How it is done: prefix search
We live in a time when it seems that everything is simple and everything is there. We need to make a scalable project - we use MongoDB, we need a queue - here is RabbitMQ, we need to raise the search functionality - just spit: set Sphinx, Solr, ElasticSearch (underline).
But here, only a grain of truth: - with a certain luck, you can put the right server and everything will move. The catch with the search lies in the fact that users are already quite accustomed to the high bar, which is set by the “big guys,” and the search that comes up out of the box will obviously not be enough. And if you can finish off the queue or the database with the iron before you optimize, then you cannot finish the search with the iron.
There are thick books about full-text search settings, but few of them read. Today I would like to talk on the fingers of what needs to be considered when you do a prefix search with output of results as you type a word or phrase.
')
We will see how with the help of our project http://indexisto.com a search is made on the site http://maximonline.ru and compare it with what is on other sites.
First, a few examples. Take the “Battle for Los Angeles” query and imagine that it will be written incorrectly by the “Los Angeles Battle” . As you can see, the user does not know exactly how to spell the name of the city, and forgot how the name of the movie sounds, and his hand shook at the end of the word “battle”.
Let's select worthy projects of the Runet, in which there is a prefix search, and try to search our query there:
As can be seen from our little research, the situation is far from ideal. Here are the typical problems.
The article will talk about the ElasticSearch server, however, these same approaches can be used when setting up SOLR, since in the end all high-level queries still apply to requests from the lower-level Lucene search library. It also doesn't matter whether you are doing a prefix search with ngram tokens or using prefix queries (rather heavy ones, since they are mapped onto fuzzy queries).
When indexing, the text passes through the tokenizer and a number of filters (morphology, synonyms ...). The original word in the end can be replaced, reduced to normal form or altogether discarded. Through whatever filters you may chase your tokens, keep the original word in the same position as the changed / replaced one. What can happen if you do not keep the original word, shown in the picture:

As you can see, the morphology filter changes the word (leads to normal form). In a normal search, this works well, since the word from the query that the user entered will also be reduced to normal form. But what to do while the user entered only half of the word (prefix search)? We keep the original token in the index!

By the way, we had problems in standard Lucene plugins, and we made our own, which work better with the positions of tokens in the document and preserve the original word. About what problems you may face, you can read, for example, here: Lucene's TokenStreams are actually graphs!
Do not use analyzers that can “clean” a query for you, for example, a filter of stop words that removes interjections and particles. Here is an example:

As you can see, “a” is a stop word, and the query analyzer has deleted it. In practice, this means that there will be a “leap”, that is, a person has typed in “Hounite A” and sees the document at the request of Juanita (without A). If we have a lot of Juanit in the issue, then there is no guarantee that we need to be on top.
In order to overcome this, remove the filter of stop words from the query:

Do not try to do everything at once with one confused giant request. Break the task into subtasks. There are boolean and dismax queries that help you glue together the results of several small queries into one. Use boost in small queries to, for example, increase the weight of the exact match in the title of the page compared to the match in the body of the page. Like this:
So, our search query consists of a handful of small queries with different boost factors. The Boost Factor is a relevance multiplier that applies when base text relevancy is already calculated.
First, we search for an exact match of the phrase in the title of the article (or the title of the page). Exact match means that we do not use the prefix. For example, the query “HOW” will be the first to display the articles “ How to…” , and not the article “We grow as a tus” . Documents found on such a request, get a boost, for example, 10,000.
Next comes the request for prefix matching. Exact matches of the word "AS" we have already found the first query, now is the time to search " like tuses" . These documents will go below exact matches at the expense of a smaller boost.
We also use the slop parameter here, which says that words in a phrase can be spaced apart several positions forward or backward. Many people forget about this parameter, and by default the prefix search only looks forward.
This is the current issue:

The first are exact matches, the second is prefix.
Matches in the title, we found and made them a decent boost. Time to go to the very body of the article. First of all, we are again looking for an exact match, and with a smaller boost factor, prefix matches.
Thus, matches in the headline will be the first to be issued, and matches in the body of the article will be lower. This raises the question: Does this sort of sorting be at the mercy of text relevance? After all, standard algorithms take into account the length of the text in which a match is found: the shorter the text, the higher the relevance. However, practice has shown that with a prefix search in the body of the article there will be a lot of coincidences. Imagine you typed 1-2 letters, and in the body of the article there will be already 200-300 matches, and, despite the length of the text, they will kill the relevance of matches in the title.
The last (due to boost) is a fuzzy search. Fuzzy search forgives some typos in a search query entered by the user. Inside the request, the Levenshtein distance is used . Fuzzy query has several settings that act as parameters to the algorithm, and it is also possible to specify the minimum necessary prefix match.
Matches found in fuzzy search go to the very bottom due to the minimum boost factor.
In the picture you can see how our results lined up depending on the coincidences:

We collect all the statistics of search queries, clicks on the results of the issue, searches without conversions, searches with a blank result.
Interestingly, on maximonline.ru, the search is a fairly demanded functionality, and 90% of search queries are the names of girls. Here you can get very interesting data :)
So, the most sought-after Maxim girls in the reverse order! Data for November 2013.
5. Anna Semenovich (presenter)

4. Vera Brezhneva (singer)

3. Anna Khilkevich (actress)

2. Maria Gorban (actress)

1. Ekaterina Volkova (actress)

But here, only a grain of truth: - with a certain luck, you can put the right server and everything will move. The catch with the search lies in the fact that users are already quite accustomed to the high bar, which is set by the “big guys,” and the search that comes up out of the box will obviously not be enough. And if you can finish off the queue or the database with the iron before you optimize, then you cannot finish the search with the iron.
There are thick books about full-text search settings, but few of them read. Today I would like to talk on the fingers of what needs to be considered when you do a prefix search with output of results as you type a word or phrase.
')
We will see how with the help of our project http://indexisto.com a search is made on the site http://maximonline.ru and compare it with what is on other sites.
First, a few examples. Take the “Battle for Los Angeles” query and imagine that it will be written incorrectly by the “Los Angeles Battle” . As you can see, the user does not know exactly how to spell the name of the city, and forgot how the name of the movie sounds, and his hand shook at the end of the word “battle”.
Let's select worthy projects of the Runet, in which there is a prefix search, and try to search our query there:
| Project | Correct request | Invalid request |
|---|---|---|
| afisha.ru | 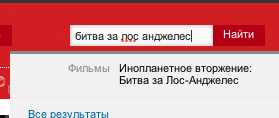 all OK |  Not found |
| ivi.ru | 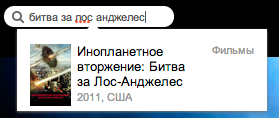 all OK | 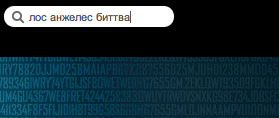 Not found |
| vk.com |  all OK | 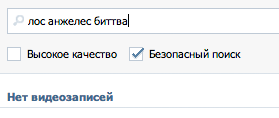 Not found |
| maximonline.ru | 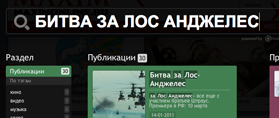 all OK | 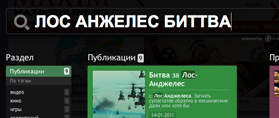 all OK |
As can be seen from our little research, the situation is far from ideal. Here are the typical problems.
- Word permutation does not work
- There are "jumps". That is, as the movie is being searched for, it appears in the results, then disappears.
- No fuzzy search
- Not everyone has a morphology
Let's go set up
The article will talk about the ElasticSearch server, however, these same approaches can be used when setting up SOLR, since in the end all high-level queries still apply to requests from the lower-level Lucene search library. It also doesn't matter whether you are doing a prefix search with ngram tokens or using prefix queries (rather heavy ones, since they are mapped onto fuzzy queries).
Indexing
When indexing, the text passes through the tokenizer and a number of filters (morphology, synonyms ...). The original word in the end can be replaced, reduced to normal form or altogether discarded. Through whatever filters you may chase your tokens, keep the original word in the same position as the changed / replaced one. What can happen if you do not keep the original word, shown in the picture:
As you can see, the morphology filter changes the word (leads to normal form). In a normal search, this works well, since the word from the query that the user entered will also be reduced to normal form. But what to do while the user entered only half of the word (prefix search)? We keep the original token in the index!
By the way, we had problems in standard Lucene plugins, and we made our own, which work better with the positions of tokens in the document and preserve the original word. About what problems you may face, you can read, for example, here: Lucene's TokenStreams are actually graphs!
Query analyzers
Do not use analyzers that can “clean” a query for you, for example, a filter of stop words that removes interjections and particles. Here is an example:
As you can see, “a” is a stop word, and the query analyzer has deleted it. In practice, this means that there will be a “leap”, that is, a person has typed in “Hounite A” and sees the document at the request of Juanita (without A). If we have a lot of Juanit in the issue, then there is no guarantee that we need to be on top.
In order to overcome this, remove the filter of stop words from the query:
Request
Do not try to do everything at once with one confused giant request. Break the task into subtasks. There are boolean and dismax queries that help you glue together the results of several small queries into one. Use boost in small queries to, for example, increase the weight of the exact match in the title of the page compared to the match in the body of the page. Like this:
{ "query":{ "bool" : { "should" : [ { "custom_boost_factor": { "query":{ "match":{ .... } }, "boost_factor": 100 } }, { "custom_boost_factor": { "query":{ "match":{ .... } } }, "boost_factor": 10 } }, ..... ] } } } The exact phrase in the title of the article
So, our search query consists of a handful of small queries with different boost factors. The Boost Factor is a relevance multiplier that applies when base text relevancy is already calculated.
First, we search for an exact match of the phrase in the title of the article (or the title of the page). Exact match means that we do not use the prefix. For example, the query “HOW” will be the first to display the articles “ How to…” , and not the article “We grow as a tus” . Documents found on such a request, get a boost, for example, 10,000.
Prefix phrase match in article title
Next comes the request for prefix matching. Exact matches of the word "AS" we have already found the first query, now is the time to search " like tuses" . These documents will go below exact matches at the expense of a smaller boost.
We also use the slop parameter here, which says that words in a phrase can be spaced apart several positions forward or backward. Many people forget about this parameter, and by default the prefix search only looks forward.
This is the current issue:
The first are exact matches, the second is prefix.
Matches in the body of the article - full and prefix
Matches in the title, we found and made them a decent boost. Time to go to the very body of the article. First of all, we are again looking for an exact match, and with a smaller boost factor, prefix matches.
Thus, matches in the headline will be the first to be issued, and matches in the body of the article will be lower. This raises the question: Does this sort of sorting be at the mercy of text relevance? After all, standard algorithms take into account the length of the text in which a match is found: the shorter the text, the higher the relevance. However, practice has shown that with a prefix search in the body of the article there will be a lot of coincidences. Imagine you typed 1-2 letters, and in the body of the article there will be already 200-300 matches, and, despite the length of the text, they will kill the relevance of matches in the title.
Fuzzy matches in the title or body of the article
The last (due to boost) is a fuzzy search. Fuzzy search forgives some typos in a search query entered by the user. Inside the request, the Levenshtein distance is used . Fuzzy query has several settings that act as parameters to the algorithm, and it is also possible to specify the minimum necessary prefix match.
"custom_boost_factor": { "query":{ "multi_match":{ "query":"${q}", "fuzziness":0.005, "prefix_length" : 2, "operator":"and", "max_expansions":999, "fields":[ "article_name", "article_body" ] } }, "boost_factor": 1 } } Matches found in fuzzy search go to the very bottom due to the minimum boost factor.
What is the result
In the picture you can see how our results lined up depending on the coincidences:
- title accurate
- in the prefix header
- in the body of the article are accurate
- in the body of the article by prefix
- in the title and body of the article are fuzzy (with typing errors)
Bonus track for those who mastered the article
We collect all the statistics of search queries, clicks on the results of the issue, searches without conversions, searches with a blank result.
Interestingly, on maximonline.ru, the search is a fairly demanded functionality, and 90% of search queries are the names of girls. Here you can get very interesting data :)
So, the most sought-after Maxim girls in the reverse order! Data for November 2013.
5. Anna Semenovich (presenter)
4. Vera Brezhneva (singer)
3. Anna Khilkevich (actress)
2. Maria Gorban (actress)
1. Ekaterina Volkova (actress)
Source: https://habr.com/ru/post/204654/
All Articles