Lock-free data structures. Basics: Memory Model

In the previous article, we looked inside the processor, albeit hypothetical. We found out that in order to correctly execute parallel code, the processor needs to be prompted to what extent it is allowed to conduct its own internal read / write optimizations. These tips are memory barriers. Memory barriers make it possible in one way or another to order memory accesses (more precisely, the cache — the processor interacts with the outside world only through the cache). The “severity” of this streamlining may be different - each architecture can provide a whole range of barriers “to choose from.” Using these or other memory barriers, we can build different memory models - a set of guarantees that will be executed for our programs.
In this article we will look at the C ++ 11 memory model.
Historical mini-review
At first, manufacturers did not publish an open specification of the processor’s memory model, that is, a set of rules by which a weakly-ordered processor works with memory, thereby hoping, I think, to gain room for maneuver in the future (really, why limit yourself in the development of architecture, taking Any obligations?) But then the manufacturers released the genie from the bottle, - the gigahertz rested against the ceiling, and the manufacturers began to introduce multi-core everywhere. As a result, the real multi-threading went to the masses. The first to beat the alarm was the developers of the operating systems: they need to support multi-core in the kernel, and there are no specifications for the weakly ordered architecture. Then the standardization bodies of languages were tightened: the programs are becoming more parallelized, it is time to standardize the memory model of the language, to give some guarantees for competitive multi-threaded execution, and there are no specifications for the memory model of the processors. As a result, today almost all modern processor architectures have open memory model specifications, and work on the Java, .NET, C ++ memory model standards has played a significant role in the emergence of such specifications.
C ++ has been famous since ancient times for its ability to express low-level things at a high level. When developing the C ++ 11 memory model, the task was not to violate this property, that is, to give programmers maximum flexibility. After analyzing the memory models of other languages that exist at that time (mainly Java) and typical examples of the internal structure of synchronization primitives and lock-free algorithms, the developers of the standard put forward not one, but three memory models:
- sequential consistency
- acquire / release semantics
- relaxed memory ordering (weak order)
All these memory models are defined in C ++ with one enumeration -
std::memory_order , which has the following 6 constants:memory_order_seq_cst- points to the sequential consistent modelmemory_order_acquire,memory_order_release,memory_order_acq_rel,memory_order_consume- refer to the model based on acquire / release semanticsmemory_order_relaxed- indicates a relaxed model
Before considering these models, you should decide how to specify the memory model in the program. Here we must return to atomic operations again.
The operations that I gave in the article about atomicity , by and large, have nothing in common with those defined in C ++ 11, since the standard
memory_order specified as an argument of an atomic operation. There are two reasons for this:- Semantic: in fact, the desired ordering (memory barrier) refers specifically to the atomic operation that we perform. The alignment of the barriers in the read / write approach is shamanism precisely because the barrier itself is in no way semantically linked to the code in which it is present — just an instruction among equivalent ones. In addition, the read / write placement of the barriers is very dependent on the architecture.
- Practical: Intel Itanium has a special, distinct from other architectures, way of specifying memory ordering for read / memory instructions and RMW operations. In Itanium, the ordering type is indicated as an optional flag of the instruction itself: acquire, release or relaxed. Moreover, there are no separate instructions (memory barriers) for specifying acquire / release semantics in the architecture; there is only an instruction for a heavy full memory barrier
Here’s what
atomic<T> operations actually look like: each specialization of the std::atomic<T> class should have at least the following methods void store(T, memory_order = memory_order_seq_cst); T load(memory_order = memory_order_seq_cst) const; T exchange(T, memory_order = memory_order_seq_cst); bool compare_exchange_weak(T&, T, memory_order = memory_order_seq_cst); bool compare_exchange_strong(T&, T, memory_order = memory_order_seq_cst); Separate memory barriers
Of course, C ++ 11 has separate free memory barrier functions:
void atomic_thread_fence(memory_order); void atomic_signal_fence(memory_order); atomic_thread_fence allows, in fact, to use the approach of separate read / write barriers, recognized as obsolete. Although the memory_order streamlining methods themselves memory_order not provide a way to specify a read barrier (Load / Load) or a write barrier (Store / Store).atomic_signal_fence intended for use in signal handlers. As a rule, this function does not generate any code, but is a barrier to the compiler.As you can see, the default memory model in C ++ 11 is sequential consistency. We will consider it first. But first, a few words about the compiler barriers.
Compiler barriers
Who can reorder the code we write? We figured out what the processor can do. But there is another source of reordering - the compiler.
Many methods of optimization (especially global) and heuristics have been developed (and are being developed to this day) under the assumption (perhaps implicitly) of single-threaded execution. The compiler is quite difficult (rather, even theoretically impossible) to understand that your code is multi-threaded. Therefore, the compiler needs hints - barriers. Such a barrier tells the compiler: do not dare to move the code in front of the barrier (mix) into the code behind the barrier, and vice versa. The compiler barrier itself does not generate any code.
For MS Visual C ++, the compiler barrier is a pseudo-function
_ReadWriteBarrier() (this name has always puzzled me: a complete association with the read / write memory barrier, the heaviest memory barrier). For GCC and Clang, this is an __asm__ __volatile__ ( "" ::: "memory" )
It should be noted that assembler inserts
__asm__ __volatile__ ( … ) are also in some way a barrier for GCC / Clang: the compiler does not have the right to throw out or move them up / down the code (this is indicated by the modifier __volatile__ ).The
memory_order affect the compiler supporting C ++ 11 as much as the processor — they are the barrier of the compiler, limiting the compiler's ability to reorder (i.e., optimize) our code. Therefore, specifying special barriers of the compiler is not required, unless, of course, the compiler fully supports the new standard.')

Sequential consistency
Suppose we implemented a lock-free stack (this is the simplest lock-free data structure), compiled it and tested it. And we get the crust (core file). What's the matter? We will look for an error, driving in our minds (no debugger will help us here) line by line the implementation of our lock-free stack, trying to emulate multithreading and answer the question which fatal combination of execution of string K of stream 1 and simultaneously string N of stream 2 led to crash. Perhaps, we will find and fix some errors, but all the same - our lock-free stack will fall. Why?
It turns out that what we are doing, trying to find an error and comparing program lines in mind for simultaneously running threads, is called a guarantee of sequential consistency . This is a strict memory model, which assumes that the processor does everything exactly in the order it is written in the program. For example, for such a code:
// Thread 1 atomic<int> a, b ; a.store( 5 ); int vb = b.load(); // Thread 2 atomic<int> x,y ; int vx = x.load() ; y.store( 42 ) ; Valid for sequential consistency are any execution script, except those that swap
a.store / b.load and x.load / y.store . Note that in this code I do not explicitly memory_order argument in the load / store — I rely on the default argument value.The same guarantee applies to the compiler: the compiler is forbidden to reorder our code in such a way that operations after
memory_order_seq_cst would be moved above this barrier, and vice versa, operations before the seq_cst barrier cannot be dropped below the barrier.The sequential consistency model is intuitively close to man, but has a very significant drawback: it is too strict for modern processors. It leads to the most severe memory barriers, not allowing the processor to fully implement speculative execution. Therefore, the new C ++ standard adopted the following compromise:
- The sequential consistency model should be taken as the default model for atomic operations for its severity and clarity.
- Introduce into C ++ other, weaker memory models that allow realizing the potential of modern architectures.
As an addition to the sequential consistency, a model was proposed based on the acquire / release semantics.
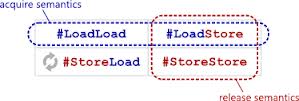
Acquire / release semantics
From the name of the acquire-release semantics, we can conclude that this semantics is somehow connected with the capture and release of resources. Indeed it is. Capture of a resource is its reading from memory to the register, release - writing from register to memory:
load memory, register ; membar #LoadLoad | #LoadStore ; // acquire- // acquire/release- ... membar #LoadStore | #StoreStore ; // release- store regiser, memory ; As you can see, in this code we
#StoreLoad using the #StoreLoad heavy barrier. It can also be noted that both the acquire-barrier and the release-barrier are semi- barriers: acquire does not order previous store-operations with subsequent load / store, and release does not order the previous load with subsequent, nor does the previous store with subsequent load . This applies to both the processor and the compiler.Acquire / release are barriers to all code that is between acquire / release. Some operations before the acquire-barrier can leak (can be reordered by the processor or compiler) into the acquire / release-section, as well as some operations after the release-barrier can be transferred up (again, by the processor or compiler), inside acquire / release -sections But operations concluded within the purchase-release will not go beyond its limits.
Probably the simplest example of using the acquire / release semantics is spin-lock.
Lock-free and spin-lock
It may seem strange that in the cycle article on lock-free algorithms, I give an example of a lock algorithm. It is required to explain.
I am not an ardent fan of pure lock-free, by no means. Yes, a clean lock-free (and even more so a wait-free) algorithm makes me happy, and twice as happy if it turns out to be implemented (this does not always happen). I am a supporter of a pragmatic approach: everything that is effective is good. Therefore, I do not disdain to apply locks where they can give benefits. Spin-lock can give a significant benefit in comparison with ordinary mutexes if it “protects” a very small piece of code - a few assembler instructions. In addition, spin-lock, despite its simplicity, is an inexhaustible source of all sorts of interesting optimizations.
I am not an ardent fan of pure lock-free, by no means. Yes, a clean lock-free (and even more so a wait-free) algorithm makes me happy, and twice as happy if it turns out to be implemented (this does not always happen). I am a supporter of a pragmatic approach: everything that is effective is good. Therefore, I do not disdain to apply locks where they can give benefits. Spin-lock can give a significant benefit in comparison with ordinary mutexes if it “protects” a very small piece of code - a few assembler instructions. In addition, spin-lock, despite its simplicity, is an inexhaustible source of all sorts of interesting optimizations.
Here's what the simplest spin-lock looks at acquire / release (C ++ experts will point out that you need to use a special type of
atomic_flag to implement spin-lock, but I will build a spin-lock on an atomic variable (not even a boolean) - so clearer from the point of view articles): class spin_lock { atomic<unsigned int> m_spin ; public: spin_lock(): m_spin(0) {} ~spin_lock() { assert( m_spin.load(memory_order_relaxed) == 0);} void lock() { unsigned int nCur; do { nCur = 0; } while ( !m_spin.compare_exchange_weak( nCur, 1, memory_order_acquire )); } void unlock() { m_spin.store( 0, memory_order_release ); } }; Note that in this code, the fact that
compare_exchange takes its first argument on the link and changes it, if CAS is unsuccessful, it really bothers me! You have to write a do-while loop with a non-empty body.In the
lock method of mastering blocking, I use acquire-semantics, and in the unlock method, release-semantics (by the way, the acquire / release semantics led its history just out of synchronization primitives: the standard developers carefully analyzed the implementation of various synchronization primitives and derived a acquire / release pattern. ) As I wrote above, the barriers in this case do not allow the code between lock() and unlock() to leak out - that’s what we need! And the atomicity of the m_spin variable guarantees us that as long as m_spin=1 , no one will be able to acquire a lock - again, that’s what is required!In the algorithm, we see that I use
compare_exchange_weak . What it is?
Weak and strong CAS
As you remember, the processor architecture can belong to one of two classes: either the processor implements an atomic primitive CAS (compare-and-swap), or a pair of LL / SC (load-linked / store-conditional). The LL / SC pair makes it possible to implement atomic CAS, but in itself is not atomic for many reasons. One of these reasons is that the code running inside the LL / SC can be interrupted by the operating system; for example, it is at this point that the OS decides to force out the current thread. Accordingly, the store conditional then, after renewal, will not work. That is, our CAS will return
false , although in reality the reason for this false may not be in the data, but in a third-party event - the interruption of the stream.It is this consideration that prompted the developers of the standard to introduce two
compare_exchange primitives - weak and weak. These primitives are called compare_exchange_weak and compare_exchange_strong . A weak version may fail, that is, return false , even if the current value of the variable is equal to the expected one. That is, a weak CAS can break the semantics of CAS and return false , when in fact it is necessary to return true (but not vice versa!) A strong CAS cannot do this: it strictly follows the semantics of CAS. Of course, it can cost something.When should a weak be applied, and when should a strong CAS be applied? I brought this rule for myself: if CAS is used in a cycle (and this is the basic pattern of using CAS) and there are no frills of operations in the cycle (that is, the body of the cycle is easy), then I use
compare_exchange_weak - weak CAS. Otherwise, a strong compare_exchange_strong .Memory order for acquire / release semantics
As I noted above, the following
memory_order values are defined for acquire / release semantics:memory_order_acquirememory_order_consumememory_order_releasememory_order_acq_rel
For reading (load), the values are
memory_order_acquire and memory_order_consume .For writing (store) - only
memory_order_release .Memory_order_acq_rel is valid only for RMW operations — compare_exchange , exchange , fetch_xxx . In general, an atomic RMW primitive can have acquire-semantics of memory_order_acquire , release-semantics of memory_order_release or both - memory_order_acq_rel . For RMW operations, these constants define precisely the semantics , since the read-modify-write primitive simultaneously performs atomic reading and writing. Semantically, an RMW operation can be considered either as acquire-read, or release-write, or both.The semantics of an RMW operation can be determined only in the algorithm where it is applied. Often, in lock-free algorithms, we can distinguish parts with something similar to spin-lock: in the beginning we receive (acquire) a certain resource, do something (usually we calculate a new value) and in the end we set (release) a new value of the resource. If the acquisition of a resource is performed by an RMW operation (usually a CAS), then such an operation is likely to acquire acquire semantics. If the new value is set by the RMW-primitive (CAS or
exchange ), then it probably has a release-semantics. “It is very likely” is inserted for a reason: a detailed analysis of the algorithm is required before one can understand which semantics is suitable for an RMW operation.If the RMW primitive is executed separately (it is impossible to distinguish the acquire / release pattern), then 3 options are possible for semantics:
memory_order_seq_cst- RMW operation is a key element of the algorithm, reordering of the code, transfer of reading and writing up and down can lead to an errormemory_order_acq_relis somewhat similar tomemory_order_seq_cst, but the RMW operation is inside the acquire / release sectionmemory_order_relaxed- transferring an RMW operation (its load and store parts) up and down the code (for example, within the purchase / release section, if the operation is inside such a section) does not lead to errors
All these tips should be considered only as an attempt to outline some general principles of hanging one or another semantics on the RMW-primitive. For each algorithm, a detailed analysis should be carried out.
Consume semantics
There is a separate, weaker, kind of acquire-semantics - consume-semantics of reading. This semantics was introduced as a “memory tribute” to the DEC Alpha processor.
Alpha architecture has a significant difference from other modern architectures: it could break the data dependency. In this code example:
struct foo { int x; int y; } ; atomic<foo *> pFoo ; foo * p = pFoo.load( memory_order_relaxed ); int x = p->x; She could re-order reading
p->x and actually getting p (do not ask me how this is possible - this is an Alpha property ; I did not have to work with Alpha, so I cannot confirm or deny it).To prevent such reordering, the consumption semantics was introduced. It is applicable for the atomic reading of a pointer to a structure, followed by reading the structure fields. In this example, the
pFoo pointer should read like this: foo * p = pFoo.load( memory_order_consume ); int x = p->x; Consume semantics is somewhere in the middle between relaxed- and acquire-semantics of reading. On many modern architectures, it maps to relaxed reading.
And once again about CAS
Above, I cited an
atomic<T> interface with two CAS weak and strong. In fact, there are two more variants of CAS - with the additional argument memory_order : bool compare_exchange_weak(T&, T, memory_order successOrder, memory_order failedOrder ); bool compare_exchange_strong(T&, T, memory_order successOrder, memory_order failedOrder ); What is this argument -
failedOrder ?Recall that CAS is a read-modify-write primitive. Even in case of failure, it performs atomic reading. The
failedOrder argument just defines the semantics of this reading in the event of a CAS failure. The values are the same as for normal reading.In practice, the indication “semantics in case of failure” is rather rarely required. Of course, it all depends on the algorithm!
Relaxed semantics
Finally, the third type of atomic operations model is relaxed semantics, which is applicable to all atomic primitives — load, store, all RMW — and which imposes almost no restrictions and therefore allows the processor to reorder almost fully, demonstrating its full power. Why almost?
First, the standard requirement is to respect the atomicity of relaxed operations. That is, even a relaxed operation must be indivisible, without partial effects.
Secondly, for atomic relaxed-record, speculative writing is prohibited by the standard.
These requirements may impose restrictions on the implementation of atomic relaxed operations in some weakly ordered architectures. For example, a relaxed load of an atomic variable on Intel Itanium is implemented as
load.acq (acquire-read, do not confuse Itanium acquire with C ++ acquire).Requiem for Itanium
I often mention Intel Itanium in my articles. You might get the impression that I am a fan of Itanium architecture, which seems to be slowly dying. No, I'm not a fan, but ...
Itanium VLIW-architecture is somewhat different from others on the principle of building a system of commands. Memory ordering is specified as a load / store / RMW instruction suffix — this is not the case in other modern architectures. Even the terms used - acquire, release - suggest whether C ++ 11 is written off from Itanium.
If we recall the story, Itanium is the architecture (or its descendant) that we all would have sat on now, if at one time AMD hadn’t jumped on and released AMD64 - a 64-bit x86 extension. Intel at this time slowly developed a new architecture for 64-bit computing. And vaguely hinted at this new architecture. From hints it was possible to understand what Itanium is waiting for us on the desktop. By the way, the Maykrosovtovskiy port of Windows and the Visual C ++ compiler for Itanium also indirectly indicate this (has anyone seen working Windows on Itanium?) But the smartest AMD ruined Intel’s plans, and the latter had to be quickly caught up by implementing 64 bits in x86. Itanium remained in the server segment, where it was dying slowly, without receiving adequate resources for development.
Meanwhile, Itanium with its “bundle” of instructions in a “very long word” (VLIW - very long instruction word) is still an interesting and breakthrough processor. The fact that modern processors themselves do - load their execution units, reordering operations, - in Itanium was entrusted to the compiler. But the compilers did not cope with this task and generated (and still generate) not very optimal code. As a result, Itanium’s productivity declined several times - and only due to the irrational (from Itanium’s point of view) distribution of instructions among the “bundles” of the VLIW (I don’t remember what it’s called in Itanium, but the translation - “bundle” - was remembered), which led to irrational loading of its executive units.
So Itanium is our unrealized future.
, , , ?..
Itanium VLIW-architecture is somewhat different from others on the principle of building a system of commands. Memory ordering is specified as a load / store / RMW instruction suffix — this is not the case in other modern architectures. Even the terms used - acquire, release - suggest whether C ++ 11 is written off from Itanium.
If we recall the story, Itanium is the architecture (or its descendant) that we all would have sat on now, if at one time AMD hadn’t jumped on and released AMD64 - a 64-bit x86 extension. Intel at this time slowly developed a new architecture for 64-bit computing. And vaguely hinted at this new architecture. From hints it was possible to understand what Itanium is waiting for us on the desktop. By the way, the Maykrosovtovskiy port of Windows and the Visual C ++ compiler for Itanium also indirectly indicate this (has anyone seen working Windows on Itanium?) But the smartest AMD ruined Intel’s plans, and the latter had to be quickly caught up by implementing 64 bits in x86. Itanium remained in the server segment, where it was dying slowly, without receiving adequate resources for development.
Meanwhile, Itanium with its “bundle” of instructions in a “very long word” (VLIW - very long instruction word) is still an interesting and breakthrough processor. The fact that modern processors themselves do - load their execution units, reordering operations, - in Itanium was entrusted to the compiler. But the compilers did not cope with this task and generated (and still generate) not very optimal code. As a result, Itanium’s productivity declined several times - and only due to the irrational (from Itanium’s point of view) distribution of instructions among the “bundles” of the VLIW (I don’t remember what it’s called in Itanium, but the translation - “bundle” - was remembered), which led to irrational loading of its executive units.
So Itanium is our unrealized future.
, , , ?..
Happens-before, synchronized-with and other relationships
The one who is familiar with the C ++ 11 standard will be asked: “Where are the relations defining the semantics of atomic operations - what happened before, synchronized-with and others?”
I will answer - in the standard.
A good review in terms of the standard is given in the book Anthony Williams C ++ Concurrency in Action ( there is a Russian translation ), the fifth chapter. There are many examples detailed in terms of relationship.
The developers of the standard did an important job - they derived the rules (relations) for the C ++ memory model, and these rules did not describe the placement of memory barriers, but guarantees of the interaction of threads. The result is a compact axiomatic description of the C ++ memory model.
Unfortunately, it is extremely difficult to apply these relationships in practice because of the huge number of options that need to be considered to prove the correctness of the indication
memory_orderin a more or less complex lock-free algorithm. That is why the default model is sequential consistency - this model does not require at all to specify any special memory_orderarguments for atomic operations. As noted, this model is the braking itself.The use of weaker models - acquire / release or relaxed - requires verification of the algorithm.
UPD: chereminrightly pointed out the inaccuracy of the last statement. Indeed, sequential consistency does not guarantee anything by itself — you can write nonsense with its use. Therefore, I clarify: verification of the lock-free algorithm is always required for any memory model, and in the case of weak models it is required especially .

Verification of lock-free algorithms
Until recently, I had known only one verification tool - the Dmitry Vyukov relacy library. Unfortunately, this tool requires the construction of a special model. In fact, you should first build a simplified model of the lock-free algorithm in terms of the relacy library (why simplified? —Because building a model, you usually remove any useful baubles that are not directly related to the algorithm under consideration). This model then needs to be debugged, and only then, when everything is debugged and all atomic operations are supplied with correct
memory_order-arguments, you can write the production-version of the algorithm. This approach is ideal for developers.lock-free algorithms and data structures - those who invent them. Actually, for developers on this model, everything ends. But to the implementers (I like the Russian term “incarnator” - he emphasizes that the subject does not invent anything, but only creatively puts someone’s thought into practice) such a two-step approach often does not fit (due to natural laziness) - they need everything here and Now, and preferably quickly.Apparently, the author of relacy himself, Dmitry Vyukov, understood this flaw of his brainchild (no irony — relacy is really a breakthrough project in his field), and once in an interview on the forum, Intel suggested that it should be done so that the verification tool (relacy or something like that ) was embedded inside the standard library. Then no additional model will be needed. Something that resembles the concept of safe iterators in the STL debug.
Recently, Dmitry, together with his colleagues from Google, presented a new tool ThreadSanitizer. This tool allows you to check the availability of data race (data race) in the program, that is, in fact, the correct use of ordering in atomic operations. Moreover, this tool is implemented not even in STL, but even deeper into the compiler (Clang 3.2, and then in GCC 4.8 ).
The use of ThreadSanitizer is quite simple - just compile the program with certain keys, make a test run - and enjoy the study of extensive logs. I plan to use this tool in the libcds library in the near future in order to make sure that
The importance of verification for the x86 architecture
x86, , (weakly-ordered) . , lock-free : , x86, .
,
lock-free , , x86- - .
,
memory_order - null ( nop!), — x86 . , release- – mov , mov relaxed-.lock-free , , x86- - .
"I do not understand ..." - Criticism of the standard
Yes, I take the liberty to criticize the standard C ++ 11! I do not understand why the standard was chosen when semantics is indicated by the argument of an atomic operation. It would be more logical to use templates and define something like this:
template <typename T> class atomic { template <memory_order Order = memory_order_seq_cst> T load() const ; template <memory_order Order = memory_order_seq_cst> void store( T val ) ; template <memory_order SuccessOrder = memory_order_seq_cst> bool compare_exchange_weak( T& expected, T desired ) ; // }; Let me explain why I believe that such a definition is more correct.
As has been repeatedly stated, the semantics of atomic operations affects not only the processor, but also the compiler. For the compiler, semantics plays the role of [semi] optimization barriers. In addition, the compiler must ensure that atomic operations have been assigned permissible semantics (remember that, for example, the release semantics is not applicable to reading). Therefore, semantics must be defined at compile time. I have no idea what the compiler will do in this code:
extern std::memory_order currentOrder ; std::Atomic<unsigned int> atomicInt ; atomicInt.store( 42, currentOrder ) ; This code does not formally contradict the C ++ 11 standard. However, all the compiler can do here is:
- or to give an error, - then why such an interface of atomic operations is allowed at all, which can lead to an error?
- or apply the sequential consistent semantics - for reasons of "it would not be worse." But then the variable is
currentOrdersimply ignored, and our program gets the brakes we wanted to avoid. - or generate switch / case for all possible values
currentOrder. In this case, instead of one or two assembly instructions, we get an inefficient code. And the problem of semantics suitable for the operation is not solved, it is quite possible to trigger a release-read or acquire-write
The standard approach is devoid of such shortcomings. In template functions, we must specify the compile time constant from the enumeration
memory_order. Yes, the call to atomic operations can be somewhat angular: std::Atomic<int> atomicInt ; atomicInt.store<std::memory_order_release>( 42 ) ; // : atomicInt.template store<std::memory_order_release>( 42 ) ; But, in my opinion, such “angularity” is compensated for by the advantages of the template approach, the unambiguous indication of the semantics of the operation at compile time.
The only explanation of the C ++ 11 approach that comes to my mind is the notorious compatibility with C. After all, in addition to the class,
std::atomicthe C ++ 11 standard introduces free C-shnye atomic functions atomic_load, atomic_storeand so on.I note that in libcds in times when C + 11 was still only in the project, I implemented atomic primitives in terms of patterns. Then I came to the conclusion that we still need to follow the standard, and shoveled the next version of libcds under the C ++ 11 atomic operations interface.
End of Essentials
This article is the conclusion of the Basics .
The end of the basics according to Google
« ». , - …
« ». , - …
Further I undertake to tell already “on a subject” - lock-free data structures and the accompanying algorithms.
Source: https://habr.com/ru/post/197520/
All Articles