PACT Conference (Parallel Architects and Compilation Techniques) 2013. Attendance Report

The 7th International Conference on Parallel Architectures and Compilation Techniques (PACT) was held from 7 to 11 September in Edinburgh, Scotland. The conference consisted of two parts: Workshops / Tutorials and the main part. I managed to visit the main part, which I would like to talk about.
The PACT conference is one of the largest and most significant in its field. The list of conference topics is extensive:
- Parallel architectures and computational models
- Tools (compilers, etc.) for parallel computer systems
- Architectures: multi-core, multi-threaded, superscalar and VLIW
- Languages and algorithms for parallel programming
- And so on and so forth, which is connected with parallelism in software and in hardware
The conference is held under the auspices of organizations such as IEEE, ACM and IFIP. The list of sponsors of the last conference includes very well-known corporations:
')

A few words about the venue. The conference was held in the historic part of Edinburgh, the old city, the building of surgeons (Surgeons' Hall):

The city impresses both with its beauty and the number of famous people associated with it. Conan Doyle, Walter Scott, Robert Louis Stevenson, JK Rowling, Sean Connery. About them and other historical figures you will be happy to tell in this city. The first thing that comes to mind when you hear Scotland is whiskey. Here you understand that whiskey is an integral part of the Scottish culture. He is everywhere, even in the conference participant’s kit there was a small bottle of single malt whiskey:

Key speakers and winners of the student competition received a full-sized bottle of excellent whiskey.
Key reports
A Comprehensive Approach to HW / SW Codesign
David J. Kuck (Intel Fellow) in his report touched on the topic of computer systems analysis by formal methods. Optimization of computer system parameters is carried out mainly by empirical methods. David Kuck proposes a methodology for constructing mathematical models of the HW / SW system described by a system of nonlinear equations. The methodology was implemented in the Cape software system, which accelerates the search for optimal solutions to the problems of computer systems design.
Parallel Programming for Mobile Computing
Câlin Caşcaval (Director of Engineering at the Qualcomm Silicon Valley Research Center) talked about the problems of paralleling computing on mobile devices. After researching mobile usage scenarios, Qualcomm offers his vision of the mobile software stack:
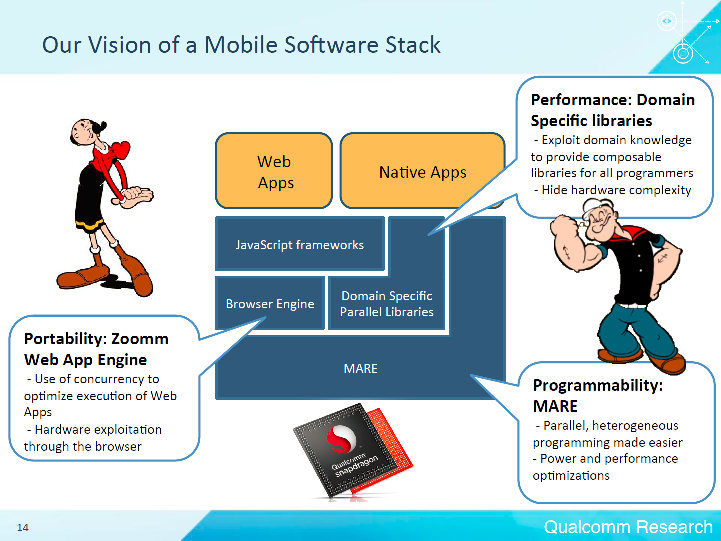
A key component of the system is the MARE - Multicore Asynchronous Runtime Environment. MARE provides a C ++ API for parallel programming and a runtime environment that optimizes the execution of a program on a heterogeneous SoC. We can say that this is an analogue of the Intel Threading Building Blocks (Intel TBB) .
Towards Automatic Resource Management in Parallel Architectures
Per Stenström (Chalmers University of Technology, Sweden) in his report “Towards Automatic Resource Management in Parallel Architectures” addressed some of the problems that will have to be faced in the framework of current trends in the development of parallel architectures.
According to forecasts, the number of cores in the processor will grow linearly in the coming years and will reach 100 cores by 2020. At the same time restrictions on energy consumption will be tightened. Despite the increase in the number of cores, the increase in memory bandwidth slows down. To achieve efficient use of processor resources, you need to parallelize programs to the maximum.
The programmer parallelizes the program, the compiler maps the program to a certain model of parallel computing, and the execution environment performs balancing. Heterogeneous processors have good energy efficiency potential. For parallel architectures, the speed of the memory subsystem becomes an acute problem. According to research, a large percentage of data in memory and caches are duplicated. Per Stenström suggests using a compressed cache as the last level caches (LLC). When using such caches, there is a twofold acceleration of program execution.
Key reports
Reports were divided into sections:
- Compilers
- Power and energy
- GPU and Energy
- Memory System Management
- Runtime and Scheduling
- Caches and Memory Hierarchy
- GPU
- Networking, Debugging and Microarchitecture
- Compiler optimization
It was necessary to choose which sections to visit, as part of the sections were going at the same time.
Below are the sections that I attended and the reports that interested me.
Compilers
Interesting was the report “Parallel Flow-Sensitive Pointer Analysis by Graph-Rewriting” (Indian Institute of Science, Bangalore) on paralleling the algorithm for analyzing pointers to aliasing. “Flow-Sensitive Pointer Analysis” means analyzing the pointers according to the order of operations. At each point of the program, a set of “points-to” is calculated. In contrast, with “Flow-Insensitive Pointer Analysis”, one set of “points-to” is built for the entire program. Pointers to aliasing can be analyzed on a graph, where vertices are program variables, and arcs are relationships between variables of one type: taking an address, copying a pointer, loading data by a pointer, writing data on a pointer. The authors of the report showed that modifying this graph according to certain rules, you can get a graph on which you can conduct a parallel analysis of pointers.
GPU and Energy
An interesting report "Parallel Frame Rendering: Trading Responsiveness for Energy on a Mobile GPU" (Universitat Politecnica de Catalunya, Intel) about paralleling the frame calculation on mobile processors with integrated graphics and problems faced by the developers.
The report "Exploring Hybrid Memory for Energy Efficiency through Hardware-Hardware Co-Design" (Auburn University, College of William and Mary, Oakridge National Lab) on the study of hybrid memory DRAM + PCM, which consumes less energy than only DRAM or PCM, having a performance of just 2% less than DRAM. Phase Change Memory (PCM) is better than DRAM in terms of power consumption, but worse in performance.
Runtime and Scheduling
"Fairness-Aware Scheduling on Single-ISA Heterogeneous Multi-Cores" (Ghent University, Intel) - traditional methods of dispatching threads are not quite suitable for heterogeneous multi-core processors. The report describes dynamic dispatching of threads, allowing to achieve the same progress of execution of each thread, which positively affects the performance of the application as a whole.
"An Empirical Model for Predicting Cross-Core Performance Interference on Multicore Processors" (Institute of Computing Technology, University of New South Wales, Huawei) - using machine learning methods to obtain a function that predicts a drop in application performance when used together with other applications.
Networking, Debugging & Microarchitecture
The report “A Debugging Technique for Every Parallel Programmer” (Intel) showed how using the Concurrent Predicates (CP) technique can significantly increase the reproducibility of bugs in multi-threaded applications. Impressed with the results of using this technique for analyzing real bugs:
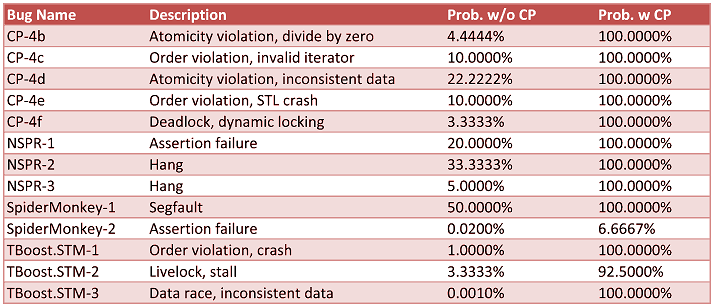
The third column is the probability of reproducing a bug without CP equipment. The fourth column is using the CP technique.
Compiler optimization
“Vectorization Past Dependent Branches Through Speculation” (University of Texas - San Antonio, University of Colorado) - a report on SIMD vectorization of cycles with simple conditional transitions in the body of a cycle. The loop contains a path that can be vectorized and which is executed in successive iterations. Based on this path, a new cycle is created. If during the execution of a cycle a situation arises where in several successive iterations different paths will be executed, then these iterations will be executed by the original unmodified loop.
Top Papers
Separately from the main reports, the best reports session was held. Of these, I would like to highlight two reports:
- "A Unified View of Selection and Application of Heterogeneous Chip Multiprocessors" (Qualcomm, North Carolina State University) - a study on finding the optimal parameters of a heterogeneous processor. It also describes a system for dynamic detection of application bottlenecks and movement of application computing threads from one core to another to eliminate bottlenecks.
- "SMT-Centric Power-Aware Thread Placement in Chip Multiprocessors" (IBM) - in multi-core processors, power consumption can be reduced by dynamically changing the voltage / frequency of the cores, or by turning off the cores. The report discusses how using these techniques together and separately can make a significant improvement in the power-performance ratio.
Conclusion
The overall impression of the conference is positive. A large number of interesting reports. Understanding what is happening in academia and in large corporations. People with whom it was interesting to talk. Helpful contacts ensued. We were pleased with the well-organized cultural program: dinners and excursions in the city, museums. Stormy emotions caused the after-party in the Museum of Surgery with an extensive collection of items treated surgically. For people “with iron nerves”, a night tour of the dungeons of Edinburgh was organized. It was nice to meet guys from Russia (MIPT and MCST) at the competition of student works.
Next year the conference will be held in Edmonton, Canada. The organizers promised to hold a conference at the same high level.
Links
PACT 2013 Home
PACT 2013 Program
PACT 2014 Home
Source: https://habr.com/ru/post/199534/
All Articles