Network for the smallest. Micro Issue number 3. IBGP
All issues
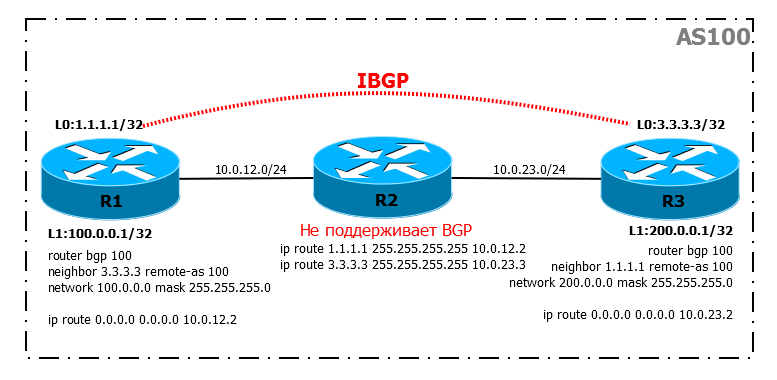
8. Networks for the smallest. Part Eight BGP and IP SLA
7. Networks for the smallest. Part Seven. VPN
6. Networks for the smallest. Part six. Dynamic routing
5. Networks for the smallest: Part Five. NAT and ACL
4. Networks for the smallest: Part Four. STP
3. Networks for the smallest: Part Three. Static routing
2. Networks for the smallest. Part two. Switching
1. Networks for the smallest. Part one. Connection to the equipment cisco
0. Networks for the smallest. Part zero. Planning
7. Networks for the smallest. Part Seven. VPN
6. Networks for the smallest. Part six. Dynamic routing
5. Networks for the smallest: Part Five. NAT and ACL
4. Networks for the smallest: Part Four. STP
3. Networks for the smallest: Part Three. Static routing
2. Networks for the smallest. Part two. Switching
1. Networks for the smallest. Part one. Connection to the equipment cisco
0. Networks for the smallest. Part zero. Planning
How long did the history of linkmeup, but the company grew, developed? The number of routers is already dozens of, its own fiber-optic lines, a developed network in the city. And it was decided to form the company as a provider and provide Internet access services for third-party organizations.
By itself, the administrative task - a license there, search for a client base, advertising, put SORM.
Of course, on the technical side, preparations are also needed - calculate the resources, capacities, ports, prepare a QoS policy. But all this (with the exception of QoS) is a routine.
We want to talk about something else - IBGP. Perhaps the topic will seem a little far-fetched, they say, the internal BGP is the prerogative of quite large providers.
However, this is not the case; now iBGP is involved in enterpraces almost no more often than in providers. For the sole purpose of internal routing. For example, for the sake of VPN is a very popular BGP-based application in a corporate environment. For example, the ability to organize perimeters, isolated on L3, on the already used infrastructure is very valuable. And there may be some fifty or even ten prefixes. Not at all Full View, but still comfortable.
')
It may not be relevant to our Linkmeup network, but it will be completely unforgivable to avoid such a concept. Therefore, we assume that the network is large enough, and we have a need for BGP in the core.
Today we will discuss
- When do you need IBGP
- What are the differences from EBGP
- Route Reflectors
- Confederation
- BGP attributes not covered in the main article
Traditional video
The challenges in this release are not directly related to IBGP, it’s rather BGP in general. It will be interesting to both beginners to break their heads, and old-timers to warm up
What is IBGP?
Let's start with the fact that such a Internal BGP. In essence, this is the same BGP, but inside the AS. It is even configured almost the same.
There are two main applications:
Reservation When there are several links to providers and you don’t want to close everything on one of your border routers (the so-called boredre (from the Old Slavic border), several routers are put, and between them IBGP rises so that they always have relevant information about all routes.
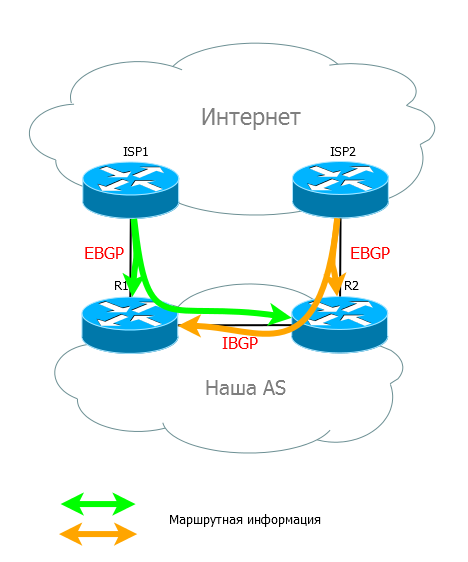
In case of problems, the ISP2 R2 provider will know that the same networks are available through ISP1. He will be informed about this by R1 via IBGP.
Connecting clients by BGP . If there is a task to connect a client via BGP, and you have more than one router, you cannot do without IBGP.
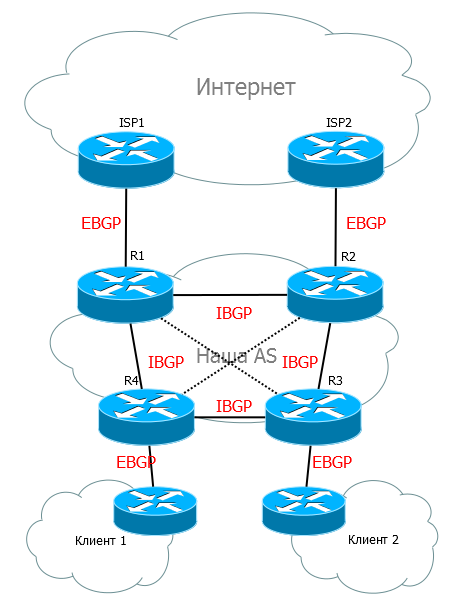
In order for R4 to transfer 1 Full View to the Client, it must receive it via IBGP from R1 or R2.
Again, EBGP is used between Automnom Systems, IBGP - inside .
Differences between IBGP and EBGP
1) The main subtlety that appears when moving inside the Autonomous System and from where the legs of almost all differences grow are loops. In EBGP, we dealt with them using AS-Path. If the list already had its own AS number, then such a route was discarded.
But, as you remember, when passing a route within the Autonomous System, AS-Path does not change. Instead, IBGP resorts to tricks: a fully connected topology is used — all neighbors have sessions with all — Full Mesh .
At the same time, the route received from the IBGP neighbor is not announced to other IBGP neighbors.
This allows all routers to have all the routes and avoid loops.
Let's explain with examples.
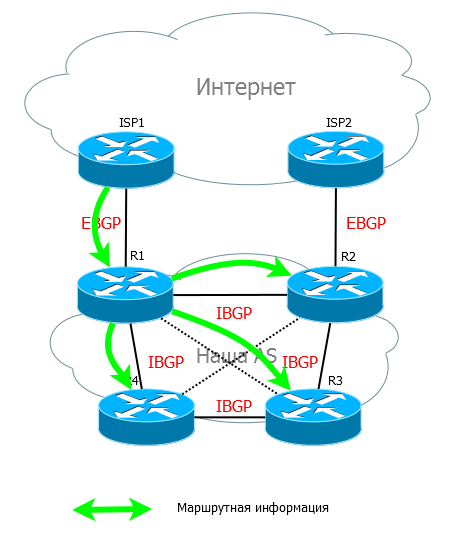
How could this be in such a topology, for example, if you do not use loop avoidance technology:
R1 received an announcement from an EBGP neighbor, passed it to R2, he passed it to R3, R3 passed it to R4. It seems that all well done, everyone knows where the Internet is. But R4 transmits this announcement back to R1.

R1 received the route from R4, and at a profit it is exactly the same as the original from the ISP - AS-Path has not changed. Therefore, even a new route from R4 can be selected as a priority, which, of course, is unwise: not only are the routes not correctly studied, so the traffic may eventually stop and will not get to the destination.

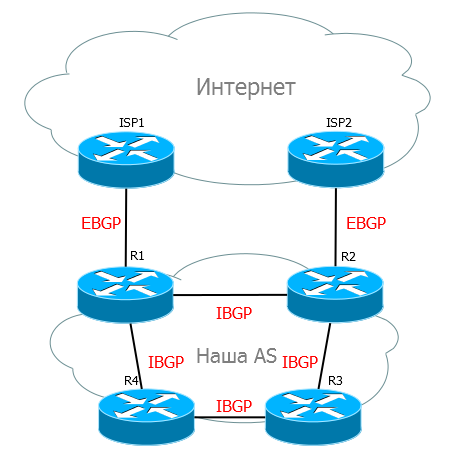
In the case of a fully connected topology and the Split Horizon rule, this situation is excluded. R1, having received an announcement from ISP1, sends it to all its neighbors at once: R2, R3, R4. And those, in turn, retain these announcements, but transmit only to EBGP partners, but not IBGP, precisely because they were received from an IBGP partner. That is, all BGP routers have up-to-date information and loops are excluded.
Moreover, it does not matter if the neighbors are connected directly or through intermediate routers. For example, in the above scheme, R1 does not have a connection with R3 directly - they communicate via R2, but this does not prevent them from establishing a TCP session and BGP on top of it.
The concept of Split Horizon is used here in a broader sense. If in RIP it meant “not to send announcements back to the interface where they came from ”, to IBGP it means “not to send announcements from IBGP partners to other IBGP partners .”
2) The second subtlety is the address of Next Hop . In the case of External BGP, the router, when sending an announcement to its EBGP neighbor, first changes the address of the Next-Hop to its own, and then sends it. It is quite logical action.
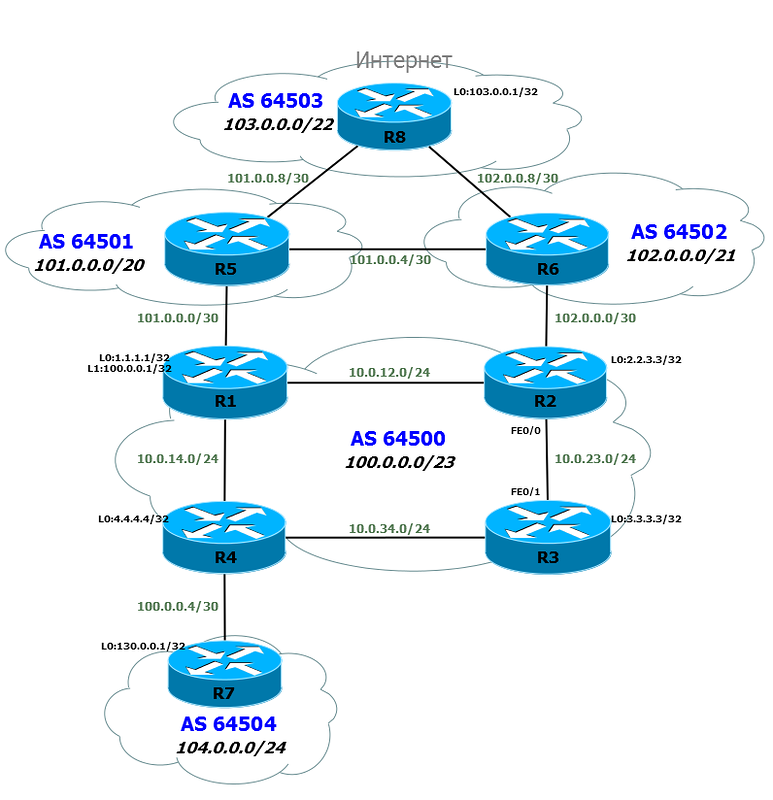
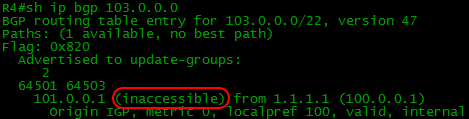
Here's how the announcement of the network 103.0.0.0/22 looks like when transferring from R5 to R1:
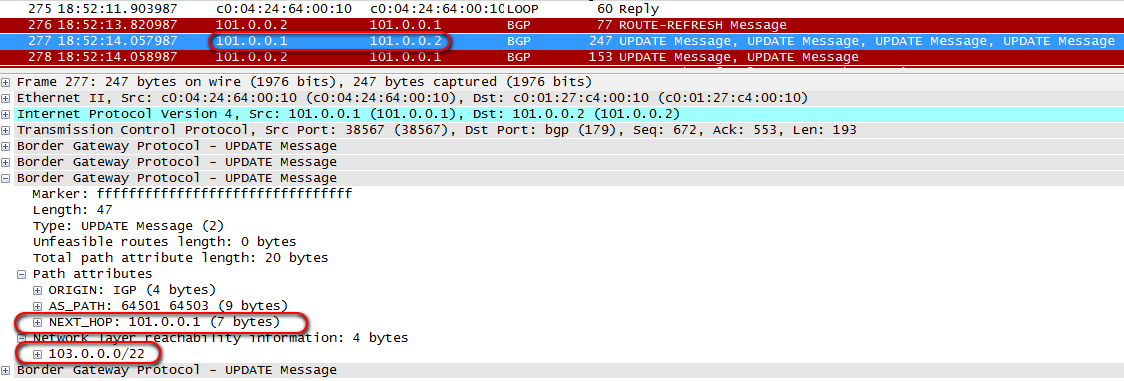
If the router sends an announcement to the IBGP neighbor, then the Next-Hop address does not change. Hm Unclear. Why? This is at odds with the usual understanding of the DV-routing protocol.
Here is the same announcement when transferring from R1 r R2:
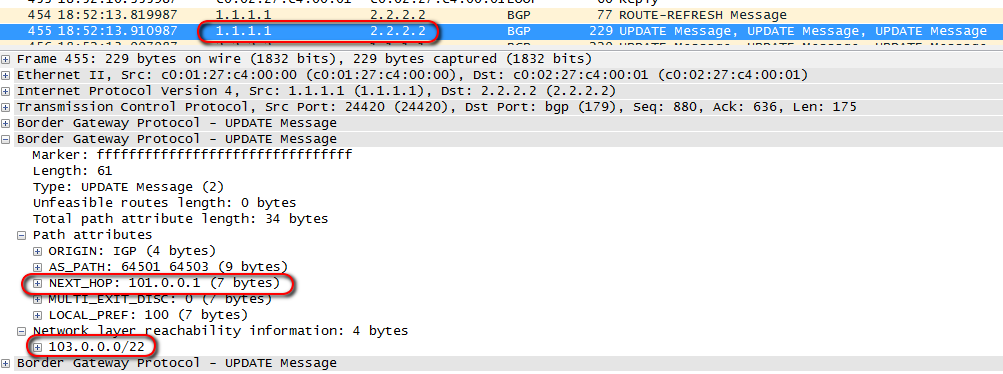
The fact is that here the concept of Next-Hop is different from that used in IGP. In IBGP, it reports the exit point from the local AS.

And here another moment arises - it is important that the recipient of such an announcement had a route to Next-Hop - this is the first thing that is checked when choosing the best route. If it does not exist, the route will be placed in the BGP table, but it will not be in the routing table.
This process is called recursive routing.
That is, in order for R2 to send ISP1 packets, it must know how to get to the address 101.0.0.1, which in this scheme is Next-Hop for the network 103.0.0.0/22.
In principle, almost all of the equipment makes it possible to change the Next-Hop address to your own when sending a route to an IBGP neighbor.
On a tsiska, this is done by the " neighbor XYZ Next-Hop-self " command. You will see later how this applies.
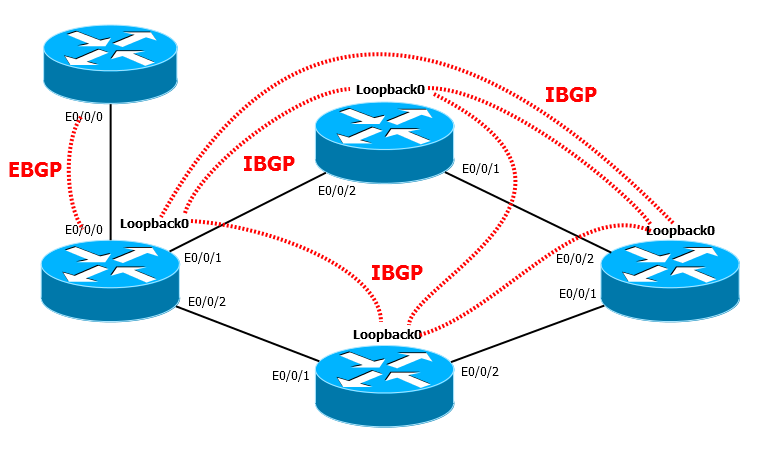
3) The third point : if the EBGP usually implies a direct connection of two neighbors to each other, in the Internal BGP neighbors can be connected through several intermediate devices.
In fact, EBGP can also be set up for neighbors who are a few hops from each other and this is actually practiced, for example, when setting up Inter-AS Option C. This business is called MultiHop BGP and is activated with the command " neighbor XYZ ebgp-multihop "in BGP configuration mode.
But for IBGP, this works by default.
This allows you to set up an IBGP partnership between Loopback addresses. This is done in order not to become attached to the physical interfaces - in case of the main link falling, the BGP session will not be interrupted, because the loopback will be available through the backup.
This is the most common practice.
However, EBGP is usually installed on link addresses, because as a rule there is only one connection and if it fails, the Loopback will still not be available. Yes, and I still don’t really want to configure some additional routing with the provider.
An example of the configuration of such a neighborhood:
=====================
 Problem number 1
Problem number 1Scheme:
In this scenario, we have two BGP routers R1 and R3, but they are located in different parts of the city and are connected via an intermediate router on which BGP is not configured.
Condition:
The IBGP session is perfectly established, even though the intermediate BGP router is not enabled, and we even see the routes:

But where is the ping?

Details of the problem here .
=====================
You need to try to avoid situations where there are non-BGP routers between IBGP neighbors.
In fact, there is a mechanism that allows if not corrected, then at least to prevent such a situation - IGP Synchronization. It will not allow the route to be added to the table if the exact same route is not known through IGP. This to some extent ensures that intermediate devices, regardless of whether BGP is activated on them or not, will have the necessary routes.
But I do not know those desperado who decided to enable IGP Synchronization.
First, how will such routes get to IGP? Only redistribution. Now imagine how Full View slowly fills LSDB OSPF, penetrating into remote corners of memory and forcing the processor to look for the shortest possible routes until exhausted. Do you want this ?
And, secondly, resulting from the “first”, by default, IGP-synchronization is turned off on almost all modern routers.
=====================
Problem number 2A link appeared between AS64504 and AS64509, which links them directly. Both networks used OSPF and seamlessly combined the network into one. But, after verification, it turned out that the traffic goes through AS64500, and not directly from AS64504 to AS64509, through OSPF.
Change BGP configuration:
- R7 must use OSPF if traffic goes to the network 109.0.0.0/24
- R9 must use OSPF if traffic goes to the network 104.0.0.0/24
Details of the task here
=====================
BGP practice
Let's now go back to the network linkmeup and try to run BGP in it.
The scheme will be as follows (on click more detailed with interfaces and IP-addresses):

As you can see, we have significantly modified it. Abandoned the naming of devices by geolocation and functions, changed the addressing for the sake of ease of remembering and understanding.
The routers will be called R X , the fine subnet between the routers R X and R Y is assigned as follows: 10.0. XY .0 / 24. Addresses are respectively 10.0. Xy. X at R X and 10.0. Xy. Y y ry .
From above, everything remains the same as in the main article on BGP .
And below was added our first commercial client that connected via BGP.
=====================
Problem number 3Our new client AS 64504 is connected to our network. And in the future, he plans to connect to another provider and he already has his PI-block of addresses. But at this stage, there is a connection only to our AS and therefore the client can use the private AS number.
Task: When a client network is announced to higher providers, remove the AS64504 private number.
Configuration and scheme: basic .
Details of the problem here .
=====================
EBGP
I think you should not stop at setting up and working EBGP - we did it in the last article.
Just for example, we give the session configuration with a new client:
R4
interface FastEthernet1/0 ip address 100.0.0.5 255.255.255.252 router bgp 64500 network 100.0.0.0 mask 255.255.254.0 neighbor 100.0.0.6 remote-as 64504 interface Loopback1 ip address 130.0.0.1 255.255.255.255 ! interface FastEthernet0/0 ip address 100.0.0.6 255.255.255.252 ! router bgp 64504 network 130.0.0.0 mask 255.255.255.0 neighbor 100.0.0.5 remote-as 64500 Everything is simple and clear, after setting up all external neighbors, we will have the following situation:
On other devices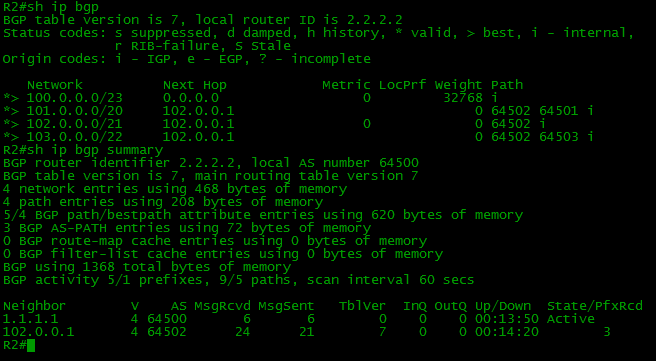
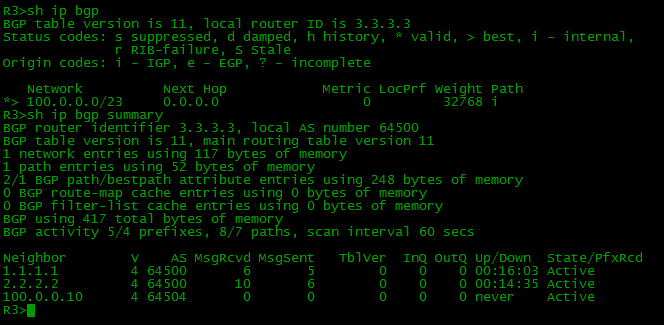
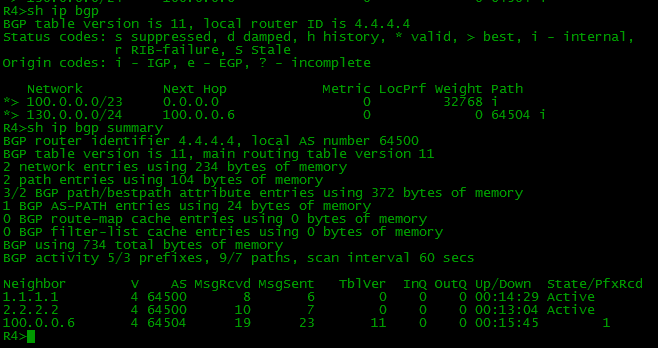
Each BGP router knows only about those networks that it received directly from its EBGP neighbor.
IBGP
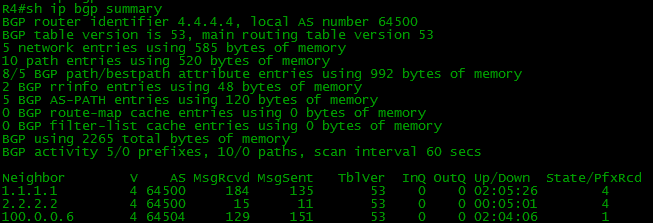
Now let's turn to the configuration of our AS routers from the point of view of IBGP.
First, as we said earlier, IBGP is usually installed between Loopback interfaces to increase availability, so first of all we will create them:
On all routers on the Loopback0 interface, configure the IP address XXXX, where X is the router number (this is for example only and do not even think of doing it on a real network):
R1
interface Loopback0 ip address 1.1.1.1 255.255.255.255 R2 interface Loopback0 ip address 2.2.2.2 255.255.255.255 R3 interface Loopback0 ip address 3.3.3.3 255.255.255.255 R4 interface Loopback0 ip address 4.4.4.4 255.255.255.255 They will become the Router ID for both OSPF and BGP.
By the way, about OSPF. As a rule, IBGP “stretches” over the existing IGP on the network. IGP provides connectivity of all routers to each other over IP, a quick response to changes in the topology and transfer of routing information about internal networks.
Configure internal routing. Ospf
Actually this will go on.
Our task is for everyone to know about all link subnets, addresses of Loopback interfaces and, of course, about our white addresses.
OSPF configuration:
R1
router ospf 1 network 1.1.1.1 0.0.0.0 area 0 network 10.0.0.0 0.255.255.255 area 0 network 100.0.0.0 0.0.1.255 area 0 R2 router ospf 1 network 2.2.2.2 0.0.0.0 area 0 network 10.0.0.0 0.255.255.255 area 0 network 100.0.0.0 0.0.1.255 area 0 R3 router ospf 1 network 3.3.3.3 0.0.0.0 area 0 network 10.0.0.0 0.255.255.255 area 0 network 100.0.0.0 0.0.1.255 area 0 R4 router ospf 1 network 4.4.4.4 0.0.0.0 area 0 network 10.0.0.0 0.255.255.255 area 0 network 100.0.0.0 0.0.1.255 area 0 After that, connectivity appears with all Loopback addresses.
Configure BGP
On each node you need to configure all the neighbors manually:
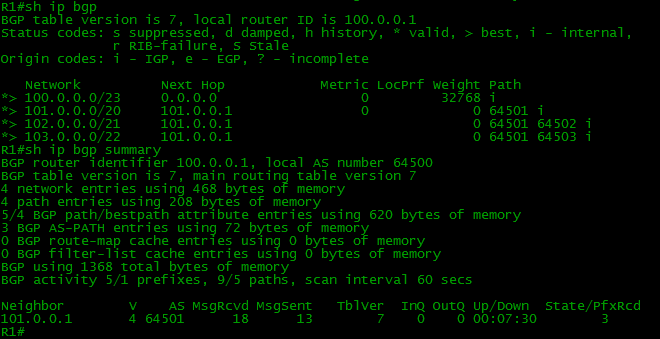
R1
router bgp 64500 network 100.0.0.0 mask 255.255.254.0 neighbor 2.2.2.2 remote-as 64500 neighbor 2.2.2.2 update-source Loopback0 neighbor 3.3.3.3 remote-as 64500 neighbor 3.3.3.3 update-source Loopback0 neighbor 4.4.4.4 remote-as 64500 neighbor 4.4.4.4 update-source Loopback0 A team of the type 2.2.2.2 remote-as 64500 announces a neighbor and informs that it is in AS 64500, BGP understands that this is the same AS in which it works and then considers 2.2.2.2 as its IBGP partner.
A command like neighbor 2.2.2.2 update-source Loopback0 reports that the connection will be established from the address of the Loopback interface. The fact is that on the other side (on 2.2.2.2) the neighbor is configured as 1.1.1.1 and it is from this address that all BGP messages are waiting.
We apply this setting on all nodes of our AS:
R2
router bgp 64500 network 100.0.0.0 mask 255.255.254.0 neighbor 1.1.1.1 remote-as 64500 neighbor 1.1.1.1 update-source Loopback0 neighbor 3.3.3.3 remote-as 64500 neighbor 3.3.3.3 update-source Loopback0 neighbor 4.4.4.4 remote-as 64500 neighbor 4.4.4.4 update-source Loopback0 R3 router bgp 64500 network 100.0.0.0 mask 255.255.254.0 neighbor 1.1.1.1 remote-as 64500 neighbor 1.1.1.1 update-source Loopback0 neighbor 2.2.2.2 remote-as 64500 neighbor 2.2.2.2 update-source Loopback0 neighbor 4.4.4.4 remote-as 64500 neighbor 4.4.4.4 update-source Loopback0 R4 router bgp 64500 network 100.0.0.0 mask 255.255.254.0 neighbor 1.1.1.1 remote-as 64500 neighbor 1.1.1.1 update-source Loopback0 neighbor 2.2.2.2 remote-as 64500 neighbor 2.2.2.2 update-source Loopback0 neighbor 3.3.3.3 remote-as 64500 neighbor 3.3.3.3 update-source Loopback0 Now we can verify that the neighborhood relationship has been established safely.

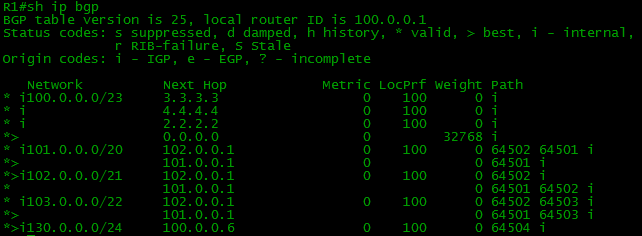
All routes are in our BGP table.
Network 130.0.0.0/24 can be seen on R1:
Network 103.0.0.0/22 can be seen on R4:
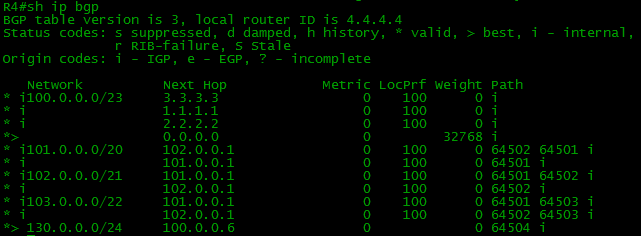
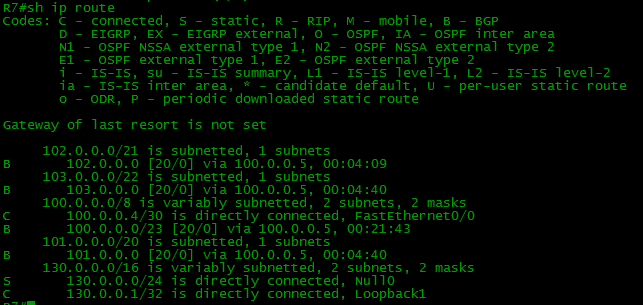
Is it time to check the end-to-end ping from R7 (our client) to the Internet (103.0.0.1)?

We arrived.
We will not torment the reader for a long time and immediately look at the routing table, R4.

And on R7 at the same time:
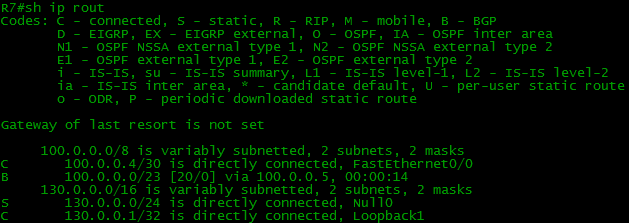
BUT? Where are my routes? Where are all my routes? R4 does not know anything about the Balagan-Telecom network, the Filkin Certificate, the Internet, respectively, there are none on R7 either.
Remember, we talked about Next-Hop above? Like, he does not change in the transfer of IBGP?
Pay attention to the Next-Hop obtained R4 routes:
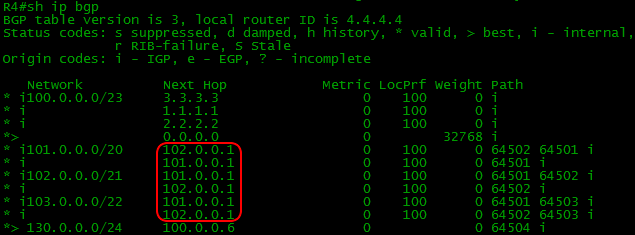
Despite the fact that they came to R4 from R1 and R2, Next-Hop addresses on them are R5 and R6 - that is, they have not changed.
This means that traffic to the network 103.0.0.0/22 R4 should be sent to the address 101.0.0.1, well, or to 102.0.0.1. Where are they in the routing table? There are no them in the routing table. Well, and this is natural - where will they come from.
To solve this problem, we have 3 ways:
1) Setting up static routes to these addresses is still fun, even if it is the gateway of last resort.
2) Add these interfaces (towards providers) to the IGP routing domain. Also an option, but as you know, external networks are not recommended to be added to IGP.
3) Change the Next-Hop address when transmitting to IBGP neighbors. Beautiful and scalable. A situation that will prevent us from realizing this, simply cannot be.
As a result, we add the following command to BGP: neghbor 2.2.2.2 Next-Hop-self . For each neighbor, on each node.
After that we see the following situation
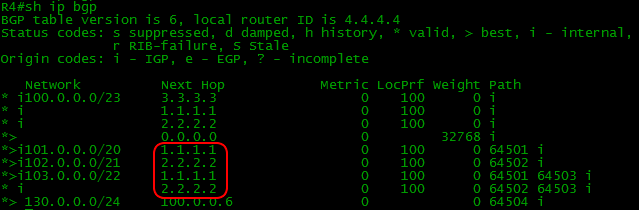
And, how to get to the address 1.1.1.1 - we know thanks to OSPF:

As you can see, all interesting networks have already appeared in table R7.
Now the ping is successful:

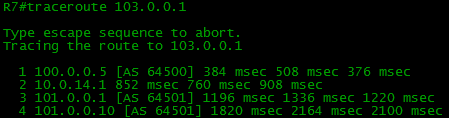
A very simple question: where are these gigantic delays in tracing? And often this situation also happens:

Device configuration
=====================
Problem number 4You need to configure the following rules for working with neighboring AS:
- prefixes are received from all neighboring ASs only if there are no more than 10 autonomous systems in them (in real life, the order of this value may be around 100).
- all prefixes that are accepted from clients must be with a mask of no more than 24 bits.
Configuration and scheme: basic .
Details of the problem here .
=====================
What can we improve?
Of course, the process of setting up BGP. Still, these are labor costs - to make very similar settings on each node. For simplicity, the concept of peer-group is introduced, which, based on the name, allows you to combine your neighbors into groups and use one command to set the necessary parameters for everyone at once.
In order not to be unfounded, we will implement it on our network:
R1
router bgp 64500 network 100.0.0.0 mask 255.255.254.0 neighbor AS64500 peer-group neighbor AS64500 remote-as 64500 neighbor AS64500 update-source Loopback0 neighbor AS64500 Next-Hop-self neighbor 2.2.2.2 peer-group AS64500 neighbor 3.3.3.3 peer-group AS64500 neighbor 4.4.4.4 peer-group AS64500 The AS64500 peer-group neighbor command creates an AS64500 neighbor group.
The AS64500 remote-as 64500 neighbor command reports that all neighbors are in AS 64500.
The AS64500 update-source Loopback0 command indicates that the connection will be established with all neighbors from the Loopback interface address.
The AS64500 Next-Hop-self neighbor command causes the router to change the Next-Hop address to its own when transmitting announcements to all its neighbors.
Further, in fact, we add neighbors to this group.
Moreover, we can easily copy the configuration commands of a group of neighbors to other routers, changing only the addresses of neighbors.
A couple of comments on the Peer-group:
1) For all members of a group, policies must be identical.
2) In fact, cisco has long been using dynamic update groups. This saves CPU resources, since the processing is carried out not once for each group member, but once for the whole group. The actual Peer groups only facilitate the configuration, and optimization is left to the mercy of the Update groups.
Surely, young green engineers had a question: why it is impossible to transfer information about public addresses via IBGP? Is he supposed to be for this? And even a more general question, why it is impossible to do BGP alone, without OSPF or IS-IS, for example? (No, seriously, forums sometimes boil holivary on the topic of BGP vs OSPF). Well, in fact, after all, there is also a routing protocol - what's the difference, to transfer information between AS or between routers - there is also Internal BGP.
To this I want to say that it will be enough for you to work a little with BGP on a real network in order to understand the insanity of such a venture.
The most important obstacle is Full Mesh . We'll have to set up a neighborhood with all all routers manually. OMG, my life and health are dear to me. (Yes, even despite the presence of Route Reflectors and scripts - these are unnecessary operations)
Another problem is the slow response and the Remote-Vector approach to the distribution of route information.
And here you can reasonably argue that, they say, there is a BFD. However, it will reduce the time to detect a problem, but convergence / restoration of connectivity will still be slow.
The third subtle point is the inability to automatically explore the neighbors. Which leads to their manual configuration.
All of the above implies scalability and service issues.
Just try it yourself to use BGP instead of IGP on a network of 10 routers, and everything will become clear.
The same applies to the distribution of white addresses - IBGP will cope with this, but each router will have to manually register all the subnets.
Well, for example, our network is 100.0.0.0/23. Suppose that 3 clients are connected to router R3 by link addresses: 100.0.0.8/30, 100.0.0.12/30 and 100.0.0.16/0.
So these 3 subnets you will need to enter into the BGP with three network commands, while in IGP it is enough to activate the protocol on the interface.
You can, of course, resort to clever redistribution of routes from IGP, but this smacks of crutches and an even less transparent configuration.
What are we doing all this for? eBGP is a routing protocol, no fools. At the same time, iBGP is not quite. It is more like a top-level application that organizes the distribution of route information throughout the network. In unchanged form, and without informing the neighbor “over there through me” at each iteration. In IGP, this behavior also sometimes occurs, but there is an exception, and here it is the norm.
I want to emphasize once again, IGP and IBGP work in a pair, in a bundle, each of them doing their work.
IGP provides internal IP connectivity, a quick (read instant) response to changes in the network, notification of all nodes about it as soon as possible. He knows about the public addresses of our AS.
IBGP handles Internet routes in our AS and their transit from Uplink to customers and back. Usually he knows nothing about the structure of the internal network.
If the question “which is better than BGP or IS-IS?” Occurred to you, this is good, it means that you have an inquiring mind, but you must clearly understand that there is only one correct answer - these are fundamentally different things, you cannot compare them and choose a miss “Routing technology 2013”. IBGP runs on top of IGP .
=====================
Problem number 5The higher AS 604503 aggregates several networks, including ours, into one 100.0.0.0/6 range. But this summary prefix has returned to our autonomous system, although it should not have been.
Configure R8 so that the aggregated prefix does not fall into the BGP table of routers that announce the subnets of this prefix. Do not use filtering for this.
Configuration and scheme: basic .
Details of the problem here .
=====================
Problem en square
At this point, the IBGP topic could have been closed if not for one “BUT” - Full Mesh. We talked about the problems of full mesh topology when we discussed OSPF . There, the output was the DR - Designated Router, allowing to reduce the number of connections between routers from n * (n-1) / 2 to n-1. But, if in the case of OSPF, this topology was rather an exception, because more than 2-3 routers in one L2 segment are quite rare, then for IBGP this is the most common practice. The “large” account of BGP routers inside the AS goes to the tens. And already for 10 devices at each node it will be necessary to register 9 neighbors, that is, only 45 connections and 90 neighbor commands at a minimum. Not sickly so.
So, we come to terms like Route Reflector and Confederation . I don’t know why, but this topic has always frightened me by some contrived complexity.
Route Reflectror
What is the essence of the concept Route Reflector? This is a special IBGP router, which, on the basis of its literal translation, performs the function of reflecting routes — one neighbor sends it to the route, and it sends it to all others. That is, in fact, on IBGP routers you need to set up a session with only one neighbor — with Route Reflector, and not with nine. Everything is quite simple and here is a direct analogy with the very DR OSPF.
A little more about the rules of the RR.
First, we introduce the notion RR client and non-RR client .
For this router, the client is an iBGP neighbor that is specifically declared as an RR client and for which special rules apply. Non-client - iBGP neighbor, which is not declared as RR client
RR servers can be (and should be in terms of fault tolerance) a few. And client / non-client concepts are strictly local to each RR server.
RR-server (or several) in conjunction with with their customers form a cluster .
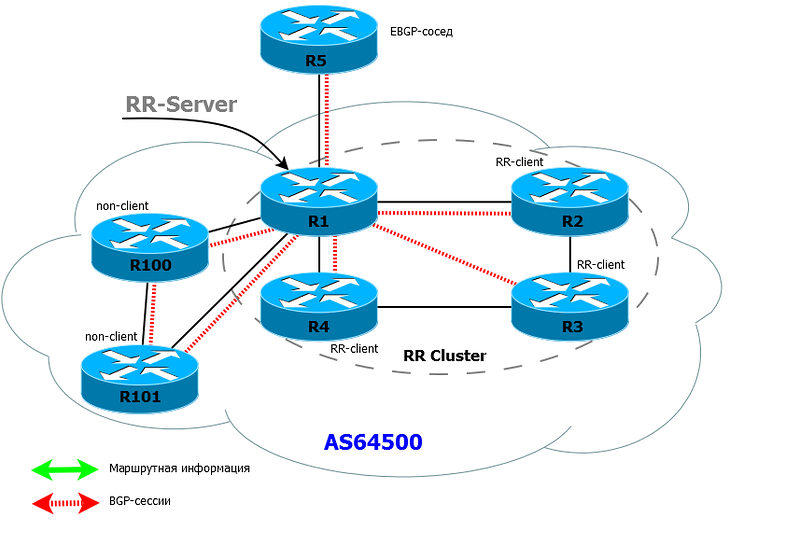
Rules of the RR
- If the RR has received the route from the client, it sends it to all its customers, non-customer neighbors, and external (EBGP) neighbors.
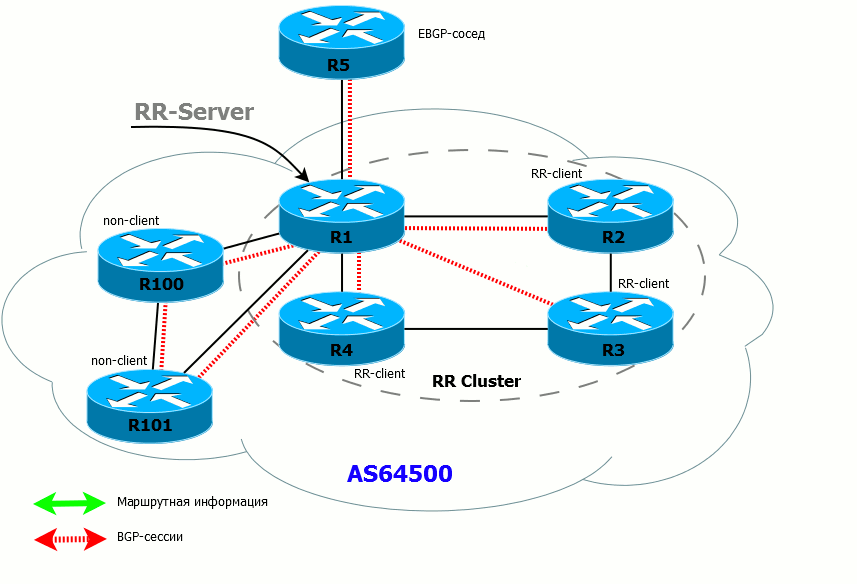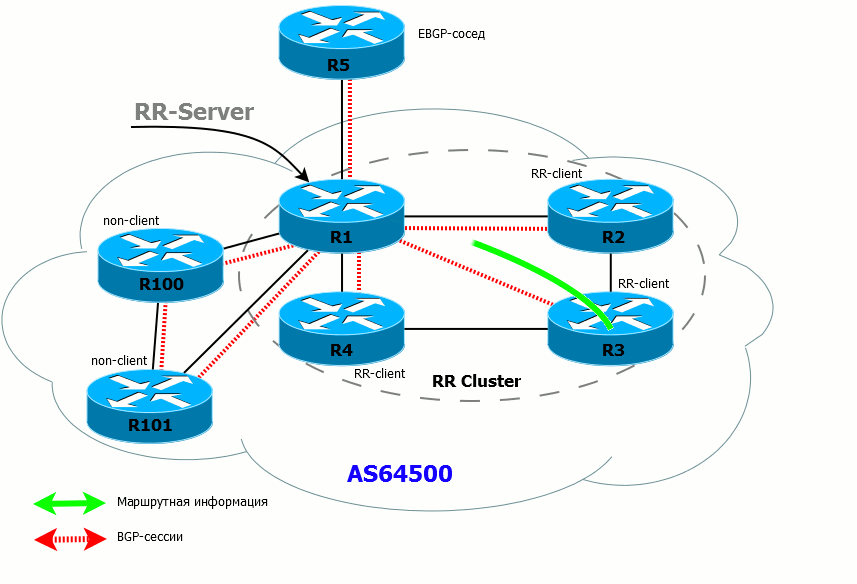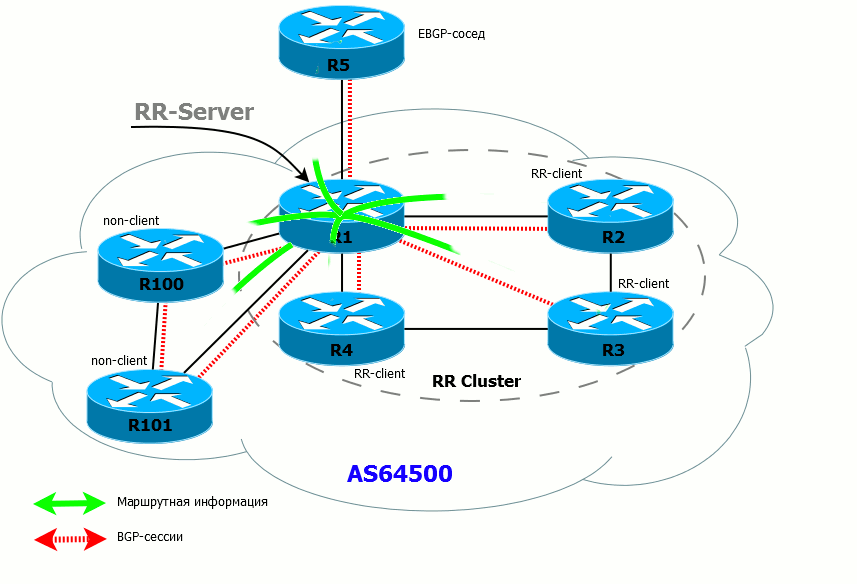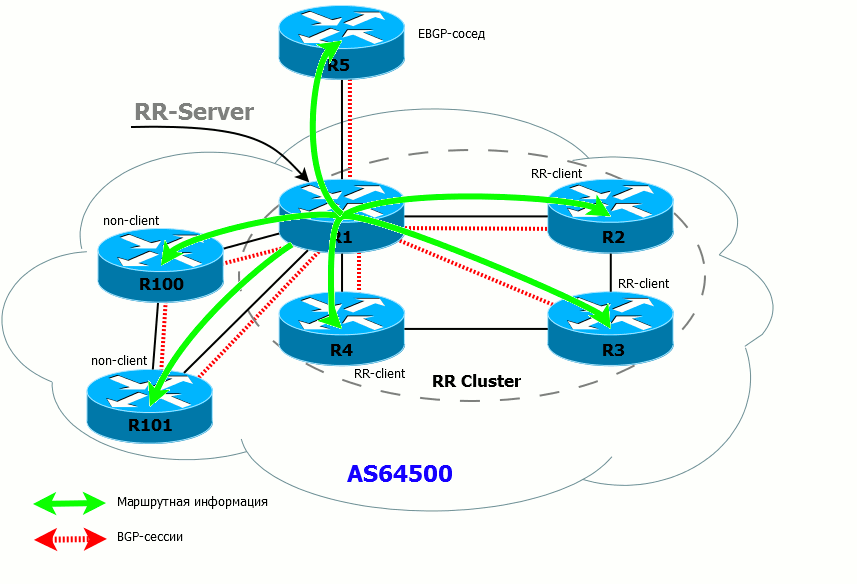
- If the RR has received a route from a non-client, it sends it to all clients and EBGP neighbors. Routes are NOT sent to non-clients (because they have already received these routes directly from the source router).
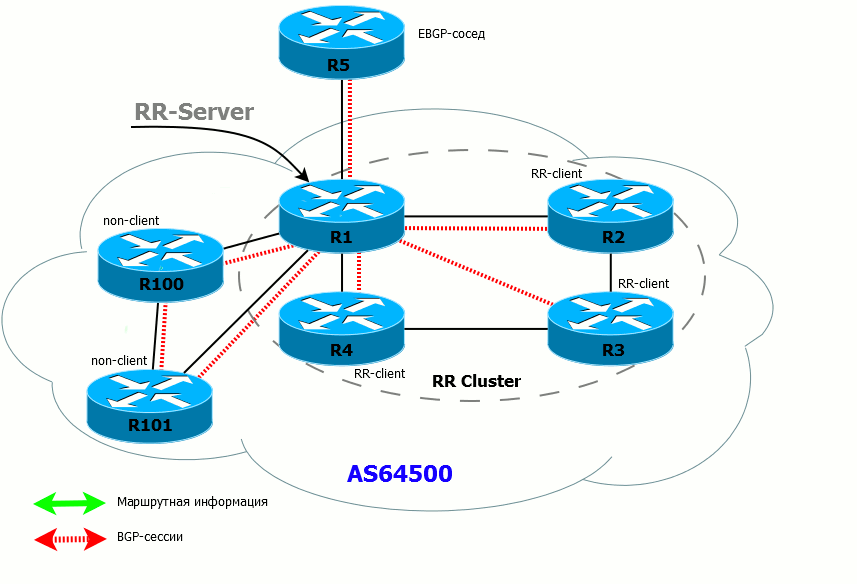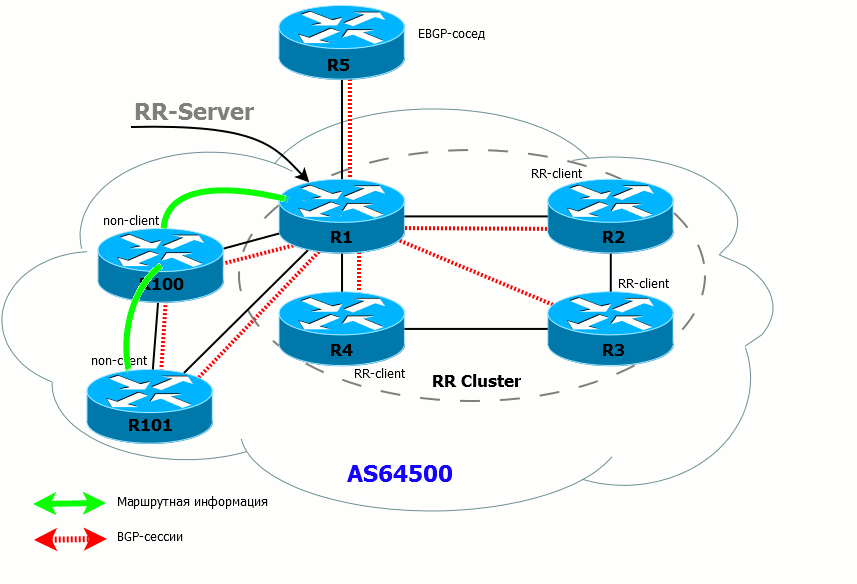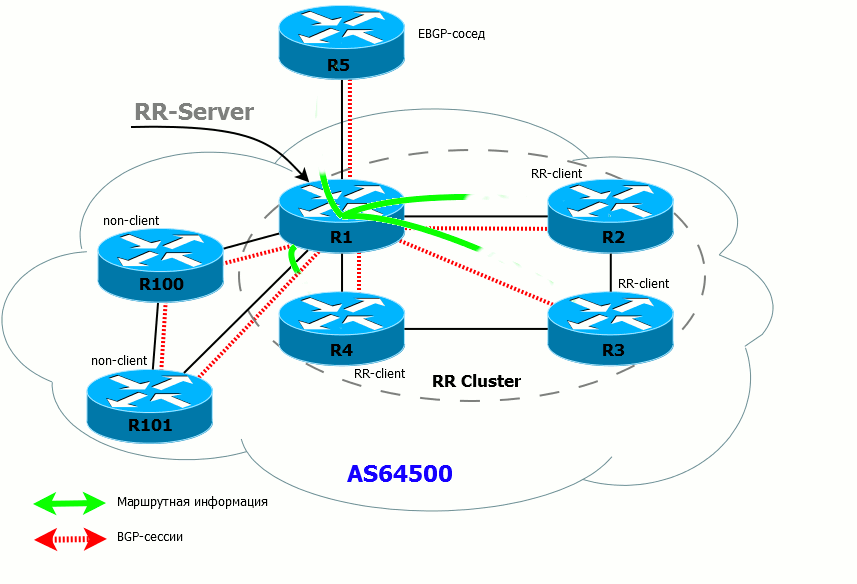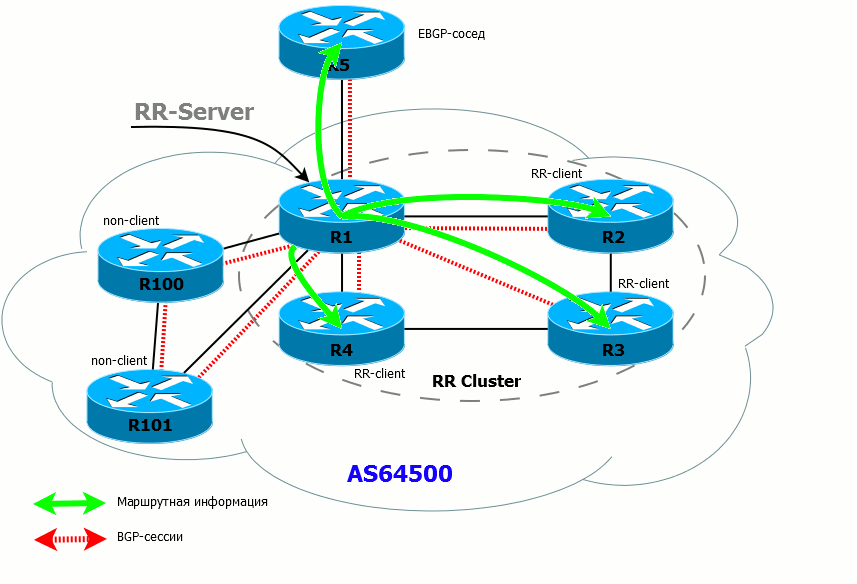
- If the RR has received a route from an EBGP neighbor, it sends it to all its clients, non-neighbor clients and external neighbors.
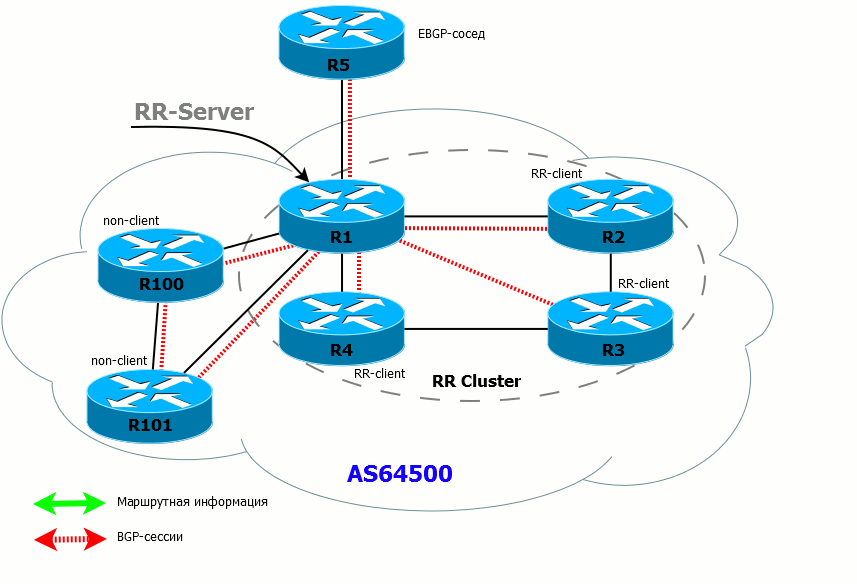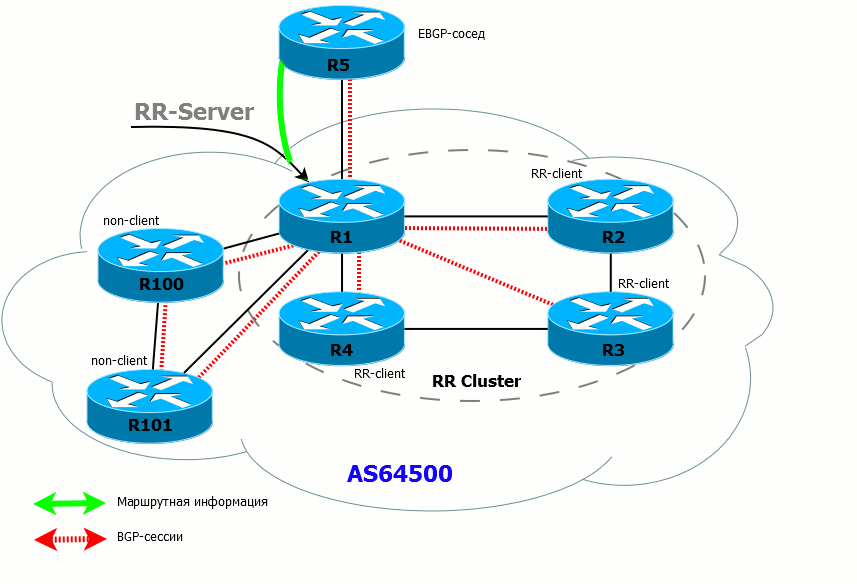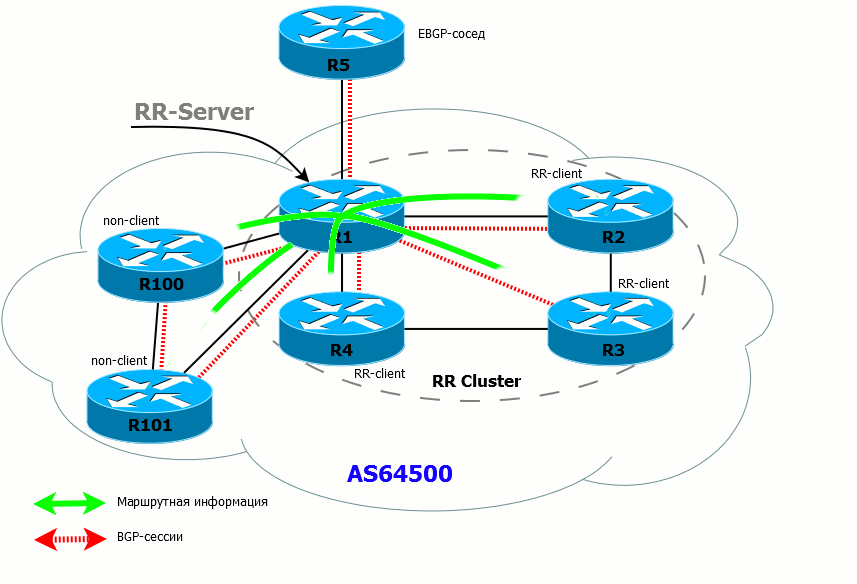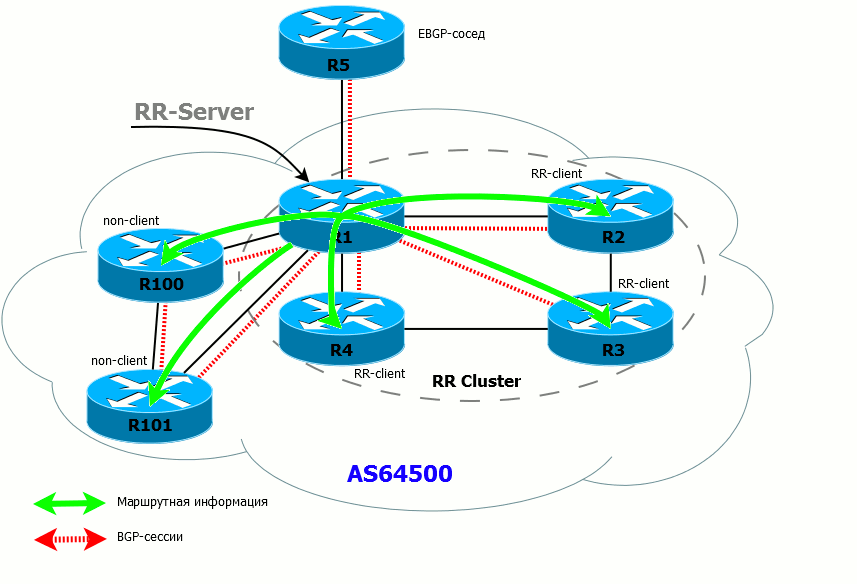
- If the client has received a route from the RR, he can send it only to the EBGP neighbor.
As we said above, there can be several Route reflectors on the network. This is normal, it will not cause the formation of a loop, because the Originator ID attribute exists - as soon as the RR receives the route, where it is specified as the sender of this route, it will discard it. Each RR in this case will have a BGP routing table exactly the same as the others. This is forced redundancy, which allows to significantly increase stability, but at the same time you should have sufficient performance of the devices themselves, for example, to maintain a pair of Full View on each.
But several RRs can cluster into clusters and
Belonging to a single cluster is configured on each RR and is determined by the Cluster ID attribute.
And here is a delicate moment - it is considered that Best Practice is setting up the same Cluster-ID on all RRs, but in fact this is not always the case. You need to choose based on the design of your network. Moreover, it is often recommended to even intentionally separate Route Reflectors - oddly enough, this increases the stability of the network.
In order not to spread across the tree, just give a link to the material about it.
This is the usual RR scheme:

The scheme with the main and backup RR:
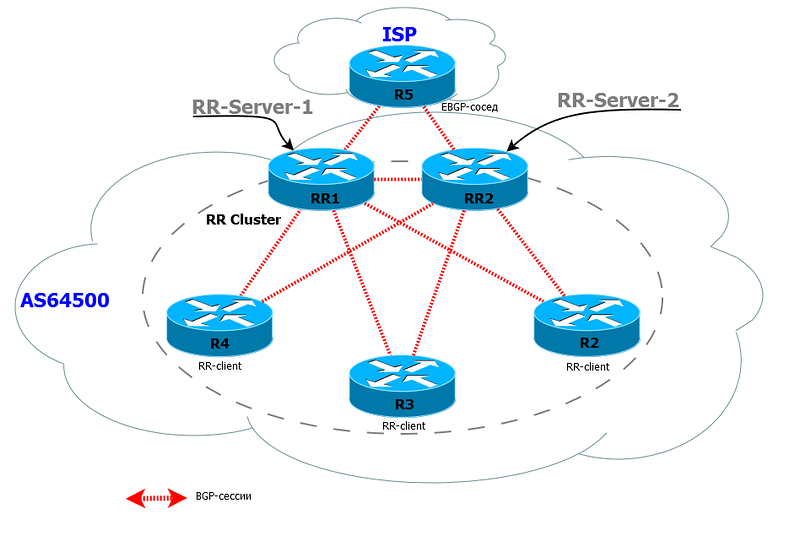
Within the cluster between the entire RR there must be complete connectivity.
There can be several clusters and a full-mesh network should also be created between them:
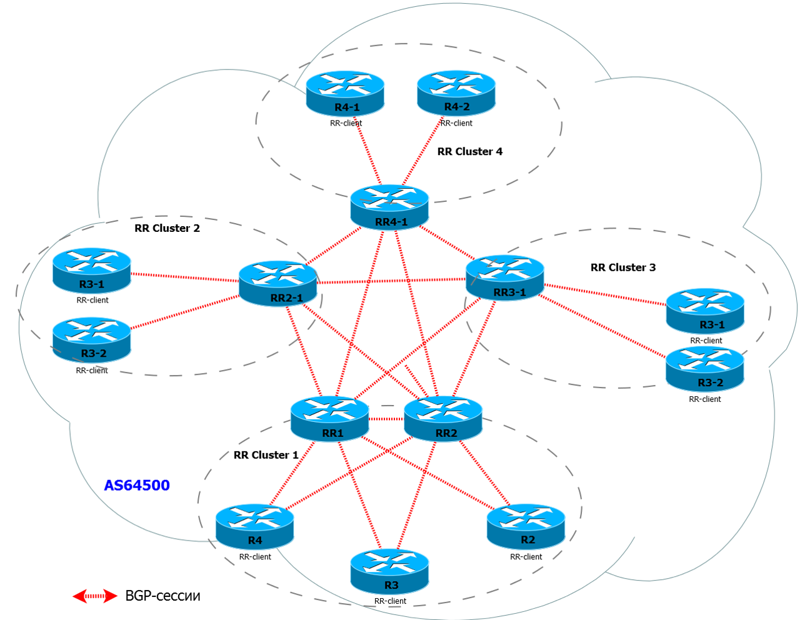
We repeat that the cluster: this is the Ruth-reflector (one or several) together with all its clients.
In addition, hierarchical RRs are often practiced. For example:
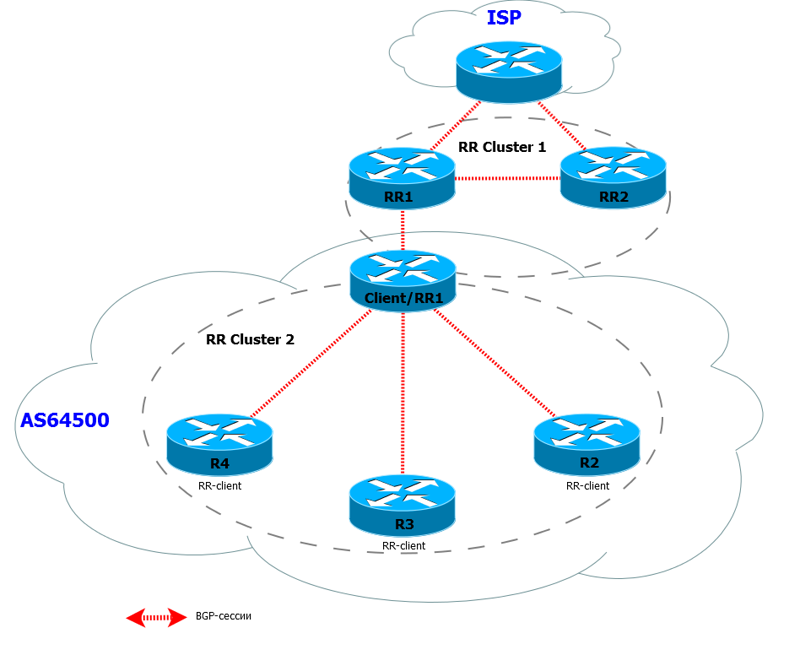
RR1 receives routes from the remote AS and distributes them to its subsidiary RR (Client / RR1), which in turn distributes them to customers.
This makes sense only in fairly large networks.
Regarding Route Reflectors, it is important to understand that the router itself, performing the RR functions, is not necessarily involved in data transmission. Moreover, RRs are often specifically taken out of the traffic path so that it performs solely the duties of transferring the routes so as not to increase the load on it.
RR practice
For example, suppose that in our network R1 will act as RR.
Here is the configuration of the simplest case of RR - single, without a cluster.
R1
router bgp 64500 network 100.0.0.0 mask 255.255.254.0 neighbor AS64500 peer-group neighbor AS64500 remote-as 64500 neighbor AS64500 update-source Loopback0 <b>neighbor AS64500 route-reflector-client</b> neighbor AS64500 Next-Hop-self neighbor 2.2.2.2 peer-group AS64500 neighbor 3.3.3.3 peer-group AS64500 neighbor 4.4.4.4 peer-group AS64500 neighbor 101.0.0.1 remote-as 64501 R2 router bgp 64500 network 100.0.0.0 mask 255.255.254.0 neighbor 1.1.1.1 remote-as 64500 neighbor 1.1.1.1 update-source Loopback0 neighbor 1.1.1.1 Next-Hop-self neighbor 102.0.0.1 remote-as 64502 R3 router bgp 64500 network 100.0.0.0 mask 255.255.254.0 neighbor 1.1.1.1 remote-as 64500 neighbor 1.1.1.1 update-source Loopback0 neighbor 1.1.1.1 Next-Hop-self R4 router bgp 64500 network 100.0.0.0 mask 255.255.254.0 neighbor 1.1.1.1 remote-as 64500 neighbor 1.1.1.1 update-source Loopback0 neighbor 1.1.1.1 Next-Hop-self neighbor 100.0.0.6 remote-as 64504 Note the " neighbor AS64500 route-reflector-client " command added to the R1 setting and that the BGP configuration on all other devices is completely identical, with the exception of external neighbors (102.0.0.1 for R2 and 100.0.0.6 for R4).
In general, nothing will change externally. R4, for example, will see everything exactly the same, except for the number of neighbors:

Please note that Route Reflector does not change the Next-Hop reflected routes to its own, despite the presence of the Next-Hop-self parameter.
At the Route Reflector itself, the difference will look like this:
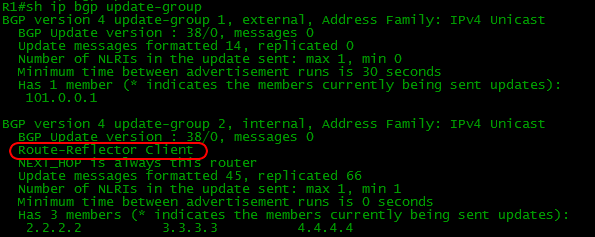
If you look at specific routes:
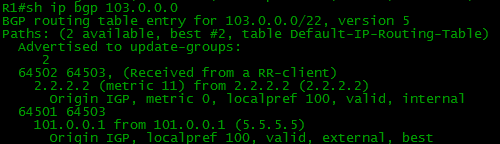
Here you can see the full subnet, the number of paths to it, which one is the best, to which table it is added, to where it is sent (update-group 2 - just our cluster).
The following lists all these paths, containing such important parameters as AS-Path, Next-Hop, Origin, etc., as well as information that, for example, the first route was received from an RR client.
This information can be successfully used for troubleshooting. So, for example, its output looks like when Next-Hop-self is not configured:
 Device configuration
Device configurationReservation issue
What is the problem with the root reflector now? All routers have connections only with it. And if R1 suddenly fails, write it is gone - the network will fall.
For these purposes, let's configure the cluster and select R2 as the second RR.
That is, now on R3 and R4 it is necessary to raise the neighborhoods not only with R1, but also with R2.
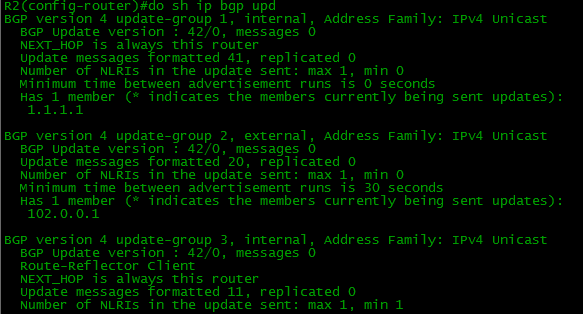
Now sh ip bgp update-group looks like this:

One external, one internal is not an RR client and two internal RR clients.
Similarly on R2:
On clients, we now have two connections with RR:
Notice that there are now two new attributes in the Update messages: Cluster-List and Originator-ID. Based on the name, they carry the RR-cluster number and the sender identifier of the announcement:
R1R2
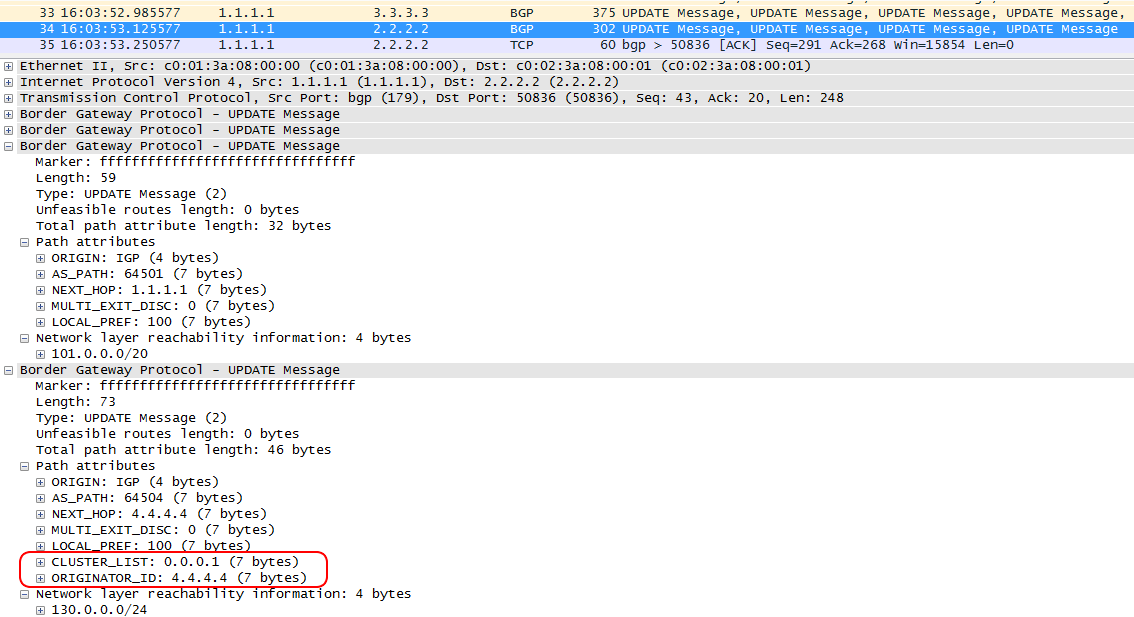
These parameters are added only to routes transmitted by IBGP.
They are necessary in order to avoid the formation of loops. If, for example, a route has passed several clusters and returned to the original one, then in the Cluster-List parameter among all the others, the router will see its cluster number, and then delete the route.

Try to answer the question, why do you need the attribute Originator-ID? Doesn't Cluster-List exhaust all the options?
If even now R1 is burned, the connection will partially only lie at the time of detecting the problem and rebuilding the routing tables (in the worst case, this is 3 minutes of waiting for the BGP keepalive message and some more time to study the new routes).
But, if your network design suggested that RRs are independent pieces of hardware, and traffic did not go through them (that is, they were solely involved in distributing routes), then it is quite likely that there will be no traffic interruption at all.First, the sender will notice only after 3 minutes that something is wrong with the RR - during this time he will have a route anyway, and since he leads not through the ingloriously lost RR, traffic will go quite safely. After these three minutes, the sender will switch to the backup RR and receive a new actual route from it. Thus the connection will not be terminated.
The essence of hierarchical root-reflectors is only that one of them is a client of the other. This helps to build a more understandable and transparent scheme of work, which will be easier to troubleshoot further.
On our network, it is devoid of any meaning, so this case will not be considered.
Confederation
Another way to solve the Full-Mesh problem is to confederations or else they are called sub-AS, sub-AS. In fact, it is a small virtual speaker inside a large real speaker.
Each confederation behaves like an adult AS - inside is a complete connectivity, from the outside, as Leibnitz puts its soul - IBGP works here on the EBGP principle (with some reservations), the border routers of the confederations, behave like EBGP neighbors, must be connected directly.
Example topology:
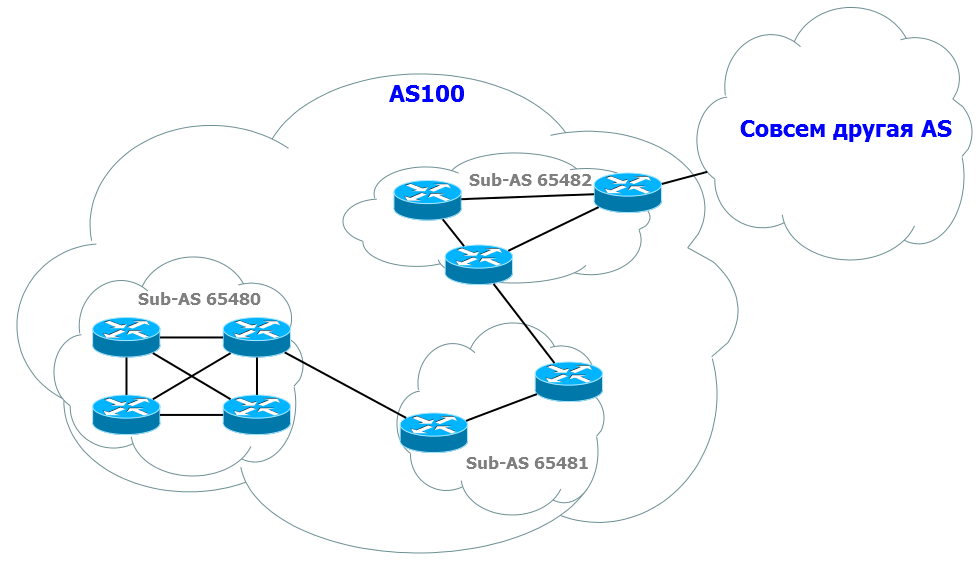
When routes are transmitted within the AU between confederations, a confederation number is added to their AS-Path (AS_CONFED_SEQ and AS_CONFED_SET segments) to avoid loops. As soon as the route leaves AS, all these numbers are deleted so that the outside world does not know about them.
It is quite rare due to its weak scalability and opacity, so we will not consider it.
More details can be read on xgu.ru .
____________________________
BGP Attributes
The final topic we’ll touch on BGP is its attributes. We have already begun to consider them in the main article (AS-Path and Next-Hop, for example). Now we will systematize and expand the existing knowledge.
They are divided into four types:
- Well-known Mandatory (Well-known Mandatory)
- Well-known optional (Well-known Discretionary)
- Optional Transmit / Transitive
- Optional non-transitive (Optional Non-transitive)
Well-known Mandatory (Well-known Mandatory)
These are the attributes that must always be present in announcements , and every BGP router must know them.
The following three attributes and only they belong to this type.
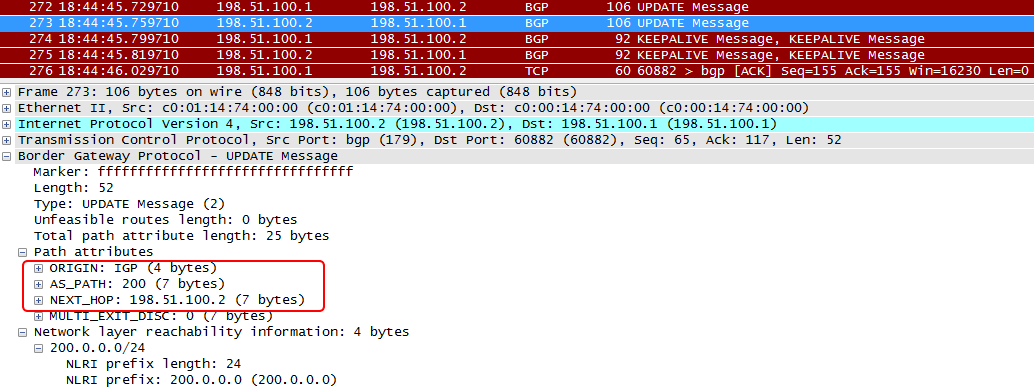
Next-Hop tells the receiving router how to send the packet.
When transmitting a route between different ASs, the value of Next-Hop changes to the address of the sending router. Inside the AS, the Next-Hop attribute does not change by default when transmitting from one IBGP speaker to another. Above, we have already considered why.
AS-pathcarries a list of all Autonomous Systems that must be overcome to achieve the goal. Used to select the best path and to eliminate routing loops. When a route is sent from one AS to another, the number of the sending AS is inserted into the AS-path . When transmitted within an AS, the parameter does not change.
Origin tells how the route originated - with the network command (IGP - value 0) or redistribution (Incomplete - value 2). The value 1 (EGP) is no longer encountered due to the fact that the EGP protocol is not used. It is assigned once by the router-dad that generated the route and nowhere else changes. Essentially means the degree of reliability of the source. IGP - the coolest.
Well-known optional (Well-known Discretionary)
These attributes must be known to all BGP routers, but their presence in the announcement is not required. Do you want to eat, do not want to - do not eat.
Examples:
Local Preference helps you choose one of several routes to one network. This attribute can be transmitted only within one AS. If the announcement with Local Preference comes from an EBGP partner, the attribute is simply ignored - we cannot control the routes of someone else's AS using Local Preference.
Atomic Aggregate says that the prefix was obtained by aggregating smaller ones.
Optional Transmit / Transitive
Attributes that do not necessarily know everything. Who knows - uses, who does not know - passes them on.
Examples:
Aggregator . Indicates the Router ID of the router where the aggregation occurred.
Community . We will talk about this attribute in detail later, in the final part of the article.
Optional non-transitive (Optional Non-transitive)
Attributes that do not necessarily know everything. But the router, which does not support them, discards them and does not transmit anywhere else.
Example:
MED - Multi-exit Descriminator . With this attribute, we can try to manage priorities in an alien AS. We can try, but it is unlikely that something will work out :) Often this attribute is filtered, it matters only if there are at least two links to one AS, it is checked after many very strong attributes (Local Preference, AS-Path), and different vendors can interpret MED in different ways.The previously mentioned Cluster List and Originator-ID . Naturally, they are optional, and of course, there is no sense in transferring them somewhere outside the AS, therefore it is not transferable.===================== Task number 6 * You need to change the standard procedure for choosing the best route on the routers in AS64500:
- R1 and R2 routers should choose eBGP routes, not iBGP, regardless of the AS path length,
- R3 and R4 routers inside the autonomous system should choose routes based on the OSPF metric.
Configuration and scheme: basic .
Details of the problem here .
=====================
Community
Here it is - one of the most interesting aspects of BGP, this is where its flexibility is manifested - the ability, in addition to the routes themselves, to transmit additional information.
Using the Community attribute, you can control the behavior of another AS’s routers from your AS.
For a long time, for some reason I did not understand for myself, I underestimated the power of this tool.
Managing your announcements in a foreign AS with the help of the community is supported by the overwhelming majority of vendors. But in fact, we should not speak here about vendors, but rather about operators / providers - it depends on them, on their configuration, whether you can manage or not.
Let's start with the theory, Community, as mentioned above, is an optional Transmit attribute (4 bytes). It is a record of the form AA: NN, where AA is the two-byte AS number, NN is the community number (for example, 64500: 666).
There are 4 so-called Well-Known community ( well-known ):
Internet - There are no restrictions - it is transmitted to everyone.
No-export - Cannot export route to other AS. At the same time, it is possible to transfer them outside the confederation.
No-export-subconfed (also called Local AS ) - As No-export, only a restriction is added and according to confederations - between them it is no longer transmitted either.
No-advertise- Do not pass this route to anyone - only a neighbor will know about it.
=====================
Problem number 7Our new client AS 64504 is connected to our network. And while not planning to connect to another provider. At this stage, the client can use the autonomous system number from the private range. The address block that the client uses will be part of our range of networks.
Task: Since the client's network is part of our address block, it is necessary that the client's network is not announced to neighboring providers.
Do not use prefix filtering or AS filtering to solve this problem.
Configuration and schema: Community .
The only difference is that the network, which is announced by AS64504: 100.0.1.0/28, and not 130.0.0.0/24
Details of the problem here .
=====================
There are thousands of online configuration examples for such a basic community and very few real-life examples.
Meanwhile, one of the most interesting uses of this attribute is black houlling from Old Slavic black hole - a way to combat DoS attacks. In great detail with an example of customization, it has already been described in Habré.
The bottom line is that when an attack began on one of your AS’s addresses, you transfer this address to a higher-level provider from the 666 community, and it sends such a route to NULL - blackhole him. That is, this parasitic traffic does not reach you already. The provider can transfer such a route further, and so, step by step, the traffic from the attacker or the bots system will be discarded already at the earliest stages, without clogging the Internet.
Such an effect of an expanding black hole is achieved thanks to the community. That is, in the usual case, you announce this address as part of a large network / 22, for example, and in the case of DoS, you pass the most specific route / 32, which will, naturally, take a higher priority.
By the way, you can listen to such attacks in the sixth edition of our podcast linkmeup.
Other examples are the management of the Local Preference attribute in a foreign AS, telling it that the announcement needs to increase the AS-path (AS-path prepending) or not pass the route to any neighbors.
About the latter. How, for example, do you solve the following problem?
There is a network shown in the figure below. You want to give your routes to neighbors from AS 100 and 200 and you do not want 300.
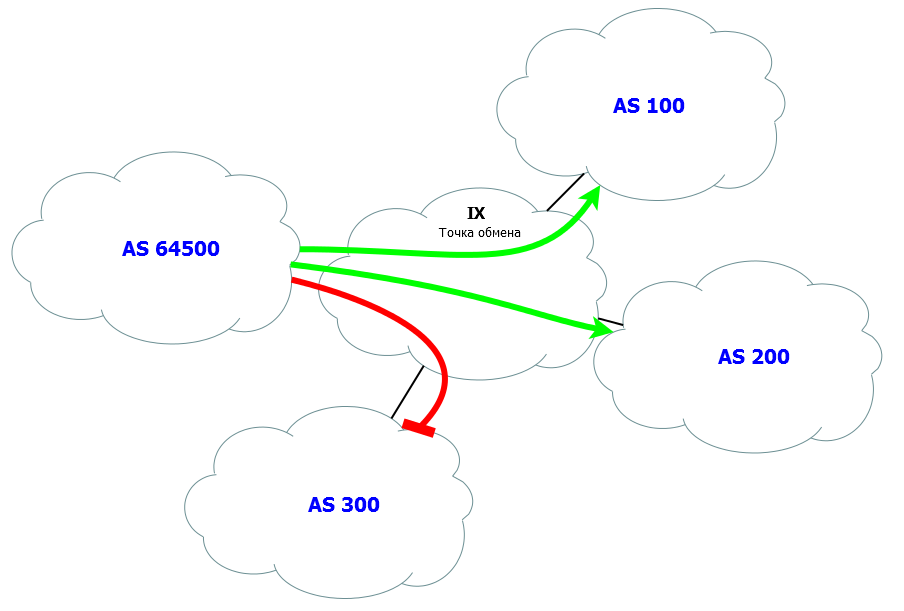
Without the use of the community, it is not possible to do this only with your AS.
By the way, no matter how regrettable it may be, but such restrictions are actually used in our life. There are common situations when several providers establish peering relationships among themselves - the traffic between their networks does not go through the higher providers, does not allow a circle through half of Russia, but does not let someone in - they do not announce their networks to someone.
The most interesting articles about the Internet and BGP and about peering wars .
Community Practice
We consider the following situation as an example.
The main scheme of the article is complemented by another client router and two links.
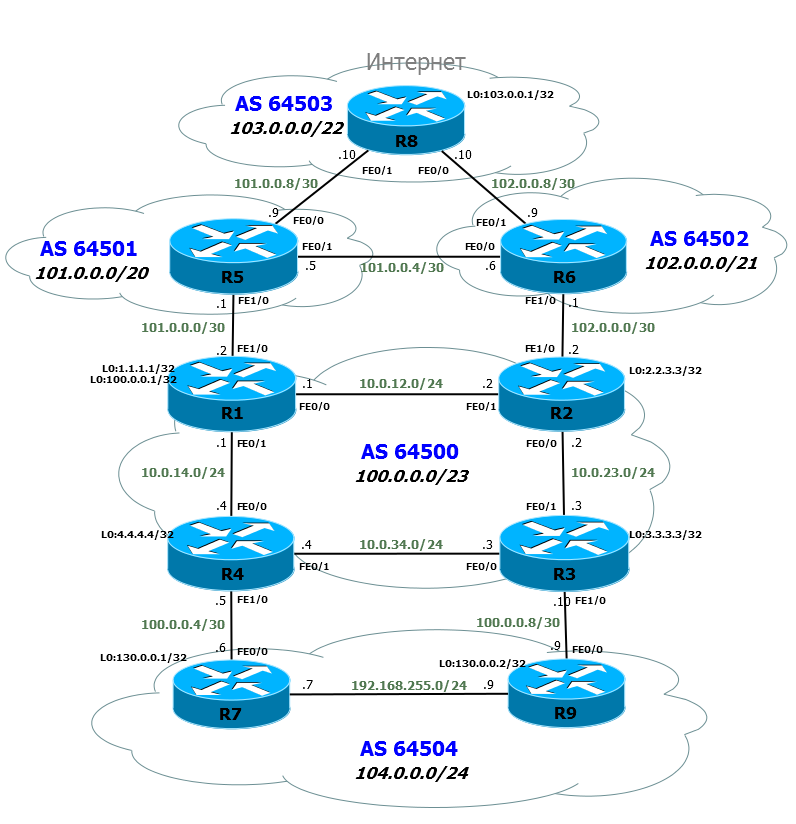
R7 and R9 are separated geographically - the so-called georeserving. The main is its right site, left - reserve.
Inside his AS, he set up transmission of outgoing traffic in the right place - via R3. But with the incoming more difficult - MED does not allow the use of religion, and there is no trust in it.
Therefore, we developed an interaction scheme using the community. In fact, it will be common to all. For example, below we will establish a rule - if you got a route with a community of 64500: 150, increase Local Preference for it to 150. And then we apply this policy to the routes we need.
On our hardware (on everything) we define the ip community-list:
ip community-list 1 permit 64504:150 Set the processing rule:
route-map LP150 permit 10 match community 1 set local-preference 150 This is a common unit that will be the same for all devices. After that, the client can say that he wants to use this function and we apply the card to the BGP neighbor: We apply the card to the BGP
neighbor on R3:
router bgp 64500 neighbor 100.0.0.10 remote-as 64504 neighbor 100.0.0.10 route-map LP150 in So, if in the announcement from the neighbor 100.0.0.10 community coincides with the value in the condition, set the Local Preference for these routes to 150.
Often such policies (route maps) are applied by default on all external neighbors. Clients can only set up the transfer of the desired community and do not even need to ask for something provider - everything will work automatically.
This is our community policy. We inform the client about it, they say, you want to set Local Preference for your route at 150 in our AS, use community 64,500: 150
And now he sets up R9:
router bgp 64504 neighbor 100.0.0.9 remote-as 64500 neighbor 100.0.0.9 route-map LP out neighbor 100.0.0.9 send-community route-map LP permit 10 set community 64500:150 If necessary, he can adjust the same to R7.
After clear ip bgp * soft in the sent announcements, we can see the community:
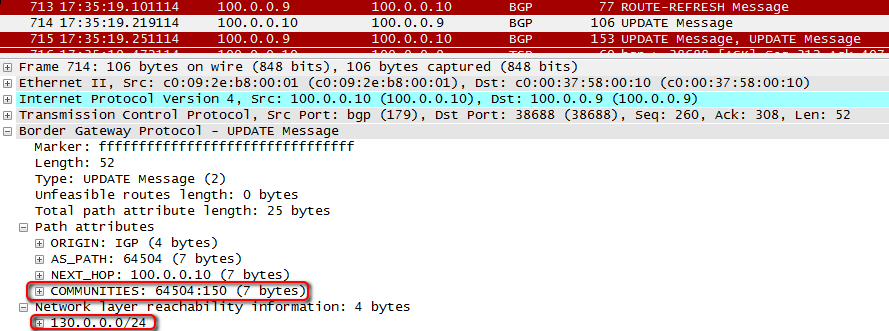
As a result, R3 has a route with a higher Local Preference:
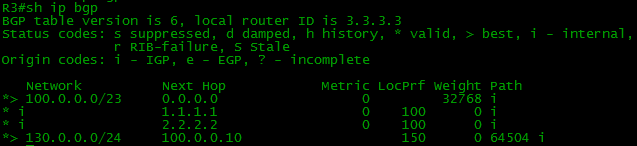
Transmits it to the root-reflector (R1 and R2), which makes a choice and distributes to all its neighbors:

And even R4, to which hand to reach R7, will send traffic to R3:

Traffic goes exactly the way we chose.
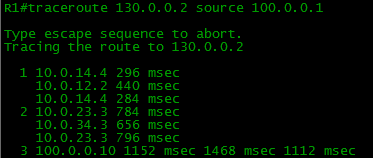
3 — R1R2R3 R1R4R3 . , . , 1- 3- R4, R3. “”? How is it going?
By the way, do not forget the ip bgp-community new-format command , otherwise instead:
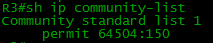
you will see this: The
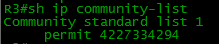
same will be sent, but in the output of the show commands will be displayed in a convenient form.
=====================
Task number 8In our AS, for setting up policies with client AS, they use the community. The following values are used: 64500: 150, 64500: 100, 64500: 50, 64500: 1, 64500: 2, 64500: 3.
In addition, the routers of our AS also use the community to work with neighboring ASs. Their format: 64501: xxx, 64502: xxx.
Task:
- all community values coming from clients that are not defined by the policy should be deleted,
- community values, which are set by clients, must be deleted when prefixes are transmitted to neighboring higher ASs. At the same time other values which are put down by routers of our AS should not be deleted.
Configuration and scheme: basic .
Details of the problem here .
=====================
Device Configuration
In the above example, you can see that the community allows you to work not with separate announcements and apply separate policies for each of them, but consider they are immediately as a group, which naturally makes maintenance much easier.
In other words, a community is a group of announcements with the same characteristics.
When working with the community, it is important to understand that the configuration is necessary from two sides - in order for the desired to work, the provider must also have the appropriate configuration.
Often, providers have an already established policy for using the community, and they simply give you the numbers you need to use. That is, after you add a community number to the announcement, the provider will not have to do anything with his hands - everything will happen automatically.
For example, Balagan Telecom may have such a policy:
| Value | Act |
|---|---|
| 64501: 100X | When announcing a route to neighbor A, add X predends, where X is from 1 to 6 |
| 64501: 101X | When announcing a route to neighbor B, add X predends, where X is from 1 to 6 |
| 64501: 102X | When announcing the route to neighbor C, add X prepend, where X is from 1 to 6 |
| 64501: 103X | AS64503 , 1 6 |
| 64501:20050 | Local Preference 50 |
| 64501:20150 | Local Preference 150 |
| 64501:666 | Next-Hop Null — Black Hole |
| 64501:3333 | BGP AS |
Based on this label, which is published on the site of Balagan Telecom, we can make a decision about traffic management.
How can this really help us?
We have Dual-homing connection to two different providers - Balagan Telecom and Filkin Certificate. The data center also has connections to both providers. It belongs to some kind of content generator, say this is a sweat video operator.
By default, everything goes to our network through Balagan Telecom (AS64501). Although the channel is wide there, its utilization is already quite high. We want to sell IPTV service to home customers and expect a significant increase in incoming traffic. It would be nice to wrap it in Filkin Certificate and not be afraid that the main channel will be clogged. At the same time, of course, you do not need to transfer all other traffic.
In the BGP table, we check where the network is 103.0.0.0. We see that this is AS64503, which is reachable through both providers with an equal number of AS in the AS-Path.
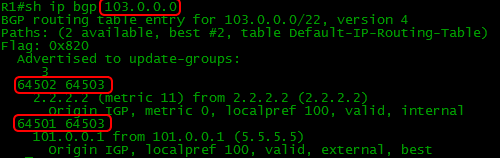
This is how the router sees us from AS 64503:
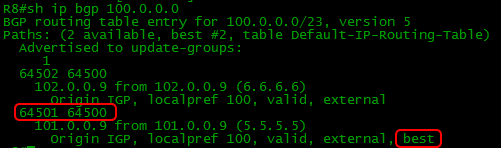
The route to Balagan-Telecom is preferred.
What are your thoughts?
Announce certain networks in Filkin Certificate, and leave the rest in Balagan Telecom? Inflexible, unscalable.
Hang up on the routes given to Balagan Telecom? Then, most likely, a bunch of other traffic will flow to the Filkin Certificate.
Ask the engineer Balagan-Telecom to manually extend our routes by transferring them to AS64503. Already closer to the truth, and it will even work, but, most likely, the provider engineer will send you ... to the site with a sign, where their Community policy is written.
Actually, all we need to do is to use the route-map on the R1 router to add the 64500: 1031 community to the R5 neighbor (recall that 103X is for the neighbor from AS 64503). Then everything will do automatic.
Here’s how the R5 sees the route itself:
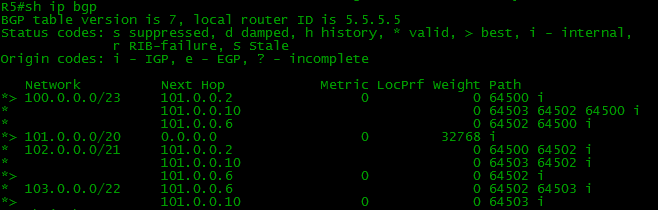
All without changes.
Here’s how the R8 sees it:
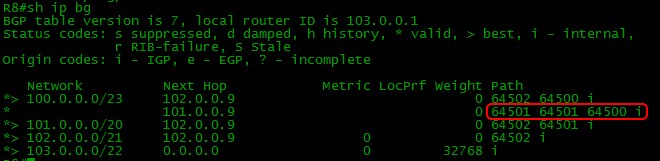
As you can see, the check mark stands in front of a shorter way through the Filkin Certificate, which we achieved.
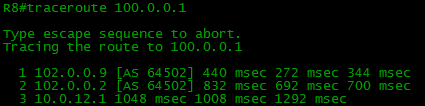
=====================
Problem number 9One of our clients was a large company. They pay us quite a lot, but there is a problem with the fact that when some problems occur with the AS64501 provider, the quality of the connection provided by the link with the AS64502 provider does not suit the client. The main thing for our client, good quality of communication to the branches.
Since the client is solid, we had to install peering with another provider AS64513. But it costs us dearly so we will use it only when the provider AS64501 is not available and only for this important client.
Task:
It is necessary to configure the network so that the client network 150.0.0.0/24 is announced through the AS64513 provider only if the network 103.0.0.0/22 is not available through the AS64501 provider (it is used to verify the provider’s operation). In addition, from the provider AS64513, we need to accept only the networks of the client’s branches (50.1.1.0/24, 50.1.2.0/24, 50.1.3.0/24) and use them only if they are not available through the provider AS64501. The rest of the client traffic will go through AS64502.
Configuration: basic .
Details of the problem here .
=====================
Release materials
A Tale of the Present Internet
BGP Blackhole - an effective means of dealing with DDoS
Comparison of functions and uses of EBGP and IBGP
BGP Basics
Device Configuration: basic IBGP , Route Reflectors , Community .
Afterword
Here on this familiarity with BGP can be considered complete. Now we come back to it as much as possible when considering MPLS L3VPN.
Material prepared for you eucariot .
For troubleshooting articles thanks to JDIMA. The
puzzles are provided by Natasha - the author of the best wikisite on network protocols and technologies - xgu.ru.
As usual, a moment of self-promotion: you can find all articles of the cycle on our website linkmeup.ru . In the same place all releases of the first podcast for linkmeup operators.
Source: https://habr.com/ru/post/197516/
All Articles