Lexicon Habra
 This post is a continuation of this study of Hubrauzer Muxto about the most frequently encountered words in Habr's articles and comments. As, however, many have noticed, the top-10 and even the top-50, received by Muxto , does not abound in actual IT terms, they are not there at all: “in” (107,735), “and” (106,420), “on” (103,084), “c” (93,453), “not” (91,591), “what” (88,488), etc.
This post is a continuation of this study of Hubrauzer Muxto about the most frequently encountered words in Habr's articles and comments. As, however, many have noticed, the top-10 and even the top-50, received by Muxto , does not abound in actual IT terms, they are not there at all: “in” (107,735), “and” (106,420), “on” (103,084), “c” (93,453), “not” (91,591), “what” (88,488), etc.The next obvious step was to identify the terms most significantly deviating from the average in the Russian language. Having received "good" from the author of the first part of the study and discussed some mathematical questions with the Trept user , I started the following activities.
From the site of the National Corpus of the Russian Language (NCRF) , a base of frequencies of word forms of the “averagely common” Russian language was downloaded, compiled on the basis of text analysis with a total volume of 192,689,044 units (words). In base 1 054 211 unique case-sensitive word forms. Since the analysis of Habr's vocabulary presented by Muxto is case-insensitive, and in principle it is more consistent with the final goal, the first task turned out to bring all word forms to lowercase. The unique case-insensitive word forms in the NCRF base remained - 888,397 (the frequencies of the combined forms, naturally, were summed up).
The second question was the actual identification of meaningfully prominent words. As it turned out, this problem was solved long ago in modern linguistics, which is actively using both statistics and computer technology. One of the statistics of the degree of “heterogeneity” of the frequency of occurrence of a word in one case with respect to the general set of cases, which philologists especially liked, is a G-test, which is a special case of a likelihood ratio test. The statistics for a single word are calculated as
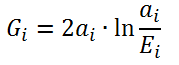
Here a i is the actually observed frequency of occurrence of the i -th word form in the body under study,
and E i - the expected frequency of the same word form in the test case, provided that the cases join, that is,
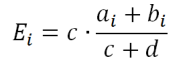
where a i and b i are the frequencies of occurrence of the i -th word form in the housings (Habr and NCRF),
and c and d are the total volume of these shells (33,732,229 and 192,689,044 units, respectively).
')
So, all the calculations are made, the words are sorted by decreasing G i , top 30 statistics:
405587,703 197850,057 139330,707 135705,259 124132,397 121233,522 116809,907 113262,075 109463,742 94468,080 92093,985 79257,370 com 77786,398 74006,346 71844,136 ru 66674,626 64946,067 63195,334 60807,287 60433,187 google 55160,380 55147,137 53984,795 52609,986 windows 50998,105 50177,316 48421,264 http 48372,913 48328,683 48158,301 Suspicious? Yes, I confess, I still manually combined the frequencies of several forms of the same word in the top 150 after the first run, choosing the initial form of the word, since It was a shame to see in the top the word form “user / user / users” or, for example, “version / versions / version” with very high indicators, but not among the leaders simply because the Russian language is rich in the end of the case and numbers.
Both the top 30 and the top 150 of Habrahabr certainly deserve reflection. Personally, I was pleased with the result - in my opinion, the essence of this unique IT resource was highlighted very accurately. Well, the leader - "USER" - is the generalized goal for which we spend hours, days and years of our life.
Wordle.net responded to the loaded top 30 (with frequencies proportional to G statistics) and the Habr color palette with such a tag cloud:

And I can only offer you as a philological warm-up to come up with in comments the longest sentence with the words from the top 30, which would not seem too artificial.
I wish you all an upbeat and fun Friday!
Source: https://habr.com/ru/post/204104/
All Articles