Oracle DBMS data clustering outside the cluster table
Oracle cluster is dead, long live clustering!
Here and further we mean cluster data storage, but not Oracle Real Application Custer
Problematics
Large information systems tend to the constant flow of various information that is accumulated, calculated and archived. We will consider a variant of the structured data stored on the Oracle RDBMS server and, as an example, take a table containing CDR records (i.e. call records) for telecom operator subscribers.
Call data is received erratically, i.e. not ordered, as you understand, by the attributes of subscribers. All data has its own life cycle - operational, current and archived. Over time, the frequency of calls and requirements for data access speeds change (ie, they fall). So Year-old recordings can be stored on slow disks, active records on disks with high access speed and no complaints about the performance of write operations, but the newly received data is subject to the requirement for the highest writing and reading speed.
Consider the option of storing data in a clustered table.
The data is consolidated by common grounds. You can place one or several tables in a cluster built on the basis of the subscriber ID, and when accessing data by one ID, all data on this subscriber will be stored in the same place with an accuracy of the cluster chunk size. Those. if all data is stored in 2 chunks that are located in 2 database blocks, then to get 100 data lines for the specified user, it will be enough to subtract only 2 database blocks. If the data were spread over the table, then we could read 100 database blocks to get the same 100 rows. The gain at the data access level is obvious.
Cluster storage can be attributed to the following characteristics:
- The data is consolidated by common grounds.
- Disk IO is minimized when accessing by cluster key.
- Disk IO is minimized with join over a cluster key when tables are stored together.
- It is characterized by high Disk IO when filling.
- Not very friendly with Parallel DML - high level of serialization.
Consider the option of storing data in a regular table.
- Data is usually stored in order of receipt.
- Characterized by a high filling rate.
- Friendly to Parallel DML.
- As the amount of data grows, the degradation of the insertion rate due to indexes may begin.
- With a highly selective sample (by index), high DiskIO is observed.
')
Requirements for data organization
In general, the customer expects the following characteristics from the proper organization of the data:
- High speed DML and insert in particular.
- High sampling rate.
- Good scalability.
- Easy to administer.
Data partitioning
One way to increase storage efficiency is to use the partitioning option (Oracle Partitioning Option).
- Breakdown in length (reducing the time degradation of the performance of the insert).
- Broken down (increased scalability).
- Ability to manage each segment separately.
- High performance Parallel operations on segmented objects.
For example, when broken down into segments in width, expectations for index segments are reduced compared to a regular table with an increase in the number of competitive DML operations on this object.
Suppose that two EQ tables are segmented by some identifier by hash (N). With EQ Partition Join operations on this identifier, the HASH JOIN operation will be performed not at the table level, but at the section level with the same hash value. This will significantly reduce the time required to perform the specified operation on a given amount of data.
I would also like to give partitioned tables the efficiency of a data access cluster ...
Data clustering
The best way to get a table to give data with cluster efficiency is to organize it in the same way as in a cluster.
Imagine that your data is broken down by arrival date (one section per period) and hash is partitioned in width by subscriber ID. All indices are local. Data is received sequentially (by date) and randomly by subscriber ID.
The main section allows you to use Partition Pruning for requests for a period and includes in the sample only those sections that contain data for the specified period, and the additional segmentation by hash from the subscriber ID allows you to select only those sections that contain data for the specified subscriber. But then the data is spread over the section and to receive, for example, 100 records per subscriber per day, we will perform 100 disk read operations.
However, there is one “BUT”: the day has passed and the data for yesterday can still be received, but the day before yesterday is unlikely. Thus, you can do this:
- Create a table with the same set of fields as our segmented table with the same principle of hash segmentation as on our table, like:
create table TBL1 as select * from table %TBL% partition(P1) order by subscriber_id, record_date... - Create the same indexes as in the section of the table.
- Perform operation
alter table %TBL% exchange partition P1 with table TBL1
PS> You can automate this process using the dbms_redefinition package.
It seems that everything looks simple, but what, you ask, is the effect? ..
Next, we consider four cases:
- Data not reorganized.
- Produced rebuild indexes.
- Reorganization done.
- Produced reorganization with data compression.
High Phisical IO Clustering
So, if you simultaneously run about a hundred processes that access data by random subscriber identifiers for a specified period, the average performance of one process — depending on the organization of the data — will vary as follows:
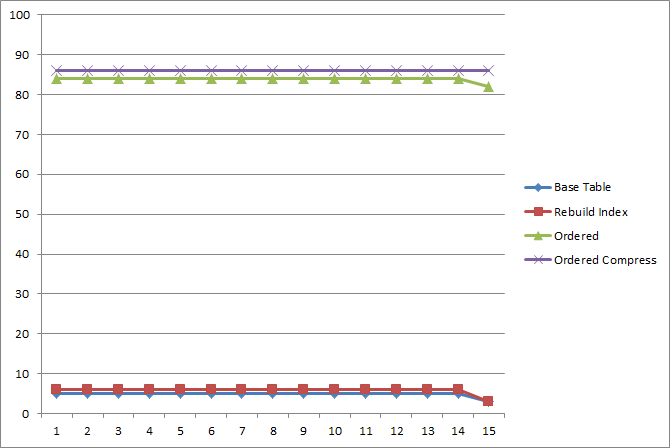
Those. we achieved performance gains on Disk IO by an order of magnitude for data with characteristics of about 13–19 records per client over a period of one section.
Below are data on I / O expectations and response times:
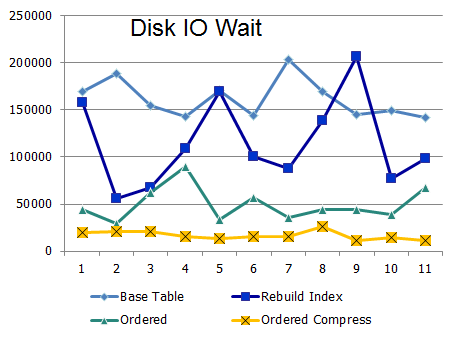

Clustering with High Logical IO
Imagine now that we have access to data that is located in the memory of the Oracle server, and not read from the disk. What will be (and whether) the gain with such an organization when only Logical IO is used.
Process performance (req / sec):
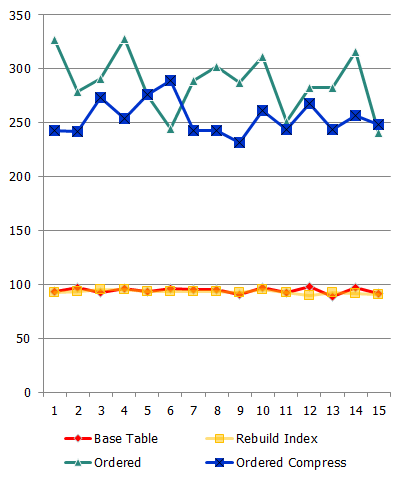
waiting time:
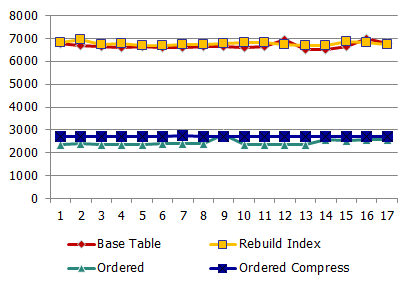
and response time:
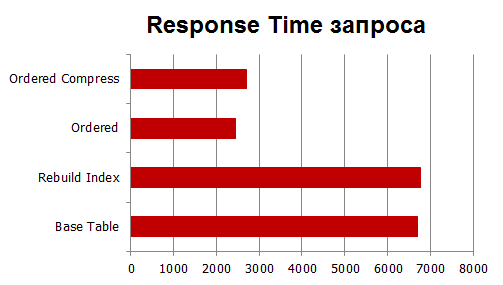
As we can see, the increase is less than with Phisical IO, but anyway the increase occurs at times.
Volume Management
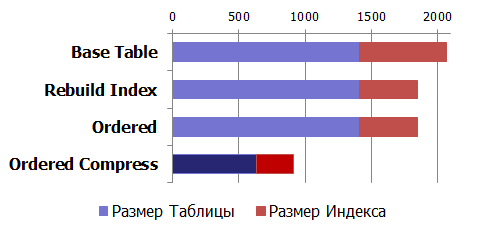
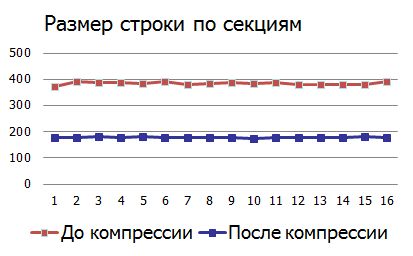
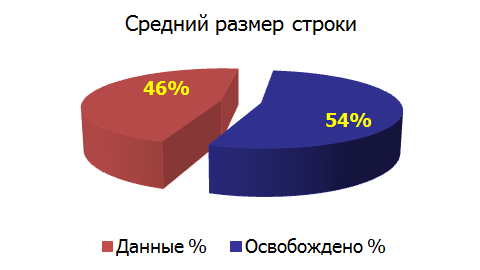
Even a normal rebuild index operation gives a reduction in its volume. What happens to the amount of disk space during the reorganization of data, as well as the use of compression?
Effect of compression (compression):

Conclusion
Given the specificity of the data structure of a specific information system through the reorganization of data, you can achieve:
- Improve the performance of individual operations.
- Improve the performance of the entire system due to the released resource.
- Reducing the amount of resources consumed, i.e. cost savings on solution costs.
- ...
PS> It may seem that reorganizing a large amount of data is a very expensive operation. This, of course, yes, but in the end, the volume of I / O operations can be reduced. Using the example of customer data, I can say that referring to a table being reorganized in this way only by the self-service system (which is less than half the load on the table) in less than an hour created I / O to the table more than the size of all its sections per day. So the game can cost a candle, although it creates additional work for the DBA.
Source: https://habr.com/ru/post/196420/
All Articles