The task of changing the voice. Part 1. What is a voice?
With this post we would like to start a cycle of articles devoted to the task of changing the voice. In foreign literature, this problem is often referred to as the term voice morphing, in the domestic literature this task has not yet received sufficient coverage in both scientific and engineering circles. The topic is quite extensive and in many ways creative. As a result of work in this direction, we have gained some experience, which we plan to systematize and set out, as well as to convey the main essence of some algorithms.
A voice change may have a different purpose. Two main areas that can be clearly identified here are getting a realistic sound of a modified voice and getting some fancy sound. Not bad results in the second case can be achieved by treating the speech signal as an ordinary sound, without focusing on its features and making many assumptions. For example, the electronic music industry has generated a huge amount of various audio effects and the result of their application to the speech signal helps to create the most incredible image of the speaker.
In the task of realistic voice change, the use of “musical” (let's call them so) audio effects can introduce distortions that are not characteristic of the naturalistic sound of speech. In such a case, it is necessary to understand more precisely what sounds make up speech, how they are formed, and what their properties are critical for perception. Simply put - it is necessary to analyze the signal before it is processed. With automated real-time speech processing, this analysis is complicated many times, because multiplies the number of uncertainties that must somehow be resolved, and reduces the number of applicable algorithms.
In the upcoming articles we will consider options for the simplest realization of such effects as changing the speaker's gender and changing the speaker's age. In order to better understand the reader, what parameters of the signal will change, in the first articles the main issues of the formation of speech sounds and ways of formal description of the speech signal will be touched upon. After that, specific proposed voice change algorithms, their strengths and weaknesses will be discussed.
')
PS
Added additional links to primary sources
If we consider the sounds of speech separately from each other, at first glance it may seem that they do not represent anything special - a typical vowel sound is in fact not so far from the sound of, say, a flute. However, the processing of separate sounds “in a vacuum” is unlikely for many to be of practical benefit - the processing of a continuous speech signal looks much more attractive. The idea of naturalistic sounding of processed speech seems doubly attractive. This task is already much more difficult - in natural fluent speech, the sounds flow so quickly and smoothly one into the other, that even a person with experience cannot always clearly define the border during processing. And if all the sounds of speech are approached in the same way - no natural sound will come out.
The speech signal is a more "versatile", so to speak, signal, rather than for example the sound of musical instruments. Occupying a relatively narrow frequency band, it consists of a huge variety of elementary sounds, which in addition can coarse in the most bizarre way, even in everyday speech, not to mention the conscious change of voice by a professional actor. At the same time, these elementary sounds have a different nature and, as a result, different characteristics in terms of standard algorithms for analyzing and processing signals.
The human speech path is perhaps the most perfect and flexible in comparison with all known animals, and, due to the variety of sounds produced, leaves behind most musical instruments. The main difficulty in analyzing and changing the voice signal lies precisely in this diversity and the resulting large uncertainty associated with the isolation and processing of elementary sound units. There are no algorithms that are well suited to handle all speech sounds. In addition, a person can pronounce the same elementary sound differently depending on his emotional, physical condition, on the place of sound in a word, etc. Individual features of pronunciation, cultural and linguistic factors, medical pathologies - all this also influences the pronounced sound.
To understand the specifics of voice signal processing, let us consider in more detail the question of the sound composition of speech and how these sounds are formed. The process of sound formation is usually described using two basic concepts: phonation and articulation, we describe them in order.
Phonation is a part of the process of sound formation occurring in the human larynx. It all begins with the compression of the lungs - this sets in motion the air that from the lungs enters the larynx through the trachea. This air flow has a practically constant, slowly varying speed. In the larynx there is a glottis, formed by two vocal folds, to which the vocal cords are attached. When the voltage of the ligaments, the glottis intermittently closes / opens and thus forms air pulses from the inlet air flow. Each pulse can be described by the volumetric air velocity that passes through the glottis; we denote its instantaneous value as U (t). The human ear perceives fluctuations in pressure, which are affected by changes in the speed of the air flow, and we are thus more interested in the first derivative of the volumetric rate, dU / dt. For more visual illustration, you can pay attention to the picture below. The model U (t) and its first derivative are shown, both graphs are obtained using the Rosenberg model:
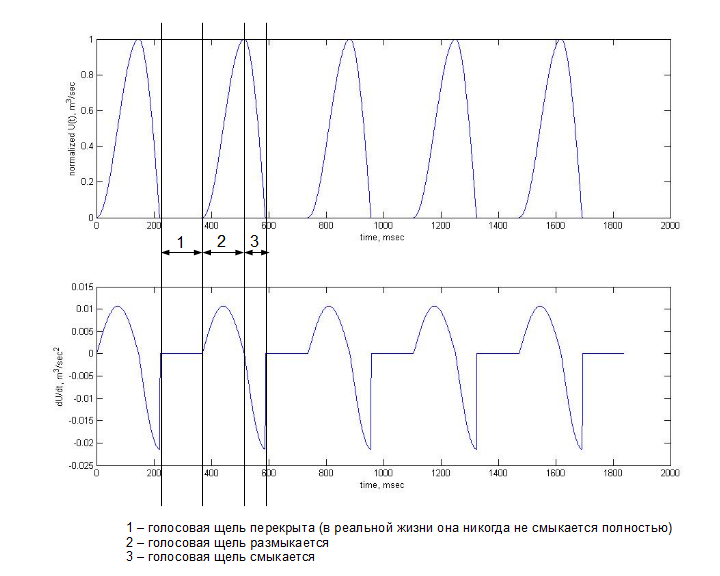
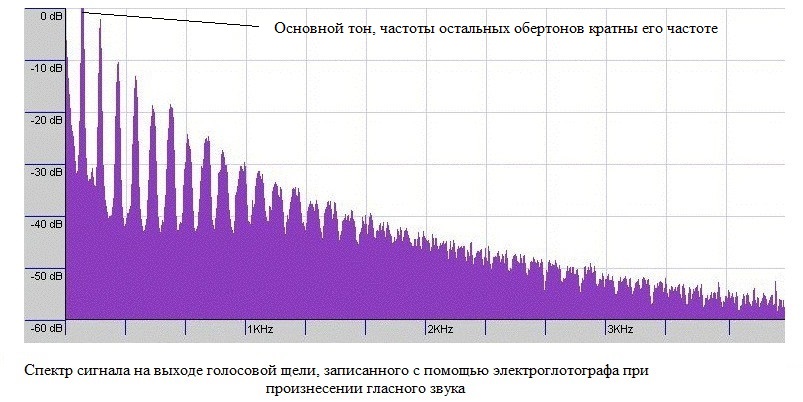
The upper graph reflects the value of U (t) in time at the exit of the glottis. The lower graph shows the first derivative of U (t) over time - the essence of the change in pressure at the exit of the glottis. This periodic change in pressure is already a sound in itself. This sound consists of noise and harmonic components. The noise component is formed by turbulence due to a sharp increase in U (t) and incomplete closure of the glottis (the model in the picture above does not take into account the noise component). The harmonic component can be represented by a harmonic series, where the frequencies of all secondary harmonics (also called overtones) are multiple to the frequency of the first lowest harmonic, called the frequency of the fundamental tone. (see picture below).
The physics of the formation of these harmonics in two words cannot be explained, for this it is better to write a separate article. The main thing is to remember that quite a harmonic sound can already come out of the larynx during the operation of the ligaments. The numerical value of the frequency of the fundamental tone is equal to the frequency of contraction of the vocal cords and is a function of their length, density, and tension.
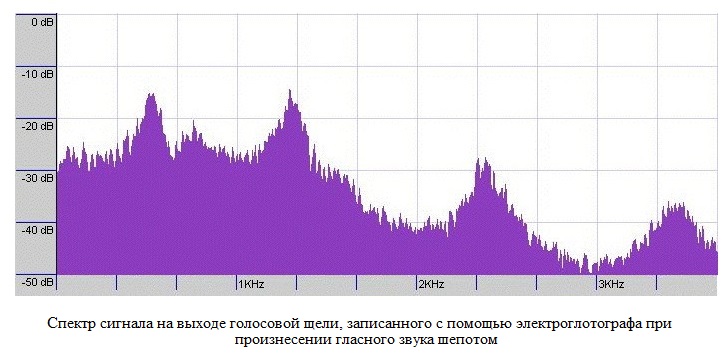
With relaxed connectives and a constantly open glottis, the air flow is not “cut”, so to speak, the air velocity in this case oscillates slightly around a certain constant value and the sound generated is of a noise nature, an example of the spectrum of this signal is given below.
The result of phonation is a sound, which is often called the "excitation signal of the vocal tract." From this basic signal (harmonic or not) as it passes through the vocal tract, the final sound that we hear during a conversation will be formed further.
Brief summary: the main “instrument” of phonation is two vocal folds, which form a glottis and are driven by vocal cords. Bundles can periodically contract or be relaxed, resulting in voiced or unvoiced sounds, respectively.
The study of phonation, especially vocalized, is devoted to a huge amount of work examining this process from various points of view - mechanical, thermodynamic, acoustic, statistical, psychoacoustic. It has been reliably established that the imperfection of air pulses generated during vocalized phonation, the random change in their shape and frequency, greatly affects the natural sound. For example, you can listen to the sound from the link provided - it is just synthesized using the model from the first figure, as well as the parameters of the speech path of the author of the article, while pronouncing the sound “A”. I do not think that this sound will seem to someone "alive" and natural. The human ear accurately determines the sound synthesized using an artificial excitation signal, which greatly increases the significance of the statistical study of this process.

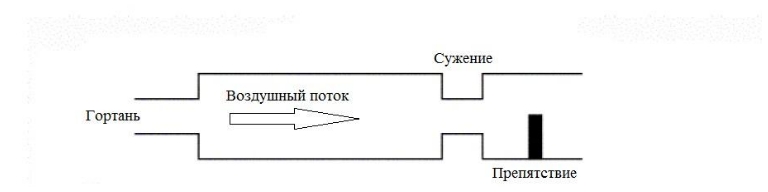
Articulation involves the process of changing the state of all elements of the vocal tract during sound pronunciation. The fonation is part of the articulation. The speech path can be simplified to represent a set of cameras and tubes (see figure on the right), through which the excitation signal passes. Constrictions and expansion of the vocal tract bows, which lie above the larynx, additionally affect the speed of the air flow, create additional (besides the glottis) zones of turbulence. At the same time, the vocal tract cavities are similar to acoustic resonators when passing through which amplify one and weaken other frequencies of sound. The muscles of the vocal tract allow a person to control the geometry of the vocal tract chambers, to create obstacles to the air flow path (tongue, teeth, lips).
In a rough approximation, we can summarize the above, as:
articulation = phonation + work of the muscles of the vocal tract,
where phonation may be voiced or not voiced, and the contraction of each individual muscle is a function of time.
In the process of learning conversational speech, a person learns to coordinate the work of the articulation organs to produce certain sounds. Due to individual anatomical features, the same sound sounds a bit different for all people, and this is one of the important factors by which we distinguish people's voices. With the coordinated work of the vocal cords and other muscles of the vocal tract, the formation of vowels, consonants, mixed and transient sounds is possible. It is further proposed to briefly review these groups, in general terms, to describe their articulation and the main features.
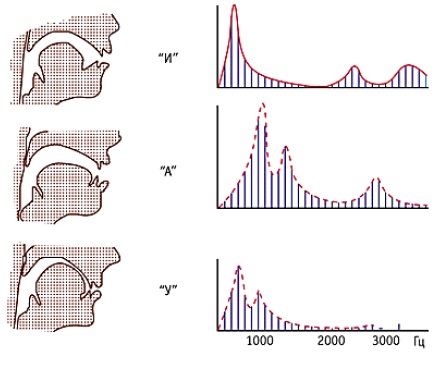
From school it is known that all sounds of speech were initially divided into vowels and consonants. Vowel sounds are generated when a voiced excitation signal from the glottis passes through the rest of the vocal tract, which in this case occupies a certain fixed geometric shape. This process is very similar to how the sound of an oscillating string passes through the body of a guitar. In the case of the human voice, the periodically shrinkable glottis appears as the “string”, and the body is everything that is higher than it. If we imagine that the guitar body can take one of several “pre-learned” forms, then it is possible to draw an analogy with vowel sounds: the larynx creates a voiced excitation signal, and the vocal tract takes one of the forms, the vowel sound is finally obtained.
Changing the geometry of the vocal tract, a person changes his acoustic resonant properties. As a result, some frequencies are amplified, while some are noticeably weaker. Gain zones are usually called formant frequencies or formants. Vowel sounds differ from each other precisely in their formant structure (see the figure on the right), depending on the geometry of the vocal tract at the time of speech formation - this is how a person by ear can distinguish them. The exact numerical values of the formant frequencies are individual for each person. However, their relative distance between each other has approximately the same proportions for all people (otherwise how could we recognize, for example, the sound “O” pronounced by different people).
We now turn to consonants. Their number significantly exceeds the number of vowel sounds and in their sound they can be divided into subclasses. As is often the case in real life, many phenomena have signs of many classes and an unambiguous classification is very difficult. Consonants in this case are no exception. Their division into classes depends on the language in question and the phonetic theory used. We consider the most general classification, consisting of three main groups:
- fricative consonants
- occlusive consonants
- sound consonants
Fricative consonants are formed by the "friction" of the air flow on the narrowing of the vocal tract and the obstacles in the path of the air. These restrictions and obstacles can be created by sky, tongue, teeth, lips, etc (sounds F, X, W, C ...). The cavities of the vocal tract in this case occupy a certain (conditionally) fixed position. Contractions and obstacles cause local changes in airflow pressure, which in turn creates turbulence zones. The turbulent noise generated in this way is no longer white - it has a color
The generated noise signal, as in the case of vowel sounds, passes through a certain number of acoustic filters (vocal tract chambers), which give this noise some characteristic spectral shape and sound.
Strong consonants are formed by complete overlap of the vocal tract by any organ of articulation with an open glottis. At the same time, the air coming from the lungs through the open glottis, injects pressure and with an abrupt disconnection of the obstacle creates an “explosive” sound (sounds K, P, T ...). For example, when pronouncing the sound “P”, a person closes his lips, but the lungs continue to exert pressure. Then the lips abruptly open and the hopping drop created in the pressure generates the familiar sound “P”. The image in the time domain is shown below:
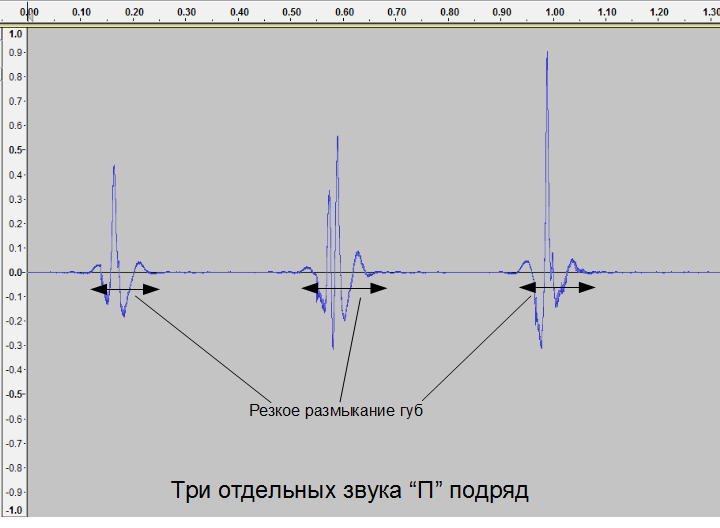
It should be noted that all three attempts at the pronunciation of sound are significantly different from each other in the time domain. Moreover, it is very difficult to distinguish them by ear.
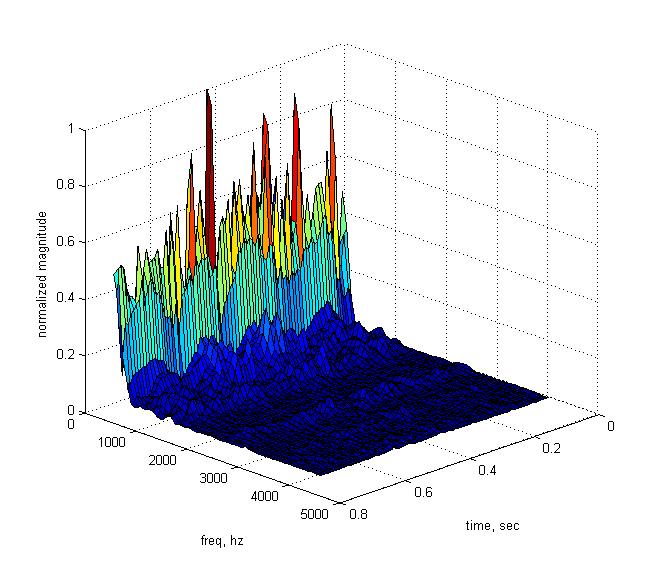
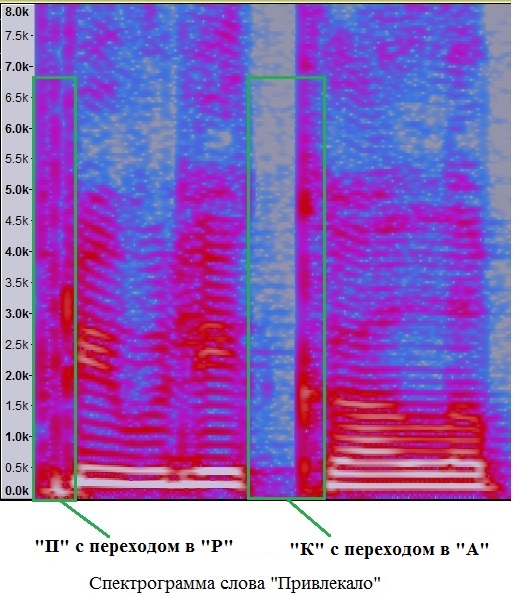
An example of a spectrogram of a word with several noisy sounds is shown below.
Also, it should be noted that both fricative and stop consonants can be “voiced”. “Voiced” consonants are, by their nature, mixed sounds, formed by pronouncing a consonant sound simultaneously with the operation of the vocal cords. For example, if you perform the actions described when you pronounce the sound “P” and add the work of the vocal cords, you get the sound “B”. However, it cannot be argued that they are a simple superposition of some vowel and some consonant sound in the time domain. You can’t just take a sound “C”, fold it with a recorded sound “E” and get the sound “H” at the output. Definitely, one can only say that voiced consonants are formed with the help of a voiced excitation signal.
In a separate group, it is customary to single out sonorous consonants that do not contain strong turbulent noise, since when they are pronounced an additional passage is created for the air (L, R, M, N, Y). However, some obstacle is still created (tongue, tongue + teeth, tongue + sky), because of this:
- many harmonics from the initial harmonic series are significantly attenuated
- in general, the energy of the spoken sound decreases
- There are some noise sounds.
Sounds “M” and “H” are nasal - a significant obstacle is created in the mouth, and the nasopharynx is completely open to the passage of air. The oral cavity in this case is an additional resonant cavity, and the nasal cavity becomes the main emitter of sound. The sound "P" refers to the group of so-called "yeast" sounds. Sonoric sounds with their spectrum quite strongly resemble vowel sounds. Looking at the spectrogram, their short-term appearances can be hard to isolate, especially when they are transformed into vowel sounds. The sounds of “L”, “P”, “Y” are considered by many authors to be semi-public because of the possibility to distinguish bright dominant formants in their composition.
It is necessary to say a few words about the calls and transitional sounds. Their education is connected with the fact that the organs of articulation of a person in continuous speech cannot take and instantly change their position. This process occurs smoothly in time. In phonetics, it is customary to distinguish three stages of pronouncing a separate sound: excursion, endurance, and recursion. During the tour, the articulation organs take the initial position necessary for the formation of sound. During exposure, the sound itself is pronounced. During recursion, the organs either come to rest or are rearranged to begin pronouncing the next sound — the recursion of one sound is superimposed on a tour of the other. Such a co-articulation affects a lot of overtones, which, as a rule, are not entered into alphabets, but may well be classified and highlighted in the voice signal (unfortunately, not always automatically). As an illustration, one can cite the spectra of the sound “P”already tortured by the author , with its separate pronunciation and in the composition of the syllable “PE”.
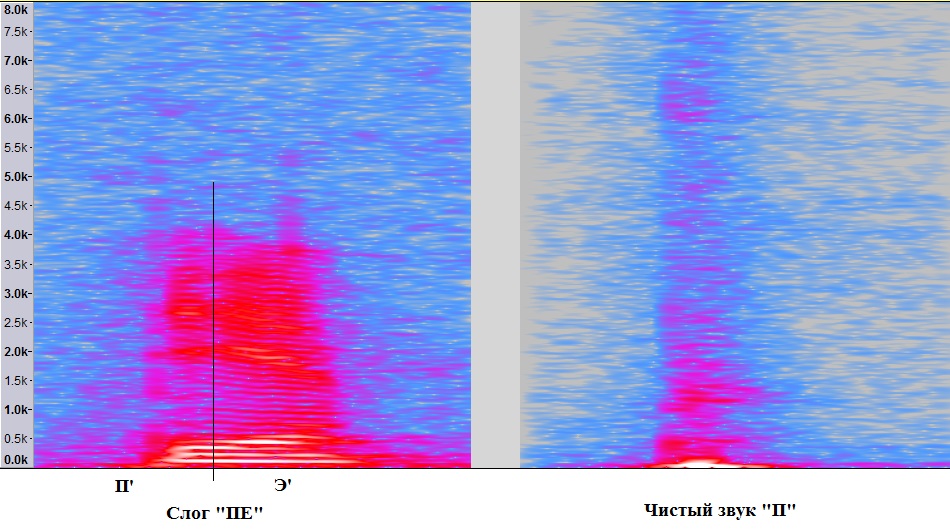
The difference between the pronunciation of the sound "P" can be seen with the naked eye. At the moment of opening the lips, the vocal tract has already taken a position to pronounce the softened “E”, which affected the pronunciation of “P”. Such metamorphoses occur with almost all consonant sounds — their position relative to vowel sounds significantly affects their “appearance” and sound.
Some facts about vowels and consonants:
1. Vowel sounds have a harmonic nature and a clearly defined formant structure. Consonants have a noise nature, but may have a pronounced harmonic component (picture below, sounds “B”, “L”).
2. Vowel sounds carry a greater amount of energy than consonants, its main part (1st and 2nd formant) lie in the range from 400 to 3000 Hz. Consonants have significantly less energy. In a large part of consonant sounds, a significant part of this energy is concentrated in the region of 2-10 KHz. One example is shown below:
3. Vowel sounds have, on average, a longer duration than consonants (100-300 msec versus 30-100 msec, although specific exact numbers are highly dependent on the language and person)
4. Despite the lower energy and duration, consonant sounds, oddly enough, carry the basic speech information. As a visual example, you can consider a good puzzle from Rabiner:
Recover phrase
"Th_y n_t_d s_gn_f_c_nt _mpr_v_m_nts _n th_ c_mp_n_s _m_g_, ..." (they’re noted significant improvement in the company's image, ...)
vs
“A__i_u_e_ _o_a___ _a_ __a_e_ e_e__ia___ __e _a_e, ...” (Attitudes towards pay stayed is essentially the same, ...).
A speech signal with continuous speech can conditionally be considered stationary in the intervals from 5 to 100 milliseconds, depending on the features of the speaker and the spoken sound. On longer analysis intervals, the probability of a significant change in the properties of a signal increases, which may lead to inconsistency in evaluating its averaged parameters. As in any other field of signal processing, big problems can create noise interference, especially those that are harmonious and / or some similarities of formant - frequency domains with relatively high energy.
This compressed overview contains only basic information about the process of speech formation and the classification of speech sounds. Even in the very first approximation, each pronounced sound depends on a considerable number of parameters, individual for each individual person. Accurate measurement of these physiological parameters is not always possible even with modern medical devices. If you set a goal to get the most realistic sound of the processed signal, many of these parameters must be assessed anyway and the only way is to search for optimal values. Such an approach almost always introduces artifacts into the reconstructed speech signal, sometimes more, sometimes less audible. If you still complicate your life and set the task of voice processing in real time, then the search for these optimal values is possible only by processing the incoming signal, so to speak, “on the go”, which also cannot but affect the final sound.
The next article will give an overview of the main toolkit, which helps in one way or another to solve many problems - briefly will be considered a model of the speech signal. It will also show what parameters of these models can be adjusted during resynthesis to change the output sound.
___________
Used Books:
[1] I. Aldoshina, Fundamentals of psychoacoustics, collection of articles.
[2] LR Rabiner, B.-H. Juang, Fundamentals of Speech Recognition
[3] LR Rabiner, RW Schafer, Digital Processing of Speech Signals
[4] V.N. Sorokin, Speech Synthesis
[5] www.phys.unsw.edu.au/jw/glottis-vocal-tract-voice.html
A voice change may have a different purpose. Two main areas that can be clearly identified here are getting a realistic sound of a modified voice and getting some fancy sound. Not bad results in the second case can be achieved by treating the speech signal as an ordinary sound, without focusing on its features and making many assumptions. For example, the electronic music industry has generated a huge amount of various audio effects and the result of their application to the speech signal helps to create the most incredible image of the speaker.
In the task of realistic voice change, the use of “musical” (let's call them so) audio effects can introduce distortions that are not characteristic of the naturalistic sound of speech. In such a case, it is necessary to understand more precisely what sounds make up speech, how they are formed, and what their properties are critical for perception. Simply put - it is necessary to analyze the signal before it is processed. With automated real-time speech processing, this analysis is complicated many times, because multiplies the number of uncertainties that must somehow be resolved, and reduces the number of applicable algorithms.
In the upcoming articles we will consider options for the simplest realization of such effects as changing the speaker's gender and changing the speaker's age. In order to better understand the reader, what parameters of the signal will change, in the first articles the main issues of the formation of speech sounds and ways of formal description of the speech signal will be touched upon. After that, specific proposed voice change algorithms, their strengths and weaknesses will be discussed.
')
PS
Added additional links to primary sources
Introduction
If we consider the sounds of speech separately from each other, at first glance it may seem that they do not represent anything special - a typical vowel sound is in fact not so far from the sound of, say, a flute. However, the processing of separate sounds “in a vacuum” is unlikely for many to be of practical benefit - the processing of a continuous speech signal looks much more attractive. The idea of naturalistic sounding of processed speech seems doubly attractive. This task is already much more difficult - in natural fluent speech, the sounds flow so quickly and smoothly one into the other, that even a person with experience cannot always clearly define the border during processing. And if all the sounds of speech are approached in the same way - no natural sound will come out.
The speech signal is a more "versatile", so to speak, signal, rather than for example the sound of musical instruments. Occupying a relatively narrow frequency band, it consists of a huge variety of elementary sounds, which in addition can coarse in the most bizarre way, even in everyday speech, not to mention the conscious change of voice by a professional actor. At the same time, these elementary sounds have a different nature and, as a result, different characteristics in terms of standard algorithms for analyzing and processing signals.
The human speech path is perhaps the most perfect and flexible in comparison with all known animals, and, due to the variety of sounds produced, leaves behind most musical instruments. The main difficulty in analyzing and changing the voice signal lies precisely in this diversity and the resulting large uncertainty associated with the isolation and processing of elementary sound units. There are no algorithms that are well suited to handle all speech sounds. In addition, a person can pronounce the same elementary sound differently depending on his emotional, physical condition, on the place of sound in a word, etc. Individual features of pronunciation, cultural and linguistic factors, medical pathologies - all this also influences the pronounced sound.
Sound formation, general information
To understand the specifics of voice signal processing, let us consider in more detail the question of the sound composition of speech and how these sounds are formed. The process of sound formation is usually described using two basic concepts: phonation and articulation, we describe them in order.
Phonation is a part of the process of sound formation occurring in the human larynx. It all begins with the compression of the lungs - this sets in motion the air that from the lungs enters the larynx through the trachea. This air flow has a practically constant, slowly varying speed. In the larynx there is a glottis, formed by two vocal folds, to which the vocal cords are attached. When the voltage of the ligaments, the glottis intermittently closes / opens and thus forms air pulses from the inlet air flow. Each pulse can be described by the volumetric air velocity that passes through the glottis; we denote its instantaneous value as U (t). The human ear perceives fluctuations in pressure, which are affected by changes in the speed of the air flow, and we are thus more interested in the first derivative of the volumetric rate, dU / dt. For more visual illustration, you can pay attention to the picture below. The model U (t) and its first derivative are shown, both graphs are obtained using the Rosenberg model:
The upper graph reflects the value of U (t) in time at the exit of the glottis. The lower graph shows the first derivative of U (t) over time - the essence of the change in pressure at the exit of the glottis. This periodic change in pressure is already a sound in itself. This sound consists of noise and harmonic components. The noise component is formed by turbulence due to a sharp increase in U (t) and incomplete closure of the glottis (the model in the picture above does not take into account the noise component). The harmonic component can be represented by a harmonic series, where the frequencies of all secondary harmonics (also called overtones) are multiple to the frequency of the first lowest harmonic, called the frequency of the fundamental tone. (see picture below).
The physics of the formation of these harmonics in two words cannot be explained, for this it is better to write a separate article. The main thing is to remember that quite a harmonic sound can already come out of the larynx during the operation of the ligaments. The numerical value of the frequency of the fundamental tone is equal to the frequency of contraction of the vocal cords and is a function of their length, density, and tension.
With relaxed connectives and a constantly open glottis, the air flow is not “cut”, so to speak, the air velocity in this case oscillates slightly around a certain constant value and the sound generated is of a noise nature, an example of the spectrum of this signal is given below.
The result of phonation is a sound, which is often called the "excitation signal of the vocal tract." From this basic signal (harmonic or not) as it passes through the vocal tract, the final sound that we hear during a conversation will be formed further.
Brief summary: the main “instrument” of phonation is two vocal folds, which form a glottis and are driven by vocal cords. Bundles can periodically contract or be relaxed, resulting in voiced or unvoiced sounds, respectively.
The study of phonation, especially vocalized, is devoted to a huge amount of work examining this process from various points of view - mechanical, thermodynamic, acoustic, statistical, psychoacoustic. It has been reliably established that the imperfection of air pulses generated during vocalized phonation, the random change in their shape and frequency, greatly affects the natural sound. For example, you can listen to the sound from the link provided - it is just synthesized using the model from the first figure, as well as the parameters of the speech path of the author of the article, while pronouncing the sound “A”. I do not think that this sound will seem to someone "alive" and natural. The human ear accurately determines the sound synthesized using an artificial excitation signal, which greatly increases the significance of the statistical study of this process.
Articulation involves the process of changing the state of all elements of the vocal tract during sound pronunciation. The fonation is part of the articulation. The speech path can be simplified to represent a set of cameras and tubes (see figure on the right), through which the excitation signal passes. Constrictions and expansion of the vocal tract bows, which lie above the larynx, additionally affect the speed of the air flow, create additional (besides the glottis) zones of turbulence. At the same time, the vocal tract cavities are similar to acoustic resonators when passing through which amplify one and weaken other frequencies of sound. The muscles of the vocal tract allow a person to control the geometry of the vocal tract chambers, to create obstacles to the air flow path (tongue, teeth, lips).
In a rough approximation, we can summarize the above, as:
articulation = phonation + work of the muscles of the vocal tract,
where phonation may be voiced or not voiced, and the contraction of each individual muscle is a function of time.
In the process of learning conversational speech, a person learns to coordinate the work of the articulation organs to produce certain sounds. Due to individual anatomical features, the same sound sounds a bit different for all people, and this is one of the important factors by which we distinguish people's voices. With the coordinated work of the vocal cords and other muscles of the vocal tract, the formation of vowels, consonants, mixed and transient sounds is possible. It is further proposed to briefly review these groups, in general terms, to describe their articulation and the main features.
The simplest classification of speech sounds
From school it is known that all sounds of speech were initially divided into vowels and consonants. Vowel sounds are generated when a voiced excitation signal from the glottis passes through the rest of the vocal tract, which in this case occupies a certain fixed geometric shape. This process is very similar to how the sound of an oscillating string passes through the body of a guitar. In the case of the human voice, the periodically shrinkable glottis appears as the “string”, and the body is everything that is higher than it. If we imagine that the guitar body can take one of several “pre-learned” forms, then it is possible to draw an analogy with vowel sounds: the larynx creates a voiced excitation signal, and the vocal tract takes one of the forms, the vowel sound is finally obtained.
Changing the geometry of the vocal tract, a person changes his acoustic resonant properties. As a result, some frequencies are amplified, while some are noticeably weaker. Gain zones are usually called formant frequencies or formants. Vowel sounds differ from each other precisely in their formant structure (see the figure on the right), depending on the geometry of the vocal tract at the time of speech formation - this is how a person by ear can distinguish them. The exact numerical values of the formant frequencies are individual for each person. However, their relative distance between each other has approximately the same proportions for all people (otherwise how could we recognize, for example, the sound “O” pronounced by different people).
We now turn to consonants. Their number significantly exceeds the number of vowel sounds and in their sound they can be divided into subclasses. As is often the case in real life, many phenomena have signs of many classes and an unambiguous classification is very difficult. Consonants in this case are no exception. Their division into classes depends on the language in question and the phonetic theory used. We consider the most general classification, consisting of three main groups:
- fricative consonants
- occlusive consonants
- sound consonants
Fricative consonants are formed by the "friction" of the air flow on the narrowing of the vocal tract and the obstacles in the path of the air. These restrictions and obstacles can be created by sky, tongue, teeth, lips, etc (sounds F, X, W, C ...). The cavities of the vocal tract in this case occupy a certain (conditionally) fixed position. Contractions and obstacles cause local changes in airflow pressure, which in turn creates turbulence zones. The turbulent noise generated in this way is no longer white - it has a color
The generated noise signal, as in the case of vowel sounds, passes through a certain number of acoustic filters (vocal tract chambers), which give this noise some characteristic spectral shape and sound.
Strong consonants are formed by complete overlap of the vocal tract by any organ of articulation with an open glottis. At the same time, the air coming from the lungs through the open glottis, injects pressure and with an abrupt disconnection of the obstacle creates an “explosive” sound (sounds K, P, T ...). For example, when pronouncing the sound “P”, a person closes his lips, but the lungs continue to exert pressure. Then the lips abruptly open and the hopping drop created in the pressure generates the familiar sound “P”. The image in the time domain is shown below:
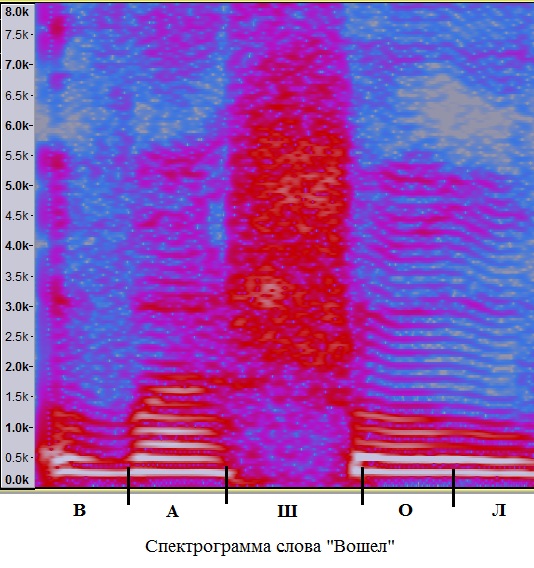
It should be noted that all three attempts at the pronunciation of sound are significantly different from each other in the time domain. Moreover, it is very difficult to distinguish them by ear.
An example of a spectrogram of a word with several noisy sounds is shown below.
Also, it should be noted that both fricative and stop consonants can be “voiced”. “Voiced” consonants are, by their nature, mixed sounds, formed by pronouncing a consonant sound simultaneously with the operation of the vocal cords. For example, if you perform the actions described when you pronounce the sound “P” and add the work of the vocal cords, you get the sound “B”. However, it cannot be argued that they are a simple superposition of some vowel and some consonant sound in the time domain. You can’t just take a sound “C”, fold it with a recorded sound “E” and get the sound “H” at the output. Definitely, one can only say that voiced consonants are formed with the help of a voiced excitation signal.
In a separate group, it is customary to single out sonorous consonants that do not contain strong turbulent noise, since when they are pronounced an additional passage is created for the air (L, R, M, N, Y). However, some obstacle is still created (tongue, tongue + teeth, tongue + sky), because of this:
- many harmonics from the initial harmonic series are significantly attenuated
- in general, the energy of the spoken sound decreases
- There are some noise sounds.
Sounds “M” and “H” are nasal - a significant obstacle is created in the mouth, and the nasopharynx is completely open to the passage of air. The oral cavity in this case is an additional resonant cavity, and the nasal cavity becomes the main emitter of sound. The sound "P" refers to the group of so-called "yeast" sounds. Sonoric sounds with their spectrum quite strongly resemble vowel sounds. Looking at the spectrogram, their short-term appearances can be hard to isolate, especially when they are transformed into vowel sounds. The sounds of “L”, “P”, “Y” are considered by many authors to be semi-public because of the possibility to distinguish bright dominant formants in their composition.
It is necessary to say a few words about the calls and transitional sounds. Their education is connected with the fact that the organs of articulation of a person in continuous speech cannot take and instantly change their position. This process occurs smoothly in time. In phonetics, it is customary to distinguish three stages of pronouncing a separate sound: excursion, endurance, and recursion. During the tour, the articulation organs take the initial position necessary for the formation of sound. During exposure, the sound itself is pronounced. During recursion, the organs either come to rest or are rearranged to begin pronouncing the next sound — the recursion of one sound is superimposed on a tour of the other. Such a co-articulation affects a lot of overtones, which, as a rule, are not entered into alphabets, but may well be classified and highlighted in the voice signal (unfortunately, not always automatically). As an illustration, one can cite the spectra of the sound “P”
The difference between the pronunciation of the sound "P" can be seen with the naked eye. At the moment of opening the lips, the vocal tract has already taken a position to pronounce the softened “E”, which affected the pronunciation of “P”. Such metamorphoses occur with almost all consonant sounds — their position relative to vowel sounds significantly affects their “appearance” and sound.
Some facts about vowels and consonants:
1. Vowel sounds have a harmonic nature and a clearly defined formant structure. Consonants have a noise nature, but may have a pronounced harmonic component (picture below, sounds “B”, “L”).
2. Vowel sounds carry a greater amount of energy than consonants, its main part (1st and 2nd formant) lie in the range from 400 to 3000 Hz. Consonants have significantly less energy. In a large part of consonant sounds, a significant part of this energy is concentrated in the region of 2-10 KHz. One example is shown below:
3. Vowel sounds have, on average, a longer duration than consonants (100-300 msec versus 30-100 msec, although specific exact numbers are highly dependent on the language and person)
4. Despite the lower energy and duration, consonant sounds, oddly enough, carry the basic speech information. As a visual example, you can consider a good puzzle from Rabiner:
Recover phrase
"Th_y n_t_d s_gn_f_c_nt _mpr_v_m_nts _n th_ c_mp_n_s _m_g_, ..." (they’re noted significant improvement in the company's image, ...)
vs
“A__i_u_e_ _o_a___ _a_ __a_e_ e_e__ia___ __e _a_e, ...” (Attitudes towards pay stayed is essentially the same, ...).
A speech signal with continuous speech can conditionally be considered stationary in the intervals from 5 to 100 milliseconds, depending on the features of the speaker and the spoken sound. On longer analysis intervals, the probability of a significant change in the properties of a signal increases, which may lead to inconsistency in evaluating its averaged parameters. As in any other field of signal processing, big problems can create noise interference, especially those that are harmonious and / or some similarities of formant - frequency domains with relatively high energy.
This compressed overview contains only basic information about the process of speech formation and the classification of speech sounds. Even in the very first approximation, each pronounced sound depends on a considerable number of parameters, individual for each individual person. Accurate measurement of these physiological parameters is not always possible even with modern medical devices. If you set a goal to get the most realistic sound of the processed signal, many of these parameters must be assessed anyway and the only way is to search for optimal values. Such an approach almost always introduces artifacts into the reconstructed speech signal, sometimes more, sometimes less audible. If you still complicate your life and set the task of voice processing in real time, then the search for these optimal values is possible only by processing the incoming signal, so to speak, “on the go”, which also cannot but affect the final sound.
The next article will give an overview of the main toolkit, which helps in one way or another to solve many problems - briefly will be considered a model of the speech signal. It will also show what parameters of these models can be adjusted during resynthesis to change the output sound.
___________
Used Books:
[1] I. Aldoshina, Fundamentals of psychoacoustics, collection of articles.
[2] LR Rabiner, B.-H. Juang, Fundamentals of Speech Recognition
[3] LR Rabiner, RW Schafer, Digital Processing of Speech Signals
[4] V.N. Sorokin, Speech Synthesis
[5] www.phys.unsw.edu.au/jw/glottis-vocal-tract-voice.html
Source: https://habr.com/ru/post/203946/
All Articles