Optimization of applications for Android x86: proven methods

Any application for Android, even written only in scripting and non-native languages (such as Java or HTML5), ultimately uses the basic components of the execution environment, which should be optimized. Good examples to illustrate optimization approaches and needs are applications using multimedia and augmented reality technologies, described below. For the Android platform (smartphones and tablets), Intel uses various types of Atom processors that have SSSE3 vectorization level and usually 2 cores with hypertrending - consider this a hint :) For those who understand the hint, under the cut is the history of optimization and parallelization of one specific Israeli company application iOnRoad - iOnRoad.
Formulation of the problem
iOnRoad is an augmented reality application for smartphones that helps you drive safely. Using GPS, sensors and a video camera smartphone, as well as modern computer vision algorithms, the application warns the driver about leaving the band, as well as a possible collision with other cars and obstacles. The application is extremely popular (more than a million downloads!), Has been awarded with all sorts of awards, and had only two drawbacks:1. Does not warn about drunken drivers of neighboring cars and beautiful girls, as well as other interesting fellow travelers voting on the road as you follow your car.
2. It requires optimization, including energy consumption, since the original version could not be used without connecting the smartphone to power for more than 30-40 minutes, during which time the battery completely sat down.
At the moment, there is only one drawback. The first.
So, working in real time, the application converts each source frame of the YUV420 / NV21 format from the camera of the smartphone to the RGB format before further processing.
 Initially, the function implementing this transformation used up to 40% of processor resources, thereby limiting the possibilities for further image processing. Thus, the need for optimization seemed urgent.
Initially, the function implementing this transformation used up to 40% of processor resources, thereby limiting the possibilities for further image processing. Thus, the need for optimization seemed urgent.The only existing optimized feature we found is the YUV420ToRGB feature from the IPP package ( Intel Integrated Performance Primitives library ), but it does not have the combination of input and output formats that iOnRoad needs. In addition, it is not multi-threaded.
Therefore, it was decided to write a new optimized code that implements the necessary transformation.
')
Transformation from YUV420 / NV21 to RGB
The YUV420 / NV21 format contains three 8-bit components — luminance Y (black and white) and two chrominance components U and V.
To get four pixels in the standard RGB format (with its three color components for each pixel), each quadruple component Y only needs one pair of corresponding components U and V.
In the picture above, the corresponding quadruples Y and the pairs U and V serving them are marked with the same color. This format (usually called YUV) provides double compression as compared to RGB.
Transformation of YUV to RGB - an integer approach using tables (look-up table, LUT)
Transformation of YUV to RGB is made by a simple linear formula. To avoid converting to floating-point numbers, iOnRoad used the following well-known integer approximation: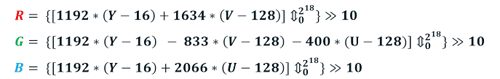
Intermediate results of calculations using this formula are more than 2 16 - this is an important point for further discussion of vectorization.
For scalar computing, iOnRoad used lookup tables (LUT): since all Y, U, and V components are 8-bit, multiplications in the above formulas can be calculated in advance and 32-bit results are stored in five tables with 256 entries.
Transformation of YUV to RGB - the general idea of using fixed-point computing based on SSE
SSE does not have “gather” vector instructions for working with LUT; the use of vector multiplication of 16-bit packed numbers seems to be faster than the combination of scalar LUT operations and subsequent packing. However, a simple 16-bit SSE multiplication (PMULLW) cannot be used, since the expected intermediate results may be greater than 2 16 . In SSE, there is a PMULHRSW instruction that combines full 16-bit multiplication and a right-shift 32-bit intermediate result to the required 16 bits with rounding. To use this instruction, the operands must be pre-shifted to the left, providing the maximum number of significant bits in the final result (in our particular case, we can get a 13-bit final result).Built-in functions (intrinsics) as a means of writing manual SSE code
To help avoid writing manual SSE code using assembler, all well-known C / C ++ compilers (MS, GNU, Intel) have a set of special APIs called intrinsic functions.From the programmer’s point of view, the built-in function looks and behaves like a normal C / C ++ function. In fact, it is a wrapper for one assembly instruction SSE and in most cases it is only compiled as this instruction. The use of built-in functions replaces the writing of an assembly code with all its difficulties at the same performance indicators.
For example, to call the PMULHRSW instruction, which was mentioned above, in the C code we used the built-in function _mm_mulhrs_epi16 ().
Each SSE instruction has a corresponding built-in function, so that the necessary SSE code can be completely written using built-in functions.
Transform YUV to RGB — Implementing SSE-based Fixed-Point Computing
The process begins with the loading of 2 portions of 16 8-bit Y and 8 8-bit pairs (U, V).As a result, this data will be converted to 16 32-bit RGB pixels (in the form of FRGB, when the high byte is 0xff).
The number 16 is subtracted from the 16 8-bit Y using the 8-bit subtraction operation with saturation, thus there is no need to check the result for negativity.
8 pairs (U, V) “serve” 2 lines with 16 Y values.
For unpacking the input data, a permutation operation (shuffle) is used, thus 2 portions are obtained from:
- 2-x sets of 8 16-bit Y;
- 1st set of 4 x 16-bit doubled U;
- 1st set of 4 x 16-bit doubled V.
Below is a detailed scheme of manufacturing a single portion.
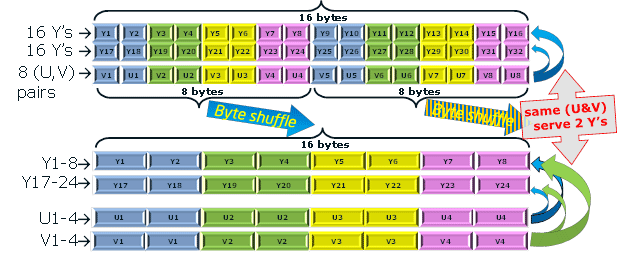
Before using U and V, 128 are subtracted from them using the 16-bit _mm_sub_epi16 () instruction.
After subtraction, all 8 16-bit values of Y, U, and V are shifted left to best fit _mm_mulhrs_epi16 (); This instruction is used with appropriately packed coefficients.
Note: These preparatory steps (subtractions and shifts), mentioned above, are used instead of LUT operations in a scalar algorithm.
The multiplication results are summed to produce final 16-bit values bounded between 0 and 2 13 -1 (8191) using _mm_min_epi16 () and _mm_max_epi16 ().
After all the calculations are completed, we get the result in the form of 16-bit R, G, and B values packed separately.
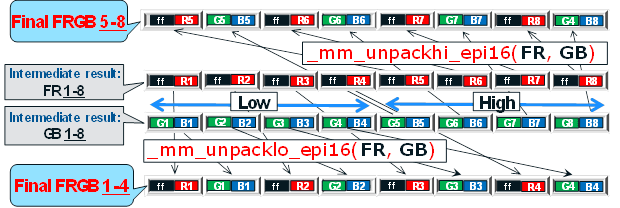
Repacking them into the FRGB format (where F is an alpha channel filled with units according to iOnRoad requirements) is performed in two steps.
In the first step, we repack 16-bit separate R, G, and B values into 16-bit FR and GB using an additional register filled with 16-bit <0xff00>. This repacking phase is performed using logical left and right shifts and logical OR / AND operations, as shown in the figure:

In the second step, the intermediate results FR and GB are finally packaged in the FRGB using the _mm_unpacklo_epi16 () and _mm_unpackhi_epi16 () unpacking instructions:
The code described above, which implements the conversion of YUV to RGB using the built-in vector functions of SSE, gives 4-fold acceleration in comparison with the original scalar code using pre-calculated tables (LUT).
Using CILK + for parallelization: trivial
All versions of Atom processors used in smartphones and tablets have at least two cores (at least logical - HT), and in the future they will have even more, so the parallelization of algorithms is very important for them.The simplest approach to parallelization is implemented in the CILK + extension of the Intel compiler for the C and C ++ languages (the famous TBB works only for C ++!). The simplest parallelization operator cilk_for (used for the external conversion cycle of YUV to RGB instead of the standard for C / C ++ language) provides a double performance gain on the dual-core Clover Trail + processor.
The use of internal SSE functions for vectorization together with CILK + parallelization gives an 8-fold total acceleration.
Using CILK + for vectorization: Array Notation, function mapping and reduction
CILK + contains a very important extension called Array Notation, which allows to significantly increase the efficiency of vectorization and at the same time improve the readability of the code.Array Notation provides platform scalability: the same code can be optimally vectorized for 128-bit Atom, and for 256-bit Haswell, and for 512-bit MIC / Skylake - unlike code based on SSE / AVX internal functions : it has to be rewritten manually for each specific platform. Array Notation allows you to use the so-called sections of the array as function arguments (function mapping), as well as for reduction (summation, maximum / minimum search, etc.).
CILK + Array Notation usage example
Look at two code snippets.Source code with complex definitions and sweep (taken from a real application):

And a single-line combination with CILK + elements, consisting of the Array Notation section, function mapping and reduction:

These two options are completely identical from a functional point of view, but the CILK + version works 6 times faster!
Conclusions and appeal to developers
Internal SSE functions (SSSE3 level) significantly improve application performance on Atom / Intel devices.Using CILK + Array Notation (built into the Intel compiler) provides great opportunities for automatic vectorization.
CILK + is a great tool for parallelizing applications on Atom / Intel devices.
Our recommendation for Atom / Android developers in the new "android" world: feel free to optimize your multimedia applications and games using SSE and CILK + - these proven tools will provide you with a huge performance boost!
The author of the text is Gregory Danovich, Senior Application Engineer, Intel Israel.
Source: https://habr.com/ru/post/202088/
All Articles