Computer vision. Lecture for the Small ShAD Yandex
The scope of computer vision is very wide: from barcode readers in supermarkets to augmented reality. In this lecture you will learn where computer vision is used and how it works, how images look in numbers, what tasks in this area are solved relatively easily, which are difficult, and why.
The lecture is designed for high school students - students of the Small ShAD, but adults will be able to learn a lot from it.
')
The ability to see and recognize objects is a natural and familiar opportunity for a person. However, for the computer so far - this is an extremely difficult task. Attempts are being made to teach the computer at least a fraction of what a person uses every day, without even noticing it.
Probably the most common person meets with computer vision at the checkout in the supermarket. Of course, we are talking about reading barcodes. They were specifically designed in such a way as to simplify the computer reading process. But there are more complex tasks: reading car numbers, analyzing medical images, manufacturing flaw detection, facial recognition, etc. The use of computer vision to create augmented reality systems is actively developing.
The child learns to recognize objects gradually. He begins to realize how the shape of an object changes depending on its position and lighting. In the future, when recognizing objects, a person is guided by previous experience. During his life, a person accumulates a huge amount of information, the process of learning a neural network does not stop for a second. For a person, it is not particularly difficult to restore the perspective from a flat picture and imagine what it would all look like in three dimensions.
Computer all this is given much more complicated. And primarily because of the problem of accumulation of experience. It is necessary to collect a huge number of examples, which so far is not very successful.
In addition, when recognizing an object, a person always takes into account the environment. If you pull an object out of its usual environment, it will become much more difficult to recognize it. Here, too, plays the role of life experience, which the computer does not have.
Imagine that we need to learn at a glance to determine the sex of a person (dressed!) From a photograph. First you need to identify the factors that may indicate belonging to a particular object. In addition, you need to collect a training set. It is desirable that it be representative. In our case, we take as a training sample of all those present in the audience. And we will try to find distinctive factors based on them: for example, hair length, presence of a beard, make-up and clothes (skirt or trousers). Knowing what percentage of people of the same sex met certain factors, we will be able to create quite clear rules: the presence of messes or other combinations of factors will, with some probability, allow us to tell which sex a person is in the photo.
Of course, this is a very simple and conditional example with a small number of high-level factors. In real tasks that are put in front of computer vision systems, there are much more factors. Determining them manually and calculating dependencies is an impossible task for humans. Therefore, in such cases, machine learning is indispensable. For example, you can define several dozen initial factors, as well as set positive and negative examples. And already the dependencies between these factors are selected automatically, a formula is drawn up that allows you to make decisions. Quite often, the factors themselves are allocated automatically.
Most commonly, RGB is used to store digital images. In it, each of the three axes (channels) is assigned its own color: red, green, and blue. Each channel is allocated 8 bits of information, respectively, the color intensity on each axis can take values in the range from 0 to 255. All colors in the RGB digital space are obtained by mixing the three primary colors.

Unfortunately, RGB is not always well suited for analyzing information. Experiments show that the geometric proximity of colors is rather far from how a person perceives the proximity of certain colors to each other.
But there are other color spaces. Very interesting in our context is the HSV space (Hue, Saturation, Value). It has a Value axis that indicates the amount of light. A separate channel is allocated to it, unlike RGB, where this value needs to be calculated each time. In fact, this is a black and white version of the image, with which you can already work. Hue is represented as an angle and is responsible for the basic tone. Color saturation depends on the value of Saturation (distance from center to edge).

HSV is much closer to how we envision colors. If you show a person in the dark red and green object, he can not distinguish colors. The same happens in HSV. The lower we move along the V axis, the smaller the difference between hues becomes, as the range of saturation values decreases. In the diagram, it looks like a cone, on top of which is an extremely black dot.
Why is it important to have data on the amount of light? In most cases, in computer vision, color does not matter, as it does not carry any important information. Let's look at two pictures: color and black and white. Finding all the objects on the black and white version is not much more difficult than on color. In this case, the color does not carry any additional load for us, and there are a great many computational problems. When we work with a color version of the image, the amount of data, roughly speaking, is raised to the power of the cube.

Color is used only in rare cases, when it on the contrary allows to simplify calculations. For example, when you need to detect a face: it is easier to first find its possible location in the picture, focusing on the range of skin tone. This eliminates the need to analyze the entire image.
The signs with the help of which we analyze the image are local and global. Looking at this picture, most will say that it shows a red car:

Such a response implies that the person selected an object on the image, and therefore, described a local color attribute. By and large, the picture shows a forest, a road and a little car. The area of the car takes up a smaller part. But we understand that the car in this picture is the most important object. If a person is offered to find pictures similar to this one, he will first of all select images on which there is a red car.
In computer vision, this process is called detection and segmentation. Segmentation - is the division of the image into many parts, connected with each other visually or semantically. And detection is the detection of objects in the image. Detection must be clearly distinguished from recognition. Suppose you can detect a traffic sign in the same picture with a car. But it is impossible to recognize it, since it is turned to us on the other side. Also, when recognizing faces, the detector can determine the location of the face, and the “recognizer” will already tell whose face it is.

There are many different approaches to recognition.
For example, such: in the image, you first need to select interesting points or interesting places. Something different from the background: bright spots, transitions, etc. There are several algorithms to do this.
One of the most common ways is called Difference of Gaussians ( DoG ). Blurring the picture with different radius and comparing the results, you can find the most contrasting fragments. The areas around these fragments are the most interesting.
Further, these areas are described in digital form. The regions are divided into small sections, it is determined in which direction the gradients are directed, vectors are obtained.
The picture below shows what it looks like. The received data is recorded in descriptors.

In order for identical descriptors to be recognized as such regardless of rotations in the plane, they are turned so that the largest vectors are turned in one direction. This is not always done. But if you want to find two identical objects located in different planes.
Descriptors can be written in numeric form. The descriptor can be represented as a point in a multidimensional array. We have a two-dimensional array in the illustration. Our handles got into it. And we can cluster them - divided into groups.

Next, for each cluster we describe a region in space. When the descriptor gets into this area, it’s not what it was for us that matters, but which area it got into, becomes important for us. And then we can compare the images, determining how many descriptors of one image are in the same clusters as the descriptors of another image. Such clusters can be called visual words.
To find not just identical pictures, but images of similar objects, it is required to take a set of images of this object and a set of pictures in which it does not exist. Then select descriptors from them and cluster them. Next, we need to find out which clusters the descriptors from the images on which the object we need was present got into. Now we know that if the descriptors from the new image fall into the same clusters, it means that the desired object is present on it.
Matching descriptors is not a guarantee of the identity of the objects containing them. One of the ways of additional verification is geometric validation. In this case, a comparison of the location of the descriptors relative to each other.
For simplicity, let's imagine that we can break all the images into three classes: architecture, nature and portrait. In turn, we can divide nature into plants of animals and birds. And having already understood that this is a bird, we can say which one: owl, seagull or raven.
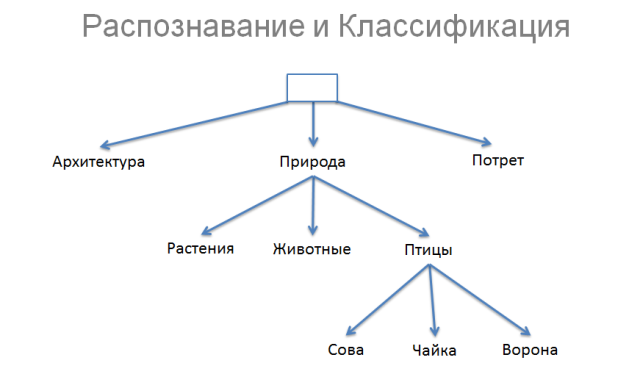
The difference between recognition and classification is rather arbitrary. If we found an owl in the picture, then this is more of a recognition. If just a bird, then this is a kind of intermediate option. And if only nature is definitely a classification. Those. the difference between recognition and classification is how deep we went through the tree. And the further the computer vision goes, the lower the line between classification and recognition will slide.
The lecture is designed for high school students - students of the Small ShAD, but adults will be able to learn a lot from it.
')
The ability to see and recognize objects is a natural and familiar opportunity for a person. However, for the computer so far - this is an extremely difficult task. Attempts are being made to teach the computer at least a fraction of what a person uses every day, without even noticing it.
Probably the most common person meets with computer vision at the checkout in the supermarket. Of course, we are talking about reading barcodes. They were specifically designed in such a way as to simplify the computer reading process. But there are more complex tasks: reading car numbers, analyzing medical images, manufacturing flaw detection, facial recognition, etc. The use of computer vision to create augmented reality systems is actively developing.
The difference between human vision and computer
The child learns to recognize objects gradually. He begins to realize how the shape of an object changes depending on its position and lighting. In the future, when recognizing objects, a person is guided by previous experience. During his life, a person accumulates a huge amount of information, the process of learning a neural network does not stop for a second. For a person, it is not particularly difficult to restore the perspective from a flat picture and imagine what it would all look like in three dimensions.
Computer all this is given much more complicated. And primarily because of the problem of accumulation of experience. It is necessary to collect a huge number of examples, which so far is not very successful.
In addition, when recognizing an object, a person always takes into account the environment. If you pull an object out of its usual environment, it will become much more difficult to recognize it. Here, too, plays the role of life experience, which the computer does not have.
Boy or girl
Imagine that we need to learn at a glance to determine the sex of a person (dressed!) From a photograph. First you need to identify the factors that may indicate belonging to a particular object. In addition, you need to collect a training set. It is desirable that it be representative. In our case, we take as a training sample of all those present in the audience. And we will try to find distinctive factors based on them: for example, hair length, presence of a beard, make-up and clothes (skirt or trousers). Knowing what percentage of people of the same sex met certain factors, we will be able to create quite clear rules: the presence of messes or other combinations of factors will, with some probability, allow us to tell which sex a person is in the photo.
Machine learning
Of course, this is a very simple and conditional example with a small number of high-level factors. In real tasks that are put in front of computer vision systems, there are much more factors. Determining them manually and calculating dependencies is an impossible task for humans. Therefore, in such cases, machine learning is indispensable. For example, you can define several dozen initial factors, as well as set positive and negative examples. And already the dependencies between these factors are selected automatically, a formula is drawn up that allows you to make decisions. Quite often, the factors themselves are allocated automatically.
Image in numbers
Most commonly, RGB is used to store digital images. In it, each of the three axes (channels) is assigned its own color: red, green, and blue. Each channel is allocated 8 bits of information, respectively, the color intensity on each axis can take values in the range from 0 to 255. All colors in the RGB digital space are obtained by mixing the three primary colors.
Unfortunately, RGB is not always well suited for analyzing information. Experiments show that the geometric proximity of colors is rather far from how a person perceives the proximity of certain colors to each other.
But there are other color spaces. Very interesting in our context is the HSV space (Hue, Saturation, Value). It has a Value axis that indicates the amount of light. A separate channel is allocated to it, unlike RGB, where this value needs to be calculated each time. In fact, this is a black and white version of the image, with which you can already work. Hue is represented as an angle and is responsible for the basic tone. Color saturation depends on the value of Saturation (distance from center to edge).
HSV is much closer to how we envision colors. If you show a person in the dark red and green object, he can not distinguish colors. The same happens in HSV. The lower we move along the V axis, the smaller the difference between hues becomes, as the range of saturation values decreases. In the diagram, it looks like a cone, on top of which is an extremely black dot.
Color and light
Why is it important to have data on the amount of light? In most cases, in computer vision, color does not matter, as it does not carry any important information. Let's look at two pictures: color and black and white. Finding all the objects on the black and white version is not much more difficult than on color. In this case, the color does not carry any additional load for us, and there are a great many computational problems. When we work with a color version of the image, the amount of data, roughly speaking, is raised to the power of the cube.
Color is used only in rare cases, when it on the contrary allows to simplify calculations. For example, when you need to detect a face: it is easier to first find its possible location in the picture, focusing on the range of skin tone. This eliminates the need to analyze the entire image.
Local and global signs
The signs with the help of which we analyze the image are local and global. Looking at this picture, most will say that it shows a red car:
Such a response implies that the person selected an object on the image, and therefore, described a local color attribute. By and large, the picture shows a forest, a road and a little car. The area of the car takes up a smaller part. But we understand that the car in this picture is the most important object. If a person is offered to find pictures similar to this one, he will first of all select images on which there is a red car.
Detection and segmentation
In computer vision, this process is called detection and segmentation. Segmentation - is the division of the image into many parts, connected with each other visually or semantically. And detection is the detection of objects in the image. Detection must be clearly distinguished from recognition. Suppose you can detect a traffic sign in the same picture with a car. But it is impossible to recognize it, since it is turned to us on the other side. Also, when recognizing faces, the detector can determine the location of the face, and the “recognizer” will already tell whose face it is.
Descriptors and visual words
There are many different approaches to recognition.
For example, such: in the image, you first need to select interesting points or interesting places. Something different from the background: bright spots, transitions, etc. There are several algorithms to do this.
One of the most common ways is called Difference of Gaussians ( DoG ). Blurring the picture with different radius and comparing the results, you can find the most contrasting fragments. The areas around these fragments are the most interesting.
Further, these areas are described in digital form. The regions are divided into small sections, it is determined in which direction the gradients are directed, vectors are obtained.
The picture below shows what it looks like. The received data is recorded in descriptors.
In order for identical descriptors to be recognized as such regardless of rotations in the plane, they are turned so that the largest vectors are turned in one direction. This is not always done. But if you want to find two identical objects located in different planes.
Descriptors can be written in numeric form. The descriptor can be represented as a point in a multidimensional array. We have a two-dimensional array in the illustration. Our handles got into it. And we can cluster them - divided into groups.
Next, for each cluster we describe a region in space. When the descriptor gets into this area, it’s not what it was for us that matters, but which area it got into, becomes important for us. And then we can compare the images, determining how many descriptors of one image are in the same clusters as the descriptors of another image. Such clusters can be called visual words.
To find not just identical pictures, but images of similar objects, it is required to take a set of images of this object and a set of pictures in which it does not exist. Then select descriptors from them and cluster them. Next, we need to find out which clusters the descriptors from the images on which the object we need was present got into. Now we know that if the descriptors from the new image fall into the same clusters, it means that the desired object is present on it.
Matching descriptors is not a guarantee of the identity of the objects containing them. One of the ways of additional verification is geometric validation. In this case, a comparison of the location of the descriptors relative to each other.
Recognition and classification
For simplicity, let's imagine that we can break all the images into three classes: architecture, nature and portrait. In turn, we can divide nature into plants of animals and birds. And having already understood that this is a bird, we can say which one: owl, seagull or raven.
The difference between recognition and classification is rather arbitrary. If we found an owl in the picture, then this is more of a recognition. If just a bird, then this is a kind of intermediate option. And if only nature is definitely a classification. Those. the difference between recognition and classification is how deep we went through the tree. And the further the computer vision goes, the lower the line between classification and recognition will slide.
Source: https://habr.com/ru/post/203136/
All Articles