Introduction to the analysis of the complexity of algorithms (part 4)
From the translator: this text is given with insignificant abbreviations due to places of excessive “razvezhnannosti” material. The author absolutely rightly warns that certain topics may seem too simple or well-known to the reader. Nevertheless, personally this text helped me to streamline the existing knowledge on the analysis of the complexity of algorithms. I hope that it will be useful to someone else.
Due to the large volume of the original article, I broke it into pieces, which in total will be four.
I (as always) would be extremely grateful for any comments in PM about improving the quality of the translation.
Published previously:
Part 1
Part 2
Part 3
Congratulations! Now you know how to analyze the complexity of the algorithms, what is the asymptotic estimate and the notation “big-O”. You also know how intuitively to find out whether the complexity of the algorithm is
')
This final section is optional. It is somewhat more complicated, so you can feel free to skip it if you want. You will need to focus and spend some time on solving the exercises. However, a very useful and powerful method for analyzing the complexity of algorithms will also be demonstrated here, which is certainly worth a look.
We looked at the implementation of sorting, called sorting by choice, and mentioning that it is not optimal. The optimal algorithm is the one that solves the problem in the best way, meaning that there is no algorithm that does it better. Those. all other algorithms for solving this problem are of the same or greater complexity. There may be a mass of optimal algorithms having the same complexity. The same sorting problem can be solved optimally in many ways. For example, we can use the same idea for quick sorting as in a binary search. This method is called merge sorting .
Before implementing the merge sort itself, we need to write an auxiliary function. Let's call it
The
Analysis of this algorithm shows that its execution time is
Using this function, we can build the best sorting algorithm. The idea is as follows: we divide the array into two parts, recursively sort each of them and combine the two sorted arrays into one. Pseudocode:
This function is harder to understand than the previous ones, so the following exercise may take longer.
As a final exercise, let's analyze the complexity of the
So, we have broken the original array into two parts, each
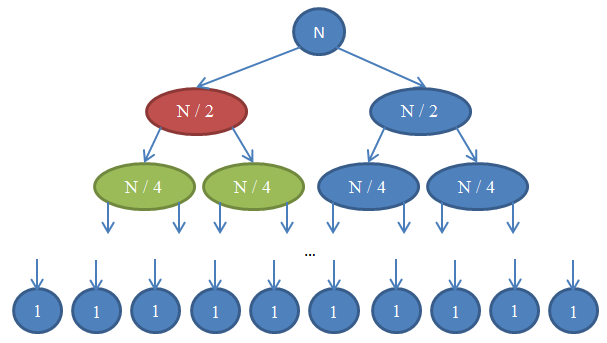
Let's see what happens here. Each circle is a call to the function
Note that the number of elements in each row remains
As a result, the complexity of each line is
As you saw in the last example, complexity analysis allows us to compare algorithms in order to understand which one is better. Based on these considerations, we can now be sure that for arrays of large sizes, merge sorting will be much faster than sorting by choice. Such a conclusion would be problematic if we did not have the theoretical basis for the analysis of the algorithms we developed. Undoubtedly, sorting algorithms with the execution time
After studying this article, your intuition about analyzing the complexity of algorithms will help you to create fast programs and focus optimization efforts on those things that really have a big impact on the speed of execution. All together will allow you to work more productively. In addition, the mathematical language and notations (for example, “big O”) discussed in this article will be useful to you when communicating with other software developers when it comes to the execution time of the algorithms, and I hope you can put into practice knowledge.
The article is published under Creative Commons 3.0 Attribution . This means that you can copy it, publish it on your websites, make changes to the text and generally do whatever you want with it. Just do not forget to mention while my name. The only thing is: if you base your work on this text, then I urge you to publish it under Creative Commons in order to facilitate collaboration and distribution of information.
Thank you for reading to the end!
Due to the large volume of the original article, I broke it into pieces, which in total will be four.
I (as always) would be extremely grateful for any comments in PM about improving the quality of the translation.
Published previously:
Part 1
Part 2
Part 3
Optimal sorting
Congratulations! Now you know how to analyze the complexity of the algorithms, what is the asymptotic estimate and the notation “big-O”. You also know how intuitively to find out whether the complexity of the algorithm is
O( 1 ) , O( log( n ) ) , O( n ) , O( n 2 ) and so on. You are familiar with the symbols o , O , ω , Ω , Θ and the concept of "worst case". If you get to this place, then my article has already completed its task.')
This final section is optional. It is somewhat more complicated, so you can feel free to skip it if you want. You will need to focus and spend some time on solving the exercises. However, a very useful and powerful method for analyzing the complexity of algorithms will also be demonstrated here, which is certainly worth a look.
We looked at the implementation of sorting, called sorting by choice, and mentioning that it is not optimal. The optimal algorithm is the one that solves the problem in the best way, meaning that there is no algorithm that does it better. Those. all other algorithms for solving this problem are of the same or greater complexity. There may be a mass of optimal algorithms having the same complexity. The same sorting problem can be solved optimally in many ways. For example, we can use the same idea for quick sorting as in a binary search. This method is called merge sorting .
Before implementing the merge sort itself, we need to write an auxiliary function. Let's call it
merge , and let it take two already sorted arrays and connect them into one (also sorted). This is easy to do: def merge( A, B ): if empty( A ): return B if empty( B ): return A if A[ 0 ] < B[ 0 ]: return concat( A[ 0 ], merge( A[ 1...A_n ], B ) ) else: return concat( B[ 0 ], merge( A, B[ 1...B_n ] ) ) The
concat function takes an element (“head”) and an array (“tail”) and connects them, returning a new array with a “head” as the first element and a “tail” as the remaining elements. For example, concat( 3, [ 4, 5, 6 ] ) returns [ 3, 4, 5, 6 ] . We use A_n and B_n to denote the sizes of arrays A and B respectively.Exercise 8
Make sure that the function above really merges. Rewrite it in your favorite programming language, using iterations (for loop) instead of recursion.
Analysis of this algorithm shows that its execution time is
Θ( n ) , where n is the length of the resulting array ( n = A_n + B_n ).Exercise 9
Verify that the
merge is Θ( n ) .Using this function, we can build the best sorting algorithm. The idea is as follows: we divide the array into two parts, recursively sort each of them and combine the two sorted arrays into one. Pseudocode:
def mergeSort( A, n ): if n = 1: return A # it is already sorted middle = floor( n / 2 ) leftHalf = A[ 1...middle ] rightHalf = A[ ( middle + 1 )...n ] return merge( mergeSort( leftHalf, middle ), mergeSort( rightHalf, n - middle ) ) This function is harder to understand than the previous ones, so the following exercise may take longer.
Exercise 10
Make sure that
mergeSort correct (i.e., check that it correctly sorts the array passed to it). If you cannot understand why it works in principle, then manually fill in a small example. Do not forget to make sure that leftHalf and rightHalf are obtained by splitting an array approximately in half. A partition does not have to be exactly in the middle if, for example, an array contains an odd number of elements (this is why we need the floor function).As a final exercise, let's analyze the complexity of the
mergeSort . At each step, we split the source array into two equal parts (like binarySearch ). However, in this case, further calculations occur on both sides. After the recursion is returned, we apply the operation merge to the results, which takes Θ( n ) time.So, we have broken the original array into two parts, each
n / 2 . When we connect them, n elements will be involved in the operation, therefore, the execution time will be Θ( n ) . The figure below explains this recursion:Let's see what happens here. Each circle is a call to the function
mergeSort . The number in the circle shows the number of elements in the array to be sorted. The top blue circle is the initial mergeSort call for an array of size n . The arrows show recursive calls between functions. The original call mergeSort spawns two new for arrays, size n / 2 each. In turn, each of them generates two more calls with arrays in n / 4 elements, and so on until we get an array of size 1. This diagram is called a recursive tree , because it illustrates the work of recursion and looks like a tree ( more precisely, as inversion of a tree with a root above and leaves below).Note that the number of elements in each row remains
n . Also note that each calling node uses results from the called nodes for the merge operation. For example, the red node sorts n / 2 items. To do this, it splits the n / 2 array into two by n / 4 , recursively calls the mergeSort (green nodes) with each of them, and combines the results into a single entity of size n / 2 .As a result, the complexity of each line is
Θ( n ) . We know that the number of such lines, called the depth of the recursive tree, will be log( n ) . The reason for this is the same arguments that we used for the binary search. So, we have log( n ) rows with complexity Θ( n ) , therefore, the total complexity of mergeSort : Θ( n * log( n ) ) . This is much better than Θ( n 2 ) , which sorting gives us a choice (remember, log( n ) much less than n , therefore n * log( n ) is also much less than n * n = n 2 ).As you saw in the last example, complexity analysis allows us to compare algorithms in order to understand which one is better. Based on these considerations, we can now be sure that for arrays of large sizes, merge sorting will be much faster than sorting by choice. Such a conclusion would be problematic if we did not have the theoretical basis for the analysis of the algorithms we developed. Undoubtedly, sorting algorithms with the execution time
Θ( n * log( n ) ) are widely used in practice. For example, the Linux kernel uses an algorithm called "heap sorting" , which has the same execution time as merge sort. Note that we will not prove the optimality of these sorting algorithms. This would have required much more cumbersome mathematical arguments, but be sure: in terms of complexity, it is impossible to find a better option.After studying this article, your intuition about analyzing the complexity of algorithms will help you to create fast programs and focus optimization efforts on those things that really have a big impact on the speed of execution. All together will allow you to work more productively. In addition, the mathematical language and notations (for example, “big O”) discussed in this article will be useful to you when communicating with other software developers when it comes to the execution time of the algorithms, and I hope you can put into practice knowledge.
Instead of conclusion
The article is published under Creative Commons 3.0 Attribution . This means that you can copy it, publish it on your websites, make changes to the text and generally do whatever you want with it. Just do not forget to mention while my name. The only thing is: if you base your work on this text, then I urge you to publish it under Creative Commons in order to facilitate collaboration and distribution of information.
Thank you for reading to the end!
Links
- Cormen, Leiserson, Rivest, Stein. Introduction to Algorithms , MIT Press
- Dasgupta, Papadimitriou, Vazirani. Algorithms , McGraw-Hill Press
- Fotakis. Course of the University of Athens
- Fotakis. Course of Algorithms and Complexity of the National Technical University of Athens
Source: https://habr.com/ru/post/196226/
All Articles