How Stack Overflow Works - Iron
I would like to say that Stack Overflow is a large-scale project, but it is not. I mean, we have achieved a lot, but I cannot call our project “big”, it is still early. Let me give you an example of some numbers - how much we are dealing with right now. Statistics slice for 24 hours from November 12, 2013. This is a normal weekday. I note that information is presented here only on our own computing power, without a CDN.

I will definitely need to write a post about how we get these numbers, but these statistics (except for traffic) are calculated only thanks to HTTP logs. How did it happen so many hours per day? We call it magic. Most people call this “multiple servers with multi-core processors,” but we write off everything as magic. Stack Exchange runs on the following hardware:
')
How all this beauty looks can be seen in the first photo (above).
We are not just hosting our sites. The nearest desk is a server for virtualization (vmware) and supporting infrastructure that does not directly affect the service, for example, deployment machines, domain controllers, monitoring, an additional database for administrators, and so on. 2 SQL servers from the list above were backup servers until recently - now they are used for read-only queries, so that we can continue to scale without thinking about the load on the database for a long time. 2 web servers from that list are intended for development and peripheral tasks; therefore, they consume little traffic.
If we imagine at the moment that something happened and all the redundancy of the infrastructure disappeared, then the whole Stack Exchange can work on the following equipment without loss of performance:
We will need to try to disable some of the servers specifically to test it out. :)
Below is the average hardware configuration:
It seems that 20Gbps is too much? Yes, for example, SQL servers do not load the network more than 100–200 Mbit / s at peak, but do not forget about backup, rebuilding the topology - this can be needed at any time and then the network will be fully utilized. Such amount of memory and SSD will be able to download this channel completely.
We currently have about 2 TB of data in SQL (1.06 / 1.16 TB on the first cluster of 18 SSDs and 0.889 / 1.45 TB on the second, consisting of 4 SSDs). Perhaps it would be worth thinking about the clouds, but now we use SSD and the recording time in the database is literally 0 milliseconds. With a database in memory and two cache levels in front of it, Stack Overflow has a read-to-write ratio of 40 to 60. Yes, that's right, she writes 60% of the database time.
Web servers use 320 GB SSDs in RAID1.
ElasticSearch servers are also equipped with 300 GB SSD disks. This is important, as there is often rewriting and indexing.
We also did not mention the SAN. This is a DELL Equal Logic PS6110X with 24 SAS 10K disks and a 2x10 Gbps connection. It is used as storage for virtual servers VmWare as a cloud and is not associated with the site itself. If this server crashes, sites will not even know about it for a while.
What are we going to do about it? We want more performance - this is very important for us. On November 12, the page loaded an average of 28 milliseconds. We try to keep the download speed no longer than 50 milliseconds. Here are the average statistics for downloading popular pages on this day:
We monitor download speeds by recording timings. Due to this, we can make a very visual schedule:
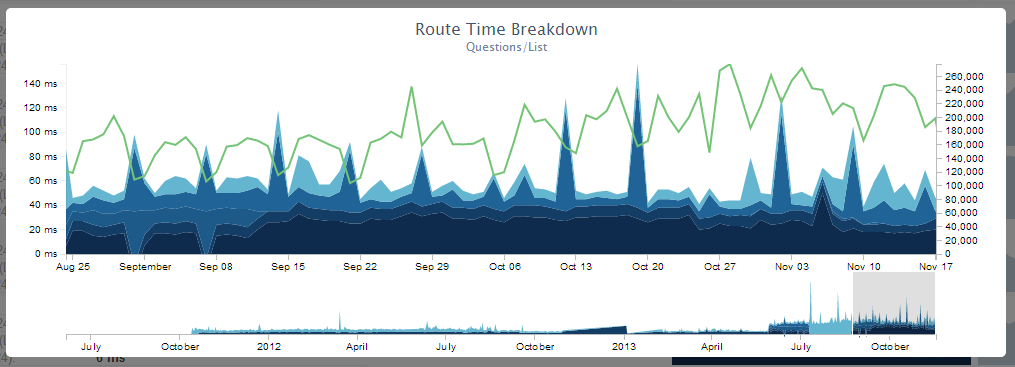
Obviously, all services are now running at low load. Web servers consume an average of 5-15% of the processor, 15.5 GB of RAM, and 20-40 MB / s of network bandwidth. The average processor load of the database server is 5-10%, 365 GB of RAM and 100-200 Mbit / s of network bandwidth. Due to this, we can fully develop and, which is very important, we are insured against a fall in case of an increase in load - an error in the code or any other failure.
Here is a screenshot of the Opserver:
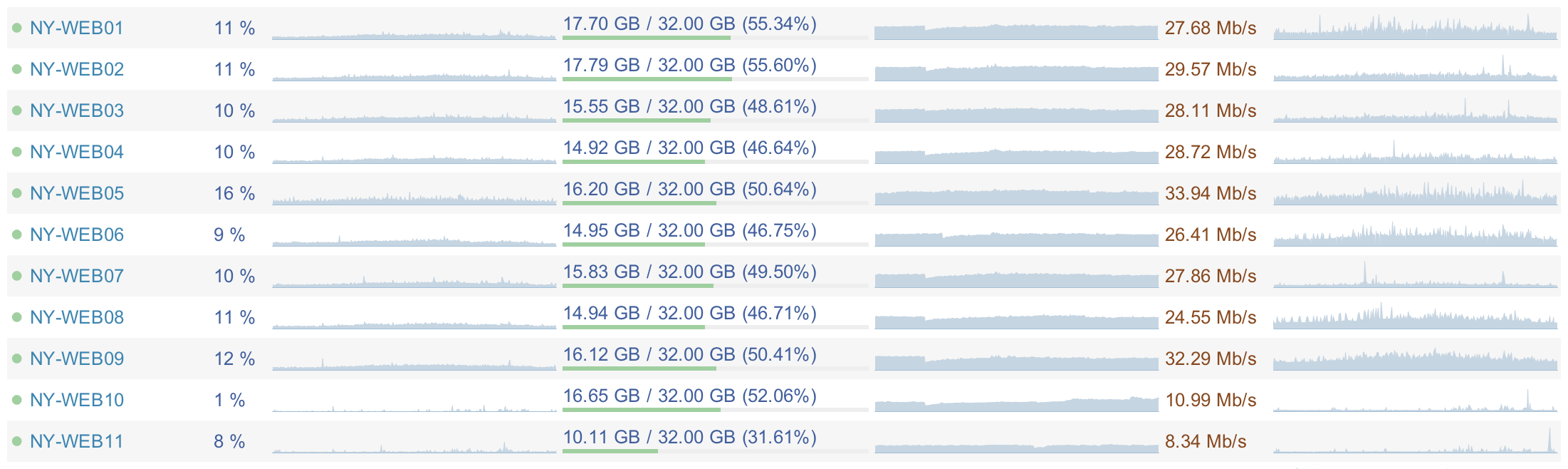
The main reason that the load is so low is the efficiency of the code. Let the post and is devoted to another, but the effective code - a critical place to scale your hardware in the future. Everything that you did, but did not have to do, will cost you more than if you did not do it at all - a similar rule applies to inefficient code. Cost is understood as the following: power consumption, hardware cost (because you need more servers, or they need to be more powerful), developers who are trying to grasp more complex code (although, to be honest, optimized code doesn't necessarily become easier) and most likely a slow render pages - which is expressed in the reaction of the user who will not wait for the download of another page ... or even no longer go to you. The price of an ineffective code can be much higher than you think.
So, today we met with the way Stack Overflow works on the current hardware. Next time we will find out why we are not in a hurry to move to the clouds.
Statistics
- 148,084,883 HTTP requests to our load balancer
- 36,095,312 of them are real page loads
- 833,992,982,627 bytes (776 GB) HTTP traffic sent
- 286,574,644,032 bytes (267 GB) of traffic received
- 1,125,992,557,312 bytes (1,048 GB) of traffic sent
- 334,572,103 SQL requests for HTTP requests
- 412,865,051 request to Redis servers
- 3,603,418 requests to tag handler (separate service)
- 558,224,585 ms (155 hours) was spent on processing SQL queries
- 99,346,916 ms (27 hours) took to wait for a response from the Redis servers
- 132,384,059 ms (36 hours) passed to process requests by tags
- 2,728,177,045 ms (757 hours) ASP.Net scripts worked
I will definitely need to write a post about how we get these numbers, but these statistics (except for traffic) are calculated only thanks to HTTP logs. How did it happen so many hours per day? We call it magic. Most people call this “multiple servers with multi-core processors,” but we write off everything as magic. Stack Exchange runs on the following hardware:
')
- 4 MS SQL servers
- 11 IIS Web Servers
- 2 Redis servers
- 3 servers processing tags (absolutely everything related to tags, for example, query / questions / tagged / c ++ )
- 3 ElasticSearch servers
- 2 load balancers (implementation of HAProxy )
- 2 switches (each based on Nexus 5596 + Fabric Extenders )
- 2 Cisco 5525-X ASAs Firewall
- 2 Cisco 3945 Router
How all this beauty looks can be seen in the first photo (above).
We are not just hosting our sites. The nearest desk is a server for virtualization (vmware) and supporting infrastructure that does not directly affect the service, for example, deployment machines, domain controllers, monitoring, an additional database for administrators, and so on. 2 SQL servers from the list above were backup servers until recently - now they are used for read-only queries, so that we can continue to scale without thinking about the load on the database for a long time. 2 web servers from that list are intended for development and peripheral tasks; therefore, they consume little traffic.
About equipment
If we imagine at the moment that something happened and all the redundancy of the infrastructure disappeared, then the whole Stack Exchange can work on the following equipment without loss of performance:
- 2 SQL servers (Stack Overflow on one machine, everything else on another, although we are sure that they can work on one server)
- 2 Web servers (maybe three, but I believe that two will suffice)
- 1 Redis server
- 1 tag server
- 1 ElasticSearch server
- 1 load balancer
- 1 switch
- 1 ASA firewall
- 1 router
We will need to try to disable some of the servers specifically to test it out. :)
Below is the average hardware configuration:
- SQL servers run 384 GB of RAM with 1.8TB file storage (SSD)
- Redis servers run on machines with 96 GB of RAM
- ElasticSearch Servers - 196 GB of RAM
- Tag processing servers require the fastest processors we can get.
- Switches - 10 Gbps for each port.
- The web server is nothing special - 32 GB of RAM, 2 quad-core processors and 300 GB SSD storage for each.
- Servers that do not have a 2x10 Gbit / s network (for example, SQL) are connected by four connections of 1 Gbit / s each.
It seems that 20Gbps is too much? Yes, for example, SQL servers do not load the network more than 100–200 Mbit / s at peak, but do not forget about backup, rebuilding the topology - this can be needed at any time and then the network will be fully utilized. Such amount of memory and SSD will be able to download this channel completely.
Storage
We currently have about 2 TB of data in SQL (1.06 / 1.16 TB on the first cluster of 18 SSDs and 0.889 / 1.45 TB on the second, consisting of 4 SSDs). Perhaps it would be worth thinking about the clouds, but now we use SSD and the recording time in the database is literally 0 milliseconds. With a database in memory and two cache levels in front of it, Stack Overflow has a read-to-write ratio of 40 to 60. Yes, that's right, she writes 60% of the database time.
Web servers use 320 GB SSDs in RAID1.
ElasticSearch servers are also equipped with 300 GB SSD disks. This is important, as there is often rewriting and indexing.
We also did not mention the SAN. This is a DELL Equal Logic PS6110X with 24 SAS 10K disks and a 2x10 Gbps connection. It is used as storage for virtual servers VmWare as a cloud and is not associated with the site itself. If this server crashes, sites will not even know about it for a while.
What's next?
What are we going to do about it? We want more performance - this is very important for us. On November 12, the page loaded an average of 28 milliseconds. We try to keep the download speed no longer than 50 milliseconds. Here are the average statistics for downloading popular pages on this day:
- Question pages with answers - 28 milliseconds (29.7 million requests)
- User Profiles - 39 milliseconds (1.7 mil. Requests)
- The list of questions - 78 milliseconds (1.1 million queries)
- The home page is 65 milliseconds (1 million requests), which is very slow. We will fix it soon.
We monitor download speeds by recording timings. Due to this, we can make a very visual schedule:
Scalability in the future
Obviously, all services are now running at low load. Web servers consume an average of 5-15% of the processor, 15.5 GB of RAM, and 20-40 MB / s of network bandwidth. The average processor load of the database server is 5-10%, 365 GB of RAM and 100-200 Mbit / s of network bandwidth. Due to this, we can fully develop and, which is very important, we are insured against a fall in case of an increase in load - an error in the code or any other failure.
Here is a screenshot of the Opserver:
The main reason that the load is so low is the efficiency of the code. Let the post and is devoted to another, but the effective code - a critical place to scale your hardware in the future. Everything that you did, but did not have to do, will cost you more than if you did not do it at all - a similar rule applies to inefficient code. Cost is understood as the following: power consumption, hardware cost (because you need more servers, or they need to be more powerful), developers who are trying to grasp more complex code (although, to be honest, optimized code doesn't necessarily become easier) and most likely a slow render pages - which is expressed in the reaction of the user who will not wait for the download of another page ... or even no longer go to you. The price of an ineffective code can be much higher than you think.
So, today we met with the way Stack Overflow works on the current hardware. Next time we will find out why we are not in a hurry to move to the clouds.
Source: https://habr.com/ru/post/203406/
All Articles