ABCat: OpenSource catalog and audiobook downloader
I discovered audiobooks five years ago and since then I have been listening to them almost daily. Of course, nothing compares to a printed book, but there is simply no time left for them in the daily whirlwind. Under the audiobooks, I travel in public transport, perform routine work at home, do repairs - in general, almost everything that does not require communication with anyone or concentration of attention.

The main source of books for me was rutracker.org (then still torrents.ru). There is a fairly strict moderation, standardized design, a large number of reviews under each book. But once I noticed that the search for interesting books starts to take more and more time, for several reasons.
First, distributions are sorted not in the order of addition, but in the order of update. Because of this, everything is constantly mixed up and you need to scroll through many pages in search of unread books.
At first, it allowed the browser to separate what was read from the unread, changing the color of the links I had already followed. But after changing the domain to rutracker, the color differentiation of thetrousers of the hands fell off, which did not exactly simplify the search process.
Splitting books into forums is also quite inconvenient. Science fiction, for example, was divided into Russian and foreign, although it would be more convenient for me personally by genres. As a result, you have to look for your favorite NF among fantasy, STALKER and others.
')
Familiar problem?
Once I thought that writing a utility for cataloging audio books would take less time than is lost with a constant manual search. The application was written and I used it for the last 4 years, gradually modifying.
After a rather unexpected support of my commentary on the article Save the largest library in runet. The whole base rutracker on your computer, it became clear that fans of audio books are not so little. I decided to put some unsystematically written code into some sort of order, to think over the architecture and extensibility, throw away all the proprietary, and then post the release with the source code.
 I decided to call this boat ABCat. Here and AudioBooks Catalog, and ABC simplicity, and, of course, all your favorite cats.
I decided to call this boat ABCat. Here and AudioBooks Catalog, and ABC simplicity, and, of course, all your favorite cats.
On the advice of Nashev, the article is not so much about development, as a review of the functional.
The application is written in .Net Framework, C #. Initially, the interface was built on the trial version of DevExpress. She asked to eat, but not very persistently - during the trial month I managed to fix the GUI, and more was not required. DevExpress bribed a powerful list filtering system, which radically simplified the search.
It is clear that for the output into the open-source light, the entire GUI had to be completely thrown away and write a new one, with WPF and MVVM, at the same time getting to know both that and the other.
What can be said about what happened? Well, except that "Graphical user interface, 1 pc.". This thing is purely utilitarian, written using open free components, but it performs its tasks.
At the time of the screenshots I did not notice that I forgot to sign the Title by the window. On screenshots it is not, in the release there.
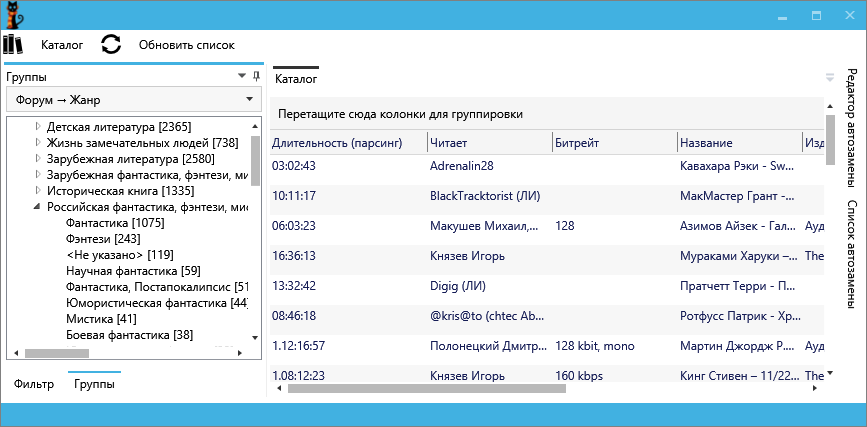
In short, the parser retrieves the pages with information about the books from the site. From the contents of the pages are calculated the name of the author, genre, duration, reader, description, publisher, bit rate. All this stuff is added to the local database. With the help of groupings, filtering and sorting the user finds the desired book and downloads.
Almost all the logic in ABCat is implemented via plugins. They are divided into three main groups:
In plug-ins, you can implement support for other sites, other logic of the normalizer, grouping, filtering, etc. Read more about plugins on the main page of the project .
Release Page on Codeplex.
Direct link to the release and database of the catalog from 10.20.201
Database of cached pages on Google Drive (caution, 200MB)
Link to the source .
Attention! ABCat is written in .Net Framework 4.5, which is not supported by operating systems below Windows Vista (i.e., XP will not work). In Google, there are links to mysterious .Net Framework 4.5 repackers under XP, but have not tried it - I don’t know.
In addition, it should be understood that the program was written just now, in my free time, and no one except me used it. The project is not commercial. Mail.ru companions, Yandex does not offer to install toolbars, don’t show advertising, donates don’t ask. Therefore, please treat with understanding the possible (and, I must say, highly probable) errors in its work. Please report any errors in any convenient way (best of all here ).
New information. Found the cause of problems on Win7, it is in the theme of the list of entries. As a result, the list is not drawn. The error is corrected, and you need to repeat all the steps from the beginning (links in the topic are new). The page cache file also needs to be downloaded again due to switching to the current version of the Entity Framework.
In addition, if the message “Could not find the requested data provider ...” appears after downloading the program, then you need to download and install the Microsoft SQL Ce client from this link . Select the x64 or x86 version depending on the version of the operating system.
Thank you all for feedback!
Before downloading the book, make sure that the release author has taken care of respecting the copyright to it.
And do not go with the distribution.
The main source of books for me was rutracker.org (then still torrents.ru). There is a fairly strict moderation, standardized design, a large number of reviews under each book. But once I noticed that the search for interesting books starts to take more and more time, for several reasons.
First, distributions are sorted not in the order of addition, but in the order of update. Because of this, everything is constantly mixed up and you need to scroll through many pages in search of unread books.
At first, it allowed the browser to separate what was read from the unread, changing the color of the links I had already followed. But after changing the domain to rutracker, the color differentiation of the
Splitting books into forums is also quite inconvenient. Science fiction, for example, was divided into Russian and foreign, although it would be more convenient for me personally by genres. As a result, you have to look for your favorite NF among fantasy, STALKER and others.
')
Familiar problem?
Lyrical digression
Once I thought that writing a utility for cataloging audio books would take less time than is lost with a constant manual search. The application was written and I used it for the last 4 years, gradually modifying.
After a rather unexpected support of my commentary on the article Save the largest library in runet. The whole base rutracker on your computer, it became clear that fans of audio books are not so little. I decided to put some unsystematically written code into some sort of order, to think over the architecture and extensibility, throw away all the proprietary, and then post the release with the source code.
I decided to call this boat ABCat. Here and AudioBooks Catalog, and ABC simplicity, and, of course, all your favorite cats.On the advice of Nashev, the article is not so much about development, as a review of the functional.
The application is written in .Net Framework, C #. Initially, the interface was built on the trial version of DevExpress. She asked to eat, but not very persistently - during the trial month I managed to fix the GUI, and more was not required. DevExpress bribed a powerful list filtering system, which radically simplified the search.
It is clear that for the output into the open-source light, the entire GUI had to be completely thrown away and write a new one, with WPF and MVVM, at the same time getting to know both that and the other.
What can be said about what happened? Well, except that "Graphical user interface, 1 pc.". This thing is purely utilitarian, written using open free components, but it performs its tasks.
At the time of the screenshots I did not notice that I forgot to sign the Title by the window. On screenshots it is not, in the release there.
In short, the parser retrieves the pages with information about the books from the site. From the contents of the pages are calculated the name of the author, genre, duration, reader, description, publisher, bit rate. All this stuff is added to the local database. With the help of groupings, filtering and sorting the user finds the desired book and downloads.
More details about working with the program
Normal grid with attribute columns.
Three grouping logics are now available:
After selecting a group, the list is automatically filtered by its contents.
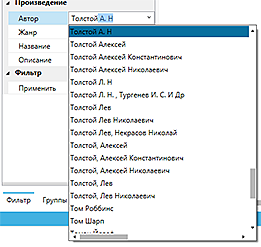 In the filter, you can specify the necessary search parameters. Some fields have the form of a drop-down list - it already contains all possible values and this is a quick search box. All filter fields are combined by "AND", i.e. After filtering, only what matches all the search fields at once is included in the list. Search for any occurrence of the string.
In the filter, you can specify the necessary search parameters. Some fields have the form of a drop-down list - it already contains all possible values and this is a quick search box. All filter fields are combined by "AND", i.e. After filtering, only what matches all the search fields at once is included in the list. Search for any occurrence of the string.
The field "Duration" is quite tricky. If you enter there "> 10 hours", then only those books will appear in the list in which the author of the distribution indicated the playback duration more than 10 hours.
There are some reservations. Firstly, the duration is not set for all distributions, secondly it is indicated in a completely free form (for example, “11 hours 5 minutes” or “11:05:00” or something else), therefore there is a logic of time parsing, which understands most (about 99%) of the spellings taken on the site. Maybe not everyone understands everything correctly (until he found one), but overall, a very convenient tool is obtained.
And just thanks to this parser, you can clog the filter in any convenient way.
Checkboxes:
18 relatively correct ways to indicate that the book was written by the Strugatsky brothers

When importing data is normalized. For this, the field values are checked against the autochange lists and replaced with the correct one.
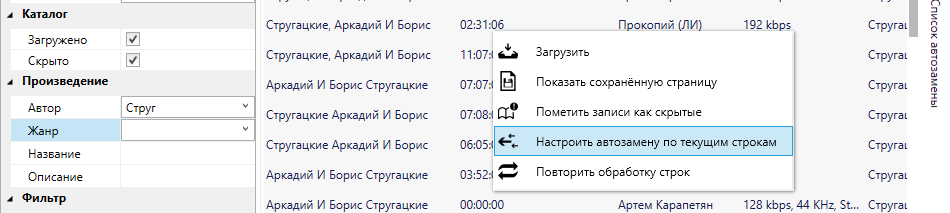
To add to the list of autochange, you need to select those entries that contain different spellings of the same parameter. Then, through the context menu of the list, we send the entries to the AutoCorrect editor.

Select the desired attribute (in this case, "Author"), double-click on the version that you like the most (if there is no such thing, simply enter it manually), and click "Save Changes."

Tree AutoCorrect.
The lists themselves are stored in a separate database file and you can take someone’s ready-made version or customize your own. There is as yet an unrealized idea of importing a list with a union, rather than replacing all the lists entirely.
The database is updated in two stages:
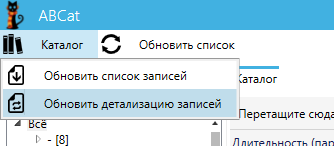
The update process is launched by two items in the main menu of the application (under the “Catalog” item).
It is highly recommended to download an already up-to-date version of the catalog (following the links below), and then periodically launch the update.
Download speed of full pages is specially limited (no more than 20 pages per minute). Just to ensure that the guys from the rutracker are not too offended. The protection is very simple and, in the presence of source codes, can be easily removed, but for someone who can find and disable it, for a DDoS rutracker you don’t need such a perverted method — five lines of code are enough.
There are more or less well-established design standards on the rutreker, so it becomes possible to get the necessary information from the majority of distributions. Of course, one cannot do without alternatively gifted personalities.

But the parser is up to work with such instances. Worse, when the distribution contains incomplete information, or it does not meet the standards at all - some records cannot be disassembled. To understand what kind of book it is enough to double-click on the desired line, which opens the distribution page in the browser.
The download of the selected book is launched from the context menu of the list.
For downloading you will need the username and password of the user rutraker Logins and passwords are not stored anywhere and are not sent anywhere (except, of course, the rutracker itself). ABCat starts uTorrent with command line parameters and the download starts automatically. The downloaded distribution falls into the library folder, the path to the library is set when you first start the program. In the library of the book are arranged in folders in accordance with the author.
You can run several books at once on the download at once, but here too there are limitations - torrent-files are downloaded no more than 6 times per minute.
Available tools
Book list
Normal grid with attribute columns.
Grouping
Three grouping logics are now available:
- By author (authors are grouped by the first letter of the full name)
- Forum ► Author
- Forum ► Genre
After selecting a group, the list is automatically filtered by its contents.
Filter
In the filter, you can specify the necessary search parameters. Some fields have the form of a drop-down list - it already contains all possible values and this is a quick search box. All filter fields are combined by "AND", i.e. After filtering, only what matches all the search fields at once is included in the list. Search for any occurrence of the string.The field "Duration" is quite tricky. If you enter there "> 10 hours", then only those books will appear in the list in which the author of the distribution indicated the playback duration more than 10 hours.
There are some reservations. Firstly, the duration is not set for all distributions, secondly it is indicated in a completely free form (for example, “11 hours 5 minutes” or “11:05:00” or something else), therefore there is a logic of time parsing, which understands most (about 99%) of the spellings taken on the site. Maybe not everyone understands everything correctly (until he found one), but overall, a very convenient tool is obtained.
And just thanks to this parser, you can clog the filter in any convenient way.
Checkboxes:
- Loaded. If it is unchecked, then already downloaded books will not appear in the list.
- Is hidden. Filters entries by the “hidden” feature (the feature itself is set in the list via the context menu).
- Apply. You can enable / disable filtering of records without losing the contents of the filter.
AutoCorrect Editor
18 relatively correct ways to indicate that the book was written by the Strugatsky brothers
When importing data is normalized. For this, the field values are checked against the autochange lists and replaced with the correct one.
To add to the list of autochange, you need to select those entries that contain different spellings of the same parameter. Then, through the context menu of the list, we send the entries to the AutoCorrect editor.
Select the desired attribute (in this case, "Author"), double-click on the version that you like the most (if there is no such thing, simply enter it manually), and click "Save Changes."
Tree AutoCorrect.
The lists themselves are stored in a separate database file and you can take someone’s ready-made version or customize your own. There is as yet an unrealized idea of importing a list with a union, rather than replacing all the lists entirely.
The database is updated in two stages:
- Download a list of records. To do this, download all the pages with the lists of distributions, pulled out of the basic information about the book - a link to the full page of the distribution and the title. For rutracker forums, the first operation takes about 20 minutes - you need to download and process about 400 pages.
- Download complete information about the records. The links received in the first stage download pages with complete information. They are much more - about 18 thousand.
The update process is launched by two items in the main menu of the application (under the “Catalog” item).
It is highly recommended to download an already up-to-date version of the catalog (following the links below), and then periodically launch the update.
Download speed of full pages is specially limited (no more than 20 pages per minute). Just to ensure that the guys from the rutracker are not too offended. The protection is very simple and, in the presence of source codes, can be easily removed, but for someone who can find and disable it, for a DDoS rutracker you don’t need such a perverted method — five lines of code are enough.
There are more or less well-established design standards on the rutreker, so it becomes possible to get the necessary information from the majority of distributions. Of course, one cannot do without alternatively gifted personalities.
But the parser is up to work with such instances. Worse, when the distribution contains incomplete information, or it does not meet the standards at all - some records cannot be disassembled. To understand what kind of book it is enough to double-click on the desired line, which opens the distribution page in the browser.
Download
The download of the selected book is launched from the context menu of the list.
For downloading you will need the username and password of the user rutraker Logins and passwords are not stored anywhere and are not sent anywhere (except, of course, the rutracker itself). ABCat starts uTorrent with command line parameters and the download starts automatically. The downloaded distribution falls into the library folder, the path to the library is set when you first start the program. In the library of the book are arranged in folders in accordance with the author.
You can run several books at once on the download at once, but here too there are limitations - torrent-files are downloaded no more than 6 times per minute.
Few technical details
Almost all the logic in ABCat is implemented via plugins. They are divided into three main groups:
- UI - User Interface Plugins
- Site - Plugins for operations with content sources and database content
- Catalog - Plugins for Operations with Content Catalog
In plug-ins, you can implement support for other sites, other logic of the normalizer, grouping, filtering, etc. Read more about plugins on the main page of the project .
Release Page on Codeplex.
Direct link to the release and database of the catalog from 10.20.201
Database of cached pages on Google Drive (caution, 200MB)
Link to the source .
Beginning of work:
- Download release , database directory and page cache .
- Unzip the release to any folder on the disk.
- Download and unpack the catalog database and page cache where it will be convenient to store 250+ megabytes of databases. The user must have write access to this path.
- Run ABCat.exe. When you first start the program will offer to set the basic settings. Be sure to specify the paths to the database files, directory and uTorrent.exe. If after the launch you observe the message “Could not find the requested data provider ..”, then you need to install the SQL client Ce from this link .
- Enjoy.
Attention! ABCat is written in .Net Framework 4.5, which is not supported by operating systems below Windows Vista (i.e., XP will not work). In Google, there are links to mysterious .Net Framework 4.5 repackers under XP, but have not tried it - I don’t know.
In addition, it should be understood that the program was written just now, in my free time, and no one except me used it. The project is not commercial. Mail.ru companions, Yandex does not offer to install toolbars, don’t show advertising, donates don’t ask. Therefore, please treat with understanding the possible (and, I must say, highly probable) errors in its work. Please report any errors in any convenient way (best of all here ).
New information. Found the cause of problems on Win7, it is in the theme of the list of entries. As a result, the list is not drawn. The error is corrected, and you need to repeat all the steps from the beginning (links in the topic are new). The page cache file also needs to be downloaded again due to switching to the current version of the Entity Framework.
In addition, if the message “Could not find the requested data provider ...” appears after downloading the program, then you need to download and install the Microsoft SQL Ce client from this link . Select the x64 or x86 version depending on the version of the operating system.
Thank you all for feedback!
Before downloading the book, make sure that the release author has taken care of respecting the copyright to it.
And do not go with the distribution.
Source: https://habr.com/ru/post/197528/
All Articles