How we accelerated the search in Yandex. Mail and at the same time released 25 servers
We have already written about how the search for letters in Yandex.Mail is organized . Since then, many things have changed and improved, so we decided to share our experience and tell you about these changes.
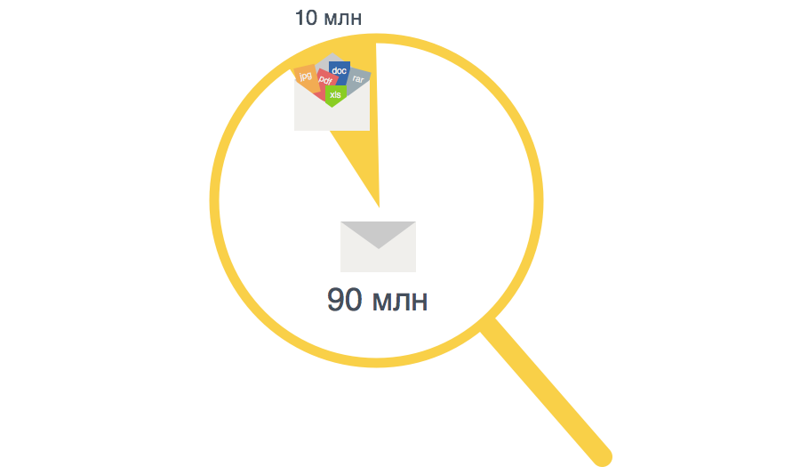
On the day about 100M of letters arrive at the Post, 10M of which - with attachments. Despite the fact that only 10% of letters contain an attachment, among the letters with attachments there is a significant proportion of those in which there is more than one file. On average, it turns out that the total number of letters is equal to the total number of attachments to them.
')
The average letter size with an attachment is 400 kb, and a letter without an attachment is 4 kb. The total size of attachments in one letter can reach 30 mb. TOP 10 types of attachments: .jpg, .pdf, .xls, .rar, .doc, .zip, .eml, .mp3, .tif, .docx. Almost all file formats, except text, contain a significant amount of redundant service information. So, for example: .docx format, contains on average only 10% of textual information, and from jpg we get only 0.25% of meta information for indexing into the search.
This gives a total volume of incoming traffic of about 25 TB per day, which increases several times to ensure the operation of a large and complex product Mail. To service such a load, Yandex.Mail has a large network, server and service infrastructure, which includes several clusters distributed across different data centers.
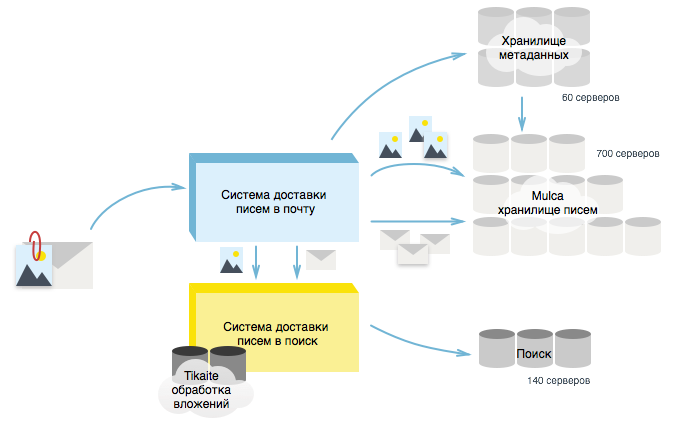
All incoming emails get into the delivery system - a cluster consisting of hundreds of servers. The delivery system tries to save letters in the store of letters, the storehouse of meta-information about letters and send them to the search — that is, to three different places at once, each of which performs its own tasks.
The storage of letters is responsible for the storage and return on request of the entire contents of each letter and for some reason is historically called mulca. For storage of letters in Yandex. Mail 700 millechny servers are unrolled. The contents of the letters, headers, attachments are stored here - in one word, everything related to the letter.
Meta-information storage serves for quick display of inbox and contains only the narrative of the letter. For example, the fields “From whom”, “To”, “Subject”, the name of the folder in which the letter is located at the moment, its current label, the date of writing, etc. Meta-cluster occupies 60 servers.
Search storage is a search index that contains all the information from a letter that is needed to provide a quick full-text search by mailbox, taking into account the morphology. Search service, performing the task of indexing and searching, are engaged in one hundred forty servers simultaneously.
A letter is considered to have been delivered if it has fallen into the store of letters and the storehouse of meta-information. Delivery of letters in the search is carried out after laying in storage. A separate Services cluster consisting of twenty-five servers is allocated for the delivery of letters to the search. On this cluster there are queues of letters awaiting indexation and programs that prepare data for indexing.
Thus, letters, getting into the mail, go a long way. First, they are added to the repository, then they fall into the Services cluster, and there they are preparing to be sent to the search.
But a search by letters is not only a search by the body of the letter , but also a search by the contents of attachments. To provide it, the files sent as an attachment must be pre-processed, text extracted and sent as a text search.
A few years ago, without changing the above-mentioned original architecture, we launched a search for the contents of attachments. This caused a number of problems. First, some types of files (especially .pdf) were processed for a long time - up to several minutes, and slowed down the delivery of new letters to the search. Secondly, there was a constant competition for resources between the indexing program and the conversion program on the Services cluster, which also slowed down the number of new letters in the search. And thirdly, when we started sending the entire letter with attachments to the Services cluster, we actually doubled the mail traffic within Yandex networks. Intranet traffic has increased by 25 TB per day, and this is a burden on resources useful for personal services and for Yandex as a whole: servers, network infrastructure and total network performance.
So, we had to fight for the quality of the service. It was impossible to let the letters come to the search after minutes. Moreover, before launching a search on attachments, 95% of all incoming emails got into the search in less than a second.
There was a thought to deliver letters entirely to the repository, and to search only for structured text directly from the repositories. Preliminary studies have shown that the average size of the text required for the search is 10 times smaller than the average size of the letter in the mail. Therefore, if only text is sent to the search, then the network traffic consumed by the search will be 10 times less, which will save approximately 22 TB per day. It seems that for the sake of saving traffic the game is worth the candle.
It was also a tempting idea to use the storage performance by two orders of magnitude greater than a small Services cluster to pre-process files for search. This would allow us to accelerate. So did.
In order for the voiced idea to be implemented, and we could receive the contents of letters and attachments directly from the repository, it was necessary to place a program for extracting the contents of attachments on its servers. This program is based on the Apache Tika library , so for simplicity and consonance with the Russian language, the developer called it Tikaite. Placing Tikaite on mulca-s it was important not to harm the storage of letters, so we studied the load in detail and saw that the storages are loaded in disk space and have sufficient free CPU performance that you can use.
We placed in the storage a program for extracting text from various formats with severe restrictions: the program was provided with 50% of the processor performance and 1 GB of RAM was allocated on each of the servers. Such restrictions allowed us to start the conversion process to the storage and did not interfere with the storage process.
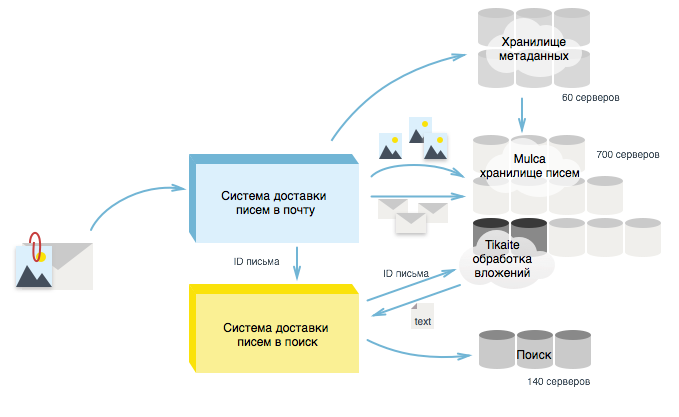
As a result, we reduced parasitic intranet traffic and increased the performance of the email delivery system in the search by two orders of magnitude - again 95% of emails began to fall into the search within a second. For delivery, we received an additional bonus in 25 free servers of the mail delivery cluster in the search. If initially we planned to increase the Services cluster by 2 times and get 50 servers here to cope with the ever-increasing flow, now that all the data necessary for the search is being prepared directly into the storage of letters, we actually have a whole cluster of 25 servers free. So in the near future we will be able to use it for other tasks, which we will certainly tell about.
PS And to search by mail, it is periodically necessary to re-index all the emails that have been accumulated over the entire existence of Yandex.Mail. This happens when it is necessary to change the search algorithm, and there is not enough data in the search for this. At this time we are actually processing the entire array of letters stored in the mail, and this is now about 10 petabytes. And it is here that it turns out just a huge savings in network traffic and performance.
PPS Despite the results, we do not plan to stop there. We will strive to make the delivery of letters to the search at the same time as they are laid in the repository and for this we will use the vacant cluster. Wait for information about this in the new publications about search in Yandex. Mail.
On the day about 100M of letters arrive at the Post, 10M of which - with attachments. Despite the fact that only 10% of letters contain an attachment, among the letters with attachments there is a significant proportion of those in which there is more than one file. On average, it turns out that the total number of letters is equal to the total number of attachments to them.
')
The average letter size with an attachment is 400 kb, and a letter without an attachment is 4 kb. The total size of attachments in one letter can reach 30 mb. TOP 10 types of attachments: .jpg, .pdf, .xls, .rar, .doc, .zip, .eml, .mp3, .tif, .docx. Almost all file formats, except text, contain a significant amount of redundant service information. So, for example: .docx format, contains on average only 10% of textual information, and from jpg we get only 0.25% of meta information for indexing into the search.
This gives a total volume of incoming traffic of about 25 TB per day, which increases several times to ensure the operation of a large and complex product Mail. To service such a load, Yandex.Mail has a large network, server and service infrastructure, which includes several clusters distributed across different data centers.
All incoming emails get into the delivery system - a cluster consisting of hundreds of servers. The delivery system tries to save letters in the store of letters, the storehouse of meta-information about letters and send them to the search — that is, to three different places at once, each of which performs its own tasks.
The storage of letters is responsible for the storage and return on request of the entire contents of each letter and for some reason is historically called mulca. For storage of letters in Yandex. Mail 700 millechny servers are unrolled. The contents of the letters, headers, attachments are stored here - in one word, everything related to the letter.
Meta-information storage serves for quick display of inbox and contains only the narrative of the letter. For example, the fields “From whom”, “To”, “Subject”, the name of the folder in which the letter is located at the moment, its current label, the date of writing, etc. Meta-cluster occupies 60 servers.
Search storage is a search index that contains all the information from a letter that is needed to provide a quick full-text search by mailbox, taking into account the morphology. Search service, performing the task of indexing and searching, are engaged in one hundred forty servers simultaneously.
A letter is considered to have been delivered if it has fallen into the store of letters and the storehouse of meta-information. Delivery of letters in the search is carried out after laying in storage. A separate Services cluster consisting of twenty-five servers is allocated for the delivery of letters to the search. On this cluster there are queues of letters awaiting indexation and programs that prepare data for indexing.
Thus, letters, getting into the mail, go a long way. First, they are added to the repository, then they fall into the Services cluster, and there they are preparing to be sent to the search.
But a search by letters is not only a search by the body of the letter , but also a search by the contents of attachments. To provide it, the files sent as an attachment must be pre-processed, text extracted and sent as a text search.
A few years ago, without changing the above-mentioned original architecture, we launched a search for the contents of attachments. This caused a number of problems. First, some types of files (especially .pdf) were processed for a long time - up to several minutes, and slowed down the delivery of new letters to the search. Secondly, there was a constant competition for resources between the indexing program and the conversion program on the Services cluster, which also slowed down the number of new letters in the search. And thirdly, when we started sending the entire letter with attachments to the Services cluster, we actually doubled the mail traffic within Yandex networks. Intranet traffic has increased by 25 TB per day, and this is a burden on resources useful for personal services and for Yandex as a whole: servers, network infrastructure and total network performance.
So, we had to fight for the quality of the service. It was impossible to let the letters come to the search after minutes. Moreover, before launching a search on attachments, 95% of all incoming emails got into the search in less than a second.
There was a thought to deliver letters entirely to the repository, and to search only for structured text directly from the repositories. Preliminary studies have shown that the average size of the text required for the search is 10 times smaller than the average size of the letter in the mail. Therefore, if only text is sent to the search, then the network traffic consumed by the search will be 10 times less, which will save approximately 22 TB per day. It seems that for the sake of saving traffic the game is worth the candle.
It was also a tempting idea to use the storage performance by two orders of magnitude greater than a small Services cluster to pre-process files for search. This would allow us to accelerate. So did.
In order for the voiced idea to be implemented, and we could receive the contents of letters and attachments directly from the repository, it was necessary to place a program for extracting the contents of attachments on its servers. This program is based on the Apache Tika library , so for simplicity and consonance with the Russian language, the developer called it Tikaite. Placing Tikaite on mulca-s it was important not to harm the storage of letters, so we studied the load in detail and saw that the storages are loaded in disk space and have sufficient free CPU performance that you can use.
We placed in the storage a program for extracting text from various formats with severe restrictions: the program was provided with 50% of the processor performance and 1 GB of RAM was allocated on each of the servers. Such restrictions allowed us to start the conversion process to the storage and did not interfere with the storage process.
As a result, we reduced parasitic intranet traffic and increased the performance of the email delivery system in the search by two orders of magnitude - again 95% of emails began to fall into the search within a second. For delivery, we received an additional bonus in 25 free servers of the mail delivery cluster in the search. If initially we planned to increase the Services cluster by 2 times and get 50 servers here to cope with the ever-increasing flow, now that all the data necessary for the search is being prepared directly into the storage of letters, we actually have a whole cluster of 25 servers free. So in the near future we will be able to use it for other tasks, which we will certainly tell about.
PS And to search by mail, it is periodically necessary to re-index all the emails that have been accumulated over the entire existence of Yandex.Mail. This happens when it is necessary to change the search algorithm, and there is not enough data in the search for this. At this time we are actually processing the entire array of letters stored in the mail, and this is now about 10 petabytes. And it is here that it turns out just a huge savings in network traffic and performance.
PPS Despite the results, we do not plan to stop there. We will strive to make the delivery of letters to the search at the same time as they are laid in the repository and for this we will use the vacant cluster. Wait for information about this in the new publications about search in Yandex. Mail.
Source: https://habr.com/ru/post/199432/
All Articles