The popularity of Habr's tags: what are the trends in posts?

Good day!
Today we will talk about how you can try to trace trends. Looking at how this makes google have a desire to make such trends based on the Habr tags. Perhaps not all users put tags in good faith, but by admitting this as the truth, you can get good results. So let's try.
1. Description
Honestly, the idea was originally only to collect all the tags and sort them in descending order, looking at which ones are most often used and which are not. But I decided to go a little further - adding the date had the opportunity to look at this frequency in time, for clarity, adding graphs. All this will be at the end, but for now let's start from the very beginning.
At once I will make a reservation that later in the text the word “tag” is encountered - this is the same as the tag, tag, tag. We will write under python 3.3.2, since in it I did not have any problems with Unicode.
')
2. Structure and preparation
For this task we need a database. It will contain 2 tables post_tags and tags. Fields of the first pid are post id, tid is tag id, date is post date with tag. Fields of the second rowid are the tag id, tag_title is the tag header. It's all very simple, so we will create a class for working with the database.
import sqlite3 class Base: def __init__(self,dbname): self.con=sqlite3.connect(dbname) def __del__(self): self.con.close( ) def maketables(self): """ """ self.con.execute('create table post_tags(pid,tid,date)') self.con.execute('create table tags(tag_title)') self.con.commit( ) Since everything is saved in the tags.py file, we will try to execute:
import tags extend = tags.Base('tags.db') extend.maketables() Now we have an empty base, let's go fill it up.
3. Parsing tags
It is necessary to collect all the tags and write together with the date of publication of the post. For this we use beautifulsoup and urllib.request .
Add a function to the created class:
- get_tag - to get a tag from the database
- add_tag - to add a tag
- add_post - to view and add post
Parsing Function Code
def get_tag(self, name, added = True): """ , tid, cur - res - added - / , false """ cur=self.con.execute("select rowid from %s where %s='%s'" % ('tags','tag_title',name)) res=cur.fetchone( ) if res==None: if added: cur=self.con.execute("insert into %s (%s) values ('%s')" % ('tags','tag_title',name)) self.con.commit( ) return cur.lastrowid else: return False else: return res[0] def add_tag(self, pid, name, date): """ pid - name - date - """ rowid = self.get_tag(name); print(pid,rowid ,name, date) self.con.execute("insert into %s (%s,%s,%s) values (%d,%d,'%s')" % ('post_tags','pid','tid','date',pid,rowid,date)) self.con.commit( ) def add_post(self, pid): """ ( ) """ if (self.get_post(pid)): return print('-'*10,'http://habrahabr.ru/post/'+str(pid),'-'*10) cur=self.con.execute("select pid from %s where %s=%d" % ('post_tags','pid',pid)) res=cur.fetchone( ) if res==None: try: soup=BeautifulSoup(urllib.request.urlopen('http://habrahabr.ru/post/'+str(pid)).read( )) except (urllib.request.HTTPError): self.add_tag(pid,"parse_error_404","") print("error 404") else: published = soup.find("div", { "class" : "published" }) tags = soup.find("ul", { "class" : "tags" }) if tags: for tag in tags.findAll("a"): self.add_tag(pid, tag.string, get_date(published.string)) else: self.add_tag(pid,"parse_access_denied","") print("access denied") else: print("post has already") To fill the base, it is enough to start a cycle on all posts. We restrict ourselves to 196,000 it falls on October 1, 2013.
for pid in range(196000): extend.add_post(pid+1) I know that the method is not ideal and with the megabit Internet would work about 170 hours.
To speed up the process, it was decided to add another post table, which will store a separate post id, not associated with the logical part, and use it as a flag. So most of the time the program "hangs". While waiting for the page to load, you can run a couple more of these programs and set them on one base to fill it in parallel. The occurrence of collisions is of course possible and in the end loss or partial recording amounted to 3% of posts, which is not so much. After such actions, it turned out that more than 8 programs cannot work in parallel, since at start 9 Habr gives 503 error , which is quite logical. Therefore, launching 6 copies (this number did not cause errors and did not conflict with each other), the base was obtained (17 Mb).
4. Data processing
Actually, now the main part is to process the received data.
Add a function to the created class:
- get_count_byid - number by tag ID
- get_graph - get a list of tuples (date, number)
- get_image - show image
- get_all_tags_sorted - sort descending
- get_all_tag_count - get a list of tuples (id, tag, number)
Function code for data processing
def get_count_byname(self, name, date = ''): """ name tid get_count_byid name - date - (*) mm_yyyy """ tid = self.get_tag(name, False) return self.get_count_byid(tid, date) def get_count_byid(self, tid, date = ''): """ """ if tid: if date: count=self.con.execute("select count(pid) from %s where %s=%d and %s='%s'" % ('post_tags','tid',tid,'date',date)) else: count=self.con.execute("select count(pid) from %s where %s=%d" % ('post_tags','tid',tid)) res=count.fetchone( ) return res[0] else: return False def get_graph(self, name): """ - """ month = ('01',''),('02',''),('03',''),('04',''),('05',''),('06',''),('07',''),('08',''),('09',''),('10',''),('11',''),('12','') years = [2006,2007,2008,2009,2010,2011,2012,2013] graph = [] for Y in years: for M,M_str in month: date = str(M)+'_'+str(Y) graph.append((date, self.get_count_byname(name, date))) return graph def get_image(self, name): """ m_x - X m_y - Y img_x - img_y - """ img_x = 960 img_y = 600 img=Image.new('RGB',(img_x,img_y),(255,255,255)) draw=ImageDraw.Draw(img) graph = self.get_graph(name) max_y = max(graph,key=lambda item:item[1])[1] if max_y == 0: print('tag not found') return False m_x, m_y = int(img_x/(len(graph))), int(img_y/max_y) draw.text((10, 10), str(max_y), (0,0,0)) draw.text((10, 20), name, (0,0,0)) x,prev_y = 0,-1 for x_str, y in graph: x += 1 if (x%12 == 1): draw.text((x*m_x, img_y - 30), str(x_str[3:]),(0,0,0)) if prev_y >= 0: draw.line(((x-1)*m_x, img_y-prev_y*m_y-1, x*m_x, img_y-y*m_y-1), fill=(255,0,0)) prev_y = y img.save('graph.png','PNG') Image.open('graph.png').show() def get_all_tags_sorted(self, tags): """ """ return sorted(tags, key=lambda tag:tag[2], reverse=True) def get_all_tag_count(self): count=self.con.execute("select count(rowid) from %s" % ('tags')) res=count.fetchone( ) alltag_count = res[0] tags = [] for tag_id in range(alltag_count-1): tags.append((tag_id+1,self.get_tag_name(tag_id+1),self.get_count_byid(tag_id+1))) print (tag_id+1,self.get_tag_name(tag_id+1),self.get_count_byid(tag_id+1)) return tags 5. Total (for fans of statistics)
Top 25 leaderboard tags:
- google - 2611
- android - 2188
- Google - 2024
- linux - 1978
- php - 1947
- javascript - 1877
- microsoft - 1801
- apple - 1668
- social networks - 1509
- startups - 1484
- startup - 1317
- programming - 1229
- Microsoft - 1220
- java - 1180
- games - 1141
- Apple - 1135
- iphone - 1122
- design - 1110
- python - 1108
- humor - 1061
- Internet - 1040
- habrahabr - 983
- video - 970
- advertising - 968
- Android - 876
The full list can be found here (format id, title_tag, number of mentions).
Now, actually, we return to the idea of trends. Below are a couple of examples (clickable):
| python | javascript | android |
 | 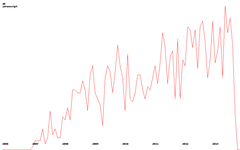 | 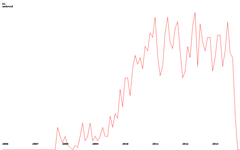 |
I am sure that there are still better methods for obtaining a similar result, but "I am not a wizard, I am just learning." I ask everyone in the comments for discussions and improvements.
Basically, my goal was achieved. Although there are already thoughts about adding register independence and morphology, as well as the ability to immediately send a list of tags.
The full code is posted on github .
Thank you all for your attention, I will be glad to criticism.
Source: https://habr.com/ru/post/197308/
All Articles