Digging into the data as a degree of freedom
Greetings dear readers.
This material will shed light on the problem of the convenience of working with RDBMS, to which I have devoted many years, but did not find the time to tell.
If you do not search, view and analyze data or do it, but are completely comfortable and do not have anything to do, feel free to stop reading this text.
So, you are a user who has the right to read in a certain DBMS. Probably, you are faced with a set of typical subtasks:
')
Finally, it is very likely that these tasks you need to solve regularly.
There are a huge amount of tools devoted to building queries, cubes and reports on the data processing tools market. Regrettably, but most of them do not see that the user has the above tasks in their entirety. Here are the typical problems, in reverse order from the previous list:
All this in the absence of documentation on the structure. Although it is out of the tool, the problem concerns the tools directly.
If you don’t understand the reality of the problems listed above, then I hope that you will understand this after learning how I try to solve them. If, in your opinion, these problems are contrived, then it will be easier for us if you do not read further.
A comprehensive solution to the problems identified in the Freedom of Sampling program is conducted in several directions simultaneously. The text of this section describes in detail the applied concepts and implementation nuances.
Only the simplest database contains entities in which it is impossible to get lost. In a well-developed application area, tables and fields are measured in tens and hundreds, respectively, and if we talk about repositories, these are hundreds and thousands. In addition, a developer or analyst often has several connections (test, production, archive) for each subject area, which, as a rule, are also quite a lot.
Distinguishing the necessary from the completely unnecessary is one of the first tasks solved by our tool.
Within the selected “engine” of access, you can create and remember connections, which, incidentally, is standard.
In the full list of tables you can find the fields of interest by substring, for example:

An entity / table context is a concept that is close to Business Objects universes, but broader. It is natural to proceed from the assumption that the user is not interested in tables that are not related to the selected one. At the same time, it would be a mistake to think that only directly related tables are included in the context - therefore in the context we can see the nesting of any level:
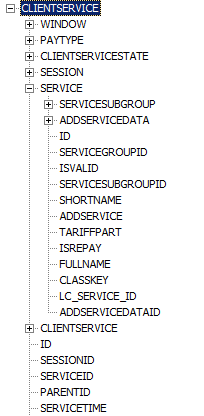
Nodes are entities, leaves are fields. Associated entities are shown next to the fields of the entity with which they have a connection. Multiple links to the same entity are distinguished by the fields through which the link is indicated:

By default, only entities referenced by the fields are shown, but you can also see connections from the other side.

This operation is performed either one-time, individually for each table, or the mode for all tables is turned on automatically.
You are lucky if the system architect has provided all the foreign keys and registered them in the scheme, then the connections will be determined automatically and you will almost not need to take care of this. I love watching such databases; The examples in the screenshots above are made in one of them - thanks to my teachers on one of the projects.
You are not lucky, not only if the architect has not provided for this, but also if the sub-driver of the access components does not support the receipt of this information. In ADO and ODBC, this is often the case, but these engines are not the only ones our tool can work with.
Suppose, for some reason, we are still faced with the fact that the data on the connections cannot be taken from the scheme. But they are so convenient to use each time.
We can define them on our own. There are several ways to do this.
The simplest is a one-time bundle of one field, through the context menu and the dialog (in some cases this can be done via drag'n'drop fields on each other):
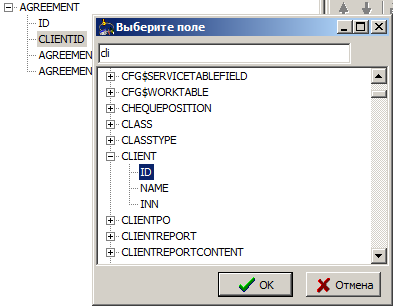
More complex is a bunch of several fields:

Finally, aerobatics is a multiple typical connection of all necessary tables:
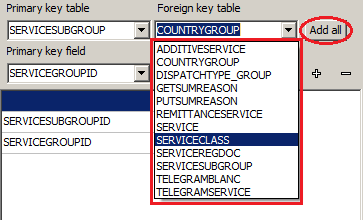
I had to perform the last task by analyzing the schema of one popular Open Source portal, where there are several dozen obvious links to each of the reference tables, in which, in turn, the number of links reaches the same order of magnitude.
All these links will be stored in the local "scheme" that exists as an addition to the automatically recognized links through the driver to the database, and henceforth will be determined by contexts along with them.
For individual special cases, there are separate goodies that make the context more flexible. We will not dwell in detail, just a snapshot of the context menu:
The definition and display of the context of the entity with which the user works is not only done so that he can focus on choosing the data he needs, nested in the links. The user does not think about linking them, because the query builder takes into account binding fields and the nature of the link is transparent to the user.
We have taken the first step for convenient work - we have separated the important from the secondary. Now our task is to simplify the selection of the essential from the available.
Our task is to open the context to the desired depth and select the required fields. Tables are only a way to navigate to them, their indication is not required at all. Typical operations with fields in the query - adding to the selection, adding to the filter and adding to the expression (in the selection or filter).
The figure highlights three buttons-icons of typical actions and shows the result of one of them (adding to the filter) using the example of the Name field of the ServiceSubGroup table referenced by the Service table:
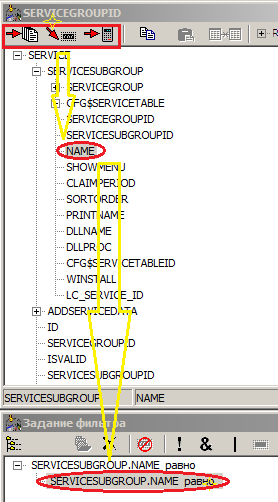
When you select a table in the tool, you can automatically add all fields to the selection. However, we do not need extra garbage in the results, so we want to get rid of some fields (in the figure, the same Service table is shown):
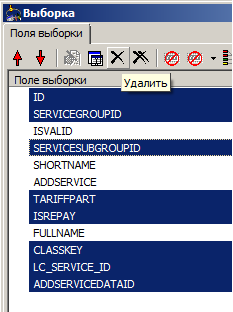
... And add a field from the depth of the context (done via drag'n'drop):

... find the maximum value of the field in groups and the number of lines:
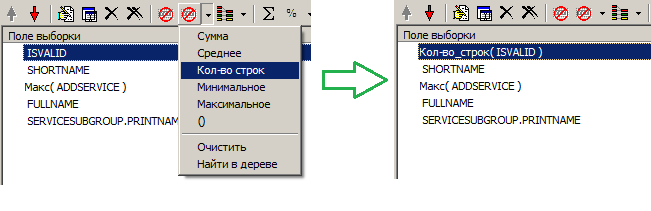
... then regroup the fields:

... make a request (filter definition is omitted, about it later):
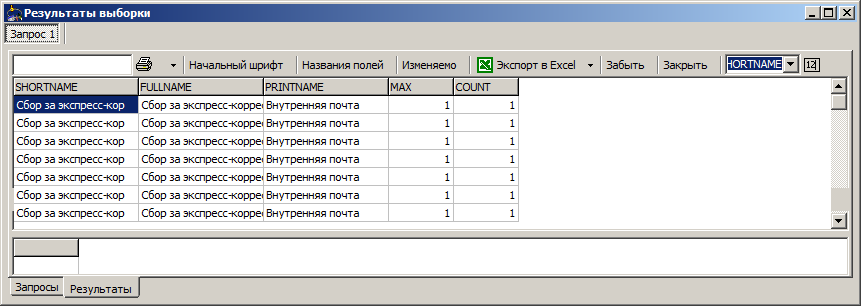
... temporarily remove one field from the selection and ungroup another:
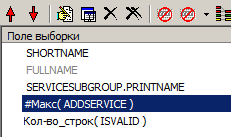
... make a new query and see a more interesting result:

All this and much more now we can do with a minimum of clicks.
The most important feature of the Freedom of Sampling tool is that database objects are treated in a holistic manner everywhere: shown, added, deleted, hidden, and so on. It allows the user to relax, operating with them, and not to lose the tool and not
spoil them in dialogue with the user.
The object model clearly controls the need and sufficiency of connections, takes into account the fields that need to be grouped by request. For example:
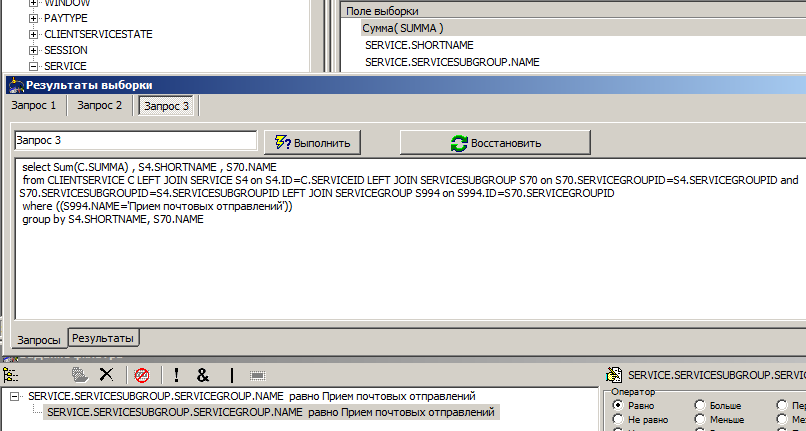
We make a grouping request for the sum of all services in the group, divided by subgroup and service name, in the middle of the figure the generated request is shown.
Then we want to group only by subgroup, for this we “hide” the name of the service:
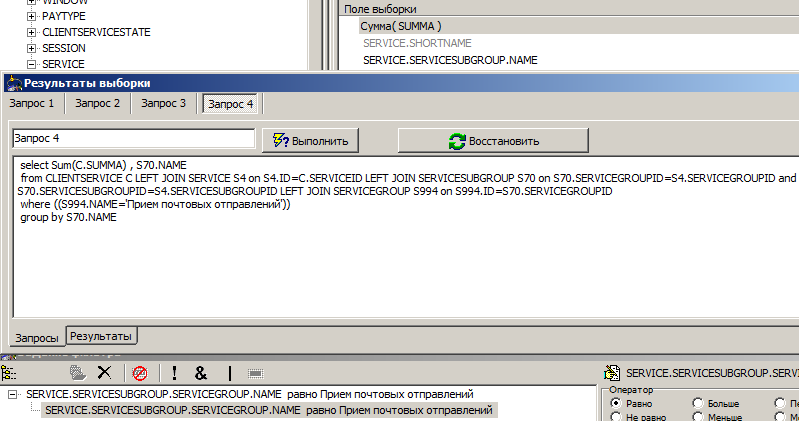
In the request, the Shortname disappeared from both parts (select, group by).
Finally, remove the selection condition (again, temporarily):
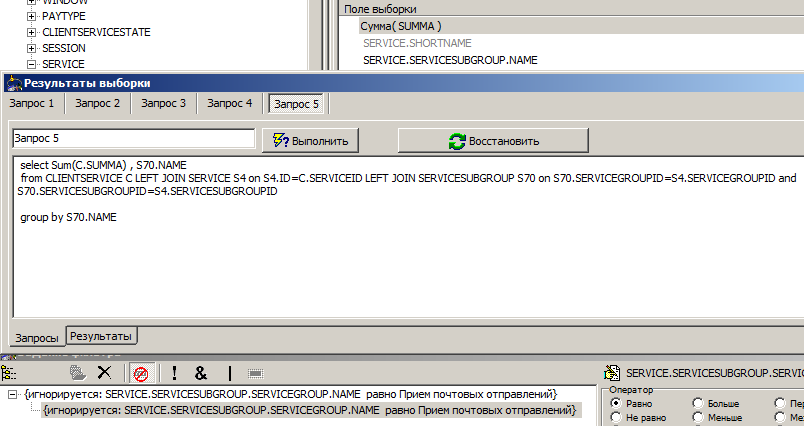
The request not only completely disappeared the where section, but also became one join less, since we no longer need the fields of the ServiceGroup table.
Naturally, in the same few clicks you can return the request to the opposite state.
The use of fields and connections alone is sufficient only up to a certain limit. Sooner or later it is necessary to calculate from them new values that are not presented in the database directly. How to combine the conveniences already known to us and the manual creation, and even more so the change of designs?
The output is quite simple: you must continue to use the fields as objects, and the rest of the richest syntax (except for standard aggregate functions) to give all the various DBMS to the user. That is, everything that is not a field, he will write with the text, plus there is an opportunity to refer or not to refer to the fields in the "correct style".
The expression editor is designed so that you can insert a link to any available field in the expression text anywhere or delete any of the previously mentioned links:
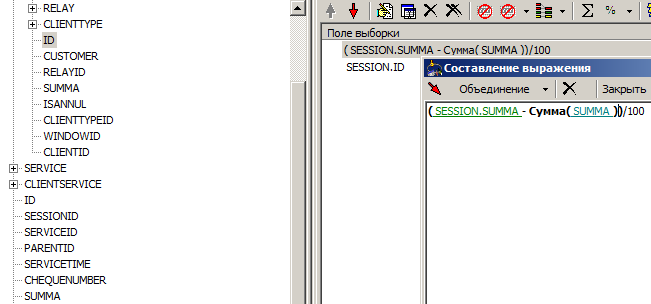
In the figure you can see that we have made the difference between the sum of the session and the sum of the sum of operations (in the hope that it will give 0, as it should) and divided it all into 100 (the sums were initially in kopecks). In this expression, there are six objects that can be controlled and are distinguished by a tool: an opening bracket, two fields, an aggregate function, and two closing brackets. The brackets are moved to managed objects to simplify the control of their pairing (when you remove the bracket, on the one hand, the bracket / function on the other is automatically removed) and the possibility of checking the occurrence of the field in the aggregate expression. All other characters: - , / , 1 , 0 , 0 will be transferred to the server "as is" and for the tool they do not mean anything.
This may not seem very convenient - to switch between creating links and writing the rest of the expression. However, even if we only compare the speed of typing the average number of characters in a field, we already get the gain. Let's add here the possible depth of context. And as a payment for the convenience of manipulation, considered both earlier and later in this text, this difference can not be considered at all.
Any field specified in the selection or filter is already ready to be changed, for example:

It is clear that in the presence of excellent means for manipulating the sample, working with limiters should be no less simple. Consider what opportunities we have at our disposal.
The filter panel initially contains an empty container for them:

There are several ways to add a filter to a container:
As a result, we get something like (filters are only sketched, but all are non-predefined):

You can add filters by selecting any of them and then specify its type and value:
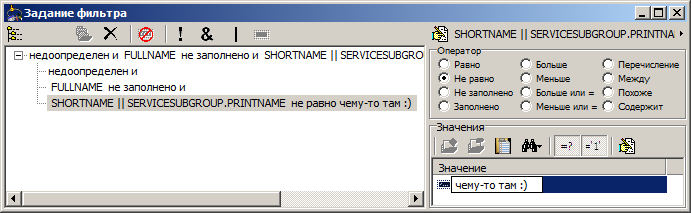
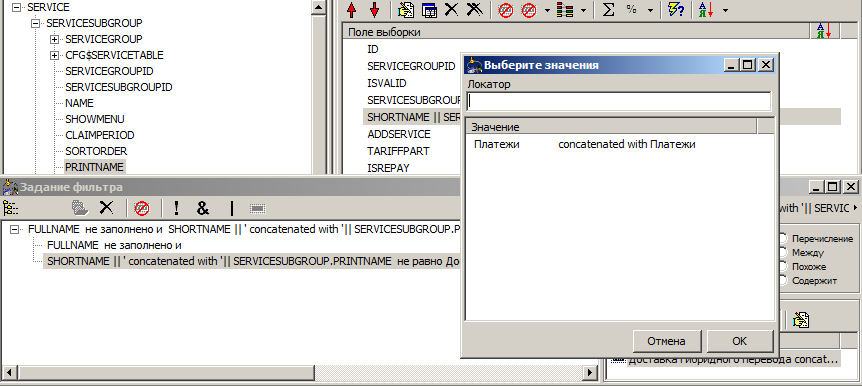
Regardless of the complexity of the expression on the left, we have the opportunity to quickly understand the set of possible values that we are going to filter. Let's make our expression a bit more catchy, and see what the “directory” offers to us:
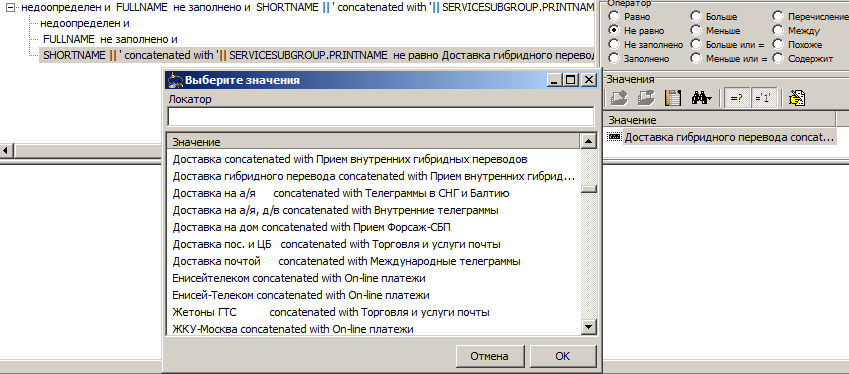
The handbook diligently gave us all the combinations for this expression.
However, this was the simplest case, since all combinations of the fields of the tables to which they belong were selected. Often there are too many of them, and there is no guarantee that they will be in the sample at all. For such cases, there are two additional selection modes:
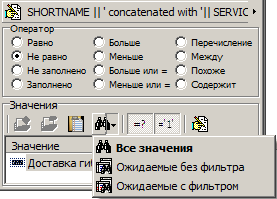
They are arranged by increasing request duration.
“Expected without filter” means that only those values that are referenced from the tables of selected fields will be selected.
"Expected with the filter" take into account the superimposed filters, thereby further narrowing the options. Naturally, the current filter is discarded.
After removing the empty filter from the previous example, and setting the “Expected with filter” selection, we will see the following result:
We could take away the values long and painfully, each time getting an empty sample, since the filter for this expression is either redundant or "incompatible with life."
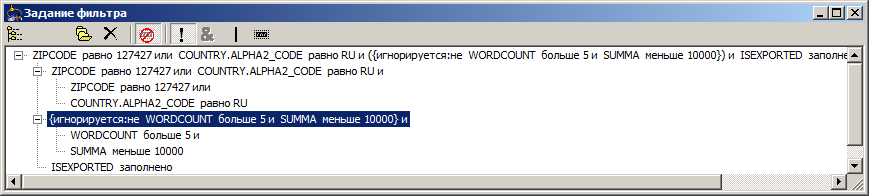
We have so far considered the simplest set of several simple filters. However, the panel allows you to group them into any combination, to perform over them the operations of association on the basis of "and", "or", to deny. This is done using the drag'n'drop gesture and toolbar buttons. Each filter can be disabled, even the root. You can, say, create such a composition:
What was once done does not want to be repeated again, at least if we are talking about labor. Let us enumerate, what results can be relied upon, having once produced them.
One of the foundations of the tool's convenience is table contexts. If you had to work on them manually, then they are saved to a file, which, among other things, can be edited manually or carried with them to another workplace. However, everyone is better if this information is spelled out by the architect.
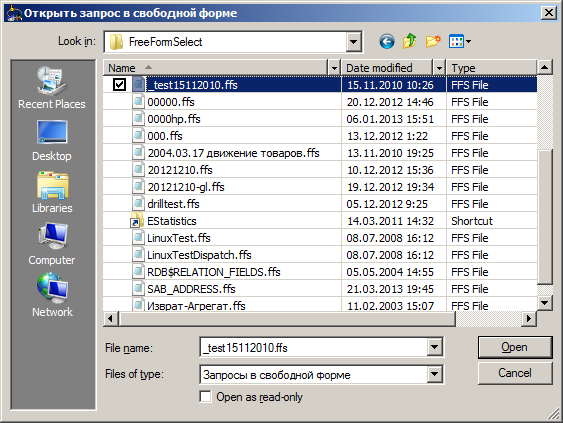
The created request can be saved and transferred as a full-fledged “document”: when opened at another time or in another place, it will be restored in all trifles. The only natural limitation is that the connection to the database must be accessible and its structure must match up to the fields used. The transfer of context settings is not required, copies of the necessary links are written in the document.
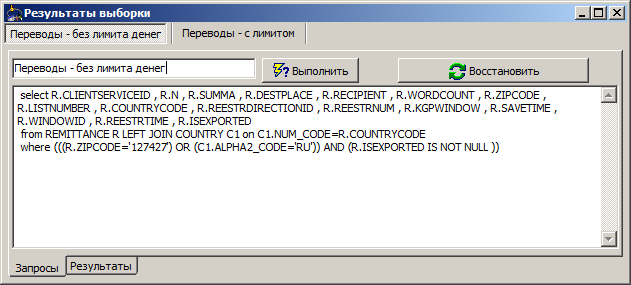
As soon as you have completed the request, it is added to the list of previously executed. This is done so that you can compare the results between iterations of the refinement of fields, conditions, groupings and other things. In addition to the data set, the query structure is saved (as a document) - it can be restored, and the original SQL query (it could be changed manually).
Finally, the entire request history is saved in case of a program crash, after restarting, it is completely restored.
There are many little things in the tool that were not mentioned here, since they are not distinctive features. In addition, many of these little things may have died or died out due to infrequent use, or by-products of refactoring.
While the tool is little known, it contains only what the developer is facing. If there is interest and demand, much can be repaired and completed.
Initially, the tool developed as a desktop, but recently, as an experiment, a simplified web interface to it was implemented. The desktop interface itself is rather outdated.
Your reaction, dear readers, I hope, and will determine whether the instrument is worth living a dynamic life, or is it just an illustration
another dead end branch of development. Thanks for attention!
This material will shed light on the problem of the convenience of working with RDBMS, to which I have devoted many years, but did not find the time to tell.
If you do not search, view and analyze data or do it, but are completely comfortable and do not have anything to do, feel free to stop reading this text.
Problematics
So, you are a user who has the right to read in a certain DBMS. Probably, you are faced with a set of typical subtasks:
')
- Understand the data structure
- Find the right entities in it.
- Find the fields in them
- Find relationships between entities
- Find values of interest
- Select a set of values
- Select the desired data
- Make sure that this is really the MOST data you were looking for.
- Save results
- Prepare reports from them
Finally, it is very likely that these tasks you need to solve regularly.
There are a huge amount of tools devoted to building queries, cubes and reports on the data processing tools market. Regrettably, but most of them do not see that the user has the above tasks in their entirety. Here are the typical problems, in reverse order from the previous list:
- Rarely where you will find the opportunity to fix the knowledge found, each new request - as from scratch
- Previously prepared requests can only be raised in
pure SQL - The query structure (fields, filters, groupings) is hard to change. As a rule, the price of rapid changes is loss of integrity or residual redundancy.
- The preparation of the filters is done blindly.
- Relationships between entities are subject to manual indication.
- All the database schema available to him falls out on the user.
All this in the absence of documentation on the structure. Although it is out of the tool, the problem concerns the tools directly.
If you don’t understand the reality of the problems listed above, then I hope that you will understand this after learning how I try to solve them. If, in your opinion, these problems are contrived, then it will be easier for us if you do not read further.
Decision
A comprehensive solution to the problems identified in the Freedom of Sampling program is conducted in several directions simultaneously. The text of this section describes in detail the applied concepts and implementation nuances.
Clear and convenient data structure
Only the simplest database contains entities in which it is impossible to get lost. In a well-developed application area, tables and fields are measured in tens and hundreds, respectively, and if we talk about repositories, these are hundreds and thousands. In addition, a developer or analyst often has several connections (test, production, archive) for each subject area, which, as a rule, are also quite a lot.
Distinguishing the necessary from the completely unnecessary is one of the first tasks solved by our tool.
Databases and tables
Within the selected “engine” of access, you can create and remember connections, which, incidentally, is standard.
In the full list of tables you can find the fields of interest by substring, for example:
Context
An entity / table context is a concept that is close to Business Objects universes, but broader. It is natural to proceed from the assumption that the user is not interested in tables that are not related to the selected one. At the same time, it would be a mistake to think that only directly related tables are included in the context - therefore in the context we can see the nesting of any level:
Nodes are entities, leaves are fields. Associated entities are shown next to the fields of the entity with which they have a connection. Multiple links to the same entity are distinguished by the fields through which the link is indicated:
By default, only entities referenced by the fields are shown, but you can also see connections from the other side.
This operation is performed either one-time, individually for each table, or the mode for all tables is turned on automatically.
Recognition
You are lucky if the system architect has provided all the foreign keys and registered them in the scheme, then the connections will be determined automatically and you will almost not need to take care of this. I love watching such databases; The examples in the screenshots above are made in one of them - thanks to my teachers on one of the projects.
You are not lucky, not only if the architect has not provided for this, but also if the sub-driver of the access components does not support the receipt of this information. In ADO and ODBC, this is often the case, but these engines are not the only ones our tool can work with.
Definition
Suppose, for some reason, we are still faced with the fact that the data on the connections cannot be taken from the scheme. But they are so convenient to use each time.
We can define them on our own. There are several ways to do this.
The simplest is a one-time bundle of one field, through the context menu and the dialog (in some cases this can be done via drag'n'drop fields on each other):
More complex is a bunch of several fields:
Finally, aerobatics is a multiple typical connection of all necessary tables:
I had to perform the last task by analyzing the schema of one popular Open Source portal, where there are several dozen obvious links to each of the reference tables, in which, in turn, the number of links reaches the same order of magnitude.
All these links will be stored in the local "scheme" that exists as an addition to the automatically recognized links through the driver to the database, and henceforth will be determined by contexts along with them.
Other features
For individual special cases, there are separate goodies that make the context more flexible. We will not dwell in detail, just a snapshot of the context menu:
Fine, but what is all this for ?!
The definition and display of the context of the entity with which the user works is not only done so that he can focus on choosing the data he needs, nested in the links. The user does not think about linking them, because the query builder takes into account binding fields and the nature of the link is transparent to the user.
Convenience request building
We have taken the first step for convenient work - we have separated the important from the secondary. Now our task is to simplify the selection of the essential from the available.
On the run
Our task is to open the context to the desired depth and select the required fields. Tables are only a way to navigate to them, their indication is not required at all. Typical operations with fields in the query - adding to the selection, adding to the filter and adding to the expression (in the selection or filter).
The figure highlights three buttons-icons of typical actions and shows the result of one of them (adding to the filter) using the example of the Name field of the ServiceSubGroup table referenced by the Service table:
When you select a table in the tool, you can automatically add all fields to the selection. However, we do not need extra garbage in the results, so we want to get rid of some fields (in the figure, the same Service table is shown):
... And add a field from the depth of the context (done via drag'n'drop):
... find the maximum value of the field in groups and the number of lines:
... then regroup the fields:
... make a request (filter definition is omitted, about it later):
... temporarily remove one field from the selection and ungroup another:
... make a new query and see a more interesting result:
All this and much more now we can do with a minimum of clicks.
Object model
The most important feature of the Freedom of Sampling tool is that database objects are treated in a holistic manner everywhere: shown, added, deleted, hidden, and so on. It allows the user to relax, operating with them, and not to lose the tool and not
spoil them in dialogue with the user.
The object model clearly controls the need and sufficiency of connections, takes into account the fields that need to be grouped by request. For example:
We make a grouping request for the sum of all services in the group, divided by subgroup and service name, in the middle of the figure the generated request is shown.
Then we want to group only by subgroup, for this we “hide” the name of the service:
In the request, the Shortname disappeared from both parts (select, group by).
Finally, remove the selection condition (again, temporarily):
The request not only completely disappeared the where section, but also became one join less, since we no longer need the fields of the ServiceGroup table.
Naturally, in the same few clicks you can return the request to the opposite state.
Expression editor
The use of fields and connections alone is sufficient only up to a certain limit. Sooner or later it is necessary to calculate from them new values that are not presented in the database directly. How to combine the conveniences already known to us and the manual creation, and even more so the change of designs?
The output is quite simple: you must continue to use the fields as objects, and the rest of the richest syntax (except for standard aggregate functions) to give all the various DBMS to the user. That is, everything that is not a field, he will write with the text, plus there is an opportunity to refer or not to refer to the fields in the "correct style".
The expression editor is designed so that you can insert a link to any available field in the expression text anywhere or delete any of the previously mentioned links:
In the figure you can see that we have made the difference between the sum of the session and the sum of the sum of operations (in the hope that it will give 0, as it should) and divided it all into 100 (the sums were initially in kopecks). In this expression, there are six objects that can be controlled and are distinguished by a tool: an opening bracket, two fields, an aggregate function, and two closing brackets. The brackets are moved to managed objects to simplify the control of their pairing (when you remove the bracket, on the one hand, the bracket / function on the other is automatically removed) and the possibility of checking the occurrence of the field in the aggregate expression. All other characters: - , / , 1 , 0 , 0 will be transferred to the server "as is" and for the tool they do not mean anything.
This may not seem very convenient - to switch between creating links and writing the rest of the expression. However, even if we only compare the speed of typing the average number of characters in a field, we already get the gain. Let's add here the possible depth of context. And as a payment for the convenience of manipulation, considered both earlier and later in this text, this difference can not be considered at all.
Any field specified in the selection or filter is already ready to be changed, for example:
The most convenient filtering
It is clear that in the presence of excellent means for manipulating the sample, working with limiters should be no less simple. Consider what opportunities we have at our disposal.
Set filters in a few clicks
The filter panel initially contains an empty container for them:
There are several ways to add a filter to a container:
- Create new, empty
- Click on the button "in the filter" in the scheme
- Drag a field from the map
- Drag an expression from the selection into the container (a filter will be created with a copy of the expression)
As a result, we get something like (filters are only sketched, but all are non-predefined):
You can add filters by selecting any of them and then specify its type and value:
Predictive selection of values
Regardless of the complexity of the expression on the left, we have the opportunity to quickly understand the set of possible values that we are going to filter. Let's make our expression a bit more catchy, and see what the “directory” offers to us:
The handbook diligently gave us all the combinations for this expression.
However, this was the simplest case, since all combinations of the fields of the tables to which they belong were selected. Often there are too many of them, and there is no guarantee that they will be in the sample at all. For such cases, there are two additional selection modes:
They are arranged by increasing request duration.
“Expected without filter” means that only those values that are referenced from the tables of selected fields will be selected.
"Expected with the filter" take into account the superimposed filters, thereby further narrowing the options. Naturally, the current filter is discarded.
After removing the empty filter from the previous example, and setting the “Expected with filter” selection, we will see the following result:
We could take away the values long and painfully, each time getting an empty sample, since the filter for this expression is either redundant or "incompatible with life."
Group, regroup, and disable filters
We have so far considered the simplest set of several simple filters. However, the panel allows you to group them into any combination, to perform over them the operations of association on the basis of "and", "or", to deny. This is done using the drag'n'drop gesture and toolbar buttons. Each filter can be disabled, even the root. You can, say, create such a composition:
Short and for ages
What was once done does not want to be repeated again, at least if we are talking about labor. Let us enumerate, what results can be relied upon, having once produced them.
Saving link configuration
One of the foundations of the tool's convenience is table contexts. If you had to work on them manually, then they are saved to a file, which, among other things, can be edited manually or carried with them to another workplace. However, everyone is better if this information is spelled out by the architect.
Recoverable query structure
The created request can be saved and transferred as a full-fledged “document”: when opened at another time or in another place, it will be restored in all trifles. The only natural limitation is that the connection to the database must be accessible and its structure must match up to the fields used. The transfer of context settings is not required, copies of the necessary links are written in the document.
Each completed request is saved to the historical pool.
As soon as you have completed the request, it is added to the list of previously executed. This is done so that you can compare the results between iterations of the refinement of fields, conditions, groupings and other things. In addition to the data set, the query structure is saved (as a document) - it can be restored, and the original SQL query (it could be changed manually).
Auto-save and restore session
Finally, the entire request history is saved in case of a program crash, after restarting, it is completely restored.
Development directions
There are many little things in the tool that were not mentioned here, since they are not distinctive features. In addition, many of these little things may have died or died out due to infrequent use, or by-products of refactoring.
While the tool is little known, it contains only what the developer is facing. If there is interest and demand, much can be repaired and completed.
Initially, the tool developed as a desktop, but recently, as an experiment, a simplified web interface to it was implemented. The desktop interface itself is rather outdated.
Your reaction, dear readers, I hope, and will determine whether the instrument is worth living a dynamic life, or is it just an illustration
another dead end branch of development. Thanks for attention!
Source: https://habr.com/ru/post/197424/
All Articles