About private "clouds": what and how is usually done in Russia, educational program and the main problems
My work is designing solutions in the field of virtualization and the introduction of private "clouds" for Russian companies. To begin with, that in general is such a private "cloud":
Why do you need it? There are four reasons to practice:
Now let's see how this is usually done and what are the rakes. Yes, and below there is still a free invitation to a seminar about the practice of building them.
As a rule, these are large companies that are already quite mature in processes. They have already implemented a service approach, but you need to automate all this with a private “cloud”. Service approach is when each part of the IT-sphere is considered as a service for the user. For example, you need a virtual machine - just given another instance with the necessary rights and settings. Centralized and unified. And so on.
As a rule, IT departments are the first to understand that they need their own “cloud”. Usually it happens like this: they raise virtual machines on demand for themselves, colleagues, contractors (by the way, giving the contractor access to their infrastructure is one of the most frequent tasks). At some point, it becomes clear that you need to do the platform - PaaS - and then it all comes to SaaS, when the necessary operation is done almost by the user in one click. In parallel, all these processes are described and their value is pretended. What for? Because knowing the savings, it is much easier to prove to the leadership the need for such a decision. Appear clear for business money. For example, a mailbox costs so much, next year there will be so many new users, and so on. There is a major factor - the price. And, believe me, many people are very happy about the transition to the language of money instead of the language of the "shamans" of the usual IT department.
')
One of the main services for large companies is the automation of the provision of environments for different development . Test environments are required for almost every large project, because, for example, in the oil and gas, banking or telecom environments you cannot test something new on “dry” data. It is necessary to drive, for example, on the yesterday's impression of the base in a controlled environment and watch what is at the exit. When such a project is one, a certain park of servers is simply allocated, and everything chases on it.
But when there are already a dozen projects, we need virtual test environments. And need desperately. They must be deployed, configured, killed or frozen so that they do not eat resources. There are a lot of projects, it takes a lot of manual labor. There is a security issue.
When a company is ready to switch to a fully service approach to IT (and most of the companies in the West do so simply because of economic feasibility), everything that ordinary users need is configured in the private cloud. As a rule, these are mail, backup, disk space for data storage, virtual machines.
A separate issue is the power to scale. For example, for a call center with pronounced seasonal peaks (tourist or, for example, having a peak on New Year's Eve), it is logical not to buy a lot of iron and licenses for two weeks of work per year - they use virtual resources that can be easily scaled.
In Big Data (like telecom billing, calculating insurance rates, and so on) there are tasks that occur once a month and completely kill even heavy server threshers. For example, one of the calculations known to me went on the physical equipment for months, after the first virtualization cycle — a week, and now all the free resources of their “cloud” are doing exactly this counting (and do not slow down the rest of the processes) - and everything passes in days.
Suppose a bank launches a project about which it is completely incomprehensible how much resources it will take. It is not clear because a start-up inside the company is new, and no one can say - it will be 500 people, 1% of the customer base or every second customer in general. Accordingly, it is logical not to buy expensive iron on the one hand at first, but also to insure against the expected or unexpected peak - after all, it will be expensive to change the infrastructure, if that. Therefore, it is also logical to twist everything in the “cloud” here. But not in public, since we are talking about a bank and 152-FZ.
Sometimes it happens that a company does not want to deploy a “cloud” to migrate from its architecture, but not against giving services from it to its contractors or clients. In this case, a private cloud, separate from the general infrastructure, is launched, from where, for example, workplaces and access to important data can be distributed in huge advertising agencies, or from where secure access to bank clients, accounting and acquiring can be set up for bank clients.
In one large energy company, the situation was generally standard - hundreds of subsidiaries, many branches, a very complex structure of individual companies within the association. All this is served by one IT service. The guys are coping, everything is tuned for the mind, but there is one problem. Specifically, for IT services (for example, virtual machines or space on servers) you need to do calculations within the union, and for this you need to somehow invoice. And this is unrealistically difficult to do, because no one can clearly check how much resources are spent on a particular request. And predict too. As a result, they deployed and set up a private “cloud”, which allowed us to simply and transparently go to the calculations of resources for each. Considering that now everyone can take and see in real time how much and for what he should, the disputes have disappeared. Billing fair. It turned out such a good financial arbiter, allowing you to bring everything back to normal. Well, plus they then gradually began to fasten other functions to the already ready "cloud".
In our company, one of the units of calculation is processor time - for example, every project has a quota for using “cloud” resources, and does not transfer it. The quota is determined by the priority of the project. For us, this is very convenient, because it is still tied to a management system, where everything necessary is picked up right when deciding about the importance of a project.
Here’s how such a distribution might look like from a management interface:
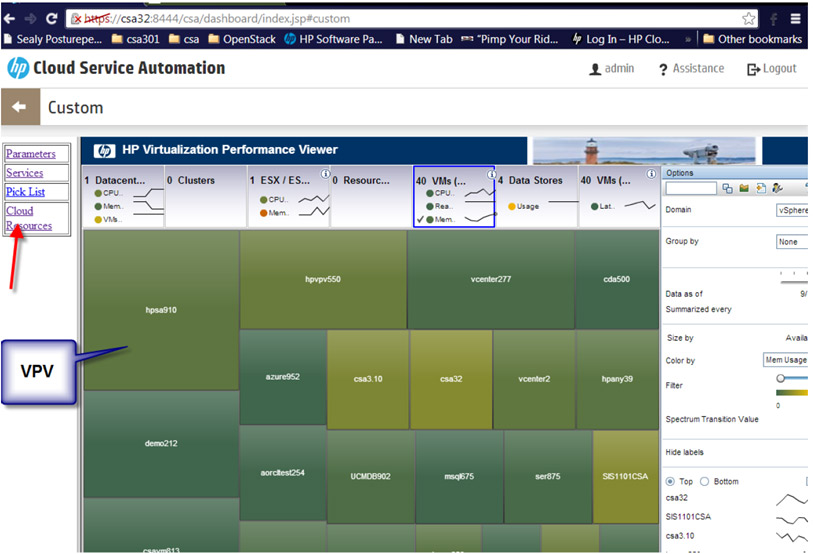
Here is an example of internal calculations:

In practice - with difficulty. The main problem I encountered is a simple misunderstanding of how everything works and what can be beneficial. It happens that they write to me from IT departments, they ask me to make a calculation so that they can show it to the management. They take their calculations, take my calculations - and only two of these pieces of paper together (so that the opinion of the employee and the external company are available) are convincing. When the decision is made, the implementation steps are:
1. First, IT services discuss what should be and how.
A catalog of services is formed, then we look at which pieces have already been implemented and which are not. For example, allocating a virtual machine on demand is a service not for the end user, but for the developer or for the contractor. Accordingly, it is automated, detailed, written SLA. Or the extension of the farm to 100 users - you need to make a connection with another part of the farm. And so on.
2. Each service is detailed.
3. Then we look at what is already there and can be used in the deployment of the “cloud”.
For example, there is a service desk system. All this is prescribed in the realities of the private "cloud".
4. Then standard things.
This is a vendor's choice, cost calculation, an exact financial plan to a penny on hardware, work, product licenses to create a “cloud”, integration.
5. Well, then, directly, work.
I'll tell you about our own experience. We, as a project company that is developing new solutions or pre-tuning boxed solutions, need a development environment and an environment for testing. Until 2006-2007, our entire laboratory consisted of iron servers, that is, in fact, for each of the projects it was necessary to form a specification, somewhere to order or find a server in the warehouse, bring them, mount them, connect. If there was a shortage of power, this is again an order, an expectation and an importation. Almost stone age.
Then VMware virtualization platforms appeared (it is important to note here that there was no de facto alternative to it at that time). We decided to purchase several powerful servers, install VMware Server on them, and make life easier for everyone. After that, it really became easier in terms of deployment speed, but not much. Because all of this was actually deployed manually, even though there were mechanisms to manage these virtual servers, our administrators still did most of the work themselves: they accepted requests, allocated computing power, and manually traced how much of a particular server is currently loaded. Often there were situations that a particular iron server was so loaded with virtuals that it was necessary to manually optimize it, transfer virtuals from server to server. All this terribly interfered with the work of project teams. They ordered a certain power, but could not get it.
Conclusion: virtualization is good, but manual control is bad. By decision of the engineer, which was taken on the principle of "half-finger-ceiling," one or another server was less loaded than the other. Just because those virtual machines that are on it are not running on it now. And to predict that now this project will enter the hot phase and all these virtuals will start, it was almost impossible. We needed a very smart engineer who could clarify plans for projects. And when there are hundreds of them at the same time, this is still a task. Many people stopped ordering virtual machines, because it was very difficult to work that way, and they ordered real hardware, by hook or by crook. But it is clear that hanging the iron server on the project is much more expensive. At times, if not by orders of magnitude.
Therefore, of course, when the opportunity to install the management platform appeared, we set it up. We chose HP, partly because we had a lot of experience with their systems, partly because of the real competitors of HP in terms of cloud management at that time was only BMC. But under our development tasks, so that users could choose their own stand parameters, HP was more suitable in terms of management flexibility. When we have automated this whole thing, you no longer need to think about where the virtual machine is spinning; it itself is transferred from one computing power to another in order to maintain the required level of performance. If any particular necessary quantum of power is exceeded, then it adds more and more. Now our engineers practically do not order iron servers.
Later, we finalized this connector management system to the public “cloud” (at Amazon and our own public “cloud” - we screwed up the option) so that we could show the customer the solution in any place where there is Internet access. CA, for example, has a direct connector to public "clouds" by default. Therefore, if someone does not want to bother for revision, in some cases, you can choose CA.
Now there are about 1000 stands in our private “cloud”, it is clear that they are not all activated, but on average, one out of every five works constantly. Servers are very different, from the point of view of the “cloud”, in fact, it is not very important which ones can be IBM Blade or HP Blade. Having connected to the “matrix” it just becomes another drop in the sea. The costs of a specific stand are now automatically, thanks to the internal billing system, falling on a specific project. Up to a penny. No more no less. And taking into account idle time, that is, if you stop a virtual machine for a while, then you don’t pay. Of course, the sky and the earth, compared to how it was before, when all the costs of the laboratory were somehow magically and completely opaque distributed among departments, areas, groups.
But let's go further.
Usually done very simply. There are predefined blocks: automation covers the infrastructure level. Everything, for the most part, is solved by installing additional units in the rack in case anything happens. If the task is not very big - then most likely the pre-delivery of servers, storage systems, a bunch together. If large - the deployment is still a farm and the organization of communication between them. Accordingly, it is easy to build forecasts like "next year we will have 30% more users, here are the costs."
At a high level, it is common, the same for a number of manufacturers. Then specific solutions are selected from both commercial and open-source implementations, there is a dialogue about details, hardware, and so on. We determine which functions are performed by which component of which manufacturer.
Here about management:
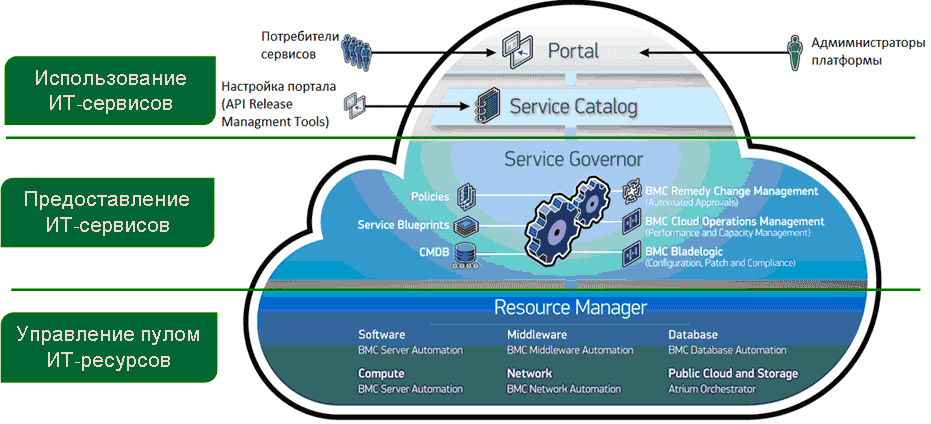
EXAMPLE OF ARCHITECTURE ON THE BMC CLOUD LIFECYCLE MANAGEMENT PLATFORM
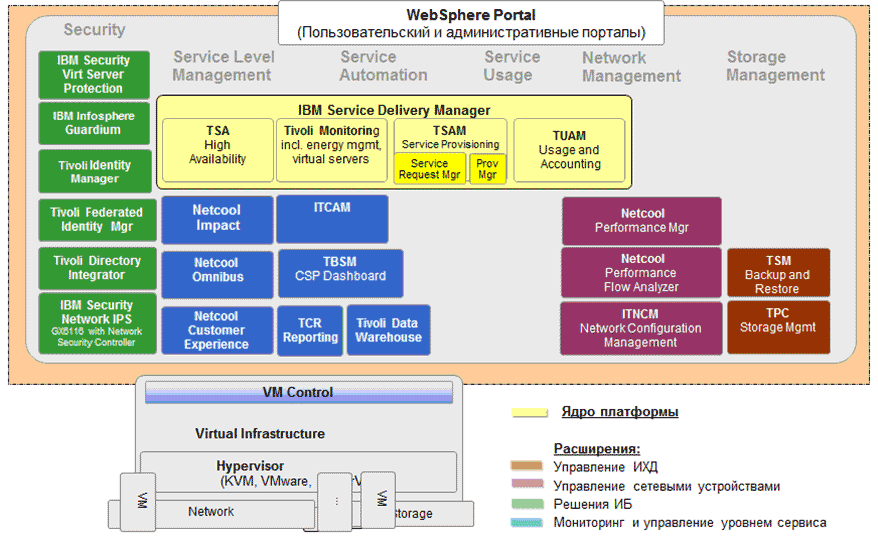
EXAMPLE ARCHITECTURE ON THE PLATFORM IBM CLOUD SERVICE PROVIDER PLATFORM (CSP2)

EXAMPLE OF ARCHITECTURE ON THE CA AUTOMATION SUITE FOR CLOUD PLATFORM
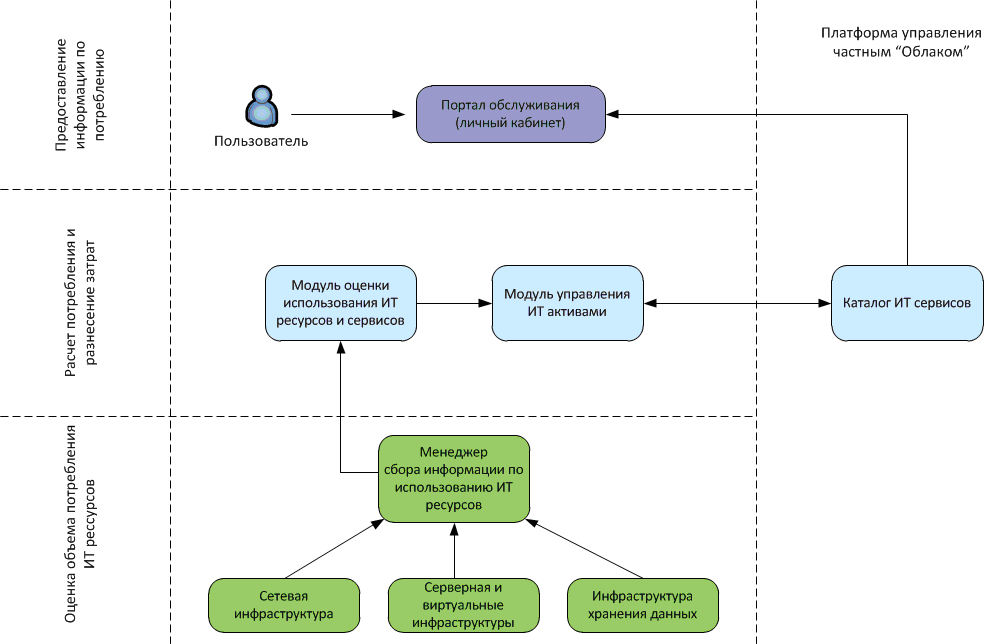
The scheme with the common components of the infrastructure of the private "cloud"
In their private cloud, customers often hone the service delivery mechanism. Then, when they understand the sensitivity of the data, they can easily use partner clouds, hybrids or public ones. For example, banks are working on important data in their own safe environment — they have the skills, new security procedures, automation, and so on. When it becomes clear that new resources are needed, and in general, their use is not a threat to IS, the resources of public clouds are used - it is simply cheaper than deploying a farm inside you.
Everything. I am ready to answer your questions in the comments or in the mail IShumovskiy@croc.ru. If this is required, I can send approximate calculations of implementation options for your situation.
If you want more practical details, tomorrow from 10:30 to 15:30 we will have a seminar in our office. We will talk in detail about the “cloud” and “cloud” ITSM architecture, about the experience of transferring the “service desk” service to the private “cloud”, about the pre-billing and resource accounting solutions, how to manage private “clouds”, which There are solutions for this and what is better to choose in this or that case, in general, about hardware and system solutions necessary for deploying a private “cloud”, about protecting “cloud” data and many more utilities. There will be a special guest from Forrester - Lauren I. Nelson, an analyst for working with specialists in the field of IT infrastructure and operations. Also promises to share some secrets. In general, come, this is a useful achivka. Sign up for free participation here .
- These are IT services in your territory.
- At the same time, these are services that have evolutionarily reached the "cloud", that is, distributed computing services.
Why do you need it? There are four reasons to practice:
- Savings on hardware: the "cloud" allows you to rotate hundreds of projects on one set of iron, while without such an infrastructure, iron would need at least three times as much. Well, in the future there is no problem with the replacement of iron.
- Savings on licenses: it so happens that license terms are often denoted not per user, but per car. And when the car is physically one, and users - 5-6, it is seriously cheaper.
- Infrastructure deployment speed requirements. From the right customized private cloud, you can easily launch a new office in the region, almost in a few minutes. Or scale without pain.
- The magic 152-FZ and a number of other standards: while it is not always possible to give your PD for processing to someone third, you need to deploy the farm at home.
Now let's see how this is usually done and what are the rakes. Yes, and below there is still a free invitation to a seminar about the practice of building them.
Who is ordering private clouds?
As a rule, these are large companies that are already quite mature in processes. They have already implemented a service approach, but you need to automate all this with a private “cloud”. Service approach is when each part of the IT-sphere is considered as a service for the user. For example, you need a virtual machine - just given another instance with the necessary rights and settings. Centralized and unified. And so on.
The very first customer - IT departments
As a rule, IT departments are the first to understand that they need their own “cloud”. Usually it happens like this: they raise virtual machines on demand for themselves, colleagues, contractors (by the way, giving the contractor access to their infrastructure is one of the most frequent tasks). At some point, it becomes clear that you need to do the platform - PaaS - and then it all comes to SaaS, when the necessary operation is done almost by the user in one click. In parallel, all these processes are described and their value is pretended. What for? Because knowing the savings, it is much easier to prove to the leadership the need for such a decision. Appear clear for business money. For example, a mailbox costs so much, next year there will be so many new users, and so on. There is a major factor - the price. And, believe me, many people are very happy about the transition to the language of money instead of the language of the "shamans" of the usual IT department.
')
Big headache is test environments.
One of the main services for large companies is the automation of the provision of environments for different development . Test environments are required for almost every large project, because, for example, in the oil and gas, banking or telecom environments you cannot test something new on “dry” data. It is necessary to drive, for example, on the yesterday's impression of the base in a controlled environment and watch what is at the exit. When such a project is one, a certain park of servers is simply allocated, and everything chases on it.
But when there are already a dozen projects, we need virtual test environments. And need desperately. They must be deployed, configured, killed or frozen so that they do not eat resources. There are a lot of projects, it takes a lot of manual labor. There is a security issue.
Company Infrastructure
When a company is ready to switch to a fully service approach to IT (and most of the companies in the West do so simply because of economic feasibility), everything that ordinary users need is configured in the private cloud. As a rule, these are mail, backup, disk space for data storage, virtual machines.
A separate issue is the power to scale. For example, for a call center with pronounced seasonal peaks (tourist or, for example, having a peak on New Year's Eve), it is logical not to buy a lot of iron and licenses for two weeks of work per year - they use virtual resources that can be easily scaled.
Peak tasks
In Big Data (like telecom billing, calculating insurance rates, and so on) there are tasks that occur once a month and completely kill even heavy server threshers. For example, one of the calculations known to me went on the physical equipment for months, after the first virtualization cycle — a week, and now all the free resources of their “cloud” are doing exactly this counting (and do not slow down the rest of the processes) - and everything passes in days.
Then come the new projects.
Suppose a bank launches a project about which it is completely incomprehensible how much resources it will take. It is not clear because a start-up inside the company is new, and no one can say - it will be 500 people, 1% of the customer base or every second customer in general. Accordingly, it is logical not to buy expensive iron on the one hand at first, but also to insure against the expected or unexpected peak - after all, it will be expensive to change the infrastructure, if that. Therefore, it is also logical to twist everything in the “cloud” here. But not in public, since we are talking about a bank and 152-FZ.
SaaS for customers
Sometimes it happens that a company does not want to deploy a “cloud” to migrate from its architecture, but not against giving services from it to its contractors or clients. In this case, a private cloud, separate from the general infrastructure, is launched, from where, for example, workplaces and access to important data can be distributed in huge advertising agencies, or from where secure access to bank clients, accounting and acquiring can be set up for bank clients.
Unusual case
In one large energy company, the situation was generally standard - hundreds of subsidiaries, many branches, a very complex structure of individual companies within the association. All this is served by one IT service. The guys are coping, everything is tuned for the mind, but there is one problem. Specifically, for IT services (for example, virtual machines or space on servers) you need to do calculations within the union, and for this you need to somehow invoice. And this is unrealistically difficult to do, because no one can clearly check how much resources are spent on a particular request. And predict too. As a result, they deployed and set up a private “cloud”, which allowed us to simply and transparently go to the calculations of resources for each. Considering that now everyone can take and see in real time how much and for what he should, the disputes have disappeared. Billing fair. It turned out such a good financial arbiter, allowing you to bring everything back to normal. Well, plus they then gradually began to fasten other functions to the already ready "cloud".
In our company, one of the units of calculation is processor time - for example, every project has a quota for using “cloud” resources, and does not transfer it. The quota is determined by the priority of the project. For us, this is very convenient, because it is still tied to a management system, where everything necessary is picked up right when deciding about the importance of a project.
Here’s how such a distribution might look like from a management interface:
Here is an example of internal calculations:
How does a private cloud come about?
In practice - with difficulty. The main problem I encountered is a simple misunderstanding of how everything works and what can be beneficial. It happens that they write to me from IT departments, they ask me to make a calculation so that they can show it to the management. They take their calculations, take my calculations - and only two of these pieces of paper together (so that the opinion of the employee and the external company are available) are convincing. When the decision is made, the implementation steps are:
1. First, IT services discuss what should be and how.
A catalog of services is formed, then we look at which pieces have already been implemented and which are not. For example, allocating a virtual machine on demand is a service not for the end user, but for the developer or for the contractor. Accordingly, it is automated, detailed, written SLA. Or the extension of the farm to 100 users - you need to make a connection with another part of the farm. And so on.
2. Each service is detailed.
3. Then we look at what is already there and can be used in the deployment of the “cloud”.
For example, there is a service desk system. All this is prescribed in the realities of the private "cloud".
4. Then standard things.
This is a vendor's choice, cost calculation, an exact financial plan to a penny on hardware, work, product licenses to create a “cloud”, integration.
5. Well, then, directly, work.
Implementation example
I'll tell you about our own experience. We, as a project company that is developing new solutions or pre-tuning boxed solutions, need a development environment and an environment for testing. Until 2006-2007, our entire laboratory consisted of iron servers, that is, in fact, for each of the projects it was necessary to form a specification, somewhere to order or find a server in the warehouse, bring them, mount them, connect. If there was a shortage of power, this is again an order, an expectation and an importation. Almost stone age.
Then VMware virtualization platforms appeared (it is important to note here that there was no de facto alternative to it at that time). We decided to purchase several powerful servers, install VMware Server on them, and make life easier for everyone. After that, it really became easier in terms of deployment speed, but not much. Because all of this was actually deployed manually, even though there were mechanisms to manage these virtual servers, our administrators still did most of the work themselves: they accepted requests, allocated computing power, and manually traced how much of a particular server is currently loaded. Often there were situations that a particular iron server was so loaded with virtuals that it was necessary to manually optimize it, transfer virtuals from server to server. All this terribly interfered with the work of project teams. They ordered a certain power, but could not get it.
Conclusion: virtualization is good, but manual control is bad. By decision of the engineer, which was taken on the principle of "half-finger-ceiling," one or another server was less loaded than the other. Just because those virtual machines that are on it are not running on it now. And to predict that now this project will enter the hot phase and all these virtuals will start, it was almost impossible. We needed a very smart engineer who could clarify plans for projects. And when there are hundreds of them at the same time, this is still a task. Many people stopped ordering virtual machines, because it was very difficult to work that way, and they ordered real hardware, by hook or by crook. But it is clear that hanging the iron server on the project is much more expensive. At times, if not by orders of magnitude.
Therefore, of course, when the opportunity to install the management platform appeared, we set it up. We chose HP, partly because we had a lot of experience with their systems, partly because of the real competitors of HP in terms of cloud management at that time was only BMC. But under our development tasks, so that users could choose their own stand parameters, HP was more suitable in terms of management flexibility. When we have automated this whole thing, you no longer need to think about where the virtual machine is spinning; it itself is transferred from one computing power to another in order to maintain the required level of performance. If any particular necessary quantum of power is exceeded, then it adds more and more. Now our engineers practically do not order iron servers.
Later, we finalized this connector management system to the public “cloud” (at Amazon and our own public “cloud” - we screwed up the option) so that we could show the customer the solution in any place where there is Internet access. CA, for example, has a direct connector to public "clouds" by default. Therefore, if someone does not want to bother for revision, in some cases, you can choose CA.
Now there are about 1000 stands in our private “cloud”, it is clear that they are not all activated, but on average, one out of every five works constantly. Servers are very different, from the point of view of the “cloud”, in fact, it is not very important which ones can be IBM Blade or HP Blade. Having connected to the “matrix” it just becomes another drop in the sea. The costs of a specific stand are now automatically, thanks to the internal billing system, falling on a specific project. Up to a penny. No more no less. And taking into account idle time, that is, if you stop a virtual machine for a while, then you don’t pay. Of course, the sky and the earth, compared to how it was before, when all the costs of the laboratory were somehow magically and completely opaque distributed among departments, areas, groups.
But let's go further.
Scaling
Usually done very simply. There are predefined blocks: automation covers the infrastructure level. Everything, for the most part, is solved by installing additional units in the rack in case anything happens. If the task is not very big - then most likely the pre-delivery of servers, storage systems, a bunch together. If large - the deployment is still a farm and the organization of communication between them. Accordingly, it is easy to build forecasts like "next year we will have 30% more users, here are the costs."
Architecture
At a high level, it is common, the same for a number of manufacturers. Then specific solutions are selected from both commercial and open-source implementations, there is a dialogue about details, hardware, and so on. We determine which functions are performed by which component of which manufacturer.
Here about management:
EXAMPLE OF ARCHITECTURE ON THE BMC CLOUD LIFECYCLE MANAGEMENT PLATFORM
EXAMPLE ARCHITECTURE ON THE PLATFORM IBM CLOUD SERVICE PROVIDER PLATFORM (CSP2)
EXAMPLE OF ARCHITECTURE ON THE CA AUTOMATION SUITE FOR CLOUD PLATFORM
The scheme with the common components of the infrastructure of the private "cloud"
Transition to hybrids and public "clouds"
In their private cloud, customers often hone the service delivery mechanism. Then, when they understand the sensitivity of the data, they can easily use partner clouds, hybrids or public ones. For example, banks are working on important data in their own safe environment — they have the skills, new security procedures, automation, and so on. When it becomes clear that new resources are needed, and in general, their use is not a threat to IS, the resources of public clouds are used - it is simply cheaper than deploying a farm inside you.
Questions
Everything. I am ready to answer your questions in the comments or in the mail IShumovskiy@croc.ru. If this is required, I can send approximate calculations of implementation options for your situation.
If you want more practical details, tomorrow from 10:30 to 15:30 we will have a seminar in our office. We will talk in detail about the “cloud” and “cloud” ITSM architecture, about the experience of transferring the “service desk” service to the private “cloud”, about the pre-billing and resource accounting solutions, how to manage private “clouds”, which There are solutions for this and what is better to choose in this or that case, in general, about hardware and system solutions necessary for deploying a private “cloud”, about protecting “cloud” data and many more utilities. There will be a special guest from Forrester - Lauren I. Nelson, an analyst for working with specialists in the field of IT infrastructure and operations. Also promises to share some secrets. In general, come, this is a useful achivka. Sign up for free participation here .
Source: https://habr.com/ru/post/203466/
All Articles