Dmitry Sklyarov: “Attentiveness and some logic. How complicated is simple. ”

We continue to share with the inhabitants of Habr a summary of the speeches of the guests of the final of the Russian Code Cup 2013. Today we bring to your attention a summary of the story by Dmitry Sklyarov about reverse engineering.
Dmitry Sklyarov - Associate Professor at the Department of Information Security, Moscow State Technical University. Baumana and analyst at Positive Technologies. Works in the field of information security for over 13 years. The developer of the algorithm program Advanced eBook Processor.
Reversing is, of course, not the easiest IT discipline. However, to get the result, that is, to understand what the program does, it is not always necessary to analyze every line of code and every assembler instruction. Sometimes a series of simple logical conclusions and the ability to “think like a programmer” are enough. To understand what I mean, we will be helped by two examples of analysis taken from my practice.
What's inside the black box?
I faced the first task on CTF. CTF is a kind of olympiad programming, only for specialists in the field of information security. The task was called "Donn Beach". So, we are given:
- some software-implemented “black box” - an executable file that converts the input sequence to the output
- the value that should be output
It is necessary to determine the sequence of 12 bytes, which must be submitted to the input.
')
Obviously, this task is not solved by simple search. We need to find out what happens inside the program, what converts the input to the output, and how to select the input values to get the specified output.
Of course, at the first stage, the program is loaded into the disassembler. Here are two code snippets that he issued:


Here it is easy to notice the lines that remain from the assembly process. Most likely, these messages are specially laid by the organizers to make it easier to guess what is being said. When you look at the lines vm_set_params and vm_get_output in your head, the question immediately arises: what is vm? In this case, nothing but the virtual machine, in general, does not occur. Thus, we can immediately assume that a virtual machine is used here and, based on this, build further analysis.


We see four consecutive function calls (the points between them are just the preparation of parameters). What can stand between parameter loading and result retrieval? It is logical to assume that there is an initialization and start of the virtual machine. Let's try to disassemble the VM initialization code.
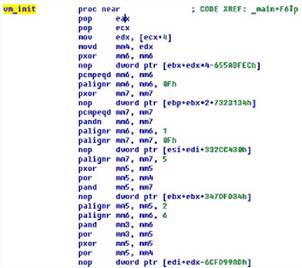
So, we look at the vm_init code, and we see a fairly large number of not quite clear operations. Despite the fact that I have been familiar with the assembly language for Intel-compatible computers for almost 20 years, I rarely have to analyze floating point instructions. Therefore, just looking at this code, without the help of a reference book, I can not say what it does. What conclusions can still be made on this code snippet?
- We work with 64-bit MMX registers
- The function code consists of 420 commands.
- Nothing is clear
Of course, you can sit down with a notepad and analyze all 420 commands, understand what each of them does, and, therefore, what happens as a result. However, it seemed to me that this is not the most effective way, and I decided to try to approach this task differently.
We have a function vm_init, which somehow loads registers from the initial data. The input is eight 32-bit values. What if we set these values to constant numbers, and mark the bytes from 00 to 1F?


It is seen that each byte was copied once. There is not a single repetition, not a single new value, and by simply coloring them with different colors, you can see which bytes are displayed.
So, we realized that the function does, without dismantling a single line, but simply by comparing the input and output. Why did I suggest that it can be done this way? Because this is logical, this is exactly what we expect from the load function of the initial state of the virtual machine.
After that, I decided to analyze what the function that I called vm_run does. In it you can see the following:
- a huge number of codes for working with multimedia registers
- when parsing the flow of commands of the virtual machine, it is clear that each command code takes 1 byte and there is 1 argument (optional)
- each byte of the command has its own processing function
- the complexity of each processing function is about the same as in vm_init (so there is not the slightest desire to disassemble it: this is a difficult and certainly not the most efficient way)
- most of the instructions are actually mapped to the same handler (this is probably the nop function)
- all processing goes in one cycle
So, we have before us the standard process of parsing commands for a virtual machine: get the command code and its arguments pointing to operands, execute through functions implementing one or another operation code, and then proceed to the next operation code.
I wrote a small debugger, but instead of looking in the debugger step by step, what the program does, I decided to trace the state of all MMX registers at each point. As a result, a log file was created in which, for each current command, the state of the VM was recorded before and after execution, as well as an operation code and one additional byte, so that the logic could be recovered knowing the operation codes.
Here's what I got:

The input to the value in the register R0 and the output it is on the stack. It is seen that the value of the register R6 decreases, and R7, on the contrary, increases.
From this we can conclude that R6 is a stack index counter, which decreases when adding data to the stack, R7 is a command pointer. In this case, the command with the operation code 0D-00 transferred the value from the zero register to the stack.

The value that was in the R4 register was again on the stack, and the command code 0D04 differs from the previous one only in the argument. From this we can assume that 0D, is the push operation code, is the placement of data on the stack, and the value in the first byte after the operation code is a pointer to the register number that will be used in this operation.

The state of registers before and after execution differ only in one register, which I called the instruction pointer (Instruction Pointer) - this means that no changes have occurred. So, we can assume that the operation code is 06 - nop, which does nothing.

In this case, the argument was the value of FF, it was on the stack, and the stack pointer decreased. It is easy to make the assumption that this command loads the value that was in the argument as a 32-bit value onto the stack.

When executing this command, the value on the stack was in the second register. Thus, operation code 4C is an extraction from the stack, and the argument following it is the register number. You can make such assumptions simply by looking at the input-output pairs ,.
After the protocol was fully analyzed and lost unnecessary lines, it turned out that in this virtual machine a sufficiently small number of commands. There is a nop command, a command to place data on a stack from a register, extract data from a stack, move between registers, addition, logical operations, shift xor and, in fact, everything.

Some operations, such as mov and shift to the left, are implemented in two or three different ways, but this does not matter - we already know what they are doing. So, after shortening the protocol, we received a program listing in the language of this virtual machine. It remains to simply analyze it and convert.

Unfortunately, I solved this problem 15 minutes after the end of the valid time, that is, we did not have time to pass it, but the solution process itself seemed to me quite interesting. Why was it so simple? Because the authors of the assignment implemented all the state of the virtual machine in the MMX registers of the processor.
Everything else that happened inside is quite logical work of the virtual machine. If I began to write a simple virtual machine, I would write it almost the same. Using the only idea that the registers are mapped to the MMX registers in an unambiguous way, and I can easily identify this unambiguous mapping, I solved the problem without analyzing the assembler code.
Is it reliable?
I managed to solve the second task, which arose in actual practice, without loading the disassembler at all. My colleagues came to me who are engaged in analyzing the safety of the system equipment, and said that they got a new piece of hardware, which needs to be tested.
In this piece of iron there is an opportunity to put passwords that are converted to some value in the config. Values are string, look like some kind of hash, but which one is not clear. I was assigned the task of finding out all the details of the algorithm that colleagues would need in order to assess how well the device is protected by analyzing the configs that are available to them.
I generated passwords for nine users:

What can be seen at first glance? It can be seen that the last characters in all passwords are the same, and the first change significantly. In addition, it is clear that the hash is always 24 characters, the last 13 characters never change, and only 50 different letters, punctuation marks and numbers are used.
Unfortunately, this is clearly not enough for any meaningful conclusion about what is happening inside the algorithm that converts the password into a hash.
It took me more of these passwords, and I asked the guys to do it, but it was the end of the day and I didn't get the passwords right away. However, before the new data appeared, I was able to make several guesses.
- Encoding is used which encodes several bits into fewer bits. Perhaps these are standard encodings, for example, Base16, Base32, or Base64.
- The number of characters> = 50, but 50 characters are somehow not cool, not a power of two. Meanwhile, 64 characters in the codepage is a pretty good guess. Why? Because Base64 means that one letter encodes 6 bits, that is, we have a total of 64 states.
- The password length is 24 characters, of which 13 do not change, and 11 characters are variable. If each of them represents 6 bits, that is, 66 bits change, this is quite close to the power of two and to the 8-byte block.
- Obviously, we are not dealing with mime64, because the characters that can be used are clearly defined for it, but the password hashes that I have been provided with are invalid characters.
- Thus, we have an encoding similar to Base64, with a different encoding table than mime64. In addition, the hash is divided into two clearly visible parts, one of which is changing, and the other is not. This suggests that a 64-bit block may be used for encryption, with each block being encrypted separately.
What else can be done while there is no input material? You can use the search. If you search for a line that was constant, it turns out that the search engine finds approximately 43 thousand pages where this line is mentioned. This is not surprising: the equipment is widespread, and people often used pieces from the documentation and from their configuration files to describe their problems. Scrolling through the pages on which this line met, I gathered the pieces of hashes that were cited there. It turned out that exactly 64 characters are used. Here they are:
! "# $% & '() * +, -. / 0123456789:; <=> @ A
BCDEFGHIJKLMNOPQRSTUVWXYZ [\] ^ _ `a
So we restored the charset. But besides the symbols themselves, you also need to know in what order they go. There is a statistical sequence in which all the characters go one after another, but there is no “?” Symbol, and at the end there is the letter “a”, which has the largest code among all the given characters. However, it is unclear in what order they should go, and the Internet cannot help in this matter.
What else can I get from the documentation found on the Internet? There is a mention that if the password is 16 characters or less, it is encrypted into a 24-character string. If the password is from 16 to 63 characters, then it turns into an 88-character string. Moreover, this number of characters is very easy to explain.
24 * 6 == 144 == 18 * 8 == (2 * 8 + 2) * 8
88 * 6 == 528 == 66 * 8 == (8 * 8 +2) * 8
If we take 24 6-bit characters, we get 144 bits, which is easily divided into two 8-byte blocks, plus 2 more bytes. 88 characters in the same way is divided into eight 8-byte blocks, plus again 2 bytes. We have before us a logical and predictable scheme for translating input symbols into weekends. If I have less than 16 characters in the password, then I get two 8-byte blocks, each of which is encrypted, add 2 bytes at the end, and all this together encode.
Finally, my colleagues generated 511 passwords for me. I asked for passwords of different lengths, an empty password, a password longer than 16. It turned out that this particular device does not know how to create hashes for passwords of more than 16 characters, and an empty password cannot be supplied. However, I have generated password hashes with values from 0000 to 0510.
As one would expect, all these hashes have the last 13 characters unchanged, and in positions from zero to ninth all 64 variants of characters that I had previously found on the Internet were found.
In the 10th position there were only those characters that are highlighted in red in the image below.

It is easy to see that the symbols alternate with period 4, in the region of the letter “a” the alternation is lost, and further, the alternation is lost again at the very end. What happens if the letter “a” was rearranged to the place where the missed “?” Had to be? It turns out such a beautiful picture, where we see a clear period of 4 characters.

It can be assumed that this is the correct table in which the characters go exactly as they will be encoded. Another confirmation of this: the last 4 characters, highlighted by a rectangle, are highlighted in red in the following picture, which shows hashes for passwords of different lengths.

This list shows that while the password is no longer than 8 characters, the right half of the hash is constant. And when the password turns out to contain more than 8 characters, the last 2 characters also do not change, the first 10 turn out to be constant, the eleventh takes 4 states, and then there is a block of 11 characters that change in a chaotic way.
Under which scheme can you customize this change logic?
- pwd [0: 8] affects out [0:10] + 4 bits out [10]
- pwd [8:16] affects 2 bits out [10] + out [11:21] + 2 bits out [21]
- out [22:24] == “!!”
It is quite possible to describe the function in which the Base64 encoding takes place according to the alphabet that was obtained earlier. Inside, there is a concatenation of two 8-byte blocks, which are the computation of some function from the first and second half of the password, and at the end, two null bytes are added, which are converted into exclamation marks with the help of the same coding table.
Base64 (fn (pwd [0: 8]) + fn (pwd [8:16]) + “\ 0 \ 0”)
The scheme is beautiful, but there is one unknown element: we do not know what kind of function it is. How exactly does the function convert the 8 character password to the output? All we know is that there is a conversion of 64 bits to 64 bits. Theoretically, this may be a hash function, but, first, I do not know good 64-bit hash functions that would be used frequently, and second, it is somehow suspicious that the size of the input is equal to the size of the output. It would be simpler to submit the entire password to the input of the hash function and get some value of a given length at the output.
Perhaps this is an encryption algorithm with a 64-bit block. I decided to find out what algorithms are there, and it turned out that there are a lot of options, they are more or less popular. In addition, even if we know the algorithm, the most important element - the encryption key - remains a mystery.
As a result, we are faced with the question: “How do you know the encryption algorithm and where to get the key?” A sensible idea is to look into the firmware. I tried to load the firmware into the disassembler, and it immediately turned out that I did not know the processor architecture. There are many architectures, the disassembler I use supports about 50 different types of architectures, and there are much more of them in the world. Bytecode, it is not always possible to determine which architecture we are dealing with. If the file had headers, if it was an .exe file or ELF is one thing; however, in front of me was just a binary file larger than 20 megabytes. Since I could not start analyzing this file in a short time, I decided to try another idea.
But what if we assume that the most popular encryption algorithm with an 8-byte block is used? This is probably the DES algorithm.
The second question remains: “Where can I find the encryption key?”. There is such an English word —hardcoded. In many security systems, elements that are fundamental to privacy are hardcoded into executable files. And what if you look for the encryption key in the firmware?
As a result, a 20-line program was written that opened the file with the firmware, read it into memory, took the first 8 bytes and tried to interpret them as an encryption key to the function described above. Then a block of 8 bytes was taken with an offset of 1 byte, 2 bytes, and so on until the end of the file. If there was a match that I needed (that is, after Base64 encryption and encryption, I got the line I expected to receive), then a corresponding message was issued.
It turned out that the key is found in the file 12 times and represents a completely logical sequence of bytes:
01 02 03 04 05 06 07 08
I'm not even sure that this sequence is part of the key. Perhaps the key is formed in a tricky, complicated way, but this line is a key suitable for DES, with which you can get a function that does the necessary transformations.
As a result, the code for decrypting these hashes (which turned out to be not at all hashes, but encrypted and reversible passwords) in Python using the pyDes library fit into 10 lines:
from pyDes import * charset = """!"#$%&'()*+,-./0123456789:;<=>a@""" \ + """ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`""" def numFromHash(s): return reduce (lambda v, c: (v << 6) + charset.index(c), s, 0L) def restorePwd(s): v = ("%036X" % numFromHash(s)).decode("hex") k = des("0102030405060708".decode("hex")) pwd = k.decrypt(v[0:8]) + k.decrypt(v[8:16]) return pwd.rstrip('\0') Morality
Why is it so easy to analyze the code? Because code is written by programmers who are focused on efficiency, consistency and understanding of the code. For example, what was non-standard in the second example? Base64 transcoding table is non-standard, but at the same time the table itself is elementarily restored based on statistics. All the rest is a typical approach of a student performing laboratory work. There is no zest here that would complicate the recovery process. Perhaps the developers did not set such a task, but in general, if you work in the field of information security, do not try to make the element as simple and clear as possible when developing an element. This can go sideways for you, because the enemy will try to think logically, like a programmer, and very quickly reveal all the mechanisms that you have put in your decision.
Source: https://habr.com/ru/post/202554/
All Articles