Prevent participation in dns amplification attack or experience in writing nuclear code
Introduction
In this article I want to talk about a rather obvious, as it seems to me, method of filtering the dns amplification attack, and about a small module that was written to implement the idea.
The fact that such a dns amplification attack has been written more than once, for example, here ; many faced this, many struggled, someone more successfully, someone less. The attack is based on sending a DNS request to any DNS server with the ip address of the source equal to the ip address of the victim. The response from the DNS server is almost always greater than the request, especially considering that attackers usually execute ANY requests. AAAA records are not uncommon, SPF and other information in TXT records, all this makes it quite easy to get a gain of 5 or more times. For the attacker, it looks very tempting, you can make a good dos, even without a large botnet. It can be very long to argue why IP addresses can be spoofed on the Internet, but the reality is that it is still possible, so today the task of making it difficult to use your DNS servers in conducting such attacks seems very relevant. I also note that in this attack it is possible to use both authoritative DNS servers and public resolvers; The proposed solution can also be used in both cases.
The main methods of struggle applicable on dns servers:
Block unwanted.
In principle, there is nothing tricky here; many firewalls have the ability to block traffic when the number of packets passing per second is exceeded. You can block by any rules, such as was done in the above article. If you don’t want to use a firewall on dns servers, you can run tcpdump once, for some time, parse its output and route unwanted traffic to / dev / null by routing. In extreme cases, you can add the attacker's ip to the loopback interface (this technique was recommended by I. Sysoev at one of the conferences, as a way to do without the firewall on FreeBSD). You can configure traffic mirroring on the switch, analyze it somewhere separately and then send the result to the border router for blocking. There are many options, minus one - we are losing some of the traffic. Do not forget that we block the substituted ip, and there may well be anything from dns to the servers of the provider and ending with the servers of your own organization.Ask for TCP.
The header of the DNS packet has a TC flag field. If the TC flag is set, the client must repeat the request using TCP, all other response data being ignored. The idea of this method is that the attacker will not switch to TCP, for it it does not make sense, while an honest client switches and receives a response via TCP. Of course, TCP for DNS is slower, but, first, the answer should settle down in the recursor or client cache, and second, some latency in this case is a lesser evil. This approach has already been implemented in some dns servers: for example, in powerdns, you can set the tc flag to respond to ANY requests, which is already a good compromise. But this option is also not perfect. The fact is that in the large Internet there are still servers, not exactly following RFCs or simply mis-configured, and simply setting the TC for all the answers, no one guarantees that everyone will correctly ask for the TCP answer. Also, do not forget that, by setting the tc flag, we, of course, reduce the amount of outgoing traffic and consequently the load on network equipment, but the servers themselves will still process this gigantic incoming request flow, spending precious context switches and warming data centers .
Actually, the idea to make something new. However, in dos protection, as a rule, there are no ideal means, and the proposed option is also not without flaws: for example, it does not protect at all from using a server to reflect dns traffic without gain. Nevertheless, the advantages of the proposed solution are as follows:
- We do not block anyone, if the threshold is exceeded, we simply force the use of tcp for certain ip addresses, that is, set the tc flag and respond with a cut dns answer.
- We force the use of TCP in the kernel.
Also, I wanted to make the decision as simple as possible in terms of using, without having to necessarily use iptables, configure any additional rules, etc. The module is Linux-specific, but I think nothing fundamentally prevents us from implementing the idea on FreeBSD.
')
How it works?
We count the number of incoming packets from each ip address in a given period of time. If the number of incoming packets from a certain ip has exceeded the threshold, then we form a UDP response with the TC flag and discard the request. Thus, we dramatically reduce the number of context switches caused by the need of the DNS server application processing this traffic. A legitimate client, having received a uc response with the tc flag, will be forced to repeat the request via TCP, and this traffic will already reach the dns server.
For an effective implementation, we will be greatly helped by the fact that the header format for the dns request and response is the same; moreover, the header is the only necessary part of the packet for the dns response to be considered correct. Let's look at the dns header in more detail:

Another good news: the dns header has a fixed size of 12 bytes. It turns out a very simple scheme, we do not even need to completely parse the dns header. We check that the packet that came to UDP port 53 contains data larger than 12 bytes, copy the first 12 bytes of data (as I wrote, the thought appeared that maybe we should additionally check other header fields) from the request to the new packet, set the TC bits to it and the response bit, and send it back. Since we copied only the header, it is also advisable to reset the QDCOUNT field, otherwise we will receive warnings from the parser on the client side. The request itself is then deleted. All this work can be done right in the NF_INET_LOCAL_IN hook, in the same hook we have to put the source ip in the KFIFO queue for further statistics calculation. Statistics of incoming packets will be considered asynchronously, in a separate stream, using red-black trees. Thus, we introduce a minimal delay in the packet passing - KFIFO is a lock free data structure, besides, a queue is created for each cpu. True, there is a need to configure the interval depending on the expected pps. There is also a limit on the amount of memory allocated for per cpu data: now it is 32kB, taking into account what is created a queue of 4096 ip addresses per cpu. Thus, choosing an interval of 100ms, we will be able to cheat up to 40,960 pps for each cpu, which in most cases seems to be sufficient. On the other hand, overflowing the queue will simply result in the loss of part of the data for calculating statistics.
A logical question arises: why not just use a hash?
Unfortunately, the careless use of hashes in such places opens up the possibility for another type of attack — attacks aimed at causing collisions: knowing that a hash is used in a part of the code that is critical at the time of execution, you can gather data that the operation with them the table will occur already beyond O (n) instead of O (1). Such attacks are also unpleasant because it can be difficult to identify them - apparently nothing has happened, and the server has become ill.
If pps from the blocked ip has become less than the threshold value, then the blocking is removed. It is possible to configure a hysteresis equal to 10% of the threshold by default.
At the end of the article there is a link to the project; Any constructive comments, suggestions and additions are welcome.
Usage example
In the directory with the assembled module execute
insmod ./kfdns.ko threshold=100 period=100 hysteresis=10threshold - the threshold, above which we will set the tc flag;
period - counting period, ms (i.e. in this case, the filter will work if you received more than 100 packets from one ip per 100ms);
hysteresis - the difference between the threshold and the release threshold of the filter. Hint: if you set hysteresis = threshold, then after the lock is triggered, it will never be removed, in some cases it may be useful.
After loading the module into
cat /proc/net/kfdnsYou can find statistics on ip that fell under filtering.
Test results
To create a parasitic load, dnsperf was used (in duplicate, one on the next virtual machine, the second on the laptop, and unfortunately it was not enough to load the system to failure), the dns server was raised in the KVM virtual machine running CentOS, as the dns server itself was used by pdns-recursor.
The graphs show the values of the counters before the activation of the module, after activation, and again with the unloaded module. PPS during the whole experiment was at the level of 80kpps.

So, what we were trying to achieve was a reduction in outgoing traffic. It can be seen that after turning on the module, outgoing traffic has become even less incoming,
which is basically logical: let's not forget that we only copy the title.
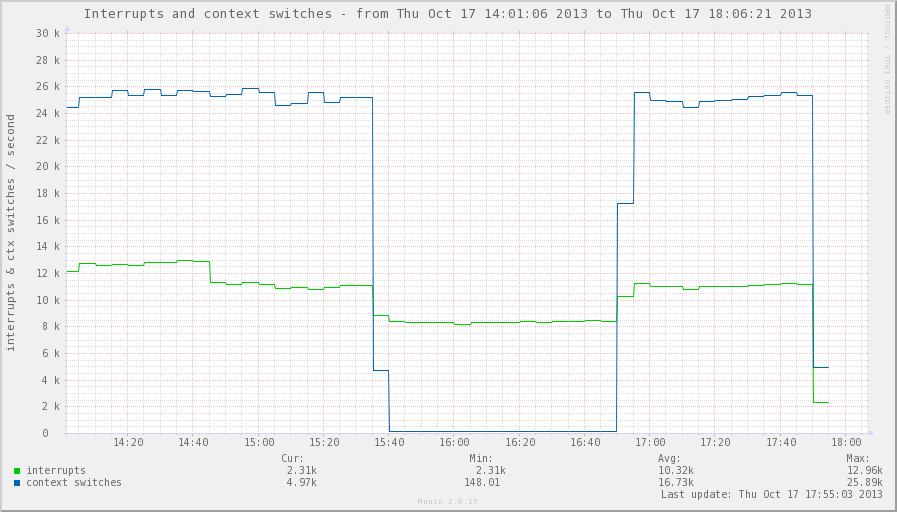
A sharp decrease in the number of context switches is good.
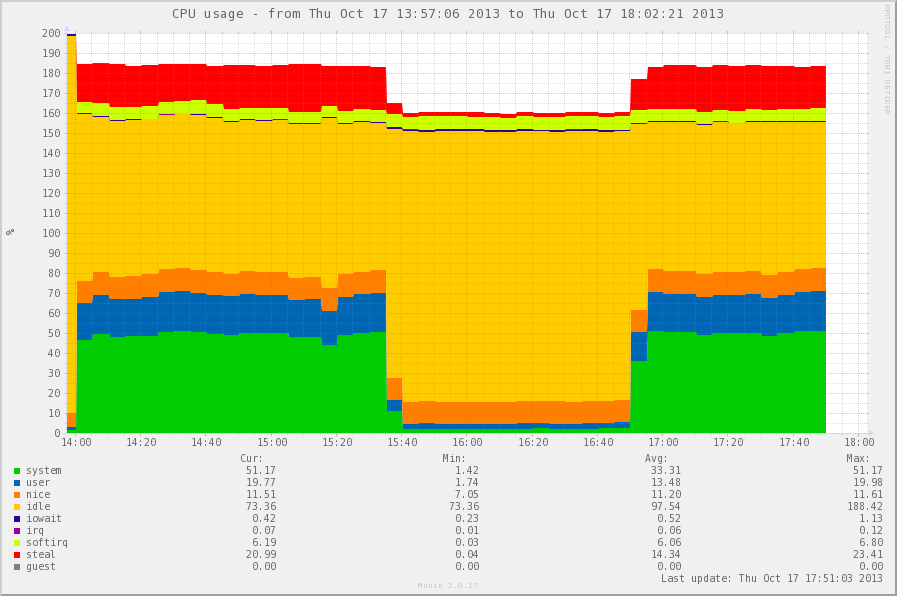
And this is what happened with the system: you can see a noticeable reduction in consumption of system time, user time. Changes in steal time in this case is the effect of virtualization, which is also logical. But a barely noticeable increase in irq time is interesting and may be a reason for further experiments.
What do you want to add in the future?
- Work from the PREROUTING hook (or from FORWARDING, but need to be checked). This will allow to use the module not only on dns servers, but also, for example, on balancers, or border firewalls.
- Preparation of packages for the main distributions.
- Documentation, best practice
The project itself:
github.com/dcherednik/kfdns4linux
While the project is in a rather young state, but I hope that there will be interested people in the Habrasoobshchestvo, and, perhaps, it will be useful for someone.
References and literature:
Linux netfilter Hacking HOWTO
Writing Netfilter Modules
Unreliable Guide To Locking
ISBN 978-5-8459-1779-9 Robert Love, The Linux Kernel: A Description of the Development Process
Source: https://habr.com/ru/post/198264/
All Articles