Under the hood at Dictionary and ConcurrentDictionary
Some time ago, I decided that I wanted to know more details about multithreading in .NET and that I had paid undue attention to this in the past. There is a great deal of information on this topic (I chose this section of the book “C # in a nutshell” as the starting point), but as it turned out, only a small part of the resources try to explain something in detail.
Each master should know his tools, and what can be used more often collections? Therefore, I decided to make a small review of multi-threaded collections and start with ConcurrentDictionary (a quick overview has already been met here , but there is very little of it). Actually, I was somewhat surprised that there is still no such article for .NET (but enough for Java ).
So let's go.
If you are already familiar with the Dictionary itself, you can skip the next section.
')
Dictionary is an implementation of the standard Hashtable .
Here the following functions are interesting:
Initialization occurs either during creation (if the initial size of the collection is transferred), or when the first element is added, and the nearest prime number (3) is selected as the size. This creates 2 internal collections - int [] buckets and Entry [] entries . The first will contain the indexes of the elements in the second collection, and she, in turn, the elements themselves in this form:
When an item is added, the hashcode of its key is calculated and then the basket index to which it will be added modulo the size of the collection:
It will look something like this:
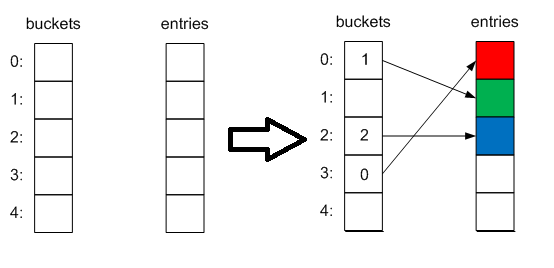
Then it is checked whether there is already such a key in the collection, if it does, then the Add operation will throw an exception, and assignment by index will simply replace the element with a new one. If the maximum dictionary size is reached, an expansion occurs (a new size is selected by the nearest prime number).
The complexity of the operation, respectively - O (n).
If a collision occurs (that is, there is already an item in the bucketNum index from the index), then the new item is added to the collection, its index is stored in the basket, and the index of the old item is in its next field.
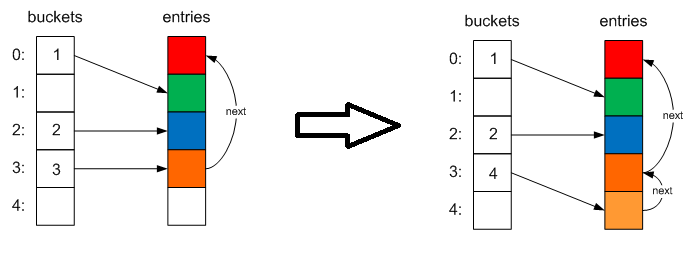
Thus we get a unidirectional linked list . This collision resolution mechanism is called chaining . If, when adding an element, the number of collisions is large (more than 100 in the current version), then when the collection is expanded , an overhanging operation occurs , before the execution of which a new hashcode is randomly selected.
The difficulty of adding O (1) or O (n) in the event of a collision.
When deleting elements, we overwrite its contents with default values, change the next pointers of other elements when necessary, and store the index of this element in the freeList internal field, and the old value in the next field. Thus, when adding a new element, we can reuse such free cells:

The difficulty is again O (1) or O (n) in the event of a collision.
It is also worth noting 2 points:
1) When cleaning the dictionary, its internal size does not change. That is, potentially, you just waste a place.
2) GetEnumerator simply returns an iterator over the entires collection (O (1) complexity). If you just added items, they will return in the same order. However, if you deleted elements and added new ones, the order will change accordingly, so you should not rely on it (especially since in future versions of the framework this may change).
It would seem that there are 2 solutions in the forehead to ensure thread-safety - to wrap all calls to the dictionary in locks or to wrap all its methods in them. However, for obvious reasons, this solution will be slow - the delays added by lock, and the restriction on 1 stream that could work with the collection does not add speed.
Microsoft went a more optimal way and Dictionary got used to some changes. So, thanks to the internal structure of the dictionary and its baskets, blocking is carried out by them, using the method
At the same time, a regular dictionary could not work with this scheme, because all baskets use the same array of entries, so baskets began to be a regular single linked list: volatile Entry [] m_buckets (the field is declared as volitale to provide non-blocking synchronization in a situation when one thread tries to perform some operation, and the other at this moment changes the size of the collection).
As a result, the baskets began to look like this:
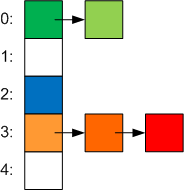
lockNo is an index in a new array that contains synchronization objects — object [] m_locks . Its use allows different threads to change different baskets at the same time. The size of this collection depends on the parameter ConcurrencyLevel which can be specified through the constructor. It defines the approximate number of threads that will simultaneously work with the collection (by default, this is the number of processors * 4). The higher this value, the easier it will be to write operations, but operations that require complete blocking of the entire collection ( Resize, ToArray, Count, IsEmpty, Keys, Values, CopyTo, Clear ) will also become much more expensive. Also, this parameter determines how many elements of the collection fall on one lock (as the ratio of the number of baskets to the size of this collection) and when there are more elements than necessary - the collection expands, because otherwise the search for an element requires not O (1), but already O (n) by traversing linked lists. To slightly reduce the number of initial extensions of the collection, the initial size of the dictionary is no longer 3, but 31.
All operations acquired the form:
When you add a new item, you have to bypass the entire linked list just to determine if there is such a key already and if not, add it. Similarly, when deleting - first you need to find the node that is to be deleted.
However, for some operations, locking is not necessary in principle - these are TryGetValue, GetEnumerator, ContainsKey and indexing . Why? Because all changes in the size of the baskets are visible due to the fact that the field is volatile, any additions or changes to the elements occur by creating a new element and replacing it with the old one, and deleting is done simply by replacing the pointer to the next node.
1) Unlike the usual Dictionary, a call to the Clear method resets the size of the collection to its default value.
2) GetEnumerator - can return old values in case changes were made by another thread after calling the method and how the iterator passed this element. In the article mentioned at the beginning it was noted that
Thanks for attention.
The article used:
1. The .NET Dictionary
2. Inside the Concurrent Collections: ConcurrentDictionary
3. Concurrent Collections
4. .NET Reflector
Each master should know his tools, and what can be used more often collections? Therefore, I decided to make a small review of multi-threaded collections and start with ConcurrentDictionary (a quick overview has already been met here , but there is very little of it). Actually, I was somewhat surprised that there is still no such article for .NET (but enough for Java ).
So let's go.
If you are already familiar with the Dictionary itself, you can skip the next section.
')
What is a Dictionary <TKey, TValue>?
Dictionary is an implementation of the standard Hashtable .
Here the following functions are interesting:
Initialization
Initialization occurs either during creation (if the initial size of the collection is transferred), or when the first element is added, and the nearest prime number (3) is selected as the size. This creates 2 internal collections - int [] buckets and Entry [] entries . The first will contain the indexes of the elements in the second collection, and she, in turn, the elements themselves in this form:
private struct Entry { public int hashCode; public int next; public TKey key; public TValue value; } Adding items
When an item is added, the hashcode of its key is calculated and then the basket index to which it will be added modulo the size of the collection:
int bucketNum = (hashcode & 0x7fffffff) % capacity; It will look something like this:
Then it is checked whether there is already such a key in the collection, if it does, then the Add operation will throw an exception, and assignment by index will simply replace the element with a new one. If the maximum dictionary size is reached, an expansion occurs (a new size is selected by the nearest prime number).
The complexity of the operation, respectively - O (n).
If a collision occurs (that is, there is already an item in the bucketNum index from the index), then the new item is added to the collection, its index is stored in the basket, and the index of the old item is in its next field.
Thus we get a unidirectional linked list . This collision resolution mechanism is called chaining . If, when adding an element, the number of collisions is large (more than 100 in the current version), then when the collection is expanded , an overhanging operation occurs , before the execution of which a new hashcode is randomly selected.
The difficulty of adding O (1) or O (n) in the event of a collision.
Deleting items
When deleting elements, we overwrite its contents with default values, change the next pointers of other elements when necessary, and store the index of this element in the freeList internal field, and the old value in the next field. Thus, when adding a new element, we can reuse such free cells:
The difficulty is again O (1) or O (n) in the event of a collision.
Other
It is also worth noting 2 points:
1) When cleaning the dictionary, its internal size does not change. That is, potentially, you just waste a place.
2) GetEnumerator simply returns an iterator over the entires collection (O (1) complexity). If you just added items, they will return in the same order. However, if you deleted elements and added new ones, the order will change accordingly, so you should not rely on it (especially since in future versions of the framework this may change).
So what about ConcurrentDictionary?
It would seem that there are 2 solutions in the forehead to ensure thread-safety - to wrap all calls to the dictionary in locks or to wrap all its methods in them. However, for obvious reasons, this solution will be slow - the delays added by lock, and the restriction on 1 stream that could work with the collection does not add speed.
Microsoft went a more optimal way and Dictionary got used to some changes. So, thanks to the internal structure of the dictionary and its baskets, blocking is carried out by them, using the method
private void GetBucketAndLockNo(int hashcode, out int bucketNo, out int lockNo, int bucketCount, int lockCount) { bucketNo = (hashcode & 0x7fffffff) % bucketCount; lockNo = bucketNo % lockCount; } At the same time, a regular dictionary could not work with this scheme, because all baskets use the same array of entries, so baskets began to be a regular single linked list: volatile Entry [] m_buckets (the field is declared as volitale to provide non-blocking synchronization in a situation when one thread tries to perform some operation, and the other at this moment changes the size of the collection).
As a result, the baskets began to look like this:
lockNo is an index in a new array that contains synchronization objects — object [] m_locks . Its use allows different threads to change different baskets at the same time. The size of this collection depends on the parameter ConcurrencyLevel which can be specified through the constructor. It defines the approximate number of threads that will simultaneously work with the collection (by default, this is the number of processors * 4). The higher this value, the easier it will be to write operations, but operations that require complete blocking of the entire collection ( Resize, ToArray, Count, IsEmpty, Keys, Values, CopyTo, Clear ) will also become much more expensive. Also, this parameter determines how many elements of the collection fall on one lock (as the ratio of the number of baskets to the size of this collection) and when there are more elements than necessary - the collection expands, because otherwise the search for an element requires not O (1), but already O (n) by traversing linked lists. To slightly reduce the number of initial extensions of the collection, the initial size of the dictionary is no longer 3, but 31.
All operations acquired the form:
void ChangeBacket(TKey key) { while (true) { Node[] buckets = m_buckets; int bucketNo, lockNo; GetBucketAndLockNo(m_comparer.GetHashCode(key), out bucketNo, out lockNo, buckets.Length); lock (m_locks[lockNo]) { if (buckets != m_buckets) { // Race condition. , . continue; } Node node = m_buckets[bucketNo]; // . } } } When you add a new item, you have to bypass the entire linked list just to determine if there is such a key already and if not, add it. Similarly, when deleting - first you need to find the node that is to be deleted.
However, for some operations, locking is not necessary in principle - these are TryGetValue, GetEnumerator, ContainsKey and indexing . Why? Because all changes in the size of the baskets are visible due to the fact that the field is volatile, any additions or changes to the elements occur by creating a new element and replacing it with the old one, and deleting is done simply by replacing the pointer to the next node.
Other
1) Unlike the usual Dictionary, a call to the Clear method resets the size of the collection to its default value.
2) GetEnumerator - can return old values in case changes were made by another thread after calling the method and how the iterator passed this element. In the article mentioned at the beginning it was noted that
it is better to use dictionary.Select (x => x.Value) .ToArray () than dictionary.Values.ToArray ()And this is not quite true - instead of “better,” there should be “faster” - due to the absence of locks, but we must take into account that these approaches can return different data.
Thanks for attention.
The article used:
1. The .NET Dictionary
2. Inside the Concurrent Collections: ConcurrentDictionary
3. Concurrent Collections
4. .NET Reflector
Source: https://habr.com/ru/post/198104/
All Articles