We write our JSON parser (with polka dots and pearl buttons)
This article was written by Aaron Patterson, a Ruby developer from Seattle, WA. He has been passionate about developing in Ruby for 7 years now and will be happy to share his love for this wonderful language.
Salute to all! Hope you have a great mood. Today, the sun briefly peeped out from behind the clouds, so that for me everything is just fine!
In this article, we will look at a series of compilation tools for use in conjunction with Ruby. And to dive into the subject, we write a JSON parser. Already I hear disgruntled exclamations like: “well, Aaron, well, why? Are not 1,234,567 pieces already written? ”That's it! We already have 1,234,567 JSON parsers written in Ruby! And we will also analyze JSON, because its grammar is simple enough to complete the work at a time, and because it is nevertheless difficult enough to use the compilation tools developed for Ruby wisely.
')
Before you continue reading, I want to draw attention to the fact that this is not an article on how to analyze JSON, but on how to use analysis and compilation tools in Ruby.
I will test on Ruby 1.9.3, but it should work on any implementation you choose. Mostly we will use tools like
Racc will be needed for us to automatically generate the analyzer. This LALR analyzer generator is much like YACC. The last abbreviation stands for “Yet Another Compiler Compiler” (another compiler compiler), but since this is a version for Ruby, it turned out Racc. Racc is committed to converting a set of grammar rules (a file with a
Hereinafter we will be engaged in writing ".y" files, however, end users will not be able to run them. To do this, you first need to convert them into Ruby executable code, and then package this code into our gem. In essence, this means that only we will install gem Racc, and end users will not need it.
Do not worry if all this does not fit in your head. Everything will become clear when we move from theory to practice and start writing code.
StringScanner is a class that (as the name implies) allows you to process strings sequentially, according to the scanner principle. It stores information about where we are in the line and allows us to move from beginning to end using regular expressions and direct reading of characters.
Let's get started! First, create a
Notice that the third call to StringScanner # scan returned
The handler can also be moved character by character using StringScanner # getch :
The
Now that we have dealt with the basics of sequential processing, let's see how Racc is used.
As I said, the Racc is a LALR analyzer generator. We can assume that this is a mechanism that allows you to create a limited set of regular expressions, which in turn can execute arbitrary code in different positions in the process of how they are matched.
Let's take an example. Suppose we want to check the substitutions of a regular expression of the form:
First, create a grammar file. At the beginning of the file comes the declaration of the Ruby class that we want to receive, followed by the keyword
Now add products for “a | c”. Let's call it
As a result, we have a rule
As I said,
And complete all the string output:
This final output performs pattern matching, in which one or more characters 'a' or 'c' are followed by 'abb' or else there is a free-standing line 'abb'. All of this is equivalent to our original regular expression of the form
I know this is much longer than a regular regular expression. But there is one plus: we can add and execute arbitrary Ruby code in any part of the matching process. For example, each time we get a freestanding line 'abb' we can output something like this:
The code that we want to execute must be enclosed in curly brackets and located immediately after the rule that will be responsible for its launch. Now we are ready to arm our knowledge with creating our own JSON analyzer, which in our case will be event-based.
Our analyzer will consist of three component parts: the parser, the lexical analyzer, and the document processor. The parser based on the Racc grammar will refer to the lexical analyzer for data from the input stream. Every time when the parser manages to isolate the JSON element from the general data stream, it sends the corresponding event to the document handler. The document processor is responsible for collecting data from JSON and translating it into a data structure in Ruby. In the process of analyzing the source data in JSON format, calls will be made as shown in the graph below:
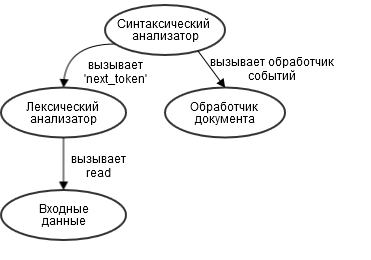
However, let's get down to business. First we will focus on the lexical analyzer, then we will do the grammar of the parser and finally complete the process by creating a document handler.
Our lexical analyzer is built on an IO object. It is from it that we will read the source data. For each
For complex types like arrays and objects, the parser will be responsible.
Values returned by
When the parser calls the
Let's look at the code of the class and analyze what it does:
First come the declarations of several regular expressions, which we will use in conjunction with the StringScanner string handler. They are built on the basis of definitions taken from json.org . An instance of StringScanner is created in the constructor. Since it requires a string when it is created, we call the read object IO. This, however, does not exclude an alternative implementation, in which the lexical analyzer reads data from an IO object not entirely, but as needed.
The main work is done in the
Let's give the lexical analyzer an example of a string in JSON format and see what lexemes we get at the output:
In this example, we wrapped a JSON string in a
This completes the work with the lexical analyzer. During initialization, it receives an
It's time to do some syntax. First, let's work a little bit with a rake. We need to implement generating a file in Ruby based on a
First, we add a rule to the rake file that says "convert
Then add the “compile” task, depending on the generated
Since the grammar file is stored in
And finally, we set the “test” task dependent on the “compile” task, so that when we run
Now you can go directly to the compilation and verification of the
Now we are going to translate diagrams from json.org to the Racc grammar format. At the root of the source document there must be either an object or an array, so we will create a
Next we define the output
The output for values (
In the JSON specification, the
Go to the definition of products for the object (
The steam may be one or more and between them they must be separated by commas. Again we use the recursive definition:
Finally, we define a pair (pair), which is a string and a number, separated by a colon:
Now let us inform Racc about our lexemes from the lexical analyzer, adding the definition at the very beginning, and our parser is ready:
The document handler will receive events from our parser. He will build our incomparable Ruby object from delightful pieces of JSON! I leave the number of events to your discretion, and I will limit myself to 5:
With these five events, we will assemble an object reflecting the original JSON structure.
Our handler will simply keep track of events coming from the parser. The result is a tree structure, on the basis of which, we build the final Ruby object.
Each time the parser detects the beginning of an object, the handler adds a list with the hash symbol to the top of the stack to mark the beginning of the associative array. Events that are children will be added to the parent, and when the end of the object is detected, the parent will be pushed out of the stack.
I do not exclude that it is difficult to understand from the first time, therefore we will consider several examples. Passing a JSON string like
Taking, for example, an array of the form
Having thus obtained an intermediate presentation of the JSON document, we proceed to convert it into a data structure in Ruby. To do this, we write the recursive function of processing the resulting tree:
The
Let's see how it works in practice:
We have a fully functional JSON analyzer. True, with one drawback - it does not have a very convenient software interface. Let's use the previous example to improve it:
Since our analyzer was originally built for an IO object, we can add a method for those who would like to send a socket or a file descriptor as input:
We are convinced that the interface has become a bit more convenient:
So, the work on the analyzer is completed. In the process, we became familiar with the compilation technology, including the basics of syntax and lexical analysis, and even touched on interpreters (that's it, in fact, we were engaged in JSON interpretation). You have something to be proud of!
The analyzer we wrote was quite flexible. We can:
I hope this article will give you confidence, and you will begin to experiment on your own with the analysis and compilation technologies implemented in Ruby. If you still have questions for me, you are welcome in the comments .
In conclusion, I want to clarify some details that I omitted in the process of presentation, so as not to introduce additional ambiguity:
That's all. Thanks for attention!
1 eng rake - rake
Comments on the translation, please send in a personal.
Salute to all! Hope you have a great mood. Today, the sun briefly peeped out from behind the clouds, so that for me everything is just fine!
In this article, we will look at a series of compilation tools for use in conjunction with Ruby. And to dive into the subject, we write a JSON parser. Already I hear disgruntled exclamations like: “well, Aaron, well, why? Are not 1,234,567 pieces already written? ”That's it! We already have 1,234,567 JSON parsers written in Ruby! And we will also analyze JSON, because its grammar is simple enough to complete the work at a time, and because it is nevertheless difficult enough to use the compilation tools developed for Ruby wisely.
')
Before you continue reading, I want to draw attention to the fact that this is not an article on how to analyze JSON, but on how to use analysis and compilation tools in Ruby.
What we need
I will test on Ruby 1.9.3, but it should work on any implementation you choose. Mostly we will use tools like
Racc and StringScanner .Racc:
Racc will be needed for us to automatically generate the analyzer. This LALR analyzer generator is much like YACC. The last abbreviation stands for “Yet Another Compiler Compiler” (another compiler compiler), but since this is a version for Ruby, it turned out Racc. Racc is committed to converting a set of grammar rules (a file with a
.y extension) into a Ruby file that describes transition rules for a finite state machine. The latter are interpreted by the state machine (runtime environment) Racc. The runtime comes with Ruby, but it doesn’t have the tool that converts files with the extension ".y" into automaton state tables. Install it by running gem install racc .Hereinafter we will be engaged in writing ".y" files, however, end users will not be able to run them. To do this, you first need to convert them into Ruby executable code, and then package this code into our gem. In essence, this means that only we will install gem Racc, and end users will not need it.
Do not worry if all this does not fit in your head. Everything will become clear when we move from theory to practice and start writing code.
StringScanner:
StringScanner is a class that (as the name implies) allows you to process strings sequentially, according to the scanner principle. It stores information about where we are in the line and allows us to move from beginning to end using regular expressions and direct reading of characters.
Let's get started! First, create a
StringScanner object and process several characters with it: irb(main):001:0> require 'strscan' => true irb(main):002:0> ss = StringScanner.new 'aabbbbb' => #<StringScanner 0/7 @ "aabbb..."> irb(main):003:0> ss.scan /a/ => "a" irb(main):004:0> ss.scan /a/ => "a" irb(main):005:0> ss.scan /a/ => nil irb(main):006:0> ss => #<StringScanner 2/7 "aa" @ "bbbbb"> irb(main):007:0> Notice that the third call to StringScanner # scan returned
nil , since the regular expression in this position no longer suits. As well as the fact that when inspect is called for an instance of StringScanner , you can see the current position of the handler in the string (in this case, 2/7 ).The handler can also be moved character by character using StringScanner # getch :
irb(main):006:0> ss => #<StringScanner 2/7 "aa" @ "bbbbb"> irb(main):007:0> ss.getch => "b" irb(main):008:0> ss => #<StringScanner 3/7 "aab" @ "bbbb"> irb(main):009:0> The
getch method returns the next character and shifts the pointer one forward.Now that we have dealt with the basics of sequential processing, let's see how Racc is used.
Racc Basics
As I said, the Racc is a LALR analyzer generator. We can assume that this is a mechanism that allows you to create a limited set of regular expressions, which in turn can execute arbitrary code in different positions in the process of how they are matched.
Let's take an example. Suppose we want to check the substitutions of a regular expression of the form:
(a|c)*abb . In other words, register cases where an arbitrary number of 'a' or 'c' characters is followed by 'abb'. To translate this into a Racc grammar, we will try to break this regular expression into its constituent parts, and then we will put it together again. Each individual grammar element is called a generating rule or product. So, we break this expression into pieces to see what the products look like and what is the format of the Racc grammar.First, create a grammar file. At the beginning of the file comes the declaration of the Ruby class that we want to receive, followed by the keyword
rule meaning that we are going to declare the products, followed by the end keyword, indicating their end: class Parser rule end Now add products for “a | c”. Let's call it
a_or_c : class Parser rule a_or_c : 'a' | 'c' ; end As a result, we have a rule
a_or_c , which performs a comparison with the symbol 'a' or 'c'. In order to perform the mapping one or more times, we will create recursive output, which we call a_or_cs : class Parser rule a_or_cs : a_or_cs a_or_c | a_or_c ; a_or_c : 'a' | 'c' ; end As I said,
a_or_cs output is recursive, being equivalent to the regular expression (a|c)+ . Next, add products for 'abb': class Parser rule a_or_cs : a_or_cs a_or_c | a_or_c ; a_or_c : 'a' | 'c' ; abb : 'a' 'b' 'b'; end And complete all the string output:
class Parser rule string : a_or_cs abb | abb ; a_or_cs : a_or_cs a_or_c | a_or_c ; a_or_c : 'a' | 'c' ; abb : 'a' 'b' 'b'; end This final output performs pattern matching, in which one or more characters 'a' or 'c' are followed by 'abb' or else there is a free-standing line 'abb'. All of this is equivalent to our original regular expression of the form
(a|c)*abb .Aaron, but it is so tedious!
I know this is much longer than a regular regular expression. But there is one plus: we can add and execute arbitrary Ruby code in any part of the matching process. For example, each time we get a freestanding line 'abb' we can output something like this:
class Parser rule string : a_or_cs abb | abb { puts " abb, !" } ; a_or_cs : a_or_cs a_or_c | a_or_c ; a_or_c : 'a' | 'c' ; abb : 'a' 'b' 'b'; end The code that we want to execute must be enclosed in curly brackets and located immediately after the rule that will be responsible for its launch. Now we are ready to arm our knowledge with creating our own JSON analyzer, which in our case will be event-based.
We create an analyzer
Our analyzer will consist of three component parts: the parser, the lexical analyzer, and the document processor. The parser based on the Racc grammar will refer to the lexical analyzer for data from the input stream. Every time when the parser manages to isolate the JSON element from the general data stream, it sends the corresponding event to the document handler. The document processor is responsible for collecting data from JSON and translating it into a data structure in Ruby. In the process of analyzing the source data in JSON format, calls will be made as shown in the graph below:
However, let's get down to business. First we will focus on the lexical analyzer, then we will do the grammar of the parser and finally complete the process by creating a document handler.
Lexical analyzer
Our lexical analyzer is built on an IO object. It is from it that we will read the source data. For each
next_token call next_token lexical analyzer reads one token from the input data stream and returns it. It will work with the following list of tokens, which we borrowed from the JSON specifications:- Strings
- Numbers
- True
- False (False)
- Null (No value)
For complex types like arrays and objects, the parser will be responsible.
Values returned by next_token :
When the parser calls the
next_token lexical analyzer, it expects to result in an array of two elements or nil . The first element of the array must contain the name of the lexeme, and the second can be anything (usually it is just mapped text). Returning nil lexical analyzer reports that there are no more tokens.Tokenizer lexical analyzer Tokenizer :
Let's look at the code of the class and analyze what it does:
module RJSON class Tokenizer STRING = /"(?:[^"\\]|\\(?:["\\\/bfnrt]|u[0-9a-fA-F]{4}))*"/ NUMBER = /-?(?:0|[1-9]\d*)(?:\.\d+)?(?:[eE][+-]?\d+)?/ TRUE = /true/ FALSE = /false/ NULL = /null/ def initialize io @ss = StringScanner.new io.read end def next_token return if @ss.eos? case when text = @ss.scan(STRING) then [:STRING, text] when text = @ss.scan(NUMBER) then [:NUMBER, text] when text = @ss.scan(TRUE) then [:TRUE, text] when text = @ss.scan(FALSE) then [:FALSE, text] when text = @ss.scan(NULL) then [:NULL, text] else x = @ss.getch [x, x] end end end end First come the declarations of several regular expressions, which we will use in conjunction with the StringScanner string handler. They are built on the basis of definitions taken from json.org . An instance of StringScanner is created in the constructor. Since it requires a string when it is created, we call the read object IO. This, however, does not exclude an alternative implementation, in which the lexical analyzer reads data from an IO object not entirely, but as needed.
The main work is done in the
next_token method. It returns nil if there is no more data in the line processor, otherwise it will check every regular expression until it finds a suitable one. If a match was found, it will return the name of the token (for example :STRING ) along with the text that matched the pattern. If none of the regular expressions matches, one character will be read from the handler, and the read value will be returned at the same time as the name of the token and its value.Let's give the lexical analyzer an example of a string in JSON format and see what lexemes we get at the output:
irb(main):003:0> tok = RJSON::Tokenizer.new StringIO.new '{"foo":null}' => #<RJSON::Tokenizer:0x007fa8529fbeb8 @ss=#<StringScanner 0/12 @ "{\"foo...">> irb(main):004:0> tok.next_token => ["{", "{"] irb(main):005:0> tok.next_token => [:STRING, "\"foo\""] irb(main):006:0> tok.next_token => [":", ":"] irb(main):007:0> tok.next_token => [:NULL, "null"] irb(main):008:0> tok.next_token => ["}", "}"] irb(main):009:0> tok.next_token => nil In this example, we wrapped a JSON string in a
StringIO object in order to achieve duck typing with IO. Then try to read a few lexemes. Each token familiar to the analyzer consists of a name that comes with the first element of the array, whereas in unknown tokens this place is taken by one character. For example, the string token will look like [:STRING, "foo"] , and the unknown token, in the particular case, as ['(', '('] . Finally, when the input data is exhausted, we get nil on the output.This completes the work with the lexical analyzer. During initialization, it receives an
IO object at the input and implements a single method next_token . Everything, it is possible to pass to the parser.Syntactical analyzer
It's time to do some syntax. First, let's work a little bit with a rake. We need to implement generating a file in Ruby based on a
.y file. Just work for rake 1 .We describe the compilation task:
First, we add a rule to the rake file that says "convert
.y files to .rb files using the following command" : rule '.rb' => '.y' do |t| sh "racc -l -o #{t.name} #{t.source}" end Then add the “compile” task, depending on the generated
parser.rb file. task :compile => 'lib/rjson/parser.rb' Since the grammar file is stored in
lib/rjson/parser.y , now that we run rake compile , rake automatically converts the .y file to a file with a .rb extension using Racc.And finally, we set the “test” task dependent on the “compile” task, so that when we run
rake test , the compiled version is automatically generated: task :test => :compile Now you can go directly to the compilation and verification of the
.y file.Parse the JSON.org specification:
Now we are going to translate diagrams from json.org to the Racc grammar format. At the root of the source document there must be either an object or an array, so we will create a
document output that matches the object — object or the array — array : rule document : object | array ; Next we define the output
array . Products for an array can either be empty or contain one or more values: array : '[' ']' | '[' values ']' ; The output for values (
values ) is defined recursively, as one value, or several values separated by comma: values : values ',' value | value ; In the JSON specification, the
value defined as a string, number, object, array, true (true), false (false) or null (no value). Our definition will be similar, the only difference is that for immediate values like NUMBER (number), TRUE (true) and FALSE (false), we use the corresponding names of the tokens defined in the lexical analyzer: value : string | NUMBER | object | array | TRUE | FALSE | NULL ; Go to the definition of products for the object (
object ). Objects can be empty, or consisting of pairs ( pairs ): object : '{' '}' | '{' pairs '}' ; The steam may be one or more and between them they must be separated by commas. Again we use the recursive definition:
pairs : pairs ',' pair | pair ; Finally, we define a pair (pair), which is a string and a number, separated by a colon:
pair : string ':' value ; Now let us inform Racc about our lexemes from the lexical analyzer, adding the definition at the very beginning, and our parser is ready:
class RJSON::Parser token STRING NUMBER TRUE FALSE NULL rule document : object | array ; object : '{' '}' | '{' pairs '}' ; pairs : pairs ',' pair | pair ; pair : string ':' value ; array : '[' ']' | '[' values ']' ; values : values ',' value | value ; value : string | NUMBER | object | array | TRUE | FALSE | NULL ; string : STRING ; end Document Handler
The document handler will receive events from our parser. He will build our incomparable Ruby object from delightful pieces of JSON! I leave the number of events to your discretion, and I will limit myself to 5:
start_object- called at the beginning of the objectend_object- called at the end of the objectstart_array- called at the beginning of the arrayend_array- called at the end of the arrayscalar- called in terminal cases such as strings, true, false, etc.
With these five events, we will assemble an object reflecting the original JSON structure.
We follow the events
Our handler will simply keep track of events coming from the parser. The result is a tree structure, on the basis of which, we build the final Ruby object.
module RJSON class Handler def initialize @stack = [[:root]] end def start_object push [:hash] end def start_array push [:array] end def end_array @stack.pop end alias :end_object :end_array def scalar(s) @stack.last << [:scalar, s] end private def push(o) @stack.last << o @stack << o end end end Each time the parser detects the beginning of an object, the handler adds a list with the hash symbol to the top of the stack to mark the beginning of the associative array. Events that are children will be added to the parent, and when the end of the object is detected, the parent will be pushed out of the stack.
I do not exclude that it is difficult to understand from the first time, therefore we will consider several examples. Passing a JSON string like
{"foo":{"bar":null}} as input, we get the following in the stack variable @stack : [[:root, [:hash, [:scalar, "foo"], [:hash, [:scalar, "bar"], [:scalar, nil]]]]] Taking, for example, an array of the form
["foo",null,true] , in @stack we get the following: [[:root, [:array, [:scalar, "foo"], [:scalar, nil], [:scalar, true]]]] Convert to Ruby:
Having thus obtained an intermediate presentation of the JSON document, we proceed to convert it into a data structure in Ruby. To do this, we write the recursive function of processing the resulting tree:
def result root = @stack.first.last process root.first, root.drop(1) end private def process type, rest case type when :array rest.map { |x| process(x.first, x.drop(1)) } when :hash Hash[rest.map { |x| process(x.first, x.drop(1)) }.each_slice(2).to_a] when :scalar rest.first end end The
result method deletes the root node and passes what is left to the process method. When process detects the hash character, it forms an associative array using the child elements resulting from the recursive process call. By analogy with this, a recursive call on the child elements builds an array when the character array is encountered. Scalar values - scalar returned without processing (which prevents endless recursion). Now, if we call result from our handler, then we will get a Ruby object at the output.Let's see how it works in practice:
require 'rjson' input = StringIO.new '{"foo":"bar"}' tok = RJSON::Tokenizer.new input parser = RJSON::Parser.new tok handler = parser.parse handler.result # => {"foo"=>"bar"} Software interface refinement:
We have a fully functional JSON analyzer. True, with one drawback - it does not have a very convenient software interface. Let's use the previous example to improve it:
module RJSON def self.load(json) input = StringIO.new json tok = RJSON::Tokenizer.new input parser = RJSON::Parser.new tok handler = parser.parse handler.result end end Since our analyzer was originally built for an IO object, we can add a method for those who would like to send a socket or a file descriptor as input:
module RJSON def self.load_io(input) tok = RJSON::Tokenizer.new input parser = RJSON::Parser.new tok handler = parser.parse handler.result end def self.load(json) load_io StringIO.new json end end We are convinced that the interface has become a bit more convenient:
require 'rjson' require 'open-uri' RJSON.load '{"foo":"bar"}' # => {"foo"=>"bar"} RJSON.load_io open('http://example.org/some_endpoint.json') Thinking out loud
So, the work on the analyzer is completed. In the process, we became familiar with the compilation technology, including the basics of syntax and lexical analysis, and even touched on interpreters (that's it, in fact, we were engaged in JSON interpretation). You have something to be proud of!
The analyzer we wrote was quite flexible. We can:
- Use it in the event paradigm, implementing the Handler handler object.
- Use a simplified interface and just input strings.
- Pass a stream in JSON format to an input through an IO object
I hope this article will give you confidence, and you will begin to experiment on your own with the analysis and compilation technologies implemented in Ruby. If you still have questions for me, you are welcome in the comments .
PS
In conclusion, I want to clarify some details that I omitted in the process of presentation, so as not to introduce additional ambiguity:
- Here is the final grammar of our analyzer. Notice the - inner section of the .y file . Everything that is presented in this section will be added to the class of the parser, which is obtained as a result of automatic generation. In this way, we pass the handler object to the parser.
- Our parser actually translates JSON terminal nodes into Ruby. Therefore, we convert JSON to Ruby twice: in the parser and in the document handler. The latter is responsible for the structure, while the first is for the immediate values (true, false, etc.). I note that it is quite reasonable to note that all transformations must be carried out by the parser or, on the contrary, be completely excluded from it.
- Finally, the lexical analyzer uses buffering. I made a sketch version without buffering, which can be taken from here . It is pretty raw, but it can be brought to mind using the logic of the finite state machine.
That's all. Thanks for attention!
1 eng rake - rake
Comments on the translation, please send in a personal.
Source: https://habr.com/ru/post/196676/
All Articles