An example of solving a credit scoring problem using a python + pandas + scikit-learn bundle
Introduction
Good afternoon, dear readers.
Recently, wandering through the expanses of the global web, I stumbled upon a tournament that was held by TCS at the beginning of this year. After reviewing the tasks, I decided to test my skills in analyzing data on them.
I decided to start checking with the scoring problem (Task №3). To solve it, I, as always, used Python with analytical modules pandas and scikit-learn .
Data Description and Problem Statement
The bank requests the applicant's credit history at the three largest Russian credit bureaus. A selection of Bank clients is provided in the SAMPLE_CUSTOMERS.CSV file. The sample is divided into parts “train” and “test”. From the “train” sample, we know the value of the target variable bad - the presence of a “default” (assuming the client has delayed 90 days or more during the first year of using the loan). The SAMPLE_ACCOUNTS.CSV file contains data from the responses of credit bureaus to all inquiries about the relevant clients.
Data format SAMPLE_CUSTOMERS - information about the possibility of default of a certain person.
Description of the format of the dataset SAMPLE_ACCOUNTS :
Kit Description
| Name | Description |
|---|---|
| TCS_CUSTOMER_ID | Customer ID |
| BUREAU_CD | Bureau code from which the invoice is received |
| BKI_REQUEST_DATE | Date on which the request was made to the bureau |
| CURRENCY | Currency of contract (ISO letter code of currency) |
| RELATIONSHIP | Type of relationship to the contract |
| 1 - Individual | |
| 2 - Additional card / Authorized user | |
| 4 - Joint | |
| 5 - Guarantor | |
| 9 - Legal entity | |
| OPEN_DATE | Date of opening of the contract |
| FINAL_PMT_DATE | Date of final payment (scheduled) |
| TYPE | Contract Type Code |
| 1 - Car loan | |
| 4 - Leasing | |
| 6 - Mortgage | |
| 7 - Credit Card | |
| 9 - Consumer credit | |
| 10 - Business Development Credit | |
| 11 - Loan for replenishment of working capital | |
| 12 - Credit for the purchase of equipment | |
| 13 - Real estate construction loan | |
| 14 - Credit for the purchase of shares (for example, margin lending) | |
| 99 - Other | |
| PMT_STRING_84M | Discipline (timeliness) of payments. The string is made up of account status codes at the time the bank sends data on the account to the bureau, the first character is the state as of date PMT_STRING_START, then successively in descending order of dates. |
| 0 - New, evaluation is not possible | |
| X - No information | |
| 1 - Payment without delay | |
| A - Delay from 1 to 29 days | |
| 2 - Delay from 30 to 59 days | |
| 3 - Delay from 60 to 89 days | |
| 4 - Delay from 90 to 119 days | |
| 5 - Delay more than 120 days | |
| 7 - Regular consolidated payments | |
| 8 - Loan repayment using collateral | |
| 9 - Bad debt / transferred for collection / missed payment | |
| STATUS | Contract status |
| 00 - Active | |
| 12 - Paid by collateral | |
| 13 - Account is closed | |
| 14 - Transferred to another bank for service | |
| 21 - Dispute | |
| 52 - Overdue | |
| 61 - Return Problems | |
| OUTSTANDING | Remaining outstanding debt. Amount in rubles at the rate of the Central Bank of the Russian Federation |
| NEXT_PMT | The amount of the next payment. Amount in rubles at the rate of the Central Bank of the Russian Federation |
| INF_CONFIRM_DATE | Date of confirmation of account information |
| FACT_CLOSE_DATE | Account closure date (actual) |
| TTL_DELQ_5 | Number of delinquency up to 5 days |
| TTL_DELQ_5_29 | The number of delinquencies from 5 to 29 days |
| TTL_DELQ_30_59 | The number of delinquencies from 30 to 59 days |
| TTL_DELQ_60_89 | The number of delinquencies from 60 to 89 days |
| TTL_DELQ_30 | Number of delinquency up to 30 days |
| TTL_DELQ_90_PLUS | 90+ days overdue |
| PMT_FREQ | Payment Rate Code |
| 1 - Weekly | |
| 2 - Every other week | |
| 3 - Monthly | |
| A - Once every 2 months | |
| 4 - Quarterly | |
| B - Once every 4 months | |
| 5 - Every six months | |
| 6 - Annually | |
| 7 - Other | |
| CREDIT_LIMIT | Credit limit. Amount in rubles at the rate of the Central Bank of the Russian Federation |
| DELQ_BALANCE | Current arrears. Amount in rubles at the rate of the Central Bank of the Russian Federation |
| MAX_DELQ_BALANCE | The maximum amount of arrears. Amount in rubles at the rate of the Central Bank of the Russian Federation |
| CURRENT_DELQ | The current number of days overdue |
| PMT_STRING_START | Start date of the line PMT_STRING_84M |
| INTEREST_RATE | Loan interest rate |
| CURR_BALANCE_AMT | The total amount paid, including the amount of principal, interest, penalties and fines. Amount in rubles at the rate of the Central Bank of the Russian Federation |
The task is to build a model that determines the probability of "default" on the train sample and put its probabilities on clients from the test sample. To evaluate the model, the Area Under ROC Curve characteristic will be used (also indicated in the problem conditions).
Preliminary data processing
First, download the source files and look at them:
from pandas import read_csv, DataFrame from sklearn.metrics import roc_curve from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier from sklearn.cross_validation import train_test_split from sklearn.naive_bayes import GaussianNB from sklearn.neighbors import KNeighborsClassifier from sklearn.decomposition import PCA import ml_metrics, string, re, pylab as pl SampleCustomers = read_csv("https://static.tcsbank.ru/documents/olymp/SAMPLE_CUSTOMERS.csv", ';') SampleAccounts = read_csv("https://static.tcsbank.ru/documents/olymp/SAMPLE_ACCOUNTS.csv",";",decimal =',') print SampleAccounts 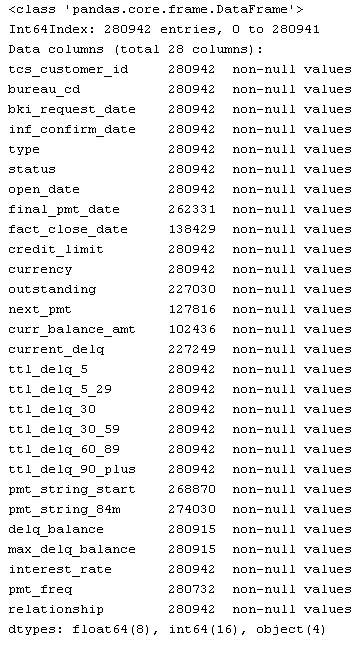
')
SampleCustomers.head() | tcs_customer_id | bad | sample_type | |
|---|---|---|---|
| 0 | one | NaN | test |
| one | 2 | 0 | train |
| 2 | 3 | one | train |
| 3 | four | 0 | train |
| four | five | 0 | train |
From the conditions of the problem, we can assume that the SampleAccounts set contains several records for one borrower, let's check this:
SampleAccounts.tcs_customer_id.drop_duplicates().count(), SampleAccounts.tcs_customer_id.count() Our assumption turned out to be true. Unique borrowers 50000 of 280942 records. This is due to the fact that one borrower has several credits and for each of them there will be different information in different bureaus. Therefore, you need to perform transformations on SampleAccounts to match one line to one borrower.
Now let's get a list of all unique loans for each borrower:
SampleAccounts[['tcs_customer_id','open_date','final_pmt_date','credit_limit','currency']].drop_duplicates() Therefore, when we received a list of credits, we will be able to display any general information on each element of the list. Those. it would be possible to take a bundle of the above fields and make it an index with respect to which we would perform further manipulations, but, unfortunately, there is one unpleasant moment that lies in wait for us. It lies in the fact that the 'final_pmt_date' field in the data set has blank values. Let's try to get rid of them.
We have an actual closing date of the loan in the set, therefore, if it is, and the 'final_pmt_date' field is not filled, then we can write this value into it. For the rest, just write 0.
SampleAccounts.final_pmt_date[SampleAccounts.final_pmt_date.isnull()] = SampleAccounts.fact_close_date[SampleAccounts.final_pmt_date.isnull()].astype(float) SampleAccounts.final_pmt_date.fillna(0, inplace=True) Now that we’ve gotten rid of empty values, let's get the most recent date for contacting any of the bureaus for each of the loans. It is useful for us to determine its attributes, such as contract status, type, etc.
sumtbl = SampleAccounts.pivot_table(['inf_confirm_date'], ['tcs_customer_id','open_date','final_pmt_date','credit_limit','currency'], aggfunc='max') sumtbl.head(15) | inf_confirm_date | |||||
|---|---|---|---|---|---|
| tcs_customer_id | open_date | final_pmt_date | credit_limit | currency | |
| one | 39261 | 39629 | 19421 | RUB | 39924 |
| 39505 | 39870 | 30,000 | RUB | 39862 | |
| 39644 | 40042 | 11858 | RUB | 40043 | |
| 39876 | 41701 | 300,000 | RUB | 40766 | |
| 39942 | 40308 | 19691 | RUB | 40435 | |
| 40421 | 42247 | 169,000 | RUB | 40756 | |
| 40428 | 51386 | 10,000 | RUB | 40758 | |
| 40676 | 41040 | 28967 | RUB | 40764 | |
| 2 | 40472 | 40618 | 7551 | RUB | 40661 |
| 40652 | 40958 | 21186 | RUB | 40661 | |
| 3 | 39647 | 40068 | 22694 | RUB | 40069 |
| 40604 | 0 | 20,000 | RUB | 40624 | |
| four | 38552 | 40378 | 75,000 | RUB | 40479 |
| 39493 | 39797 | 5000 | RUB | 39823 | |
| 39759 | 40123 | 6023 | RUB | 40125 |
Now add the dates we received to the main set:
SampleAccounts = SampleAccounts.merge(sumtbl, 'left', left_on=['tcs_customer_id','open_date','final_pmt_date','credit_limit','currency'], right_index=True, suffixes=('', '_max')) So, then we divide the columns in which the parameters are strictly defined, so that each value from these fields corresponds to a separate column. By condition, the columns with the specified values will be:
- pmt_string_84m
- pmt_freq
- type
- status
- relationship
- bureau_cd
The code for converting them is shown below:
# pmt_string_84m vals = list(xrange(10)) + ['A','X'] PMTstr = DataFrame([{'pmt_string_84m_%s' % (str(j)): str(i).count(str(j)) for j in vals} for i in SampleAccounts.pmt_string_84m]) SampleAccounts = SampleAccounts.join(PMTstr).drop(['pmt_string_84m'], axis=1) # pmt_freq SampleAccounts.pmt_freq.fillna(7, inplace=True) SampleAccounts.pmt_freq[SampleAccounts.pmt_freq == 0] = 7 vals = list(range(1,8)) + ['A','B'] PMTstr = DataFrame([{'pmt_freq_%s' % (str(j)): str(i).count(str(j)) for j in vals} for i in SampleAccounts.pmt_freq]) SampleAccounts = SampleAccounts.join(PMTstr).drop(['pmt_freq'], axis=1) # type vals = [1,4,6,7,9,10,11,12,13,14,99] PMTstr = DataFrame([{'type_%s' % (str(j)): str(i).count(str(j)) for j in vals} for i in SampleAccounts.type]) SampleAccounts = SampleAccounts.join(PMTstr).drop(['type'], axis=1) # status vals = [0,12, 13, 14, 21, 52,61] PMTstr = DataFrame([{'status_%s' % (str(j)): str(i).count(str(j)) for j in vals} for i in SampleAccounts.status]) SampleAccounts = SampleAccounts.join(PMTstr).drop(['status'], axis=1) # relationship vals = [1,2,4,5,9] PMTstr = DataFrame([{'relationship_%s' % (str(j)): str(i).count(str(j)) for j in vals} for i in SampleAccounts.relationship]) SampleAccounts = SampleAccounts.join(PMTstr).drop(['relationship'], axis=1) # bureau_cd vals = [1,2,3] PMTstr = DataFrame([{'bureau_cd_%s' % (str(j)): str(i).count(str(j)) for j in vals} for i in SampleAccounts.bureau_cd]) SampleAccounts = SampleAccounts.join(PMTstr).drop(['bureau_cd'], axis=1) The next step is to transform the 'fact_close_date' field, which contains the date of the last actual payment, so that it contains only 2 values:
- 0 - there was no last payment
- 1 - last payment was
I made this replacement because the field was originally half filled.
SampleAccounts.fact_close_date[SampleAccounts.fact_close_date.notnull()] = 1 SampleAccounts.fact_close_date.fillna(0, inplace=True) Now from our data set we need to pull out the latest data on all loans. The “inf_confirm_date_max” field obtained above will help us in this. In it, we added the deadline for updating loan information in all bureaus:
PreFinalDS = SampleAccounts[SampleAccounts.inf_confirm_date == SampleAccounts.inf_confirm_date_max].drop_duplicates() After the above actions, our sample was significantly reduced, but now we need to summarize all the information on the loan and the borrower obtained earlier. To do this, we group our data set:
PreFinalDS = PreFinalDS.groupby(['tcs_customer_id','open_date','final_pmt_date','credit_limit','currency']).max().reset_index() Our data is almost ready to start the analysis. It remains to perform a few more actions:
- Remove unwanted columns
- Bring all credit limits in rubles
- Calculate how many credits each borrower has from bureau information
Let's start by clearing the table of unnecessary columns:
PreFinalDS = PreFinalDS.drop(['bki_request_date', 'inf_confirm_date', 'pmt_string_start', 'interest_rate', 'open_date', 'final_pmt_date', 'inf_confirm_date_max'], axis=1) Further we will transfer all credit limits to rubles. For simplicity, I took the current exchange rates. Although probably it would be more correct to take a course at the time of opening an account. Another caveat is that for analysis we need to remove the “surrency” text field, so after converting currencies to rubles, we will perform the manipulation with this field, which we did with the fields above:
curs = DataFrame([33.13,44.99,36.49,1], index=['USD','EUR','GHF','RUB'], columns=['crs']) PreFinalDS = PreFinalDS.merge(curs, 'left', left_on='currency', right_index=True) PreFinalDS.credit_limit = PreFinalDS.credit_limit * PreFinalDS.crs # vals = ['RUB','USD','EUR','CHF'] PMTstr = DataFrame([{'currency_%s' % (str(j)): str(i).count(str(j)) for j in vals} for i in PreFinalDS.currency]) PreFinalDS = PreFinalDS.join(PMTstr).drop(['currency','crs'], axis=1) So before the final grouping, add to our set a field filled with units. Those. when we perform the last grouping, the amount on it will give the number of loans from the borrower:
PreFinalDS['count_credit'] = 1 Now that we have all the quantitative data in the data set, we can fill in the gaps in data 0 and perform the final grouping by customer:
PreFinalDS.fillna(0, inplace=True) FinalDF = PreFinalDS.groupby('tcs_customer_id').sum() FinalDF Preliminary analysis
Well, the primary data processing is completed and you can begin to analyze them. To begin with, we divide our data into training and test samples. The column “sample_type” from SampleCustomers will help us with this; this division is made just by it.
In order to break our processed DataFrame, it is enough to combine it with SampleCustomers to play around with filters:
SampleCustomers.set_index('tcs_customer_id', inplace=True) UnionDF = FinalDF.join(SampleCustomers) trainDF = UnionDF[UnionDF.sample_type == 'train'].drop(['sample_type'], axis=1) testDF = UnionDF[UnionDF.sample_type == 'test'].drop(['sample_type'], axis=1) Next, let's see how the signs correlate with each other, for this we construct a matrix with the coefficients correlation coefficients. With pandas, this can be done with one command:
CorrKoef = trainDF.corr() After the action above, CorrKoef will contain a matrix of sizes 61x61.
The rows and columns will be the corresponding field names, and at their intersection the value of the correlation coefficient. For example:
| fact_close_date | |
|---|---|
| status_13 | 0.997362 |
It is possible that there is no correlation coefficient. This means that these fields are most likely filled with only one identical value and can be omitted in the analysis. Check:
FieldDrop = [i for i in CorrKoef if CorrKoef[i].isnull().drop_duplicates().values[0]] At the exit, we received a list of fields that can be deleted:
- pmt_string_84m_6
- pmt_string_84m_8
- pmt_freq_5
- pmt_freq_A
- pmt_freq_B
- status_12
The next step is to find the fields that correlate with each other (whose correlation coefficient is more than 90%) using our matrix:
CorField = [] for i in CorrKoef: for j in CorrKoef.index[CorrKoef[i] > 0.9]: if i <> j and j not in CorField and i not in CorField: CorField.append(j) print "%s-->%s: r^2=%f" % (i,j, CorrKoef[i][CorrKoef.index==j].values[0]) At the output we get the following:
fact_close_date -> status_13: r ^ 2 = 0.997362
ttl_delq_5_29 -> ttl_delq_30: r ^ 2 = 0.954740
ttl_delq_5_29 -> pmt_string_84m_A: r ^ 2 = 0.925870
ttl_delq_30_59 -> pmt_string_84m_2: r ^ 2 = 0.903337
ttl_delq_90_plus -> pmt_string_84m_5: r ^ 2 = 0.978239
delq_balance -> max_delq_balance: r ^ 2 = 0.986967
pmt_freq_3 -> relationship_1: r ^ 2 = 0.909820
pmt_freq_3 -> currency_RUB: r ^ 2 = 0.910620
pmt_freq_3 -> count_credit: r ^ 2 = 0.911109
So, based on the links we got in the previous step, we can add the following fields to the delete list:
FieldDrop =FieldDrop + ['fact_close_date','ttl_delq_30', 'pmt_string_84m_5', 'pmt_string_84m_A', 'pmt_string_84m_A', 'max_delq_balance', 'relationship_1', 'currency_RUB', 'count_credit'] newtr = trainDF.drop(FieldDrop, axis=1) Build and select models
Well, the primary data is processed and now you can proceed to the construction of the model.
Let's separate the class attribute from the training sample:
target = newtr.bad.values train = newtr.drop('bad', axis=1).values Now let's reduce the dimension of our sample in order to take only significant parameters. To do this, we use the principal component method and its implementation of PCA () in the sklearn module. In the parameter, we pass the number of components that we want to save (I chose 20, since with them the results of the models practically did not differ from the results on the initial data)
coder = PCA(n_components=20) train = coder.fit_transform(train) The time has come to define classification models. Take several different algorithms and compare the results of their work using the characteristics of the Area Under ROC Curve ( auc ). The following algorithms will be considered for modeling:
models = [] models.append(RandomForestClassifier(n_estimators=165, max_depth=4, criterion='entropy')) models.append(GradientBoostingClassifier(max_depth =4)) models.append(KNeighborsClassifier(n_neighbors=20)) models.append(GaussianNB()) So the models are selected. Let's now break down our training sample into 2 subsamples: test and training. This action is necessary so that we can calculate the characteristic auc for our models. The splitting can be performed using the train_test_split () function from the sklearn module:
TRNtrain, TRNtest, TARtrain, TARtest = train_test_split(train, target, test_size=0.3, random_state=0) It remains to train our models and evaluate the result.
To calculate the characteristics of auc there are 2 ways:
- Standard means of the sklearn module using the roc_auc_score or auc function
- Using the third-party package ml_metrics and auc () function
I will use the second method, because The first was shown in a previous article. The ml_metrics package is a very useful addition to sklearn, since it contains some metrics that are not in sklearn.
So, we will construct ROC curves and we will count their areas:
plt.figure(figsize=(10, 10)) for model in models: model.fit(TRNtrain, TARtrain) pred_scr = model.predict_proba(TRNtest)[:, 1] fpr, tpr, thresholds = roc_curve(TARtest, pred_scr) roc_auc = ml_metrics.auc(TARtest, pred_scr) md = str(model) md = md[:md.find('(')] pl.plot(fpr, tpr, label='ROC fold %s (auc = %0.2f)' % (md, roc_auc)) pl.plot([0, 1], [0, 1], '--', color=(0.6, 0.6, 0.6)) pl.xlim([0, 1]) pl.ylim([0, 1]) pl.xlabel('False Positive Rate') pl.ylabel('True Positive Rate') pl.title('Receiver operating characteristic example') pl.legend(loc="lower right") pl.show() 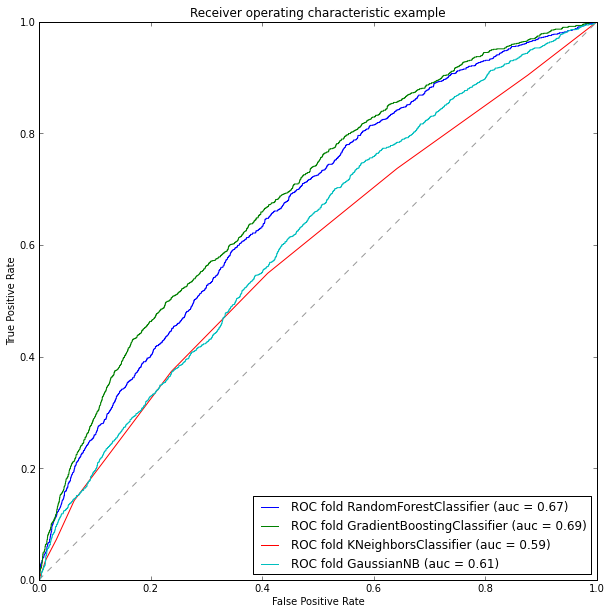
So, according to the analysis of our models, we can say that the gradient boosting showed itself best, its accuracy is about 69%. Accordingly, for learning a test sample, we will select it. Let's fill in the information in the test sample, having previously processed it to the required format:
# FieldDrop.append('bad') test = testDF.drop(FieldDrop, axis=1).values test = coder.fit_transform(test) # model = models[1] model.fit(train, target) # testDF.bad = model.predict(test) Conclusion
As a conclusion, I would like to note that the resulting accuracy of the model in 69% is not good enough, but I could not achieve greater accuracy. I would like to note the fact that when building a model on the full dimension, i.e. without taking into account correlated columns and reducing the dimension, it also gave 69% accuracy (this can be easily checked using the trainDF kit to train the model)
In this article, I tried to show all the main stages of data analysis from the primary processing of raw data to the construction of the classifier model. In addition, I would like to note that the reference vector method was not included in the analyzed models, this is due to the fact that after normalizing the data, the accuracy of the model dropped to 51% and the best result I was able to get with it was around 60%, with significant time consuming.
I would also like to note that, unfortunately on the test sample, the result could not be verified, since did not meet the timing of the tournament.
Source: https://habr.com/ru/post/204500/
All Articles