Asynchrony: back to the future

Asynchrony ... Having heard this word, programmers start to shine eyes, breathing becomes shallow, hands begin to shake, voice stutters, the brain begins to draw numerous levels of abstraction ... Managers have eyes rounded, sounds become inarticulate, hands go into fists, and voice switches to overtone ... The only thing that unites them is a quick pulse. Only the reasons for this are different: programmers rush into battle, and managers try to look into the crystal ball and realize the risks, start frantically thinking up the reasons for the increase in terms at times ... And only then, when most of the code is written, programmers begin to realize and learn all the bitterness of asynchrony, conducting endless nights in the debugger, desperately trying to figure out what is going on ...
It is this picture that draws my inflamed imagination with the word “asynchrony”. Of course, all this is too emotional and not always true. Is that so? .. Options are possible. Some will say that “with the right approach, everything will work well”. However, this can be said always and everywhere at every convenient and not convenient occasion. But this does not get any better, bugs are not corrected, and insomnia does not go away.
So what is asynchrony? Why is she so attractive? And most importantly: what is wrong with her?
Introduction
Asynchrony is currently quite a popular topic. Enough to view the latest articles on Habré to see this. Here you have an overview of various libraries, and the use of the Go language, and all sorts of asynchronous frameworks on JS, and much more.')
Typically, asynchronous is used for network programming: all sorts of socketed sockets, reader-writers and other acceptors. But there are still funny and interesting events, especially in the UI. Here I will only consider networking. However, as will be shown in the next article, the approach can be expanded and deepened into unknown distances.
To be very specific, we will write a simple HTTP server, which sends a standard response to any request. This is not to write a parser, because He has exactly the same attitude to the topic of asynchrony, as the position of the stars to the character of a person (see astrology).
Synchronous single-threaded server

Hm Synchronous? And what’s the point of being synchronous, the attentive reader will ask, opening an article about asynchrony. Well, first of all, you need to start somewhere. From something simple. And secondly ... In short, I am the author, so it will be so. And then you will find out why.
In order not to write low-level platform-specific code, for all our purposes I will use a powerful asynchronous library called boost.asio . Fortunately, the articles have already been written about her enough to be at least a little bit in the subject.
Again, for better visibility and “production” of the code, I will make wrappers for calling the appropriate functions from the boost.asio library. Of course, someone might like wrappers like
boost::asio::ip::tcp::socket or boost::asio::ip::udp::resolver::iterator , but the clarity and readability of the code is significantly reduced.So, the description of the socket and acceptor:
typedef std::string Buffer; // forward declaration struct Acceptor; struct Socket { friend struct Acceptor; Socket(); Socket(Socket&& s); // void read(Buffer&); // , void readSome(Buffer&); // until int readUntil(Buffer&, const Buffer& until); // void write(const Buffer&); // void close(); private: boost::asio::ip::tcp::socket socket; }; struct Acceptor { // explicit Acceptor(int port); // void accept(Socket& socket); private: boost::asio::ip::tcp::acceptor acceptor; }; Nothing extra, just a server.
Socket allows you to write and read, including up to certain characters ( readUntil ). Acceptor listens to the specified port and accepts connections.The implementation of this whole farm is shown below:
boost::asio::io_service& service() { return single<boost::asio::io_service>(); } Socket::Socket() : socket(service()) { } Socket::Socket(Socket&& s) : socket(std::move(s.socket)) { } void Socket::read(Buffer& buffer) { boost::asio::read(socket, boost::asio::buffer(&buffer[0], buffer.size())); } void Socket::readSome(Buffer& buffer) { buffer.resize(socket.read_some(boost::asio::buffer(&buffer[0], buffer.size()))); } bool hasEnd(size_t posEnd, const Buffer& b, const Buffer& end) { return posEnd >= end.size() && b.rfind(end, posEnd - end.size()) != std::string::npos; } int Socket::readUntil(Buffer& buffer, const Buffer& until) { size_t offset = 0; while (true) { size_t bytes = socket.read_some(boost::asio::buffer(&buffer[offset], buffer.size() - offset)); offset += bytes; if (hasEnd(offset, buffer, until)) { buffer.resize(offset); return offset; } if (offset == buffer.size()) { LOG("not enough size: " << buffer.size()); buffer.resize(buffer.size() * 2); } } } void Socket::write(const Buffer& buffer) { boost::asio::write(socket, boost::asio::buffer(&buffer[0], buffer.size())); } void Socket::close() { socket.close(); } Acceptor::Acceptor(int port) : acceptor(service(), boost::asio::ip::tcp::endpoint(boost::asio::ip::tcp::v4(), port)) { } void Acceptor::accept(Socket& socket) { acceptor.accept(socket.socket); } Here I used a singleton for
io_service in order not to pass it to the socket each time explicitly in the input parameters. And how can the user know that there should be some io_service ? Therefore, I hid it away so that my eyes would not be cornered. The rest, I believe, is quite understandable, with the exception, perhaps, of the readUntil function. But its essence is simple: read the Baitik until a cherished ending is encountered. This is needed just for HTTP, because in advance, we, alas, cannot specify the size. It is necessary to resize.Let's now write the long-awaited server. Here he is:
#define HTTP_DELIM "\r\n" #define HTTP_DELIM_BODY HTTP_DELIM HTTP_DELIM // Buffer httpContent(const Buffer& body) { std::ostringstream o; o << "HTTP/1.1 200 Ok" HTTP_DELIM "Content-Type: text/html" HTTP_DELIM "Content-Length: " << body.size() << HTTP_DELIM_BODY << body; return o.str(); } // 8800 ( 80 ?) Acceptor acceptor(8800); LOG("accepting"); while (true) { Socket socket; acceptor.accept(socket); try { LOG("accepted"); Buffer buffer(4000, 0); socket.readUntil(buffer, HTTP_DELIM_BODY); socket.write(httpContent("<h1>Hello sync singlethread!</h1>")); socket.close(); } catch (std::exception& e) { LOG("error: " << e.what()); } } The server is ready!
Synchronous multithreaded server
The disadvantages of the previous server are obvious:- Unable to handle multiple connections at the same time.
- The client can reuse the connection for more efficient interaction, and we always close it.
Therefore, an idea appears to process the connections in another thread, while continuing to accept the following connections. To do this, we need the function to create a new thread, which I suddenly call
go : typedef std::function<void ()> Handler; void go(Handler handler) { LOG("sync::go"); std::thread([handler] { try { LOG("new thread had been created"); handler(); LOG("thread was ended successfully"); } catch (std::exception& e) { LOG("thread was ended with error: " << e.what()); } }).detach(); } It is worth noting one funny thing: if you remove
detach() , then guess what the program will do?Answer:
Stupidly complete without any messages. Thanks to the developers of the standard, keep it up!
Now you can write the server:
Acceptor acceptor(8800); LOG("accepting"); while (true) { Socket* toAccept = new Socket; acceptor.accept(*toAccept); LOG("accepted"); go([toAccept] { try { Socket socket = std::move(*toAccept); delete toAccept; Buffer buffer; while (true) { buffer.resize(4000); socket.readUntil(buffer, HTTP_DELIM_BODY); socket.write(httpContent("<h1>Hello sync multithread!</h1>")); } } catch (std::exception& e) { LOG("error: " << e.what()); } }); } It would seem that all is well, but it was not there: on real tasks under load, this case falls quickly and then it is not wrung out. Therefore, smart guys thought, thought, and decided to use asynchrony.
Asynchronous server
What is the problem with the previous approach? And the fact that the threads instead of real work most of the time waiting for events from the network, otzhiraya resources. I would like to somehow more efficiently use threads to perform useful work.Therefore, now I will implement similar functions, but asynchronously, using the proactor model. What does this mean? This means that we call the function for all operations and pass the callback, which will automatically be called at the end of the operation. Those. they will call us as soon as the operation is completed. This differs from the reactor model when we have to call the necessary handlers ourselves, observing the state of operations. A typical example of a reactor is epoll, kqueue, and various selects. Example of proactor: IOCP on Windows. I will use a cross-platform proactor boost.asio .
Asynchronous interfaces:
typedef boost::system::error_code Error; typedef std::function<void(const Error&)> IoHandler; struct Acceptor; struct Socket { friend struct Acceptor; Socket(); Socket(Socket&&); void read(Buffer&, IoHandler); void readSome(Buffer&, IoHandler); void readUntil(Buffer&, Buffer until, IoHandler); void write(const Buffer&, IoHandler); void close(); private: boost::asio::ip::tcp::socket socket; }; struct Acceptor { explicit Acceptor(int port); void accept(Socket&, IoHandler); private: boost::asio::ip::tcp::acceptor acceptor; }; It is worth looking at some things:
- Error handling is now significantly different. In the case of a synchronous approach, we have 2 options: the return of the error code or the generation of an exception (this method was used at the beginning of the article). In the case of an asynchronous call, there is exactly one way: passing the error through the handler. Those. not even through the result, but as the input parameter of the handler. And if you want, you do not want - be kind enough to handle errors like in the good old days, when there were no exceptions: for every check. But the most interesting, of course, is not that; interesting is when an error occurred in the handler and must be processed. Context recall is a favorite asynchronous programming task!
- For a uniform approach, I used
IoHandler, which makes the code simpler and more versatile.
If you look closely, the only difference from synchronous functions is that asynchronous ones contain an additional handler as an input parameter.
Well, it seems there is nothing terrible yet.
Implementation:
Socket::Socket() : socket(service()) { } Socket::Socket(Socket&& s) : socket(std::move(s.socket)) { } void Socket::read(Buffer& buffer, IoHandler handler) { boost::asio::async_read(socket, boost::asio::buffer(&buffer[0], buffer.size()), [&buffer, handler](const Error& error, std::size_t) { handler(error); }); } void Socket::readSome(Buffer& buffer, IoHandler handler) { socket.async_read_some(boost::asio::buffer(&buffer[0], buffer.size()), [&buffer, handler](const Error& error, std::size_t bytes) { buffer.resize(bytes); handler(error); }); } bool hasEnd(size_t posEnd, const Buffer& b, const Buffer& end) { return posEnd >= end.size() && b.rfind(end, posEnd - end.size()) != std::string::npos; } void Socket::readUntil(Buffer& buffer, Buffer until, IoHandler handler) { VERIFY(buffer.size() >= until.size(), "Buffer size is smaller than expected"); struct UntilHandler { UntilHandler(Socket& socket_, Buffer& buffer_, Buffer until_, IoHandler handler_) : offset(0), socket(socket_), buffer(buffer_), until(std::move(until_)), handler(std::move(handler_)) { } void read() { LOG("read at offset: " << offset); socket.socket.async_read_some(boost::asio::buffer(&buffer[offset], buffer.size() - offset), *this); } void complete(const Error& error) { handler(error); } void operator()(const Error& error, std::size_t bytes) { if (!!error) { return complete(error); } offset += bytes; VERIFY(offset <= buffer.size(), "Offset outside buffer size"); LOG("buffer: '" << buffer.substr(0, offset) << "'"); if (hasEnd(offset, buffer, until)) { // found end buffer.resize(offset); return complete(error); } if (offset == buffer.size()) { LOG("not enough size: " << buffer.size()); buffer.resize(buffer.size() * 2); } read(); } private: size_t offset; Socket& socket; Buffer& buffer; Buffer until; IoHandler handler; }; UntilHandler(*this, buffer, std::move(until), std::move(handler)).read(); } void Socket::write(const Buffer& buffer, IoHandler handler) { boost::asio::async_write(socket, boost::asio::buffer(&buffer[0], buffer.size()), [&buffer, handler](const Error& error, std::size_t) { handler(error); }); } void Socket::close() { socket.close(); } Acceptor::Acceptor(int port) : acceptor(service(), boost::asio::ip::tcp::endpoint(boost::asio::ip::tcp::v4(), port)) { } void Acceptor::accept(Socket& socket, IoHandler handler) { acceptor.async_accept(socket.socket, handler); } Here everything should be clear, except for the
readUntil method. In order to call asynchronous read on a socket several times, it is necessary to save the state. For this purpose, a special class is UntilHandler , which saves the current state of the asynchronous operation. A similar implementation can be found in boost.asio for various functions (for example, boost::asio::read ), which require several calls for simpler (but no less asynchronous) operations.In addition, you need to write an analogue
go and dispatch: void go(Handler); void dispatch(int threadCount = 0); Here you specify the handler that will be launched asynchronously in the thread pool and, in fact, the creation of a thread pool with subsequent dispatching.
Here is the implementation:
void go(Handler handler) { LOG("async::go"); service().post(std::move(handler)); } void run() { service().run(); } void dispatch(int threadCount) { int threads = threadCount > 0 ? threadCount : int(std::thread::hardware_concurrency()); RLOG("Threads: " << threads); for (int i = 1; i < threads; ++ i) sync::go(run); run(); } Here we use
sync::go to create threads from the synchronous approach.Server implementation:
Acceptor acceptor(8800); LOG("accepting"); Handler accepting = [&acceptor, &accepting] { struct Connection { Buffer buffer; Socket socket; void handling() { buffer.resize(4000); socket.readUntil(buffer, HTTP_DELIM_BODY, [this](const Error& error) { if (!!error) { LOG("error on reading: " << error.message()); delete this; return; } LOG("read"); buffer = httpContent("<h1>Hello async!</h1>"); socket.write(buffer, [this](const Error& error) { if (!!error) { LOG("error on writing: " << error.message()); delete this; return; } LOG("written"); handling(); }); }); } }; Connection* conn = new Connection; acceptor.accept(conn->socket, [conn, &accepting](const Error& error) { if (!!error) { LOG("error on accepting: " << error.message()); delete conn; return; } LOG("accepted"); conn->handling(); accepting(); }); }; accepting(); dispatch(); 
Here is a sheet. With each new challenge, nesting lambda grows. Usually, of course, they do not write this through lambdas, since there are difficulties with looping: it is necessary to forward oneself in lambda in order to call oneself within oneself. But nevertheless, the readability of the code will be about the same, i.e. equally bad when compared with synchronous code.
So, let's discuss the pros and cons of the asynchronous approach:
- The undoubted advantage (and this, in fact, for the sake of which all these torments) is productivity. And it is not just much higher, it is higher by orders of magnitude!
- Well, now the cons. There is only one minus - complicated and complicated code, which is also difficult to debug.
Well, of course, if everything is written correctly and it immediately worked and without bugs. But if this is not so ... In general, happy debugging, as they say in such cases. And I have also considered a fairly simple example where you can track the sequence of calls. With a slight complication of the processing scheme (for example, simultaneous reading and writing to sockets), the complexity of the code increases like a yeast, and the number of bugs starts to grow almost exponentially.
So is the game worth the candle? Is it worth doing asynchrony? In fact, there is a solution - coroutines or coroutines .
Coroutines

So, what do we all want?
It sounds great on paper. Is it possible? To answer the question we need a small introduction to coroutines.
What are the usual procedures? We are, therefore, in some place of performance, and here again, and called the procedure. To call, the current place to return is first remembered, then the procedure is called, it is executed, completed and returns to the place from which it was called. A coroutine is the same, only something else: it also returns control to the place from which it was called, but it does not end , but stops at a certain place from which it continues to work further when it is restarted. Those. it turns out a kind of ping-pong: the caller throws the ball, the coroutine catches it, runs to another place, throws it back, the caller also does something (crosses) and again throws the coroutines back to the previous place. And this happens until the coroutine is completed. In general, we can say that the procedure is a special case of the coroutine.
How can this be used now for our asynchronous tasks? Well here it suggests that the coroutine retains a certain execution context, which is extremely important for asynchrony. This is what I will use: if the coroutine needs to perform an asynchronous operation, then I will simply call the asynchronous method and exit the coroutine. And the handler upon completion of the asynchronous operation will simply continue execution of our coroutine from the place of the last call of that same asynchronous operation. Those. all the dirty work of preserving the context falls on the shoulders of the coroutine implementation.
And this is where the problems begin. The fact is that coroutine support on the side of languages and processors is a matter of bygone days. To implement the execution context switching, today it is necessary to do a lot of operations: save register states, switch the stack, and fill in some service fields for the execution environment to work correctly (for example, for exceptions, TLS , etc.). Moreover, the implementation depends not only on the processor architecture, but also on the compiler and the operating system. It sounds like the last nail in the coffin lid ...
Fortunately, there is boost.context , which implements everything that is needed to support a specific platform. Everything is written in assembler, in the best traditions. You can, of course, use boost.coroutine , but why, when there is boost.context ? More hell and bane!
Implementation of coroutines
So, for our purposes, we write our coroutines. The interface will be: // void yield(); // , bool isInsideCoro(); // struct Coro { // , friend void yield(); Coro(); // Coro(Handler); // ~Coro(); // void start(Handler); // ( yield) void resume(); // , bool isStarted() const; private: ... }; Here is a simple interface. Well, immediately use option:
void coro() { std::cout << '2'; yield(); std::cout << '4'; } std::cout << '1'; Coro c(coro); std::cout << '3'; c.resume(); std::cout << '5'; Must display on screen:
12345
Let's start with the
start method: void Coro::start(Handler handler) { VERIFY(!isStarted(), "Trying to start already started coro"); context = boost::context::make_fcontext(&stack.back(), stack.size(), &starterWrapper0); jump0(reinterpret_cast<intptr_t>(&handler)); } Here,
boost::context::make_fcontext creates a context for us and passes the starterWrapper0 static method as a starting function: TLS Coro* t_coro; void Coro::starterWrapper0(intptr_t p) { t_coro->starter0(p); } which simply redirects to the
starter0 method, retrieving the current Coro instance from TLS . All the magic of context switching is in the private jump0 method: void Coro::jump0(intptr_t p) { Coro* old = this; std::swap(old, t_coro); running = true; boost::context::jump_fcontext(&savedContext, context, p); running = false; std::swap(old, t_coro); if (exc != std::exception_ptr()) std::rethrow_exception(exc); } Here we replace the old TLS
t_coro value t_coro a new one (needed for recursive switching between several coroutines), set all sorts of flags and switch the context using boost::context::jump_fcontext . After completion, we restore the old values and throw exceptions into the calling function.Now we look at the private method
starter0 , which starts the necessary handler: void Coro::starter0(intptr_t p) { started = true; try { Handler handler = std::move(*reinterpret_cast<Handler*>(p)); handler(); } catch (...) { exc = std::current_exception(); } started = false; yield0(); } I will note one interesting point: if you do not save the handler inside the coroutine (before calling it), then the next time you return the program can safely fall. This is due to the fact that, generally speaking, the handler stores in itself some state that can be destroyed at some point.
Now it remains to consider the remaining functions:
// void yield() { VERIFY(isInsideCoro(), "yield() outside coro"); t_coro->yield0(); } // , bool isInsideCoro() { return t_coro != nullptr; } // yield void Coro::resume() { VERIFY(started, "Cannot resume: not started"); VERIFY(!running, "Cannot resume: in running state"); jump0(); } // , bool Coro::isStarted() const { return started || running; } // void Coro::yield0() { boost::context::jump_fcontext(context, &savedContext, 0); } Synca: async vice versa

Now it is the turn to realize asynchrony on coroutines. A trivial implementation is shown in the following diagram:

Here, a coroutine is created, then the coroutine starts an asynchronous operation and completes its work using the
yield() function. Upon completion of the operation, the coroutine continues its work by calling the resume() method.And everything would be fine if it were not for the notorious multithreading. As always happens, it introduces some turbulence, so the above approach will not work properly, as the following diagram illustrates:

Those. immediately after the operation sheduling, a handler can be called who will continue execution until exit from the coroutine. This, of course, was not part of our plans. Therefore it is necessary to complicate the sequence:
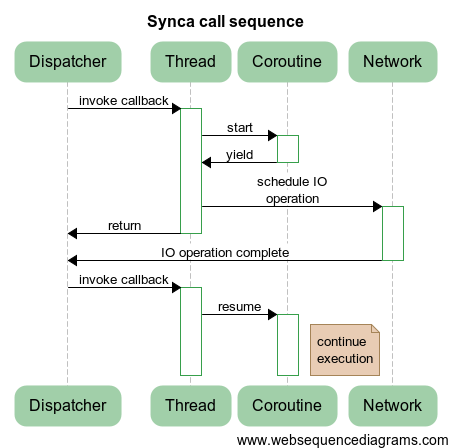
The difference lies in the fact that we do not start scheduling in the coroutine, but outside it, which excludes the possibility described above. At the same time, the continuation of the coroutine can occur in another thread, which is quite normal behavior. For this, the coroutines are designed to be able to hang around to and fro while keeping the execution context.
Small note
, boost.asio .
io_service::strand , . - , … , , .Implementation
go : void go(Handler handler) { LOG("synca::go"); async::go([handler] { coro::Coro* coro = new coro::Coro(std::move(handler)); onCoroComplete(coro); }); } .
onCoroComplete , , : typedef std::function<void(coro::Coro*)> CoroHandler; TLS CoroHandler* t_deferHandler; void onCoroComplete(coro::Coro* coro) { VERIFY(!coro::isInsideCoro(), "Complete inside coro"); VERIFY(coro->isStarted() == (t_deferHandler != nullptr), "Unexpected condition in defer/started state"); if (t_deferHandler != nullptr) { LOG("invoking defer handler"); (*t_deferHandler)(coro); t_deferHandler = nullptr; LOG("completed defer handler"); } else { LOG("nothing to do, deleting coro"); delete coro; } } : , - . — , — .
:
t_deferHandler ? : TLS const Error* t_error; void handleError() { if (t_error) throw boost::system::system_error(*t_error, "synca"); } void defer(CoroHandler handler) { VERIFY(coro::isInsideCoro(), "defer() outside coro"); VERIFY(t_deferHandler == nullptr, "There is unexecuted defer handler"); t_deferHandler = &handler; coro::yield(); handleError(); } . , , .. . , (
coro::yield ), onCoroComplete , . defer Socket::accept : void onComplete(coro::Coro* coro, const Error& error) { LOG("async completed, coro: " << coro << ", error: " << error.message()); VERIFY(coro != nullptr, "Coro is null"); VERIFY(!coro::isInsideCoro(), "Completion inside coro"); t_error = error ? &error : nullptr; coro->resume(); LOG("after resume"); onCoroComplete(coro); } async::IoHandler onCompleteHandler(coro::Coro* coro) { return [coro](const Error& error) { onComplete(coro, error); }; } void Acceptor::accept(Socket& socket) { VERIFY(coro::isInsideCoro(), "accept must be called inside coro"); defer([this, &socket](coro::Coro* coro) { VERIFY(!coro::isInsideCoro(), "accept completion must be called outside coro"); acceptor.accept(socket.socket, onCompleteHandler(coro)); LOG("accept scheduled"); }); } onCompleteHandler , . t_error , (. handleError defer ), coro->resume() , .. defer yield() . :
:
void Socket::readSome(Buffer& buffer) { VERIFY(coro::isInsideCoro(), "readSome must be called inside coro"); defer([this, &buffer](coro::Coro* coro) { VERIFY(!coro::isInsideCoro(), "readSome completion must be called outside coro"); socket.readSome(buffer, onCompleteHandler(coro)); LOG("readSome scheduled"); }); } void Socket::readUntil(Buffer& buffer, Buffer until) { VERIFY(coro::isInsideCoro(), "readUntil must be called inside coro"); defer([this, &buffer, until](coro::Coro* coro) { VERIFY(!coro::isInsideCoro(), "readUntil completion must be called outside coro"); socket.readUntil(buffer, std::move(until), onCompleteHandler(coro)); LOG("readUntil scheduled"); }); } void Socket::write(const Buffer& buffer) { VERIFY(coro::isInsideCoro(), "write must be called inside coro"); defer([this, &buffer](coro::Coro* coro) { VERIFY(!coro::isInsideCoro(), "write completion must be called outside coro"); socket.write(buffer, onCompleteHandler(coro)); LOG("write scheduled"); }); } async::Socket async::Acceptor , .Using
. : Acceptor acceptor(8800); LOG("accepting"); go([&acceptor] { while (true) { Socket* toAccept = new Socket; acceptor.accept(*toAccept); LOG("accepted"); go([toAccept] { try { Socket socket = std::move(*toAccept); delete toAccept; Buffer buffer; while (true) { buffer.resize(4000); socket.readUntil(buffer, HTTP_DELIM_BODY); socket.write(httpContent("<h1>Hello synca!</h1>")); } } catch (std::exception& e) { LOG("error: " << e.what()); } }); } }); dispatch(); - … ! :
sync | synca |
|---|---|
| |
dispatch . , , : , go , dispatch .: , . : , , .. .

. , : , , , .
goAccept : async::IoHandler onCompleteGoHandler(coro::Coro* coro, Handler handler) { return [coro, handler](const Error& error) { if (!error) go(std::move(handler)); onComplete(coro, error); }; } struct Acceptor { typedef std::function<void(Socket&)> Handler; // ... }; void Acceptor::goAccept(Handler handler) { VERIFY(coro::isInsideCoro(), "goAccept must be called inside coro"); defer([this, handler](coro::Coro* coro) { VERIFY(!coro::isInsideCoro(), "goAccept completion must be called outside coro"); Socket* socket = new Socket; acceptor.accept(socket->socket, onCompleteGoHandler(coro, [socket, handler] { Socket s = std::move(*socket); delete socket; handler(s); })); LOG("accept scheduled"); }); } :
Acceptor acceptor(8800); LOG("accepting"); go([&acceptor] { while (true) { acceptor.goAccept([](Socket& socket) { try { Buffer buffer; while (true) { buffer.resize(4000); socket.readUntil(buffer, HTTP_DELIM_BODY); socket.write(httpContent("<h1>Hello synca!</h1>")); } } catch (std::exception& e) { LOG("error: " << e.what()); } }); } }); dispatch(); .
1. ?

, , / .
, , (!!!) , . :
- 30K RPS (.. 30 ).
asyncsynca.
:
| Method | |||
|---|---|---|---|
| async | 30,000 | one | 75±5% |
| synca | 30,000 | one | 80±5% |
, , ( , .. ) . , HTTP , , - , , .
2. . ?
. .

.
, . , .. . - . :
// async(..., handler); // , :
// async(..., handler); :
// synca(...); handler(); Those.
synca async , , handler() . ., . :
// go { async(..., handler); } // ,
async go , : // go { synca(...); handler(); } // Those. . . ...
findings
. , , . , : ., !
!

PS : bitbucket:gridem/synca
Source: https://habr.com/ru/post/201826/
All Articles