Introduction to the analysis of the complexity of algorithms (part 1)
From the translator: this text is given with insignificant abbreviations due to places of excessive “razvezhnannosti” material. The author absolutely rightly warns that certain topics will seem too simple or well-known. Nevertheless, personally this text helped me to streamline the existing knowledge on the analysis of the complexity of algorithms. I hope that it will be useful to someone else.
Due to the large volume of the original article, I broke it into pieces, which in total will be four.
I (as always) would be extremely grateful for any comments in PM about improving the quality of the translation.
Many modern programmers who write cool and widespread programs have an extremely vague idea of theoretical computer science. This does not prevent them from being excellent creative professionals, and we are grateful for what they create.
However, knowledge of the theory also has its advantages and can be very useful. In this article, intended for programmers who are good practitioners, but have a weak understanding of the theory, I will present one of the most pragmatic programmer tools: the notion “big O” and the analysis of the complexity of algorithms. As a person who has worked both in the field of academic science and in creating commercial software, I find these tools really useful in practice. I hope that after reading this article you can apply them to your own code to make it even better. Also, this post will bring with it an understanding of such general terms used by computer science theorists as “big O”, “asymptotic behavior”, “analysis of the most unfavorable case”, etc.
This text is also aimed at secondary school students from Greece or any other country participating in the International Olympiad in Informatics , competitions in algorithms for students and the like. As such, it does not require prior knowledge of any complex mathematical aspects and will simply give you a basis for further research of algorithms with a firm understanding of the theory behind them. As one who has participated in various competitions at one time, I strongly recommend that you read and understand all the introductory material. This knowledge will be essential when you continue to learn algorithms and various advanced technologies.
')
I hope that this text will be useful for those practical programmers who do not have much experience in theoretical computer science (the fact that the most inspired software engineers never went to college is a long-time fact). But since the article is intended for students too, at times it will sound like a textbook. Moreover, some topics may seem too simple (for example, you might encounter them during your training). So, if you feel that you understand them - just skip these moments. Other sections go somewhat deeper and are more theoretical, because students participating in competitions should understand the theory of algorithms better than the average practitioner. But to know these things is not less useful, but to follow the course of the narration is not so difficult, so they most likely deserve your attention. The original text was sent to high school students, it does not require any special mathematical knowledge, so everyone who has programming experience (for example, who knows what recursion is) is able to understand it without any special problems.
In this article you will find many interesting links to materials that go beyond our discussion. If you are a working programmer, then it is quite possible that you are familiar with most of these concepts. If you are just a novice student participating in competitions, clicking on these links will give you information about other areas of computer science and software development that you have not yet had time to learn. View them to increase your own baggage of knowledge.
The “big O” notation and analysis of the complexity of algorithms are those things that both practitioners and novice students often find difficult to understand, fear, or avoid at all, as useless. But they are not so complicated and abstruse, as it may seem at first glance. The complexity of the algorithm is just a way to formally measure how fast a program or algorithm works, which is a very pragmatic goal. Let's start with a little motivation on this topic.
We already know that there are tools that measure how fast the code works. These are programs called profilers , which determine the execution time in milliseconds, helping us to identify bottlenecks and optimize them. But, although it is a useful tool, it is not related to the complexity of the algorithms. The complexity of the algorithm is that it is based on comparing the two algorithms at an ideal level, ignoring low-level details such as the implementation of a programming language, the hardware on which the program is running, or the instruction set in a given CPU. We want to compare the algorithms in terms of what they actually are: ideas, how the calculation happens. Counting the milliseconds will be of little help here. It may well turn out that a bad algorithm written in a low-level language (for example, assembly language ) will be much faster than a good algorithm written in a high-level programming language (for example, Python or Ruby ). So it's time to decide what the “best algorithm” really is.
An algorithm is a program that is exclusively a calculation, without other things that are often performed by a computer — network tasks or user input / output. Analysis of complexity allows us to find out how fast this program is when it performs calculations. Examples of purely computational operations can be operations on floating-point numbers (addition and multiplication), searching for a given value from a database located in RAM, and determining by game artificial intelligence (AI) movement of your character so that it moves only a short distance inside the game. world, or launching a regular expression pattern against a string. Obviously, computing is found everywhere in computer programs.
The complexity analysis also allows us to explain how the algorithm will behave as the input data stream increases. If our algorithm runs for one second with 1000 entries, how does it behave, if we double this value? Will it also work fast, one and a half times faster or four times slower? In programming practice, such predictions are extremely important. For example, if we created an algorithm for a web application that works with thousands of users, and measured its execution time, then using complexity analysis, we will get a very good idea of what will happen when the number of users rises to two thousand. For competitions on the construction of algorithms, the analysis of complexity will also give us an understanding of how long our code will run on the largest of the tests to verify its correctness. So, if we define the general behavior of our program on a small amount of input data, we can get a good idea of what will happen to it with large data streams. Let's start with a simple example: finding the maximum element in an array.
In this article, I will use various programming languages to implement the examples. Do not worry if you are not familiar with any of them - anyone who can program can read this code without any problems, because it is simple and I’m not going to use any exotic baubles of the implementation language. If you are an academic student, then most likely write in C ++ , so you should have no problems either. In this case, I also recommend working out the exercises using C ++ for more practice.
The maximum array element can be found using the simplest code snippet. For example, such, written in Javascript . Given an input array
First, let's calculate how many fundamental instructions are calculated here. We will do it only once - as we go deeper into theory, such a need will disappear. But for now, have patience for the time we spend on it. In the process of analyzing this code, it makes sense to break it into simple instructions - tasks that can be performed by the processor immediately or close to it. Suppose that our processor is able to perform the following operations as a single instruction:
We will assume that the branching (the choice between
Two instructions are required: to search for
All this happens before the first run of
Thus, if we ignore the contents of the loop body, then the number of instructions in this algorithm is
In the body of the loop, we have search operations in the array and comparisons that always occur:
But the
We can no longer determine
With the function obtained above, we have a very good idea of how fast our algorithm is. However, as I promised, we do not need to constantly engage in such a tedious task, like counting commands in a program. Moreover, the number of instructions for a particular processor required to implement each position of the programming language used depends on the compiler of this language and the set of commands available to the processor (AMD or Intel Pentium on a personal computer, MIPS on Playstation 2, etc.). Earlier we said that we were going to ignore conditions of this kind. Therefore, we will now skip our function
Our function
It makes sense to think of 4 simply as an “initialization constant”. Different programming languages may require different time settings. For example, Java first needs to initialize its virtual machine . And since we agreed to ignore the differences in programming languages, we simply discard this value.
The second thing you can ignore is a factor in front of
equivalent to the following in C:
So it makes sense to expect that different programming languages will be influenced by various factors that will affect the counting of instructions. In our example, where we use the “dumb” Pascal compiler, ignoring optimization possibilities, we need three instructions in Pascal for each access to an array element instead of one in C. Neglect of this factor goes in line with the neglect of the differences between specific programming languages with a focus on analyzing the very idea of the algorithm itself.
The filters described above - “discard all factors” and “leave only the largest element” - together give what we call asymptotic behavior . For
We find the asymptotics for the following examples, using the principles of discarding constant factors and leaving only the fastest growing element:
Due to the large volume of the original article, I broke it into pieces, which in total will be four.
I (as always) would be extremely grateful for any comments in PM about improving the quality of the translation.
Introduction
Many modern programmers who write cool and widespread programs have an extremely vague idea of theoretical computer science. This does not prevent them from being excellent creative professionals, and we are grateful for what they create.
However, knowledge of the theory also has its advantages and can be very useful. In this article, intended for programmers who are good practitioners, but have a weak understanding of the theory, I will present one of the most pragmatic programmer tools: the notion “big O” and the analysis of the complexity of algorithms. As a person who has worked both in the field of academic science and in creating commercial software, I find these tools really useful in practice. I hope that after reading this article you can apply them to your own code to make it even better. Also, this post will bring with it an understanding of such general terms used by computer science theorists as “big O”, “asymptotic behavior”, “analysis of the most unfavorable case”, etc.
This text is also aimed at secondary school students from Greece or any other country participating in the International Olympiad in Informatics , competitions in algorithms for students and the like. As such, it does not require prior knowledge of any complex mathematical aspects and will simply give you a basis for further research of algorithms with a firm understanding of the theory behind them. As one who has participated in various competitions at one time, I strongly recommend that you read and understand all the introductory material. This knowledge will be essential when you continue to learn algorithms and various advanced technologies.
')
I hope that this text will be useful for those practical programmers who do not have much experience in theoretical computer science (the fact that the most inspired software engineers never went to college is a long-time fact). But since the article is intended for students too, at times it will sound like a textbook. Moreover, some topics may seem too simple (for example, you might encounter them during your training). So, if you feel that you understand them - just skip these moments. Other sections go somewhat deeper and are more theoretical, because students participating in competitions should understand the theory of algorithms better than the average practitioner. But to know these things is not less useful, but to follow the course of the narration is not so difficult, so they most likely deserve your attention. The original text was sent to high school students, it does not require any special mathematical knowledge, so everyone who has programming experience (for example, who knows what recursion is) is able to understand it without any special problems.
In this article you will find many interesting links to materials that go beyond our discussion. If you are a working programmer, then it is quite possible that you are familiar with most of these concepts. If you are just a novice student participating in competitions, clicking on these links will give you information about other areas of computer science and software development that you have not yet had time to learn. View them to increase your own baggage of knowledge.
The “big O” notation and analysis of the complexity of algorithms are those things that both practitioners and novice students often find difficult to understand, fear, or avoid at all, as useless. But they are not so complicated and abstruse, as it may seem at first glance. The complexity of the algorithm is just a way to formally measure how fast a program or algorithm works, which is a very pragmatic goal. Let's start with a little motivation on this topic.
Motivation
We already know that there are tools that measure how fast the code works. These are programs called profilers , which determine the execution time in milliseconds, helping us to identify bottlenecks and optimize them. But, although it is a useful tool, it is not related to the complexity of the algorithms. The complexity of the algorithm is that it is based on comparing the two algorithms at an ideal level, ignoring low-level details such as the implementation of a programming language, the hardware on which the program is running, or the instruction set in a given CPU. We want to compare the algorithms in terms of what they actually are: ideas, how the calculation happens. Counting the milliseconds will be of little help here. It may well turn out that a bad algorithm written in a low-level language (for example, assembly language ) will be much faster than a good algorithm written in a high-level programming language (for example, Python or Ruby ). So it's time to decide what the “best algorithm” really is.
An algorithm is a program that is exclusively a calculation, without other things that are often performed by a computer — network tasks or user input / output. Analysis of complexity allows us to find out how fast this program is when it performs calculations. Examples of purely computational operations can be operations on floating-point numbers (addition and multiplication), searching for a given value from a database located in RAM, and determining by game artificial intelligence (AI) movement of your character so that it moves only a short distance inside the game. world, or launching a regular expression pattern against a string. Obviously, computing is found everywhere in computer programs.
The complexity analysis also allows us to explain how the algorithm will behave as the input data stream increases. If our algorithm runs for one second with 1000 entries, how does it behave, if we double this value? Will it also work fast, one and a half times faster or four times slower? In programming practice, such predictions are extremely important. For example, if we created an algorithm for a web application that works with thousands of users, and measured its execution time, then using complexity analysis, we will get a very good idea of what will happen when the number of users rises to two thousand. For competitions on the construction of algorithms, the analysis of complexity will also give us an understanding of how long our code will run on the largest of the tests to verify its correctness. So, if we define the general behavior of our program on a small amount of input data, we can get a good idea of what will happen to it with large data streams. Let's start with a simple example: finding the maximum element in an array.
Counting instructions
In this article, I will use various programming languages to implement the examples. Do not worry if you are not familiar with any of them - anyone who can program can read this code without any problems, because it is simple and I’m not going to use any exotic baubles of the implementation language. If you are an academic student, then most likely write in C ++ , so you should have no problems either. In this case, I also recommend working out the exercises using C ++ for more practice.
The maximum array element can be found using the simplest code snippet. For example, such, written in Javascript . Given an input array
n : var M = A[ 0 ]; for ( var i = 0; i < n; ++i ) { if ( A[ i ] >= M ) { M = A[ i ]; } } First, let's calculate how many fundamental instructions are calculated here. We will do it only once - as we go deeper into theory, such a need will disappear. But for now, have patience for the time we spend on it. In the process of analyzing this code, it makes sense to break it into simple instructions - tasks that can be performed by the processor immediately or close to it. Suppose that our processor is able to perform the following operations as a single instruction:
- Assign variable value
- Find the value of a specific element in the array
- Compare two values
- Increment value
- Basic arithmetic operations (for example, addition and multiplication)
We will assume that the branching (the choice between
if and else parts of the code after calculating if -conditions) occurs instantly, and we will not take this instruction into account when calculating. For the first line in the code above: var M = A[ 0 ]; Two instructions are required: to search for
A[0] and to assign a value to M (we assume that n always at least 1). These two instructions will be required by the algorithm, regardless of the value of n . Initializing the for loop will also occur all the time, which gives us two more commands: assignment and comparison. i = 0; i < n; All this happens before the first run of
for . After each new iteration, we will have two more instructions: the increment i and the comparison to check if it is time for us to stop the cycle. ++i; i < n; Thus, if we ignore the contents of the loop body, then the number of instructions in this algorithm is
4 + 2n - four at the beginning of the for loop and two for each iteration, which we have n pieces. Now we can define a mathematical function f(n) such that, knowing n , we will know the number of instructions required by the algorithm. For a for loop with an empty body, f( n ) = 4 + 2n .Analysis of the most unfavorable case
In the body of the loop, we have search operations in the array and comparisons that always occur:
if ( A[ i ] >= M ) { ... But the
if body may or may not start, depending on the actual value from the array. If it happens that A[ i ] >= M , then we will run two additional commands: search in the array and assignment: M = A[ i ] We can no longer determine
f(n) so easily, because now the number of instructions depends not only on n , but also on specific input values. For example, for A = [ 1, 2, 3, 4 ] program will require more commands than for A = [4, 3, 2, 1]. When we analyze algorithms, we most often consider the worst case scenario. What will it be in our case? When will the algorithm require the most instructions to complete? Answer: when the array is ordered in ascending order, such as A = [ 1, 2, 3, 4 ] . Then M will be reassigned each time, which will give the most commands. Theorists have for this a bizarre name - analysis of the most unfavorable case , which is nothing more than a simple consideration of the most unfortunate option. Thus, in the worst case, four instructions are run from our code in the loop body, and we have f( n ) = 4 + 2n + 4n = 6n + 4 .Asymptotic behavior
With the function obtained above, we have a very good idea of how fast our algorithm is. However, as I promised, we do not need to constantly engage in such a tedious task, like counting commands in a program. Moreover, the number of instructions for a particular processor required to implement each position of the programming language used depends on the compiler of this language and the set of commands available to the processor (AMD or Intel Pentium on a personal computer, MIPS on Playstation 2, etc.). Earlier we said that we were going to ignore conditions of this kind. Therefore, we will now skip our function
f through a “filter” to clean it of minor details that theorists prefer to ignore.Our function
6n + 4 consists of two elements: 6n and 4 . When analyzing complexity, only what happens with the function of counting instructions with a significant increase in n important. This coincides with the previous idea of the “worst scenario”: we are interested in the behavior of an algorithm that is in “bad conditions” when it is forced to perform something difficult. Notice that this is really useful when comparing algorithms. If one of them beats the other with a large input data stream, then it is likely that it will remain faster and on light, small streams. That is why we discard those elements of the function that increase as n grows slowly, and leave only those that grow strongly . Obviously, 4 will remain 4, regardless of the value of n , and 6n contrary will grow. Therefore, the first thing we will do is drop 4 and leave only f( n ) = 6n .It makes sense to think of 4 simply as an “initialization constant”. Different programming languages may require different time settings. For example, Java first needs to initialize its virtual machine . And since we agreed to ignore the differences in programming languages, we simply discard this value.
The second thing you can ignore is a factor in front of
n . So our function turns into f( n ) = n . As you can see, this simplifies a lot. Once again, it makes sense to discard the constant multiplier if we think about the differences in compile time for different programming languages (PL). “Searching in an array” for one PL can be compiled completely differently than for another. For example, in C, performing A[ i ] does not include checking that i does not go beyond the declared size of the array, while for Pascal it exists. Thus, this Pascal code: M := A[ i ] equivalent to the following in C:
if ( i >= 0 && i < n ) { M = A[ i ]; } So it makes sense to expect that different programming languages will be influenced by various factors that will affect the counting of instructions. In our example, where we use the “dumb” Pascal compiler, ignoring optimization possibilities, we need three instructions in Pascal for each access to an array element instead of one in C. Neglect of this factor goes in line with the neglect of the differences between specific programming languages with a focus on analyzing the very idea of the algorithm itself.
The filters described above - “discard all factors” and “leave only the largest element” - together give what we call asymptotic behavior . For
f( n ) = 2n + 8 it will be described by the function f( n ) = n . Speaking in the language of mathematics, we are interested in the limit of the function f as n tends to infinity. If you do not quite understand the meaning of this formal phrase, then do not worry - you already know everything you need. (Aside: strictly speaking, in the mathematical formulation we could not reject constants in the limit, but for the purposes of theoretical informatics we act this way for the reasons described above). Let's work on a couple of tasks in order to fully understand this concept.We find the asymptotics for the following examples, using the principles of discarding constant factors and leaving only the fastest growing element:
f( n ) = 5n + 12givesf( n ) = n.
The bases are the same as those described above.f( n ) = 109will givef( n ) = 1.
We drop the factor to109 * 1, but 1 is still needed to show that the function is non-zero.f( n ) = n2+ 3n + 112will givef( n ) = n2
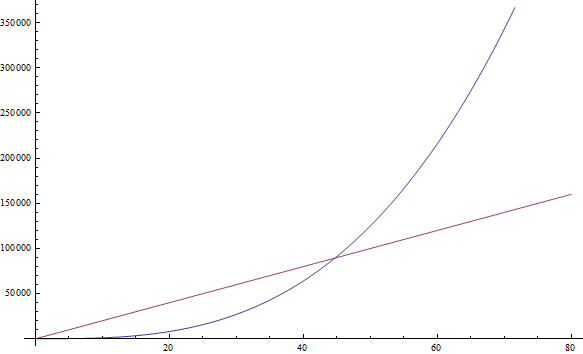
Heren2 increases faster than3n, which, in turn, grows faster112f( n ) = n3+ 1999n + 1337will givef( n ) = n3
Despite the large magnitude of the factor beforen, we still believe that we can find an even largern, thereforef( n ) = n3 is still more than1999n(see the figure above)f( n ) = n + sqrt( n )will givef( n ) = n
Becausenincreasing the argument grows faster thansqrt( n )
Exercise 1
If you have problems with performing this task, then just substitute a large enough
- f (n) = n 6 + 3n
- f (n) = 2 n + 12
- f (n) = 3 n + 2 n
- f (n) = n n + n
If you have problems with performing this task, then just substitute a large enough
n into the expression and see which of its members has the most value. It's very simple, isn't it?Source: https://habr.com/ru/post/196560/
All Articles