Hadoop clusters on demand from the cloud: internal device, first steps, tasks, Hive

Some time ago, at the Strata + Hadoop World conference, the launch of Windows Azure HDInsight , a 100% Apache Hadoop-compatible cloud service, was announced . Details about the history of the appearance of the service and its capabilities can be found in this article on Habré. About the announcements of the Strata + Hadoop World conference can be found in another fresh article .
This article will focus on the internal structure of HDInsight clusters, start working with them and the first tasks and requests for Hive. At the end of the article are real examples of the use of Windows Azure HDInsight by large international organizations.
Windows Azure HDInsight offers the following benefits to its users:
- Working with big data using familiar tools: thanks to deep integration with Microsoft's business intelligence tools such as PowerPivot, Power View and Excel, HDInsight allows you to easily analyze your data using the capabilities of Hadoop. Transparently combine data from various data sources, including HDInsight using Power Query. Easily analyze and visualize geographic data using Power Map - a new 3D mapping tool in Excel 2013;
- Flexibility - HDInsight offers the flexibility to match the changing needs of your organization. With a rich set of PowerShell scripts, you can host and administer a Hadoop cluster in minutes, instead of the usual hours or even days. If you need a larger cluster, simply delete the existing one and create a new one in the required size within a few minutes without losing any data;
- Enterprise Level Hadoop : HDInsight offers enterprise level security and manageability. With a dedicated Secure Node, HDInsight helps secure your Hadoop cluster. In addition, we have simplified the management of your Hadoop cluster with an impressive set of PowerShell scripts;
- Rich opportunities for developers : HDInsight offers powerful capabilities for developing applications with a rich choice of languages, including .NET, Java and others. Developers on the .NET platform can take advantage of LINQ to Hive queries.
About Windows Azure HDInsight
Windows Azure HDInsight is a 100% compatible Apache Hadoop distribution available on the Windows Azure platform as a service. Instead of building its own distribution, Microsoft chose a partnership with Hortonworks to port Apache Hadoop to the Windows platform. Micrsoft has invested more than 6,000 man-hours and over 25,000 lines of code in various Apache Hadoop ecosystem projects.
')

One of Microsoft’s most notable contributions is the development of Windows Azure Storage-Blob (WASB) , a thin layer that represents Windows Azure storage blob blocks as the HDFS file system of your Windows Azure HDInsight cluster. Microsoft is also actively participating and investing in the Hive Stinger project and is working to achieve better security integration on the Windows platform.
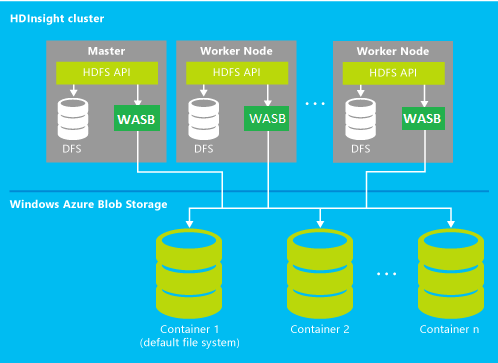
The architecture of the cluster in the cloud, obtained on request as a service is presented in the following picture:

The figure shows the following elements:
Secure Role or Gateway Node is a reverse proxy that works as a gateway to your Hadoop cluster. Secure Role is responsible for authentication and authorization tasks and provides endpoints for WebHcat, Ambari, HiveServer, HiveServer2 and Oozie on port 433. In order to connect to the cluster, you use your credentials specified when creating the cluster;
Head Node is a node represented by an Extra Large virtual machine (8 cores, 14 GB RAM). In HDInsight Head Node performs an important role, taking on the key functions of the Hadoop cluster: NameNode, Secondary NameNode and JobTracker. Head Node contains and executes the following operational and data services:
- HiveServer and HiveServer2
- Pig
- Sqoop
- Metastore
- Derbyserver
- Oozie
- Templeton
- Ambari
Worker Nodes are nodes represented by Large virtual machines (4 cores, 7 GB RAM). Worker Roles is responsible for launching services that support task scheduling, task execution, and data access:
- Tasktracker
- DataNode
- Pig
- Hive client
Windows Azure Storage-BLOB (WASB) —The default file system in your Windows Azure HDInsight cluster is represented as Windows Azure Blob Storage. Microsoft implemented a thin layer on top of Blog Storage, which represents storage in the form of an HDFS file system, which we call Windows Azure Storage-Blob or WASB.
The great news is that you can interact with WASB using DFS commands using the Blob Storage REST API or through numerous popular utilities .
Another remarkable feature of WASB is that all the data you store in it will be available to the HDInsight cluster, and after its deletion will remain intact. If you want to delete the cluster and then re-create a new one, then you can simply point the old cluster to the old data and use it.
It is cheaper to store data in WASB, because when working with them there is no need to pay for outgoing traffic or computing power required when working with local HDFS storage inside virtual machines.
Finally, storing data in WASB will allow you to share it with other cloud services or applications running outside of your cluster. The reverse is also true: data stored in Windows Azure Storage from other services can be easily obtained in an HDInsight cluster.
Details on the benefits of using WASB can be found at the following link .
Local HDFS - except for WASB in the HDInsight cluster, you also have access to local HDFS storage, but its use is not encouraged, as it is more expensive (working with it equals cluster operation) and everything that is stored in the local HDFS will be deleted along with the cluster when you refuse it.
Application versions available in HDInsight . Today, within the Hadoop cluster in the HDInsight service, the following versions of applications and services are available to you on request:
Component | Version |
Apache hadoop | 1.2.0 |
Apache heve | 0.11.0 |
Apache pig | 0.11 |
Apache sqoop | 1.4.3 |
Apache oozie | 3.2.2 |
Apache hcatalog | Merged with hive |
Apache templeton | 0.1.4 |
SQL Server JDBC Driver | 3.0 |
Ambari | API v1.0 |
You can always find the latest version information on the HDInsight cluster components at the following link .
Getting started with HDInsight
An HDInsight cluster can be created from the Windows Azure Management Portal by selecting HDInsight from the Data Services menu. In order to create a cluster, you need to specify the name, cluster size and number of data nodes (Data Nodes), password to access the cluster.
A cluster must contain at least one associated Windows Azure Storage, which will be the permanent storage location for this cluster, and the cluster and the storage must be located in the same region. You can associate additional storage for the cluster using the custom cluster creation option.

Deploying and configuring a cluster in the cloud will only take a few minutes. As soon as it is deployed, you can go to the welcome page, which offers additional links to useful resources and code examples that you can practice working with Hadoop.
On the Dashboard tab, you will see information about the current status of your cluster, including various metrics: node consumption, task history, and associated data stores.

Run the first Map / Reduce task for your cluster
Before you run your first task in a cluster, you need to prepare your environment for using PowerShell cmdlets. To work with these cmdlets, you need to install Windows Azure Powershell and HDInsight PowerShell. To do this, simply follow the links in “Step 1” of your welcome page in the Windows Azure Cluster Control Panel.
On the welcome page, you can also find sample commands for working with both Hive and MapReduce tasks. We will start working with MapReduce.
Run the example using the following commands to create job definitions (job definition). Definitional tasks contain all the information needed for the task, for example, which mappers or reducers to use, which data to use as input and where to place the output data. In the sample code, we use the MapReduce program and a test file that is already contained in the cluster. We will also create a directory to save the output.
$ jarFile = "/example/jars/hadoop-examples.jar"
$ className = "wordcount"
$ statusDirectory = "/ samples / wordcount / status"
$ outputDirectory = "/ samples / wordcount / output"
$ inputDirectory = "/ example / data / gutenberg"
$ wordCount = New - AzureHDInsightMapReduceJobDefinition - JarFile $ jarFile - ClassName
$ className - Arguments $ inputDirectory , $ outputDirectory - StatusFolder $ statusDirectory
Run the following commands to get information about your Windows Azure subscription and to start running the MapReduce program. MapReduce tasks usually last a long time, here we use an example to demonstrate how to use asynchronous commands to start a task.
$ subscriptionId = ( Get - AzureSubscription - Current ) . SubscriptionId
$ wordCountJob = $ wordCount | Start - AzureHDInsightJob - Cluster HadoopIsAwesome -
Subscription $ subscriptionId | Wait - AzureHDInsightJob - Subscription $ subscriptionId
Finally, run the following command to get and display all the results of the task.
Get - AzureHDInsightJobOutput - Subscription ( Get - AzureSubscription - Current ) . SubscriptionId
- Cluster bc - newhdstorage - JobId $ wordCountJob . JobId –StandardError
The result of this command and the output of the task execution information you will see in the terminal, as shown below.

The output of the task was placed in your repository in the "/ samples / wordcount / output ” directory. Open the repository viewer in the Windows Azure portal and browse to this file to download it and examine the contents.

Creating the first Hive task
On the start page there are examples of commands for connecting to a cluster and launching Hive tasks. Click on the Hive button in the Job Type switch to access the example.

Run the following command to connect to your cluster.
Use - AzureHDInsightCluster HadoopIsAwesome ( Get - AzureSubscription - Current ) . SubscriptionID
Then run the following command to launch the HiveQL query to the cluster. This query uses a test table that is already placed in the cluster when it is created.
Invoke - Hive "select country, state, count (*)
This query is an example of a simple query with select and group by, after its execution you will see the results in the PowerShell window:

Learn more about Windows Azure HDInsight
In this article, we looked at how easy it is to create and run an HDInsight cluster and start analyzing your data. But HDInsight offers significantly more features that you can explore, such as downloading your own data sets, running complex sophisticated tasks, and analyzing results. To learn more about how to work with HDInsight, visit the documentation page or use the following direct links to articles (in English):
- Getting started with the HDInsight service
- HDInsight Cluster Management
- Hadoop software task assignment
- Connect Excel to Windows Azure HDInsight using Power Query
Articles in Russian are available on the portal AzureHub.ru:
- Introduction to Windows Azure HDInsight
- Microsoft HDInsight. The cloudy (and not only) future of Hadoop
- MapReduce for processing semistructured data in HDInsight
- Cloud recommendation system using Hadoop and Apache Mahout
- Executing Hadoop Tasks in Windows Azure, Analyzing Data Using Excel Hive
- Analyzing Twitter data in the cloud using Apache Hadoop and Hive
For pricing information on the Windows Azure HDInsight service, visit this page .
The article partially used information from
This article is the official blog.
Examples of using Windows Azure HDInsight
Despite the fact that the commercial availability of the service was announced recently, a large number of companies and organizations have already tried the service at the preview stage. Among them, the following examples can be singled out:
The city of Barcelona chose Microsoft's business intelligence and big data processing tools, including Windows Azure HDInsight. Announcement and detailed description of the example;
Virginia Polytechnic Institute uses HDInsight to process genome data. Detailed description of the example ;
Danish research organization Chr. Hansen, a developer of natural ingredients for food, pharmacological, and agricultural industries, uses Windows Azure HDInsight to increase data processing speeds by a factor of 100 compared to its previous method. Detailed description of the example .
Company 343 Industries - Halo 4 game developers are using Windows Azure HDInsight to conduct analytical research based on data from over 50 million copies of Halo games sold to make online services even better. Detailed description of the example .
Medical company Ascribe Ltd from the UK - a leader in its field - uses Windows Azure HDInsight to improve the quality of clinical research, offering researchers a much faster way to process large data from a large number of sources. Detailed description of the example .
useful links
Below you will find links to resources that will help you in using the Microsoft cloud platform:
- Free 30-day trial of Windows Azure;
- Free access to Windows Azure resources for startups , partners , teachers, MSDN subscribers ;
- Windows Azure Development Center (azurehub.ru) - scripts, tutorials, examples, recommendations on the choice of services and development on Windows Azure;
- Latest Windows Azure News - Twitter.com/windowsazure_ru .
And if you are already developing on Windows Azure or want to find the developers of your service, visit appprofessionals.ru .
We will be happy to answer your questions at azurerus@microsoft.com . And we are waiting for you in the Windows Azure Community on Facebook . Here you will find experts (don't forget to ask them questions), photos, and lots and lots of news.
Source: https://habr.com/ru/post/200750/
All Articles