make rules or ontologies. If necessary, such a system is easily reconfigured and retrained. The rules are more abstract. However, there are downsides. Tools for the automatic marking of Russian texts are not yet very developed, and the existing ones are not always easily accessible. Shells should be large enough, laid out correctly, consistently and completely. And this is quite a laborious process. In addition, if something went wrong, it is difficult to track exactly where the error occurred, and fix it pointwise.
The third approach is a rule-based approach, i.e. writing templates by hand. The analyst makes descriptions of the types of information that must be extracted. The approach is convenient because if the analysis results reveal errors, it is very easy to find their reason and make the necessary changes to the rules. The easiest way is to create rules for relatively standardized objects: names, dates, company names, etc.
The choice of the optimal approach is determined by a specific task. Now ontologies and machine learning are most commonly used, however, the future is in hybrid systems.
In Yandex, NER is used to extract facts in the mail, names of geographical features and names from requests, facts in vacancies, and also for clustering and classifying news.
The lecture is designed for high school students - students of the Small ShAD, but adults can use it to fill in some of the gaps.
http://video.yandex.ru/users/e1coyot/view/4/
Extracting objects and facts from texts is part of NLP (Natural Language Processing). The ultimate goal - to teach the machine to fully understand the usual human text. And we have just begun the movement towards this goal.
Today NLP is successfully used for several purposes:
')
- Text search
- Fetching facts
- Interactive Systems and Question Answering
- Synthesis and speech recognition
- Rating tonality reviews
- Clustering and classification of texts.
Extracting structured information from unstructured text is called text mining. The main part of this process is devoted to the definition of objects, their relationships and properties in tests. Text Mining can be divided into several major tasks:
- Named Entity Recognition (NER) - extraction of named entities / objects;
- Co-reference resolution - coreference resolution;
- Information Extraction (IE) - extract facts.
So, for a start we will mark the named entities in the text. In the example, the names of companies are highlighted in red and the names of people in green. This selection corresponds to the desired behavior of the algorithm. After that, you can proceed to the resolution of coreference.
Coreference is an attempt to link several different references in the text to one real object.
One example of coreference is anaphora - reference to an object using special pointers. In our case, these are pronouns.
The second example of coreference is synonymy. It can be expressed in different ways:
- Transliteration: Yandex - Yandex.
- Abbreviation: VTB - Vneshtorgbank - Bank for Foreign Trade.
- Synonyms: hospital - hospital.
- Word Formation: Moscow - Moscow.
- Graphic: auto loan - auto loan.
Coreference must be taken into account when analyzing the text in order to avoid extracting unnecessary facts and entities that are not tied to real objects.
Facts can be presented as rows in a table, in the columns of which there are objects and relations between them. The result of the fact extraction process looks something like this:
We usually use IE to extract the following types of objects: dates, addresses, phone numbers, full names, names of goods, companies, etc. Useful facts are most often events, opinions and reviews, contact details and announcements.
Primary text processing
So, at the entrance we have a text in natural language. It is necessary to analyze it immediately on all linguistic levels:
- gramathematic.
- lexical
- morphological
- syntactic
- semantic
The text is divided into paragraphs, sentences, words. Then the words are normalized - their initial form is highlighted. Next, a full or partial syntactic analysis is carried out, the dependencies and connections between words in sentences are determined.
At first glance, it seems that breaking the text into sentences is not difficult. You just need to focus on the punctuation marks that mark the end of the sentence. But this method does not always work. After all, for example, a dot may indicate abbreviations, used in fractional numbers or URLs. Any punctuation mark can be used in company or service names. For example, Yahoo! Or Yandex.Market.
With the selection of the initial form is also not so simple. Of course, in most cases it can be obtained with the help of a morphological dictionary. But this is not always applicable. For example, how to define the dictionary form of the word "glass"? This can be either a noun or a verb. And before turning to the morphological dictionary, you need to remove homonyms. This is solved with the help of the corpus of a language in which all words are marked in parts of speech, and homonymy is removed. Thus, based on the context and statistics of the use of the word in the body, it is possible to decide which part of speech a particular word belongs to.
The next stage is full or partial syntactic parsing. Builds a graph of dependencies and relationships between words within a sentence. Here is an example of a syntax tree that can be built with a parser :
Algorithms that under any conditions can build a complete syntax graph without errors do not exist. However, for most applications, Text Mining suffices a partial analysis.
In addition to the morphological homonymy, about which we spoke above, there is also syntactic and “object” homonymy. As an example of syntactic homonymy, let us give an example: "He saw their family with his own eyes." Both ways of reading will be syntactically correct: someone saw someone with their own eyes, or someone seven-eyed saw someone. To solve such a problem, it is necessary to involve already semantic analysis.
“Object” homonymy suggests that two different real objects may have the same name. For example, in Russia there are just two famous people by the name of Mikhail Zadornov: a humorist and a former finance minister. If you do not teach the system to distinguish between these people, when trying to extract facts about them, various incidents can occur.
Fetching facts
When all these steps are completed, you can proceed directly to the extraction of facts. With the help of special algorithms, we want to get a text from an unstructured passage, in which all the objects and facts we need will be marked and categorized. You can visualize this as follows:
Conventionally, there are three main approaches used in the extraction of facts:
- ontologies;
- based on rules (Rule-based);
- relying on machine learning (ML).
In our case, ontologies are “conceptual dictionaries”, which are structures in which certain concepts and / or objects are described, the relations between them, as well as their characteristics.
Ontologies can be universal (they attempt to describe the widest possible set of objects), industry-specific (with information on subject areas), and highly specialized (designed to solve a particular problem). Object ontologies (knowledge bases) can also be used. The most vivid example of a knowledge base is Wikipedia.
So, we have some ontology. Based on contexts and already existing lists of objects, it is possible to build hypotheses in relation to objects and facts in the text, and further to verify or reject these hypotheses. On the left is the text in which objects are marked in color, about which I would like to extract some information. Wikipedia is applicable as an ontology. By sending there inquiries for all the keywords from our text, we will get a list of articles located on the right. Red in it marked articles related to several objects.
Now our goal is to cut off the wrong hypotheses. This can be done in different ways. The most commonly used machine learning, various contextual and syntactic factors.
Extraction of information using ontologies allows to obtain a sufficiently high accuracy of NER and the absence of random responses. The removal of homonymy also occurs with high accuracy. The disadvantages of this approach are low completeness, because you can only extract what is already in ontology. And in the ontology, you need to either add objects by hand, or build a procedure for automatic addition.
Another approach - machine learning - requires a large amount of input data. It is necessary to cover as much as possible with the linguistic information the training selection of texts: mark up all the morphology, syntax, semantics, ontological links. The advantages of this approach are that it does not require manual labor other than creating a marked body. No need to make rules or ontologies. If necessary, such a system is easily reconfigured and retrained. The rules are more abstract. However, there are downsides. Tools for the automatic marking of Russian texts are not yet very developed, and the existing ones are not always easily accessible. Shells should be large enough, laid out correctly, consistently and completely. And this is quite a laborious process. In addition, if something went wrong, it is difficult to track exactly where the error occurred, and fix it pointwise.
The third approach is a rule-based approach, i.e. writing templates by hand. The analyst makes descriptions of the types of information that must be extracted. The approach is convenient because if the analysis results reveal errors, it is very easy to find their reason and make the necessary changes to the rules. The easiest way is to create rules for relatively standardized objects: names, dates, company names, etc.
The choice of the optimal approach is determined by a specific task. Now ontologies and machine learning are most commonly used, however, the future is in hybrid systems.
In Yandex, NER is used to extract facts in the mail, names of geographical features and names from requests, facts in vacancies, and also for clustering and classifying news.
Source: https://habr.com/ru/post/205198/
All Articles