Parallels Cloud Server Automated Testing
I want to tell how one of the products of the company Parallels Inc. in which I work is tested,
- Parallels Cloud Server. I think some habrachchiteli this product is already familiar under the articles Parallels declassified Cloud Server , FastVPS: How we changed the virtualization platform and Collect it myself: how we did the Amazon-style storage for small hosters . If not, I recommend the articles above for reading.
Testing this product can be interesting for many reasons, and one of them is that the product is complex, multi-component and is being developed by several independent teams.
If I got you interested - welcome under the cat.
Parallels Cloud Server itself is a bare metal product, that is, it is installed on bare metal. It is an RHEL-based Linux distribution (we use Cloud Linux) with integrated components: a Linux kernel with our patches, a hypervisor , Parallels Cloud Storage components, a redesigned Anaconda-based installer, a convenient web-based panel for managing Parallels Virtual Automation containers and virtual machines, and many console utilities to manage and monitor Cloud Server. Our testing covers each of these components.
')
Now 98% of the functionality of Parallels Cloud Server is tested by autotests. And if for testing Parallels Server Bare Metal 4.0 (the predecessor of PCS 6.0) we launched 180 different tests, then in PCS 6.0 there were already 600 of them. I’ll just say that the specificity of the product itself left an imprint on the testing itself: we run autotests only on physical ones servers and our tests differ from any tests for sites on Selenium by the complexity of the tests themselves, the sophistication of their configurations and the duration (tests can last from 1 hour to 1 week).
So that you could imagine the volumes of our testing, I’ll give you some numbers: in PCS 6.0 RTM we used 572 tests and made 2959 test runs for 2.5 months, which is approximately 294 machine days. And we tested one of the latest updates with 260 unique tests and made 4800 launches.
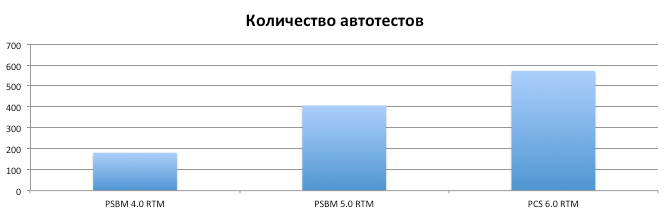
But it was not always so. More recently, about a few years ago, we didn’t have so many autotests and servers to run them. We installed the products on each machine manually, manually launched each autotest, manually created bugs in the bug tracker. But over time, the number of machines increased from 20 to 100, the number of tests from 180 to 600, which need to be run not from time to time, but on each build. And over time, we came to a testing system that is.
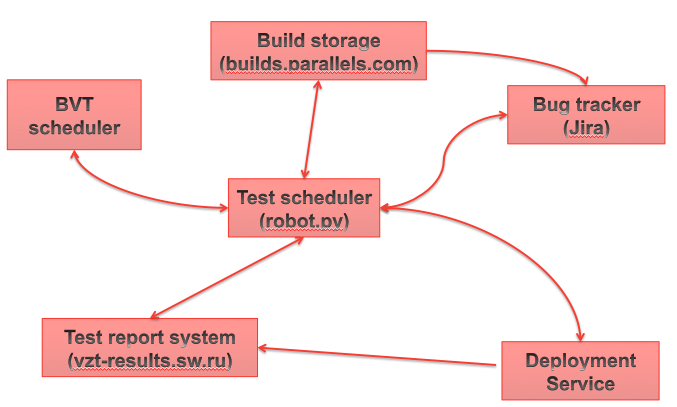
The basic infrastructure for running automated tests is quite simple and consists of several services:
Each build after building goes through several stages of testing:
According to the schedule of the build system, the Parallels Cloud Server build is being built and a notification about the successful completion of the build appears on the builds server. After that, the BVT (basic validation test) starts automatically. Our BVT actually consists of two parts: a test for the validation of the Parallels Cloud Server itself (this is a test of the basic functionality of containers and virtual machines) and a test of Parallels Cloud Storage (the same test, but Parallels Cloud Storage acts as a local disk) . If both tests succeed, the BVT scheduler sends notifications to the builds server and there the build is marked as valid. After this, the test planner runs all other scheduled tests. If the validation was not successful, then the testing ends there until a new build is built with the problem fixed.
The test planner is one of the key components of automated testing. And if sometimes you can get by with one of the most popular Continuous Integration systems for running tests (like Yandex uses Jenkins for example), then such solutions didn’t work for us because of the need to use your test run logic.
The scheduler receiving information from other services can:
Before testing another update or major release, we make up a set of tests that need to be run. Each such test plan consists of a set of titles, which briefly describes the test configuration (server requirements for running a test, a set of test parameters).
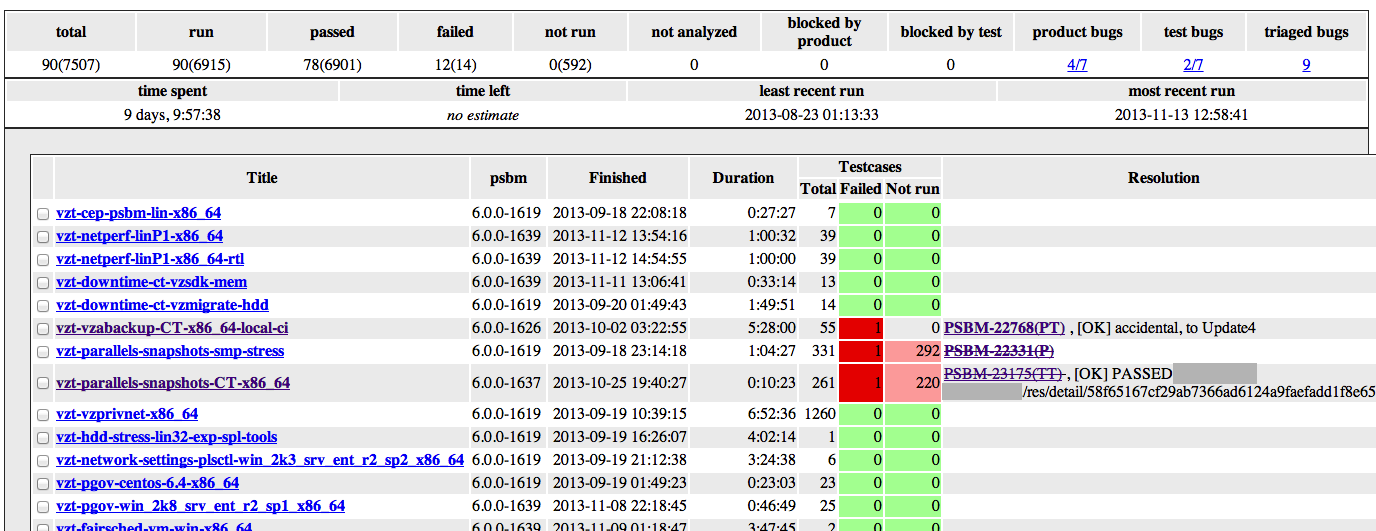
For each of the titles in the test plan there is a so-called “job” - a description of the test environment for running the test and its options: how many servers are needed to run, what are the requirements for these servers where the test will run (on the server itself, in a container or in a virtual machine etc.). The robot periodically scans the test plan, takes each title and, if the title is not blocked by test or product bugs, it tries to queue this title for launch: it tries to find servers that meet the requirements in the job for this title. If the necessary nodes are found, the robot creates activities for installing the operating system and product on these nodes in the deployment system and activity for running the test at the end of all installations.
While the test is running, the nodes involved in the test are marked with activities and are not used for other tests.

The screenshot above shows that the test was run on five nodes, the test was launched from the client ( pclin-c19 ) and not on the nodes themselves, Parallels Cloud Server was installed on two nodes, a pool of IP addresses was reserved for each node IP addresses for containers and virtual machines.
Upon successful completion of the test, the deployment system exports the results to the test report system, activities are destroyed and servers are used to run other tests.
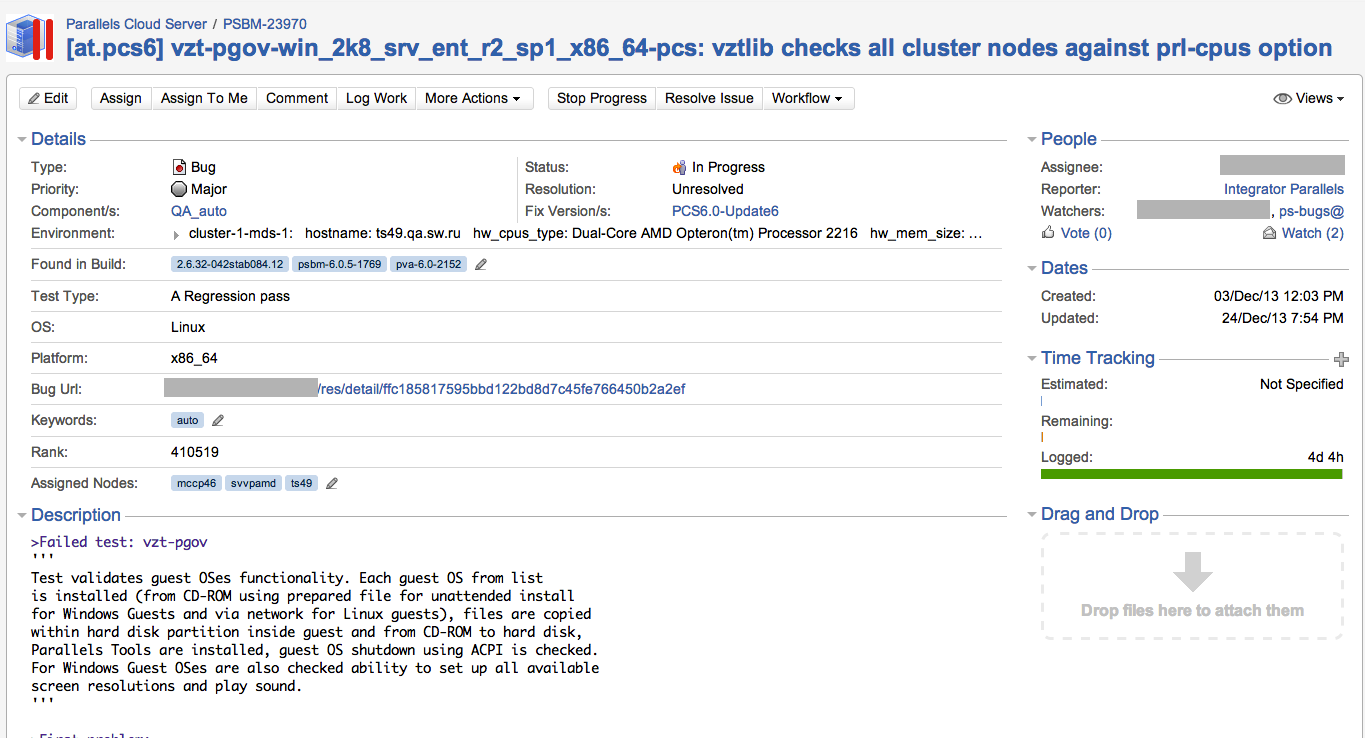
In case of problems when starting the test, a bug is started in Jira. Each autotest test bug contains: versions of the products participating in the test, a link to the test results, a test description, a backtrace test, a description of how to restart the test, problems for the virtual machine and a link to the previous results of this title (you have not forgotten what a title is ?) To each bug are attached the machines on which the bug was found (in the screenshot it’s mccp46 , ts49 and svvpamd ).
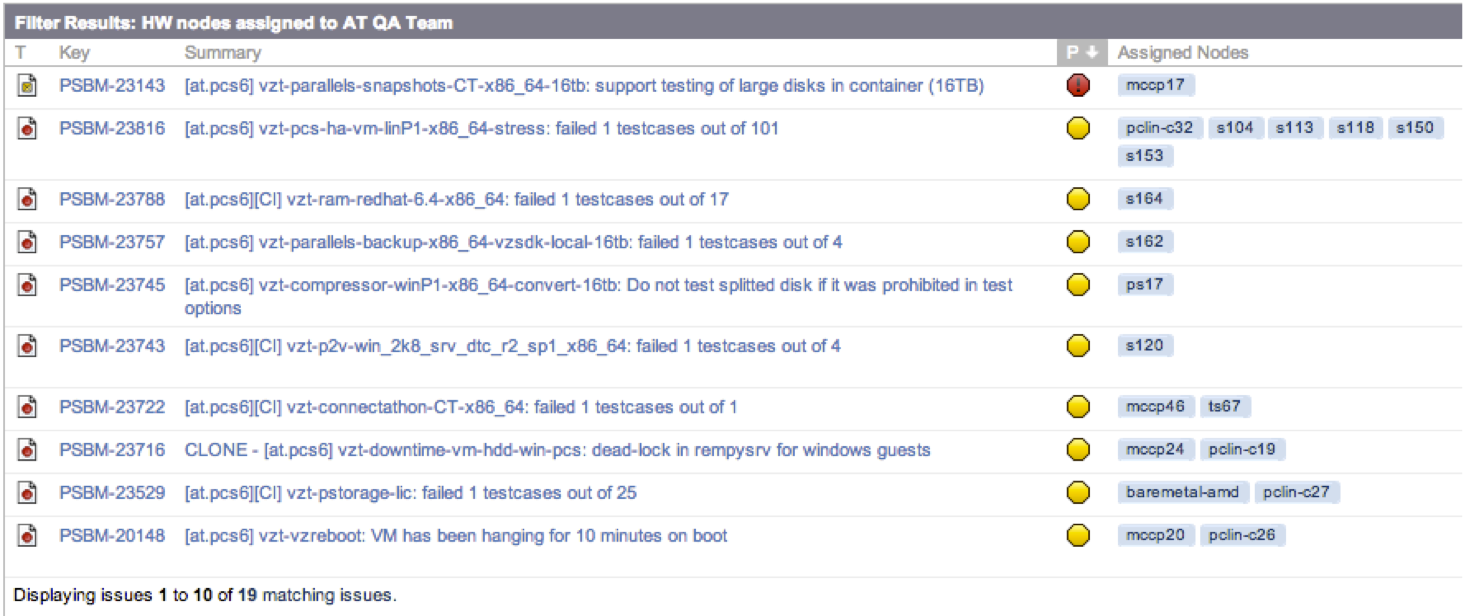
A developer or tester can always investigate a bug in the environment in which it was found. If the bug is trivial or the nodes are not needed for the study, then the nodes are detached from the bug (by simply editing the field in the bug).
To see in dynamics what is happening with the entire test pool of nodes, we have a schedule.
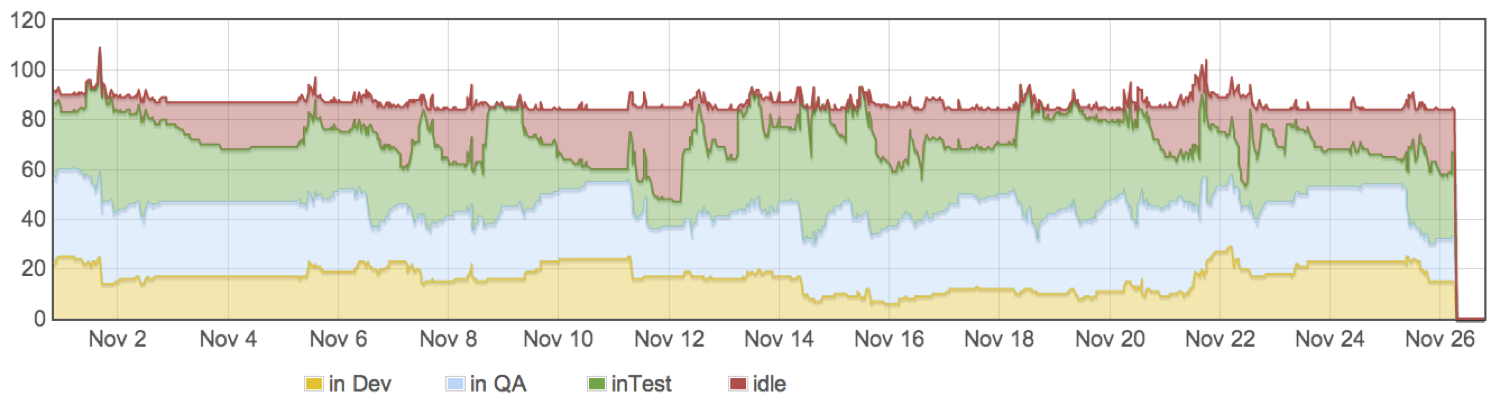
Therefore, we always know what our servers do.
As I wrote above, in addition to directly running tests, the robot can automatically validate product bugs. How it works? Each commit in the product contains a link to the ticket in jire. After the successful build of the build, a script is launched, which adds the build number to the closed changes from the changelog.
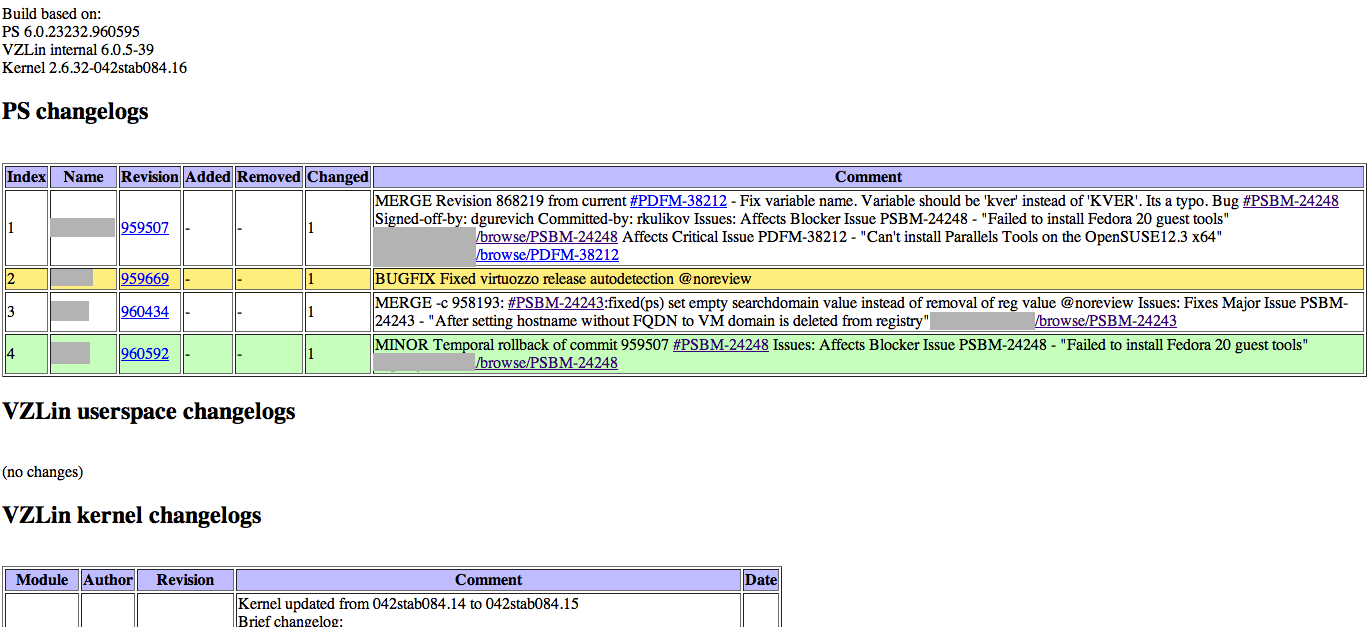
When planning tests, the robot takes this information into account and restarts tests with bugs only on the build where there is a fix. If the restarted test was successful, the robot automatically validates the bug in Jira and adds the build number and a link to the successful test run to the comment.
Automation automation, but no matter how much we want, the product cannot be tested without the participation of people. A test run on such an industrial scale is one person who is responsible for creating new test configurations (“jobs”), creating test plans with the necessary test set for each product update, server support (sometimes they break, sometimes you need to add specific equipment like SSD, USB bulk device emulation device, adding new functionality to test scheduler, etc.
And what is your interest in automated testing?
- Parallels Cloud Server. I think some habrachchiteli this product is already familiar under the articles Parallels declassified Cloud Server , FastVPS: How we changed the virtualization platform and Collect it myself: how we did the Amazon-style storage for small hosters . If not, I recommend the articles above for reading.
Testing this product can be interesting for many reasons, and one of them is that the product is complex, multi-component and is being developed by several independent teams.
If I got you interested - welcome under the cat.
Parallels Cloud Server itself is a bare metal product, that is, it is installed on bare metal. It is an RHEL-based Linux distribution (we use Cloud Linux) with integrated components: a Linux kernel with our patches, a hypervisor , Parallels Cloud Storage components, a redesigned Anaconda-based installer, a convenient web-based panel for managing Parallels Virtual Automation containers and virtual machines, and many console utilities to manage and monitor Cloud Server. Our testing covers each of these components.
')
Foreword
Now 98% of the functionality of Parallels Cloud Server is tested by autotests. And if for testing Parallels Server Bare Metal 4.0 (the predecessor of PCS 6.0) we launched 180 different tests, then in PCS 6.0 there were already 600 of them. I’ll just say that the specificity of the product itself left an imprint on the testing itself: we run autotests only on physical ones servers and our tests differ from any tests for sites on Selenium by the complexity of the tests themselves, the sophistication of their configurations and the duration (tests can last from 1 hour to 1 week).
So that you could imagine the volumes of our testing, I’ll give you some numbers: in PCS 6.0 RTM we used 572 tests and made 2959 test runs for 2.5 months, which is approximately 294 machine days. And we tested one of the latest updates with 260 unique tests and made 4800 launches.
But it was not always so. More recently, about a few years ago, we didn’t have so many autotests and servers to run them. We installed the products on each machine manually, manually launched each autotest, manually created bugs in the bug tracker. But over time, the number of machines increased from 20 to 100, the number of tests from 180 to 600, which need to be run not from time to time, but on each build. And over time, we came to a testing system that is.
General scheme of autotesting
The basic infrastructure for running automated tests is quite simple and consists of several services:
- builds is a portal where information about all builds, validation status, etc. is collected.
- bug tracker (we have this Atlassian Jira)
- test report system - a service that stores all test results. We use a samopisny portal.
- deployment system - our 'in house' service for server inventory, automatic installation of the OS on bare hardware, automatic installation of all Parallels products, installation of Windows updates, hard disk backup, node activity management (QA investigation, Developer investigation, Test execution etc) and much more.
- test planner
Each build after building goes through several stages of testing:
- basic validation of the build (Basic Validation Test)
- run continuous, regular tests, performance tests and stress tests
According to the schedule of the build system, the Parallels Cloud Server build is being built and a notification about the successful completion of the build appears on the builds server. After that, the BVT (basic validation test) starts automatically. Our BVT actually consists of two parts: a test for the validation of the Parallels Cloud Server itself (this is a test of the basic functionality of containers and virtual machines) and a test of Parallels Cloud Storage (the same test, but Parallels Cloud Storage acts as a local disk) . If both tests succeed, the BVT scheduler sends notifications to the builds server and there the build is marked as valid. After this, the test planner runs all other scheduled tests. If the validation was not successful, then the testing ends there until a new build is built with the problem fixed.
The test planner is one of the key components of automated testing. And if sometimes you can get by with one of the most popular Continuous Integration systems for running tests (like Yandex uses Jenkins for example), then such solutions didn’t work for us because of the need to use your test run logic.
The scheduler receiving information from other services can:
- run auto tests with different launch strategies
- prepare a test environment for running the test
- monitor new builds
- monitor server status based on information from deployment service
- monitor the status of the test plan and the statuses of bugs blocking autotests
- verify bugs from autotests
Before testing another update or major release, we make up a set of tests that need to be run. Each such test plan consists of a set of titles, which briefly describes the test configuration (server requirements for running a test, a set of test parameters).
For each of the titles in the test plan there is a so-called “job” - a description of the test environment for running the test and its options: how many servers are needed to run, what are the requirements for these servers where the test will run (on the server itself, in a container or in a virtual machine etc.). The robot periodically scans the test plan, takes each title and, if the title is not blocked by test or product bugs, it tries to queue this title for launch: it tries to find servers that meet the requirements in the job for this title. If the necessary nodes are found, the robot creates activities for installing the operating system and product on these nodes in the deployment system and activity for running the test at the end of all installations.
While the test is running, the nodes involved in the test are marked with activities and are not used for other tests.
The screenshot above shows that the test was run on five nodes, the test was launched from the client ( pclin-c19 ) and not on the nodes themselves, Parallels Cloud Server was installed on two nodes, a pool of IP addresses was reserved for each node IP addresses for containers and virtual machines.
Upon successful completion of the test, the deployment system exports the results to the test report system, activities are destroyed and servers are used to run other tests.
In case of problems when starting the test, a bug is started in Jira. Each autotest test bug contains: versions of the products participating in the test, a link to the test results, a test description, a backtrace test, a description of how to restart the test, problems for the virtual machine and a link to the previous results of this title (you have not forgotten what a title is ?) To each bug are attached the machines on which the bug was found (in the screenshot it’s mccp46 , ts49 and svvpamd ).
A developer or tester can always investigate a bug in the environment in which it was found. If the bug is trivial or the nodes are not needed for the study, then the nodes are detached from the bug (by simply editing the field in the bug).
To see in dynamics what is happening with the entire test pool of nodes, we have a schedule.
Therefore, we always know what our servers do.
As I wrote above, in addition to directly running tests, the robot can automatically validate product bugs. How it works? Each commit in the product contains a link to the ticket in jire. After the successful build of the build, a script is launched, which adds the build number to the closed changes from the changelog.
When planning tests, the robot takes this information into account and restarts tests with bugs only on the build where there is a fix. If the restarted test was successful, the robot automatically validates the bug in Jira and adds the build number and a link to the successful test run to the comment.
Automation automation, but no matter how much we want, the product cannot be tested without the participation of people. A test run on such an industrial scale is one person who is responsible for creating new test configurations (“jobs”), creating test plans with the necessary test set for each product update, server support (sometimes they break, sometimes you need to add specific equipment like SSD, USB bulk device emulation device, adding new functionality to test scheduler, etc.
And what is your interest in automated testing?
Source: https://habr.com/ru/post/204292/
All Articles