Lock-free data structures. Inside Memory management circuits

As I mentioned in my previous notes, the main difficulties in implementing lock-free data structures are the ABA-problem and memory removal. I share these two problems, although they are related: the fact is that there are algorithms that solve only one of them.
In this article I will give an overview of safe memory reclamation methods known to me for lock-free containers. I will demonstrate the use of this or that method on Michael-Scott's classic lock-free queue [MS98].
Tagged pointers
A tagged pointers scheme was proposed by IBM to solve an ABA problem. Perhaps this is the first known algorithm for solving this problem.
According to this scheme, each pointer is an indivisible pair of the actual address of the memory cell and its tag - a 32-bit integer.
template <typename T> struct tagged_ptr { T * ptr ; unsigned int tag ; tagged_ptr(): ptr(nullptr), tag(0) {} tagged_ptr( T * p ): ptr(p), tag(0) {} tagged_ptr( T * p, unsigned int n ): ptr(p), tag(n) {} T * operator->() const { return ptr; } }; The tag acts as a version number and is incremented with each CAS operation on a labeled pointer and is never reset , that is, it increases strictly. When removing an item from a container, instead of physically deleting an item, it should be placed on some free-list of free-list items. In this case, it is quite acceptable if the remote element that is in the free-list is addressed: the structures are lock-free, so while one thread deletes the element X, another thread can have a local copy of the labeled pointer to X and access the fields of the element . Therefore, the free-list must be separate for each type T, moreover, in many cases it is unacceptable to call the T data type destructor when placing the element in the free-list (due to parallel access - during the operation of the destructor another thread can read the data of this element).
The tagged pointer scheme has the following disadvantages:
- The scheme is implemented on platforms on which there is an atomic primitive CAS over a double word (dwCAS). For 32-bit modern platforms, this requirement is met, since dwCAS works with 64-bit words, and all modern architectures have a full set of 64-bit instructions. But for a 64-bit mode, a 128-bit (or at least 96-bit) dwCAS is required, which is not implemented on all architectures.Yes, you wrote nonsense, my dear!Particularly sophisticated in the lock-free may argue that to implement tagged pointers it is not necessary to have a wide 128-bit (or 96-bit) CAS. You can get by with 64-bit if you consider that modern processors use only 48 bits for addressing, the older 16 bits of the address are free and can be used to store the counter-tag. Well, indeed, they can. This is done in
boost.lockfree.
In this approach, there are two "but":- Who guarantees that in the future these older 16-bit addresses will not be involved? As soon as another breakthrough comes in the field of memory chips and its volume will increase by an order of magnitude, vendors will immediately release new processors with fully 64-bit addressing
- Is 16 bits enough to hold a tag? Studies have been conducted on this score, and the result of these studies is this: 16 bits is not enough, overflow is quite possible, which could potentially lead to an ABA problem. But 32 bits is enough.
Indeed, 16 bits are tag values 0–65535. In modern operating systems, the time slice allocated to the stream is about 300–500 thousand assembly instructions (taken from the internal correspondence of linux developers), and with an increase in processor performance this quantum can only grow. It turns out that for one quantum it is quite possible to perform 65 thousand even such heavy operations as CAS (well, if it is not possible today, it will be possible already tomorrow). Thus, with a 16-bit tag, we are completely at risk of getting an ABA-problem.
- The free-list implementation is a lock-free stack or a lock-free queue, which makes a negative contribution to performance: at least one more call to CAS when retrieving an item from the free-list and adding to it. On the other hand, the presence of a free-list can contribute to an increase in productivity, since if the free-list is not empty, then you should not contact the system, usually quite slow and synchronized memory allocation functions.
- Having a separate free-list for each data type can be an unaffordable luxury for some applications, as it can lead to inefficient use of memory. For example, if the lock-free queue on average contains 10 items, but at the peak its size can reach 1 million, then the size of the free-list after reaching the peak will consistently be about 1 million. Often this behavior is unacceptable.
Thus, the tagged pointer scheme is an example of an algorithm that solves only an ABA problem and does not solve the problem of freeing memory.
')
The libcds library currently does not use tagged pointers to implement lock-free containers. Despite the relative simplicity, this scheme can lead to an uncontrolled increase in memory consumption due to the presence of a free-list for each container object. In libcds, I focused on lock-free algorithms with predictable memory consumption, without using dwCAS.
A good example of using the tagged pointers scheme is the
boost.lockfree library.Example tagged pointers
Lovers of sheets (if any) - pseudocode
MSQueue [MS98] with tagged pointer. Yes, lock-free algorithms are very verbose!For simplicity, I omitted the use of
std:atomic . template <typename T> struct node { tagged_ptr next; T data; } ; template <typename T> class MSQueue { tagged_ptr<T> volatile m_Head; tagged_ptr<T> volatile m_Tail; FreeList m_FreeList; public: MSQueue() { // dummy node // Head & Tail dummy node m_Head.ptr = m_Tail.ptr = new node(); } }; void enqueue( T const& value ) { E1: node * pNode = m_FreeList.newNode(); E2: pNode–>data = value; E3: pNode–>next.ptr = nullptr; E4: for (;;) { E5: tagged_ptr<T> tail = m_Tail; E6: tagged_ptr<T> next = tail.ptr–>next; E7: if tail == m_Tail { // Tail ? E8: if next.ptr == nullptr { // E9: if CAS(&tail.ptr–>next, next, tagged_ptr<T>(node, next.tag+1)) { // , E10: break; } E11: } else { // Tail // tail E12: CAS(&m_Tail, tail, tagged_ptr<T>(next.ptr, tail.tag+1)); } } } // end loop // tail E13: CAS(&m_Tail, tail, tagged_ptr<T>(pNode, tail.tag+1)); } bool dequeue( T& dest ) { D1: for (;;) { D2: tagged_ptr<T> head = m_Head; D3: tagged_ptr<T> tail = m_Tail; D4: tagged_ptr<T> next = head–>next; // Head, tail next ? D5: if ( head == m_Head ) { // Queue tail ? D6: if ( head.ptr == tail.ptr ) { // ? D7: if (next.ptr == nullptr ) { // D8: return false; } // Tail // tail D9: CAS(&m_Tail, tail, tagged_ptr<T>(next.ptr, tail.tag+1>)); D10: } else { // Tail // CAS, // dequeue next D11: dest = next.ptr–>data; // head D12: if (CAS(&m_Head, head, tagged_ptr<T>(next.ptr, head.tag+1)) D13: break // , } } } // end of loop // dummy node D14: m_FreeList.add(head.ptr); D15: return true; // – dest } 
Let's look closely at the algorithms of operations enqueue and dequeue. On their example, you can see several standard techniques when building lock-free structures.
It immediately draws attention to the fact that both methods contain loops — the entire substantive part of the operations is repeated until it succeeds (or successful execution is impossible, for example,
dequeue from an empty queue). Such “slotting” with the help of a cycle is a typical method of lock-free programming.The first element in the queue (pointed to by
m_Head ) is a dummy node. The presence of a dummy element ensures that the pointers to the beginning and end of the queue will never be NULL . A sign of void queue is the condition m_Head == m_Tail && m_Tail->next == NULL (lines D6-D8). The last condition ( m_Tail->next == NULL ) is significant, because in the process of adding to the queue we do not change m_Tail , the line E9 only changes m_Tail->next . Thus, at first glance, the enqueue method violates the queue structure. In fact, changing the tail of m_Tail occurs in another method and / or another thread: the enqueue operation enqueue for the addition of an element (line E8) that m_Tail points to the last element (that is, m_Tail->next == NULL ), and if it is not so, trying to move the pointer to the end (line E12); similarly, the dequeue operation dequeue before performing its “immediate duties” if it does not indicate the end of the queue (line D9). This shows us a common approach in lock-free programming - mutual aid flows ( helping ): the algorithm of one operation is “smeared” across all container operations and one operation relies heavily on the fact that its work will be completed by the next call (possibly another) of operation in ( possible) another thread.Another fundamental observation: the operations store in the local variables the values of the pointers that they need to work (lines E5-E6, D2-D4). Then (lines E7, D5) the values just read are compared with the originals - a typical lock-free technique, redundant for noncompetitive programming: the original values may change in the time since reading. In order for the compiler not to optimize access to shared data of the queue (and too “smart” compiler is able to completely remove the E7 or D5 comparison lines),
m_Head and m_Tail must be declared in C ++ 11 as atomic (in pseudocode - volatile ). In addition, recall that the CAS primitive checks the value of the target address with the given one, and if they are equal, changes the data on the target address to a new value. Therefore, a local copy of the current value should always be specified for a CAS primitive; calling CAS(&val, val, newVal) will almost always succeed, which is an error for us.Now let's see when
dequeue is copied in the dequeue method (line D11): before removing an item from the queue (line D12). Given that the elimination of an element (promotion of m_Head in line D12) can be unsuccessful, data copying (D11) can be repeated. From the point of view of C ++, this means that the data stored in the queue should not be too complicated, otherwise the overhead of the assignment operator in line D11 will be too large. Accordingly, under high load conditions, the probability of failure of the CAS primitive increases. Attempting to “optimize” the algorithm by moving the string D11 outside the cycle limits will result in an error: the next element can be removed by another thread. Since the queue implementation in question is based on the tagged pointer scheme, in which elements are never deleted, such an “optimization” will result in the fact that we can return incorrect data (not those that were in the queue at the time of successful execution of the D12 line).M & S Queue Feature
In general, the
This feature can cause a lot of trouble if you want to use the intrusive version of the
MSQueue algorithm MSQueue interesting in that m_Head always points to a dummy node, and the first element of a non-empty queue is the element following m_Head . With dequeue value of the first element is read from a non-empty queue, that is, m_Head.next , the dummy element is deleted, and the next element, that is, the one whose value we return, becomes the new dummy element (and new head). It turns out that physically removing an element is possible only after the next dequeue operation .This feature can cause a lot of trouble if you want to use the intrusive version of the
cds::intrusive::MSQueue .Epoch-based reclamation
Frazer [Fra03] proposed a scheme based on epochs . Delayed deletion is applied at a safe point in time, when there is complete confidence that none of the threads have references to the deleted item. This guarantee is provided by eras : there is a global epoch of
nGlobalEpoch , and each thread operates in its own local epoch of nThreadEpoch . When entering a protected epoch-based code, the local epoch of the stream is incremented if it does not exceed the global epoch. Once all threads have reached the global era, nGlobalEpoch incremented.Pseudocode scheme:
// static atomic<unsigned int> m_nGlobalEpoch := 1 ; const EPOCH_COUNT = 3 ; // TLS data struct ThreadEpoch { // unsigned int m_nThreadEpoch ; // List<void *> m_arrRetired[ EPOCH_COUNT ] ; ThreadEpoch(): m_nThreadEpoch(1) {} void enter() { if ( m_nThreadEpoch <= m_nGlobalEpoch ) m_nThreadEpoch = m_nGlobalEpoch + 1 ; } void exit() { if ( , m_nGlobalEpoch ) { ++m_nGlobalEpoch ; (delete) m_arrRetired[ (m_nGlobalEpoch – 1) % EPOCH_COUNT ] ; } } } ; The released lock-free elements of the container are placed in the thread-local list of the elements to be deleted
m_arrRetired[m_nThreadEpoch % EPOCH_COUNT] . As soon as all the streams have passed through the global m_nGlobalEpoch epoch, all lists of all streams of the m_nGlobalEpoch – 1 epoch can be freed, and the global epoch itself can be incremented.UPD 2016
UPD 2016: thanks to perfhunter for pointing out the error in this pseudocode:
Please correct a small error in the article “Lock-free data structures. Inside Memory management schemes ”- in the“ Epoch-based reclamation ”section, in the exit () function, you need to replace m_arrRetired [(m_nGlobalEpoch - 2)% EPOCH_COUNT] with m_arrRetired [(m_nGlobalEpoch - 1)% EPOCH_COUNT]. At this moment, the local epoch for threads can be either m_nGlobalEpoch (for those threads that have already entered enter (), or m_nGlobalEpoch + 1 (for streams that are again included in the critical section), and the generation of m_nGlobalEpoch - 1 can be safely released.
Each container lock-free operation is enclosed in calls to
ThreadEpoch::enter() and ThreadEpoch::exit() , which is very similar to the critical section: lock_free_op( … ) { get_current_thread()->ThreadEpoch.enter() ; . . . // lock-free . // “ ” epoch-based , // , , // . . . . get_current_thread()->ThreadEpoch.exit() ; } The scheme is quite simple and protects local links (that is, links inside container operations) to elements of lock-free containers. The scheme cannot provide protection for global links (from outside container operations), that is, the concept of iterators over the lock-free container elements is not implemented with the help of an epoch based scheme. The disadvantage of this scheme is that all program threads must go to the next epoch, that is, turn to some lock-free container; if at least one stream does not enter the next epoch, the removal of deferred pointers will not occur. If the priority of flows is not the same, low-priority flows can cause an uncontrolled growth of the list of deferred items for removal of high-priority flows. Thus, an epoch-based scheme can lead (and in the case of the collapse of one of the threads, it will necessarily lead) to unlimited memory consumption.
The libcds library has no implementation of an epoch-based scheme. Reason: I did not manage to build a sufficiently effective algorithm for determining whether all flows reached the global era. Perhaps some of the readers will recommend a solution? ..
Hazard pointer

The scheme is proposed by Michael [Mic02a, Mic03] and is designed to protect local references to the lock-free elements of the data structure. Perhaps, it is the most well-known and detailed scheme of pending removal. It is based only on atomic reading and writing and does not use “heavy” synchronization primitives like CAS at all.
The cornerstone of the scheme is the obligation to declare a pointer to the lock-free element of the container as hazardous within the lock-free operation of the data structure, that is, before working with the pointer to the element, we must place it in the
HP hazard-pointer array of the current stream. The HP array is private to the stream: only the stream owner is written to it, all threads can read (in the Scan procedure). If you carefully analyze the operations of different lock-free containers, you will notice that the size of the HP array (the number of hazard-pointers to one stream) does not exceed 3 to 4, so the overhead of supporting the scheme is small.Giant data structures
To be fair, it should be noted that there are “giant” data structures that require more than 64 hazard pointers. As an example, skip-list (
cds::container::SkipListMap ) is a probabilistic data structure, in fact, a list of lists, with a variable height of each element. Such containers are not very suitable for the Hazard Pointer schema, although libcds has a skip-list implementation for this schema.Hazard Pointers [Mic02] pseudo code:
// // P : // K : hazard pointer // N : hazard pointers = K*P // R : batch size, RN=Ω(N), , R=2*N // Per-thread : // Hazard Pouinter // - // void * HP[K] // dlist ( 0..R) unsigned dcount = 0; // void* dlist[R]; // // dlist void RetireNode( void * node ) { dlist[dcount++] = node; // – Scan if (dcount == R) Scan(); } // // dlist, // Hazard Pointer void Scan() { unsigned i; unsigned p=0; unsigned new_dcount = 0; // 0 .. N void * hptr, plist[N], new_dlist[N]; // Stage 1 – HP // plist for (unsigned t=0; t < P; ++t) { void ** pHPThread = get_thread_data(t)->HP ; for (i = 0; i < K; ++i) { hptr = pHPThread[i]; if ( hptr != nullptr ) plist[p++] = hptr; } } // Stage 2 – hazard pointer' // sort(plist); // Stage 3 – , hazard for ( i = 0; i < R; ++i ) { // dlist[i] plist Hazard Pointer' // dlist[i] if ( binary_search(dlist[i], plist)) new_dlist[new_dcount++] = dlist[i]; else free(dlist[i]); } // Stage 4 – . for (i = 0; i < new_dcount; ++i ) dlist[i] = new_dlist[i]; dcount = new_dcount; } When the
RetireNode(pNode) of the pNode lock-free element is pNode stream j places pNode in a local (for stream j ) list of dlist deferred (to be deleted) elements. As soon as the size of the dlist reaches R ( R is comparable to N = P*K , but more than N ; for example, R = 2N ), the Scan() procedure is called, which deals with the removal of deferred elements. The condition R > P*K is essential: only if this condition is met, it is guaranteed that Scan() will be able to remove something from the array of pending data. If this condition is violated, Scan() can remove nothing from the array, and we get an algorithm error — the array is completely filled, but it cannot be reduced.Scan() consists of four stages.- First, prepare a
plistarray of current hazard-pointers, which includes all non-nullhazard-pointers of all streams. Only the first stage reads shared data — arrays ofHPstreams — the remaining stages work only with local data. - Stage 2 sorts the
plistarray to optimize the subsequent search; here you can also removeplistelements fromplist. - Stage 3 - deletion itself: all elements of the
dlistarray of the current stream are viewed. If thedlist[i]element is inplist(that is, some thread is working with this pointer, declaring it as a hazard pointer), it cannot be deleted and it remains in thedlist(transferred tonew_dlist). Otherwise, thedlist[i]element can be deleted - not a single thread works with it. - Stage 4 copies the undeleted items from
new_dlisttodlist.SinceR > N, the procedureScan()will necessarily reduce the size of the arraydlist, that is, some elements will be necessarily removed.
Declaring a pointer as a Hazard Pointer is usually done as follows:
std::atomic<T *> atomicPtr ; … T * localPtr ; do { localPtr = atomicPtr.load(std::memory_order_relaxed); HP[i] = localPtr ; } while ( localPtr != atomicPtr.load(std::memory_order_acquire)); atomicPtr localPtr ( ) HP[i] HP hazard- . , , atomicPtr , , atomicPtr localPtr . , HP ( hazard) atomicPtr . Hazard Pointer' ( hazard), , .The Hazard Pointer scheme (HP scheme) is analyzed in detail from the point of view of atomic C ++ 11 operations and memory ordering in [Tor08].
MSQueue performed by Hazard Pointer
Lock-free - [MS98] Hazard Pointer. “” , libcds:
template <typename T> class MSQueue { struct node { std::atomic<node *> next ; T data; node(): next(nullptr) {} node( T const& v): next(nullptr), data(v) {} }; std::atomic<node *> m_Head; std::atomic<node *> m_Tail; public: MSQueue() { node * p = new node; m_Head.store( p, std::memory_order_release ); m_Tail.store( p, std::memory_order_release ); } void enqueue( T const& data ) { node * pNew = new node( data ); while (true) { node * t = m_Tail.load(std::memory_order_relaxed); // hazard. HP – thread-private HP[0] = t; // , m_Tail ! if (t != m_Tail.load(std::memory_order_acquire) continue; node * next = t->next.load(std::memory_order_acquire); if (t != m_Tail) continue; if (next != nullptr) { // m_Tail // m_Tail m_Tail.compare_exchange_weak( t, next, std::memory_order_release); continue; } node * tmp = nullptr; if ( t->next.compare_exchange_strong( tmp, pNew, std::memory_order_release)) break; } m_Tail.compare_exchange_strong( t, pNew, std::memory_order_acq_rel ); HP[0] = nullptr; // hazard pointer } bool dequeue(T& dest) { while true { node * h = m_Head.load(std::memory_order_relaxed); // Hazard Pointer HP[0] = h; // , m_Head if (h != m_Head.load(std::memory_order_acquire)) continue; node * t = m_Tail.load(std::memory_order_relaxed); node * next = h->next.load(std::memory_order_acquire); // head->next Hazard Pointer HP[1] = next; // m_Head – if (h != m_Head.load(std::memory_order_relaxed)) continue; if (next == nullptr) { // HP[0] = nullptr; return false; } if (h == t) { // enqueue – m_Tail m_Tail.compare_exchange_strong( t, next, std::memory_order_release); continue; } dest = next->data; if ( m_Head.compare_exchange_strong(h, next, std::memory_order_release)) break; } // Hazard Pointers HP[0] = nullptr; HP[1] = nullptr; // // . RetireNode(h); } }; Hazard Pointer ? ? , , — . : hazard pointer' K . – hazard pointer – , , , hazard- . , hazard-. – [Har01]. , HP- .
, HP- hazard-. , . libcds , , , HP-. , — Pass the Buck , — Hazard Pointer, hazard-. .
Hazard Pointer libcds
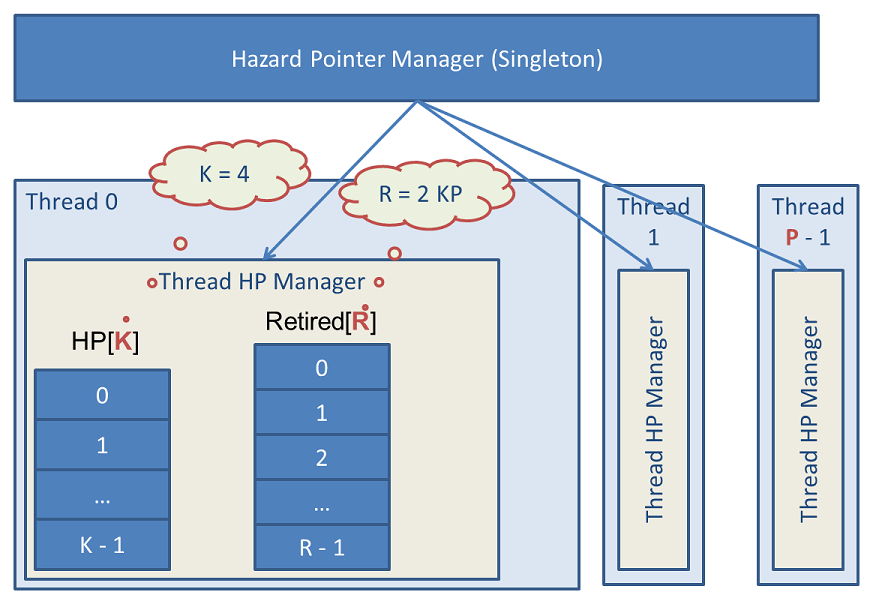
hazard pointer libcds. – Hazard Pointer Manager — , libcds.dll/.so. — Thread HP Manager , — HP hazard pointer' K () Retired R . Thread HP Manager . P . libcds:
- hazard-
K = 8 P = 100- ( )
R = 2 * K * P = 1600.
libcds HP- :
- – (
cds::gc::hzp). (T), . , ( , «» – . , – -, – « ». , , – ). - – ,
cds::gc::hzp. (template) - , (- type erasure). - (API) –
cds::gc::HP. , ( ) lock-free libcds, , ( , )GC.cds::gc::HP– .
«» , , , ? : (, retired) :
( retired ) .
, , , .
struct retired_ptr { typedef void (* fnDisposer )( void * ); void * ptr ; // fnDisposer pDisposer; // - retired_ptr( void * p, fnDisposer d): ptr(p), pDisposer(d) {} }; ( retired ) .
Scan() HP- pDisposer(ptr) «» .pDisposer . . , : template <typename T> struct make_disposer { static void dispose( void * p ) { delete reinterpret_cast<T *>(p); } }; template <typename T> void retire_ptr( T * p ) { // p arrRetired // , arrRetired – arrRetired.push( retired_ptr( p, make_disposer<T>::dispose )); // – scan if ( arrRetired.full() ) scan(); } , , , .
HP- libcds,
main() cds::gc::HP , , HP-, . , , cds::gc::HP . API HP-.API cds::gc::HP
,
,
cds::gc::HP – , , .- Constructor
HP(size_t nHazardPtrCount = 0, size_t nMaxThreadCount = 0, size_t nMaxRetiredPtrCount = 0, cds::gc::hzp::scan_type nScanType = cds::gc::hzp::inplace);nHazardPtrCount– hazard pointer' ( K )nMaxThreadCount– ( P )nMaxRetiredPtrCount– retired- (R = 2KP)nScanType– :cds::gc::hzp::classic,Scan;cds::gc::hzp::inplaceScan()new_dlistdlist( ).
,cds::gc::HP. ,cds::gc::HPHazard Pointer, , , . - retired ( )
template <class Disposer, typename T> static void retire( T * p ) ; template <typename T> static void retire( T * p, void (* pFunc)(T *) )Disposer(pFunc) (). :struct Foo { … }; struct fooDisposer { void operator()( Foo * p ) const { delete p; } }; // myDisposer Foo Foo * p = new Foo ; cds::gc::HP::retire<fooDisposer>( p ); static void force_dispose();Scan()Hazard Pointer. , , libcds .
,
cds::gc::HP :thread_gc– (thread data), Hazard Pointer. , HP- , ,Guard– hazard pointertemplate <size_t Count> GuardArray– hazard pointer'. HP- hazard- . ,Guard
Guard GuardArray<N> Hazard Pointer, . .Guard hazard- API:template <typename T> T protect( CDS_ATOMIC::atomic<T> const& toGuard ); template <typename T, class Func> T protect( CDS_ATOMIC::atomic<T> const& toGuard, Func f );
(T– ) hazard. , :toGuard, hazard pointer' , .
(Func) , hazardT *, . , (node), (,node).Func:struct functor { value_type * operator()( T * p ) ; };
, hazard.template <typename T> T * assign( T * p ); template <typename T, int Bitmask> T * assign( cds::details::marked_ptr<T, Bitmask> p );
p hazard. ,protect, , —phazard-.cds::details::marked_ptr. marked- 2-3 ( 0 ) , — lock-free . hazard- (Bitmask).
, hazard.template <typename T> T * get() const;
hazard-. .void copy( Guard const& src );
hazard-srcthis. hazard- .void clear();
hazard-.Guard.
GuardArray API, : template <typename T> T protect(size_t nIndex, CDS_ATOMIC::atomic<T> const& toGuard ); template <typename T, class Func> T protect(size_t nIndex, CDS_ATOMIC::atomic<T> const& toGuard, Func f ) template <typename T> T * assign( size_t nIndex, T * p ); template <typename T, int Bitmask> T * assign( size_t nIndex, cds::details::marked_ptr<T, Bitmask> p ); void copy( size_t nDestIndex, size_t nSrcIndex ); void copy( size_t nIndex, Guard const& src ); template <typename T> T * get( size_t nIndex) const; void clear( size_t nIndex); CDS_ATOMIC – ?,
std::atomic . ( ) C++11 atomic , CDS_ATOMIC std . – cds::cxx11_atomics , , libcds- atomic. libcds boost.atomic , CDS_ATOMIC boost .Hazard Pointer with Reference Counter

Hazard Pointer , lock-free . , , , , : hazard-.
, HP- . - HP-, . , (, hazard- ). , hazard-, , HP- .
— «, , ». , — , . , .
— «, , ». , — , . , .
, , (reference counting, RefCount). Valois – lock-free — . RefCount- , – , . , RefCount-, lock-free fetch-and-add (, , – ).
2005 [GPST05], Hazard Pointer RefCount : Hazard Pointers lock-free , RefCount – . HRC (Hazard pointer RefCounting).
Hazard Pointers / , RefCounting- . , (- , . [GPST05]). Hazard Pointers lock-free , HRC :
void CleanUpNode( Node * pNode); void TerminateNode( Node * pNode); TerminateNode pNode . CleanUpNode , , pNode «» ( ) , () ; RefCount- , , CleanUpNode : void CleanUpNode(Node * pNode) { for (all x where pNode->link[x] of node is reference-counted) { retry: node1 = DeRefLink(&pNode->link[x]); // HP if (node1 != NULL and !is_deleted( node1 )) { node2 = DeRefLink(node1->link[x]); // HP // , // node1 CompareAndSwapRef(&pNode->link[x],node1,node2); ReleaseRef(node2); // HP ReleaseRef(node1); // HP goto retry; // , } ReleaseRef(node1); // HP } } lock-free ( C++) HRC lock-free . , ,
CleanUpNode , , . lock-free , , MultiCAS ., Hazard Pointers , .
Scan Hazar Pointers ( , CleanUpNode ). : Hazard Pointers ( R > N = P * K ), Scan - ( , hazard-), HRC Scan - ( – ). , Scan , CleanUpAll : CleanUpNode , Scan .HRC- libcds
UPD (2016 ): libcds 2.0.0 HRC- ( , ), - , Hazard Pointer.
libcds HRC- HP-. –
HRC- – – libcds. , lock-free . , , . – – lock-free : -, , . , , HP- , , — lock-free .
, HRC- libcds HP-. , ( ) HP-: HRC- 2-3 , HP-. «», : -
HRC- libcds HP-like , . HRC- HRC-based HP-based .
libcds HRC- HP-. –
cds::gc::HRC . API API cds::gc::HP . namespace cds::gc::hrc .HRC- – – libcds. , lock-free . , , . – – lock-free : -, , . , , HP- , , — lock-free .
, HRC- libcds HP-. , ( ) HP-: HRC- 2-3 , HP-. «», : -
Scan (, - ) CleanUpAll , retired-.HRC- libcds HP-like , . HRC- HRC-based HP-based .
Pass the Buck

lock-free , Herlihy & al Pass-the-Buck (PTB, “ ”) [HLM02, HLM05], HP- ., .
, HP-, PTB- (guarded, hazard pointer HP-). PTB- ( hazard pointer'). (retired)
Liberate — Scan HP-. Liberate , . HP-, retired- , PTB- .guard' (hazard pointer'): , retired-, hand-off (“ ”).
Liberate , retired- guard', retired- hand-off guard'. Liberate hand-off , guard, , , .[HLM05]
Liberate : wait-free lock-free. Wait-free dwCAS (CAS ), dwCAS . Lock-free , . (guard' retired-) lock-free Liberate , (, retired-, ). , PTB- , Liberate .,
LiberatePTB-scheme, making it similar to the HP-scheme. As a result, the implementation of PTB in libcds has become more similar to the variant of the HP scheme with an arbitrary number of hazard-pointers and a single array of retired-data. This affected the performance slightly: a “clean” HP scheme is still slightly faster than PTB, but PTB may be preferable due to the lack of restrictions on the number of guards.Implementation in libcds
UPD (2016 ): libcds 2.0.0
libcds PTB-
cds::gc::DHP — HP, — pass-the-buck , — Hazard Pointer .libcds PTB-
cds::gc::PTB , namespace cds::gc::ptb . API cds::gc::PTB cds::gc:::HP , . : PTB( size_t nLiberateThreshold = 1024, size_t nInitialThreadGuardCount = 8 ); nLiberateThreshold—Liberate. retired- ,LiberatenInitialThreadGuardCount— quard' (, libcds). guard'
Conclusion
safe memory reclamation, Hazard Pointer. HP- lock-free .
lock-free . libcds, , (attach)
GC libcds. , Scan() / Liberate() . — .— RCU, HP-like , — .
UPD 2016: Errandir , Hazard Pointer ( HP).
[Fra03] Keir Fraser Practical Lock Freedom , 2004; technical report is based on a dissertation submitted September 2003 by K.Fraser for the degree of Doctor of Philosophy to the University of Cambridge, King's College
[GPST05] Anders Gidenstam, Marina Papatriantafilou, Hakan Sundell, Philippas Tsigas Practical and Efficient Lock-Free Garbage Collection Based on Reference Counting , Technical Report no. 2005-04 in Computer Science and Engineering at Chalmers University of Technology and Goteborg University, 2005
[Har01] Timothy Harris A pragmatic implementation of Non-Blocking Linked List , 2001
[HLM02] M. Herlihy, V. Luchangco, and M. Moir The repeat offender problem: A mechanism for supporting
dynamic-sized lockfree data structures Technical Report TR-2002-112, Sun Microsystems
Laboratories, 2002.
[HLM05] M.Herlihy, V.Luchangco, P.Martin, and M.Moir Nonblocing Memory Management Support for Dynamic-Sized Data Structure , ACM Transactions on Computer Systems, Vol. 23, No. 2, May 2005, Pages 146–196.
[Mic02] Maged Michael Safe Memory Reclamation for Dynamic Lock-Free Objects Using Atomic Reads and Writes , 2002
[Mic03] Maged Michael Hazard Pointers: Safe Memory Reclamation for Lock-Free Objects , 2003
[MS98] Maged Michael, Michael Scott Simple, Fast and Practical Non-Bloking and Blocking Concurrent Queue Algorithms , 1998
[Tor08] Johan Torp The parallelism shift and C++'s memory model , chapter 13, 2008
[GPST05] Anders Gidenstam, Marina Papatriantafilou, Hakan Sundell, Philippas Tsigas Practical and Efficient Lock-Free Garbage Collection Based on Reference Counting , Technical Report no. 2005-04 in Computer Science and Engineering at Chalmers University of Technology and Goteborg University, 2005
[Har01] Timothy Harris A pragmatic implementation of Non-Blocking Linked List , 2001
[HLM02] M. Herlihy, V. Luchangco, and M. Moir The repeat offender problem: A mechanism for supporting
dynamic-sized lockfree data structures Technical Report TR-2002-112, Sun Microsystems
Laboratories, 2002.
[HLM05] M.Herlihy, V.Luchangco, P.Martin, and M.Moir Nonblocing Memory Management Support for Dynamic-Sized Data Structure , ACM Transactions on Computer Systems, Vol. 23, No. 2, May 2005, Pages 146–196.
[Mic02] Maged Michael Safe Memory Reclamation for Dynamic Lock-Free Objects Using Atomic Reads and Writes , 2002
[Mic03] Maged Michael Hazard Pointers: Safe Memory Reclamation for Lock-Free Objects , 2003
[MS98] Maged Michael, Michael Scott Simple, Fast and Practical Non-Bloking and Blocking Concurrent Queue Algorithms , 1998
[Tor08] Johan Torp The parallelism shift and C++'s memory model , chapter 13, 2008
Source: https://habr.com/ru/post/202190/
All Articles