UNPIVOT
During my work, I came across a wide range of tasks. Some tasks required monotonous work, others came down to pure creativity.
The most interesting tasks that I can now recall, one way or another, raised questions of query optimization.
Optimization is, first of all, the search for the optimal query plan. However, what to do in a situation when a standard language construct produces a plan that is very far from optimal?
')
I encountered this kind of problem when I used the UNPIVOT construct to convert columns to rows.
Through a small comparative analysis, a more effective alternative was found for UNPIVOT .
So that the task does not seem abstract, suppose that we have at our disposal a table containing information about the number of medals among users.
Taking this table as a basis, we present various methods for converting columns to rows, as well as plans for their implementation.
At one time, SQL Server 2000 did not provide an efficient way to convert columns to rows. As a result, the practice of multiple sampling from the same table, but with a different set of columns united through the UNION ALL construction, was widely practiced:
A huge disadvantage of this approach is the repeated readings of data, which significantly reduced the efficiency in performing such a query.
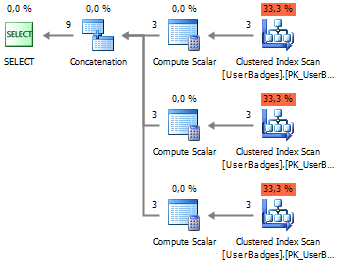
If you look at the execution plan, you can easily see this:
With the release of SQL Server 2005 , it became possible to use the new design of the T-SQL language - UNPIVOT .
Using UNPIVOT, the previous request can be simplified to:
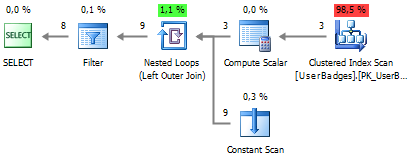
Upon execution, we will get the following plan:
Beginning with SQL Server 2008, it became possible to use the VALUES construct not only for creating multi-line INSERT queries, but also inside the FROM block.
Using the VALUES construct, the query above can be rewritten as:
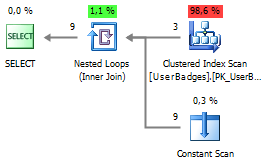
At the same time, in comparison with UNPIVOT , the implementation plan is slightly simpler:
Using dynamic SQL, it is possible to create a "universal" query for any table. The main condition for this is that the columns that are not part of the primary key must have compatible data types.
You can find the list of such columns by the following query:
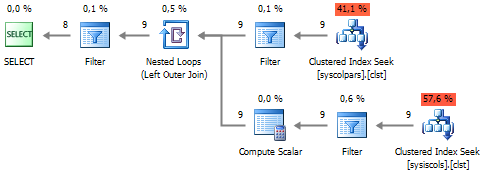
If you look at the query plan, you will notice that connecting to sys.index_columns is quite expensive:
To get rid of this connection, you can use the INDEX_COL function. As a result, the final version of the request will take the following form:
When executed, a request will be generated in accordance with the template:
Even if we take into account the optimization that we have done, it is worth noting that this method is still slower compared to the previous two:
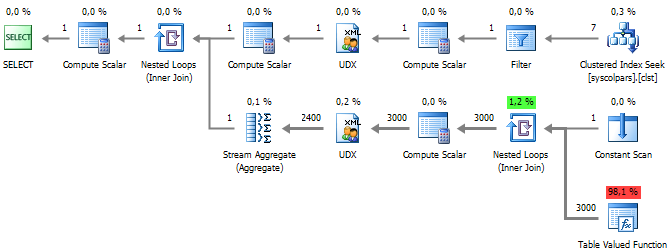
It is more elegant to implement dynamic UNPIVOT by using the following trick with XML :
In which for each line an XML of the form is formed:
Then the name of each attribute and its value is parsed.
In most cases, using XML results in a slower execution plan - this is a payback for universality.

Now compare the results:

There is no dramatic difference in execution speed between UNPIVOT and VALUES . This statement is true when it comes to simply converting columns to rows.
Let's complicate the task and consider another option, where for each user you need to find out the type of medals, which he has the most.
Let's try to solve the problem using the UNPIVOT construction:
The execution plan shows that the problem is observed in re-reading the data and sorting, which is necessary to organize the data:
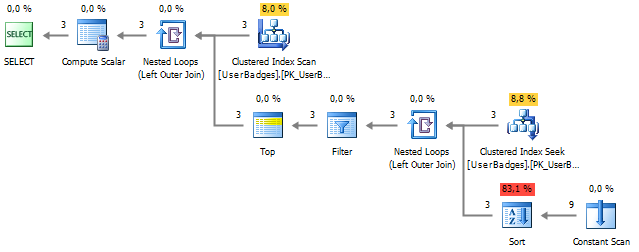
Getting rid of re-reading is easy enough if we recall that it is allowed to use columns from the outer block in the subquery:
Repeated readings are gone, but the sorting operation has not gone away:
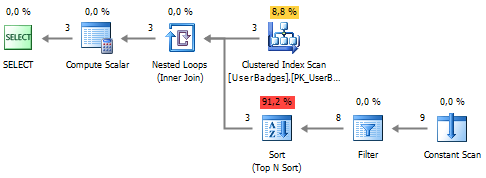
Let's see how the VALUES construction behaves in this task:
The plan is expectedly simplified, but the sorting is still present in the plan:
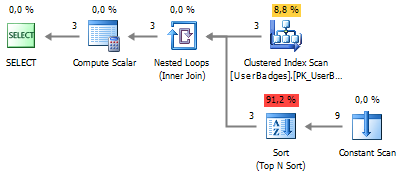
Let's try to bypass the sorting using the aggregate function:
We got rid of sorting:
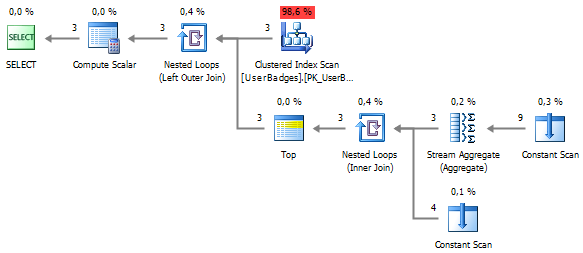
Small results:
In a situation where it is necessary to make a simple conversion of columns into rows, it is most preferable to use the constructions UNPIVOT or VALUES .
If, after conversion, the obtained data is planned to be used in aggregation or sorting operations, then it is more preferable to use the VALUES construct, which, in most cases, allows to obtain more efficient execution plans.
If the number of columns in a table is variable, it is recommended to use XML , which, unlike dynamic SQL, can be used inside table functions.
PS To adapt, part of the examples for the features of SQL Server 2005 , the construction using VALUES :
It is necessary to replace the combination SELECT UNION ALL SELECT :
UPDATE 10/16/2013 : How do UNPIVOT and VALUES behave on large amounts of data?
The table is based on the following structure (25 columns in total).
This table contains ~ 186000 rows. From a cold start on a local SQL Server 2012 SP1 , the operation to convert rows to columns gave the following results.
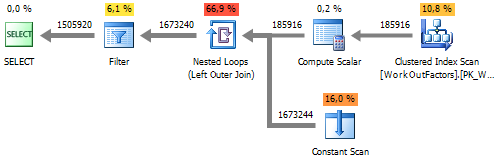
UNPIVOT execution plan :
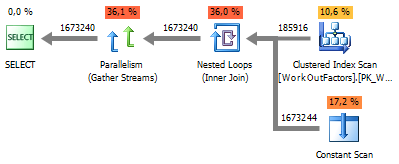
VALUES execution plan:
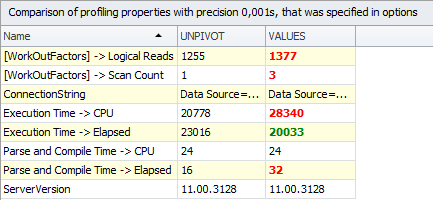
In comparison, you can see that VALUES runs faster (by 3 seconds), but it requires a lot of CPU resources:
From myself I will add that in each specific situation the difference in performance will differ.
The most interesting tasks that I can now recall, one way or another, raised questions of query optimization.
Optimization is, first of all, the search for the optimal query plan. However, what to do in a situation when a standard language construct produces a plan that is very far from optimal?
')
I encountered this kind of problem when I used the UNPIVOT construct to convert columns to rows.
Through a small comparative analysis, a more effective alternative was found for UNPIVOT .
So that the task does not seem abstract, suppose that we have at our disposal a table containing information about the number of medals among users.
IF OBJECT_ID('dbo.UserBadges', 'U') IS NOT NULL DROP TABLE dbo.UserBadges GO CREATE TABLE dbo.UserBadges ( UserID INT , Gold SMALLINT NOT NULL , Silver SMALLINT NOT NULL , Bronze SMALLINT NOT NULL , CONSTRAINT PK_UserBadges PRIMARY KEY (UserID) ) INSERT INTO dbo.UserBadges (UserID, Gold, Silver, Bronze) VALUES (1, 5, 3, 1), (2, 0, 8, 1), (3, 2, 4, 11) Taking this table as a basis, we present various methods for converting columns to rows, as well as plans for their implementation.
1. UNION ALL
At one time, SQL Server 2000 did not provide an efficient way to convert columns to rows. As a result, the practice of multiple sampling from the same table, but with a different set of columns united through the UNION ALL construction, was widely practiced:
SELECT UserID, BadgeCount = Gold, BadgeType = 'Gold' FROM dbo.UserBadges UNION ALL SELECT UserID, Silver, 'Silver' FROM dbo.UserBadges UNION ALL SELECT UserID, Bronze, 'Bronze' FROM dbo.UserBadges A huge disadvantage of this approach is the repeated readings of data, which significantly reduced the efficiency in performing such a query.
If you look at the execution plan, you can easily see this:
2. UNPIVOT
With the release of SQL Server 2005 , it became possible to use the new design of the T-SQL language - UNPIVOT .
Using UNPIVOT, the previous request can be simplified to:
SELECT UserID, BadgeCount, BadgeType FROM dbo.UserBadges UNPIVOT ( BadgeCount FOR BadgeType IN (Gold, Silver, Bronze) ) unpvt Upon execution, we will get the following plan:
3. VALUES
Beginning with SQL Server 2008, it became possible to use the VALUES construct not only for creating multi-line INSERT queries, but also inside the FROM block.
Using the VALUES construct, the query above can be rewritten as:
SELECT p.UserID, t.* FROM dbo.UserBadges p CROSS APPLY ( VALUES (Gold, 'Gold') , (Silver, 'Silver') , (Bronze, 'Bronze') ) t(BadgeCount, BadgeType) At the same time, in comparison with UNPIVOT , the implementation plan is slightly simpler:
4. Dynamic SQL
Using dynamic SQL, it is possible to create a "universal" query for any table. The main condition for this is that the columns that are not part of the primary key must have compatible data types.
You can find the list of such columns by the following query:
SELECT c.name FROM sys.columns c WITH(NOLOCK) LEFT JOIN ( SELECT i.[object_id], i.column_id FROM sys.index_columns i WITH(NOLOCK) WHERE i.index_id = 1 ) i ON c.[object_id] = i.[object_id] AND c.column_id = i.column_id WHERE c.[object_id] = OBJECT_ID('dbo.UserBadges', 'U') AND i.[object_id] IS NULL If you look at the query plan, you will notice that connecting to sys.index_columns is quite expensive:
To get rid of this connection, you can use the INDEX_COL function. As a result, the final version of the request will take the following form:
DECLARE @table_name SYSNAME SELECT @table_name = 'dbo.UserBadges' DECLARE @SQL NVARCHAR(MAX) SELECT @SQL = ' SELECT * FROM ' + @table_name + ' UNPIVOT ( value FOR code IN ( ' + STUFF(( SELECT ', [' + c.name + ']' FROM sys.columns c WITH(NOLOCK) WHERE c.[object_id] = OBJECT_ID(@table_name) AND INDEX_COL(@table_name, 1, c.column_id) IS NULL FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, '') + ' ) ) unpiv' PRINT @SQL EXEC sys.sp_executesql @SQL When executed, a request will be generated in accordance with the template:
SELECT * FROM <table_name> UNPIVOT ( value FOR code IN (<unpivot_column>) ) unpiv Even if we take into account the optimization that we have done, it is worth noting that this method is still slower compared to the previous two:
5. XML
It is more elegant to implement dynamic UNPIVOT by using the following trick with XML :
SELECT p.UserID , BadgeCount = tcvalue('.', 'INT') , BadgeType = tcvalue('local-name(.)', 'VARCHAR(10)') FROM ( SELECT UserID , [XML] = ( SELECT Gold, Silver, Bronze FOR XML RAW('t'), TYPE ) FROM dbo.UserBadges ) p CROSS APPLY p.[XML].nodes('t/@*') t(c) In which for each line an XML of the form is formed:
<t Column1="Value1" Column2="Value2" Column3="Value3" ... /> Then the name of each attribute and its value is parsed.
In most cases, using XML results in a slower execution plan - this is a payback for universality.
Now compare the results:
There is no dramatic difference in execution speed between UNPIVOT and VALUES . This statement is true when it comes to simply converting columns to rows.
Let's complicate the task and consider another option, where for each user you need to find out the type of medals, which he has the most.
Let's try to solve the problem using the UNPIVOT construction:
SELECT UserID , GameType = ( SELECT TOP 1 BadgeType FROM dbo.UserBadges b2 UNPIVOT ( BadgeCount FOR BadgeType IN (Gold, Silver, Bronze) ) unpvt WHERE UserID = b.UserID ORDER BY BadgeCount DESC ) FROM dbo.UserBadges b The execution plan shows that the problem is observed in re-reading the data and sorting, which is necessary to organize the data:
Getting rid of re-reading is easy enough if we recall that it is allowed to use columns from the outer block in the subquery:
SELECT UserID , GameType = ( SELECT TOP 1 BadgeType FROM (SELECT t = 1) t UNPIVOT ( BadgeCount FOR BadgeType IN (Gold, Silver, Bronze) ) unpvt ORDER BY BadgeCount DESC ) FROM dbo.UserBadges Repeated readings are gone, but the sorting operation has not gone away:
Let's see how the VALUES construction behaves in this task:
SELECT UserID , GameType = ( SELECT TOP 1 BadgeType FROM ( VALUES (Gold, 'Gold') , (Silver, 'Silver') , (Bronze, 'Bronze') ) t (BadgeCount, BadgeType) ORDER BY BadgeCount DESC ) FROM dbo.UserBadges The plan is expectedly simplified, but the sorting is still present in the plan:
Let's try to bypass the sorting using the aggregate function:
SELECT UserID , BadgeType = ( SELECT TOP 1 BadgeType FROM ( VALUES (Gold, 'Gold') , (Silver, 'Silver') , (Bronze, 'Bronze') ) t (BadgeCount, BadgeType) WHERE BadgeCount = ( SELECT MAX(Value) FROM ( VALUES (Gold), (Silver), (Bronze) ) t(Value) ) ) FROM dbo.UserBadges We got rid of sorting:
Small results:
In a situation where it is necessary to make a simple conversion of columns into rows, it is most preferable to use the constructions UNPIVOT or VALUES .
If, after conversion, the obtained data is planned to be used in aggregation or sorting operations, then it is more preferable to use the VALUES construct, which, in most cases, allows to obtain more efficient execution plans.
If the number of columns in a table is variable, it is recommended to use XML , which, unlike dynamic SQL, can be used inside table functions.
PS To adapt, part of the examples for the features of SQL Server 2005 , the construction using VALUES :
SELECT * FROM ( VALUES (1, 'a'), (2, 'b') ) t(id, value) It is necessary to replace the combination SELECT UNION ALL SELECT :
SELECT id = 1, value = 'a' UNION ALL SELECT 2, 'b' UPDATE 10/16/2013 : How do UNPIVOT and VALUES behave on large amounts of data?
The table is based on the following structure (25 columns in total).
CREATE TABLE [dbo].[WorkOutFactors] ( WorkOutID BIGINT NOT NULL PRIMARY KEY, NightHours INT NOT NULL, EveningHours INT NOT NULL, HolidayHours INT NOT NULL, ... ) This table contains ~ 186000 rows. From a cold start on a local SQL Server 2012 SP1 , the operation to convert rows to columns gave the following results.
UNPIVOT execution plan :
VALUES execution plan:
In comparison, you can see that VALUES runs faster (by 3 seconds), but it requires a lot of CPU resources:
From myself I will add that in each specific situation the difference in performance will differ.
Source: https://habr.com/ru/post/197476/
All Articles