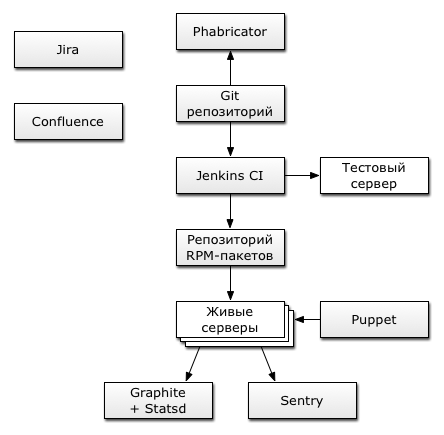
Infrastructure and life cycle of web project development
When the project is small, there are no special problems with it. The task list can be maintained in a text file (TODO), the version control system, by and large, you can not use it, you can simply copy them (cp / scp / rsync) to the desired directory to put the files on a live server, and you can always look at the errors in the log file. It would be foolish, for example, for a simple service with two scripts and three visitors per day to raise a full-fledged server configuration management system.
With the growth of the project requirements are growing. It becomes inconvenient to keep dozens of tasks and bugs in a TODO file: I want priorities, comments, links. There is a need for a version control system, special scripts / systems for code pickup on a server, a monitoring system. The situation is exacerbated when several people work on the project, and when the project grows to several servers, a full-fledged infrastructure appears (“a set of interconnected service structures or objects that make up and / or provide the basis for the functioning of the system”, Wikipedia).
Using the example of our Mail.ru Calendar service, I want to talk about the typical infrastructure and the life cycle of developing a medium-sized web project in a large Internet company.
Any work begins with the formulation of the problem, whether it is a planned feature or an error message.
')
As the “Issue & project tracking” system, we, at Mail.ru, use Atlassian Jira , which is the de facto standard among large organizations. This is not a complete list of companies using Jira: ru.wikipedia.org/wiki/Atlassian_JIRA . The functionality, flexibility, extensibility and usability of this system are unequal, and I don’t see an alternative, although according to my information, some of the largest IT companies with thousands of employees successfully (according to their assertions) use Bugzilla as a bugtracker.
For small teams and projects it is more expedient to use less sophisticated and more free counterparts like the same Bugzilla , Phabricator or Redmine . Alternatively, in the case of hosting projects ( GitHub , BitBucket and others), you can use the bug tracking systems built into them.
After the task has been assigned by the manager, testing specialist, or customer support service, the developer starts working on it. All project code is in the repository.
To date, the most common version control systems are Git and Mercurial . Both have, by and large, a similar functionality (distributed systems), although they differ in details. Almost all Mail.ru projects have switched to Git (some with SVN, some with CVS), and Calendar is no exception.
Our company has several large and powerful servers that have gitosis installed for hosting git repositories. Different repositories have different settings, for example, developers will not be able to push Python code into the calendar repository, which does not meet the PEP8 standards (this is followed by a special server hook).
All Calendar code (frontend and backend) is stored in one repository. For a small and medium project, this allows you to quickly deploy the entire project entirely and easily track any changes in the code. For large and very large projects (such as Mail.ru Mail), it seems more convenient to store client and server code in separate repositories (or even several), although, of course, any approach requires a sensible and reasoned decision.
In order to develop a project, you must first run it, for this you need to have the appropriate software and libraries.
It is said that every safety rule is written in blood. In IT companies this, of course, does not reach, but there are strict rules, nonetheless. For example, in Mail.ru, only system administrators have access to "combat" servers and data from real users. Developers have access to only test machines with test users, which are not related to “live” in any way, and all development is carried out only in the test network. This separation of duties eliminates the most "intelligent" programmers from the temptation to do something "quick fix on the living" and makes them write the code more thoughtfully and efficiently.
There are systems that are very difficult, and sometimes impossible to run on one machine, for example, Mail.Ru Mail: to complete the work, it requires a huge number of libraries, demons, scripts and services. Such projects are launched on several (dozens) virtual servers in the test network, and the developers work with the code running on these machines (vim, emacs, diff, that's all).
We were lucky in the Calendar: the whole project is fairly easy to run on the local developer’s machine and there are no problems with the development. You can use your favorite editors, IDE and debuggers without tricks, each programmer works with his code and does not affect the work of others. Of course, we also have virtual servers in the development network, but they are mainly used for testing. Even more facilitating the work is the fact that everyone in the Calendar prefers to use the MacBook in their work, so the development environment is almost the same for the team members.
The server part of the calendar is written in Python, and, of course, we use virtualenv when developing and deploying the system, so to install all the libraries you just need to run the command
from the cloned repository. The client (front-end) part uses npm and all dependencies are installed just as easily and naturally.
All the necessary software on the Mac is installed from brew , and for the initial installation of the project on the developer’s computer, it’s enough to run
with a list of dependencies. Of course, one command is not enough and further configuration is required, for example, the initialization of the user and the database in PostgreSQL. There are some features in installing individual programs (for example, we use patched nginx with our modules), but this does not cause any problems, because everything is described in the documentation system (wiki).
Knowledge is power. Knowledge is worth sharing with your colleagues, they need to be recorded in order not to forget yourself. The ideal place to store information is wiki-systems, and in Mail.ru we use Atlassian Confluence as such. I do not see any particular advantages over other wiki-systems with Confluence (their functionality, in fact, is similar), but it so happened that Atlassian products got accustomed to our company and is popular. Although there is one virtue: the products of one company are easy to integrate with each other, and in any large company all internal services are somehow connected with each other.
We try to document everything related to the development and operation process: how to install this or that software, what configuration is required, what problems you may encounter, on which servers, which services are running and how they communicate with each other.
Any product needs quality control and our Calendar is no exception.
Each developer is faced with errors in the code. The first step in the fight for quality is code review, this allows you to notice any flaws in the program in time. Another advantage of code auditing is acquaintance with each commit of at least two programmers: the one who wrote the code and the one who reviewed it (respectively, the responsibility is also divided in half).
Atlassian for code review has a smart tool called Crucible , but historically, we use Phabricator in the Calendar: an open-source development from Facebook. The manufacturer has many opportunities, but we use only a part of them, namely, auditing, commenting on the code and viewing the repository online.
After correction of colleagues' comments, the code passes to the next stages of quality control.
Beautiful code is a good code. Following the code-style rules by all team members allows you to look at any place of the program at a glance, and also allows you to avoid the vast majority of stupid mistakes. Each push to the calendar repository is checked using PEP8 , pyflake and pylint .
Good code is working code. We love when our programs work, and we don’t like when they are broken. Smart people have come up with different types of testing (unit tests, functional, regression testing), and we are happy to use these developments.
To run various tasks, we use the open-source Jenkins CI (Continuous Integration) system, which has three tasks for the calendar:
All tasks are started when the corresponding branch is clicked on the hook in the git repository.
Automatic testing is good, but the human mind and ingenuity cannot be replaced by a soulless machine. Live testers come to the rescue. Each release (and the release of the Calendar project takes place, on average, once every two weeks) is checked on the pre-release server by our testers. They pay special attention to the new functionality, which was implemented over the past week, as well as to test the critical functionality of the project.
The output is one (or several, depending on the project) RPM file, which contains the entire project completely, with virtualenv, all the necessary dependencies (libraries) and files (statics).
The release is assembled, tested, tested and ready for display on combat vehicles, which only system administrators have access to.
Admins are smart and lazy people. If you often have to do routine operations, then why not automate them?
Mail.ru has many thousands of servers, each has its own role and its own settings. We use Puppet to manage server configurations. Settings for each server group are described in simple files that are in the version control system. Thus, there is always a history of changes in configuration files with the ability to roll back to any of the previous states. Only system administrators have access to repositories and the pappet in general.
The process of laying out the new iteration on live servers looks like this: admins, if necessary, edit the project configuration files, prescribe the necessary versions of RPM packages and push changes to the repository. Then Puppet takes care of everything: all configuration files on all servers will be updated, packages are installed and the necessary services are restarted.
The code is decomposed into production, it would seem, you can relax and unwind, but this should not be done. Testers, of course, are extremely clever and resourceful and sometimes find such errors that the developers didn’t even suspect, but real users will give a hundred points of handicap to any tester. You need to be able to monitor the status of the project.
First of all, we are interested in the so-called "five hundred", that is, critical errors on the server. If they are (and they are, there is no way out of it), then something went wrong and you need to urgently prepare bug fixes. How to catch such errors? You can, of course, write everything to the log, and then with a simple “grep” (by searching the log file) we will always be aware of the number and type of errors, but there is a better option.
The logging system in the Calendar is configured in such a way as to send all errors, exceptions and simply varnings to a special system called Sentry . In it, we see not only statistics on errors (when, which errors and how many times have occurred), but also detailed information about these errors: a full traceback (order of function calls) with the value of all variables in the context of each function. There is also information about the user (email, OS, browser) and request (url, headers, GET and POST parameters). All browser errors also fall into Sentry, although the information is not so detailed (JavaScript, nothing can be done). All this makes it easy to localize problems and correct errors as soon as possible.
Basically, we write various warnings to Sentry. For example, in the process of refactoring, before abandoning any function, we always add warning to it, and only in the absence of messages in Sentry, at the next iteration, this function will be permanently removed from the code. There are, of course, mistakes, and there are a lot of mistakes (“packs”).
Logging is good, but this is not enough, statistics are vital for the project.
Everyone loves statistics. Managers admire it, rejoicing in the increase in the number of hits and users, the developers receive information about the project's “health”. We use Graphite as a system for collecting and storing metrics, as well as StatsD - a server that processes and aggregates incoming metrics, transferring them for storage to all the same graphite.
What are graphics for? As I said, according to the charts, you can always judge the status of the project: the number of redirects suddenly increased, the average request time to the database doubled, or the number of I / O operations on one of the servers increased. All this allows you to detect the problem, and the presence of history (charts are stored for months and years) facilitate the analysis of sudden trouble with the project.
Graphics help refactor. It is enough, for example, to add statistic decorators to the functions that caused questions during profiling and to obtain reliable information about the code behavior under load. After laying out the iteration with edits, you can evaluate their effectiveness, for example, reducing the average operation time of a function ten times (from hundreds to tens and even units of milliseconds) or the number of requests to the database from hundreds (thousands) to units better than any words proves the refactoring.
The server performance graphs (we use Diamond for this) allow us to estimate the load in a timely manner and to order additional machines in advance, or to attend to program performance.
Any project is written not for logs and not for graphs: it is written for people, for our favorite users. And users are sometimes unhappy with the project.
In the Calendar there is a feedback form that people actively use. These are mostly messages about noticed errors, requests for the implementation of one or another functional, or just words of gratitude for our excellent service. These letters go to the customer support service (which uses a special system for working with user letters called OTRS ), and are also duplicated to us, that is, the project developers. This allows you to always be aware of all the problems and respond promptly to them: in difficult cases, we ourselves respond to the people who wrote and together with them solve the difficulties that have arisen.
I remember a funny case when one of the users wrote us a letter asking him to add the necessary functionality to the Calendar (if I’m not mistaken, it was about SMS notifications), and we just finished this task and did it on a live server. Fifteen minutes after the request, the user received the answer that, they say, we did everything as you requested. There was no limit to his surprise.
The process of developing a calendar from scratch lasts just a year and a half, and the calendar’s release took place a little less than a year ago. The project is young, and we, its developers, are constantly improving its infrastructure. I'll tell you a little about our plans for the future.
I would like to try to use Vagrant in the development, it will allow even faster and easier to deploy developer environment. I'd like to try Selenium for automatic testing of the project (web version and mobile clients). For better testing, the new functionality lacks the ability to enable it by criteria, for example, only on company employees or on a certain percentage of users. We want to try the open-source Gargoyle project for this. In the near future, following the example of other Python-projects in our company, our team is going to implement Arcanist : add-on git to work with Phabricator from the command line in the project repository. This will simplify the code-review process and simplify development.
I tried to go through the whole development process, but touched only a small part of it. Development of the project is a difficult process, but thanks to all the resources access to which is possible in a large company, it is very interesting and fascinating. I suggest in the comments to ask questions that interest you, and I will try to answer them.
Vladimir Rudnykh,
Technical Director of the Mail.Ru Calendar.
With the growth of the project requirements are growing. It becomes inconvenient to keep dozens of tasks and bugs in a TODO file: I want priorities, comments, links. There is a need for a version control system, special scripts / systems for code pickup on a server, a monitoring system. The situation is exacerbated when several people work on the project, and when the project grows to several servers, a full-fledged infrastructure appears (“a set of interconnected service structures or objects that make up and / or provide the basis for the functioning of the system”, Wikipedia).
Using the example of our Mail.ru Calendar service, I want to talk about the typical infrastructure and the life cycle of developing a medium-sized web project in a large Internet company.
Any work begins with the formulation of the problem, whether it is a planned feature or an error message.
')
Project and Task Management
As the “Issue & project tracking” system, we, at Mail.ru, use Atlassian Jira , which is the de facto standard among large organizations. This is not a complete list of companies using Jira: ru.wikipedia.org/wiki/Atlassian_JIRA . The functionality, flexibility, extensibility and usability of this system are unequal, and I don’t see an alternative, although according to my information, some of the largest IT companies with thousands of employees successfully (according to their assertions) use Bugzilla as a bugtracker.
For small teams and projects it is more expedient to use less sophisticated and more free counterparts like the same Bugzilla , Phabricator or Redmine . Alternatively, in the case of hosting projects ( GitHub , BitBucket and others), you can use the bug tracking systems built into them.
At the moment, the project “Calendar” in Jira contains 1816 tasks, of which 1386 are successfully closed. About 500 of them were bugs =)
After the task has been assigned by the manager, testing specialist, or customer support service, the developer starts working on it. All project code is in the repository.
Version Control System
To date, the most common version control systems are Git and Mercurial . Both have, by and large, a similar functionality (distributed systems), although they differ in details. Almost all Mail.ru projects have switched to Git (some with SVN, some with CVS), and Calendar is no exception.
Our company has several large and powerful servers that have gitosis installed for hosting git repositories. Different repositories have different settings, for example, developers will not be able to push Python code into the calendar repository, which does not meet the PEP8 standards (this is followed by a special server hook).
All Calendar code (frontend and backend) is stored in one repository. For a small and medium project, this allows you to quickly deploy the entire project entirely and easily track any changes in the code. For large and very large projects (such as Mail.ru Mail), it seems more convenient to store client and server code in separate repositories (or even several), although, of course, any approach requires a sensible and reasoned decision.
To date, we have 7,175 commits in the Calendar repository, and for all the time about 300 branches have been created. The size of the entire project is 60 MB.
In order to develop a project, you must first run it, for this you need to have the appropriate software and libraries.
Development Environment
It is said that every safety rule is written in blood. In IT companies this, of course, does not reach, but there are strict rules, nonetheless. For example, in Mail.ru, only system administrators have access to "combat" servers and data from real users. Developers have access to only test machines with test users, which are not related to “live” in any way, and all development is carried out only in the test network. This separation of duties eliminates the most "intelligent" programmers from the temptation to do something "quick fix on the living" and makes them write the code more thoughtfully and efficiently.
There are systems that are very difficult, and sometimes impossible to run on one machine, for example, Mail.Ru Mail: to complete the work, it requires a huge number of libraries, demons, scripts and services. Such projects are launched on several (dozens) virtual servers in the test network, and the developers work with the code running on these machines (vim, emacs, diff, that's all).
We were lucky in the Calendar: the whole project is fairly easy to run on the local developer’s machine and there are no problems with the development. You can use your favorite editors, IDE and debuggers without tricks, each programmer works with his code and does not affect the work of others. Of course, we also have virtual servers in the development network, but they are mainly used for testing. Even more facilitating the work is the fact that everyone in the Calendar prefers to use the MacBook in their work, so the development environment is almost the same for the team members.
The server part of the calendar is written in Python, and, of course, we use virtualenv when developing and deploying the system, so to install all the libraries you just need to run the command
pip install -r requirements / development.txt
from the cloned repository. The client (front-end) part uses npm and all dependencies are installed just as easily and naturally.
The calendar currently uses 33 third-party Python libraries.
All the necessary software on the Mac is installed from brew , and for the initial installation of the project on the developer’s computer, it’s enough to run
brew install ...
with a list of dependencies. Of course, one command is not enough and further configuration is required, for example, the initialization of the user and the database in PostgreSQL. There are some features in installing individual programs (for example, we use patched nginx with our modules), but this does not cause any problems, because everything is described in the documentation system (wiki).
Project Documentation
Knowledge is power. Knowledge is worth sharing with your colleagues, they need to be recorded in order not to forget yourself. The ideal place to store information is wiki-systems, and in Mail.ru we use Atlassian Confluence as such. I do not see any particular advantages over other wiki-systems with Confluence (their functionality, in fact, is similar), but it so happened that Atlassian products got accustomed to our company and is popular. Although there is one virtue: the products of one company are easy to integrate with each other, and in any large company all internal services are somehow connected with each other.
We try to document everything related to the development and operation process: how to install this or that software, what configuration is required, what problems you may encounter, on which servers, which services are running and how they communicate with each other.
The project Calendar in Confluence has 122 pages of documentation.
Any product needs quality control and our Calendar is no exception.
Code review
Each developer is faced with errors in the code. The first step in the fight for quality is code review, this allows you to notice any flaws in the program in time. Another advantage of code auditing is acquaintance with each commit of at least two programmers: the one who wrote the code and the one who reviewed it (respectively, the responsibility is also divided in half).
Atlassian for code review has a smart tool called Crucible , but historically, we use Phabricator in the Calendar: an open-source development from Facebook. The manufacturer has many opportunities, but we use only a part of them, namely, auditing, commenting on the code and viewing the repository online.
On average, with every audit of a commit, three or four comments appear.
After correction of colleagues' comments, the code passes to the next stages of quality control.
Syntax control and testing
Beautiful code is a good code. Following the code-style rules by all team members allows you to look at any place of the program at a glance, and also allows you to avoid the vast majority of stupid mistakes. Each push to the calendar repository is checked using PEP8 , pyflake and pylint .
There are no exceptions in the calendar from the pep8 and pyflake rules.
Good code is working code. We love when our programs work, and we don’t like when they are broken. Smart people have come up with different types of testing (unit tests, functional, regression testing), and we are happy to use these developments.
To date, we have 580 automatic tests in our project.
To run various tasks, we use the open-source Jenkins CI (Continuous Integration) system, which has three tasks for the calendar:
- for test branches: syntax control (lint) of the code, running all tests, preparing a code coverage report
- for the prerelease branch: syntax control (lint) of the code, running all the tests, building the test package (RPM) of the project and distributing it to our prerelease (test) server
- for the master branch: run tests and build the package (RPM) of the project
All tasks are started when the corresponding branch is clicked on the hook in the git repository.
Build the project lasts, on average, about five minutes.
Automatic testing is good, but the human mind and ingenuity cannot be replaced by a soulless machine. Live testers come to the rescue. Each release (and the release of the Calendar project takes place, on average, once every two weeks) is checked on the pre-release server by our testers. They pay special attention to the new functionality, which was implemented over the past week, as well as to test the critical functionality of the project.
The output is one (or several, depending on the project) RPM file, which contains the entire project completely, with virtualenv, all the necessary dependencies (libraries) and files (statics).
The release is assembled, tested, tested and ready for display on combat vehicles, which only system administrators have access to.
The layout of the project into battle
Admins are smart and lazy people. If you often have to do routine operations, then why not automate them?
Mail.ru has many thousands of servers, each has its own role and its own settings. We use Puppet to manage server configurations. Settings for each server group are described in simple files that are in the version control system. Thus, there is always a history of changes in configuration files with the ability to roll back to any of the previous states. Only system administrators have access to repositories and the pappet in general.
The process of laying out the new iteration on live servers looks like this: admins, if necessary, edit the project configuration files, prescribe the necessary versions of RPM packages and push changes to the repository. Then Puppet takes care of everything: all configuration files on all servers will be updated, packages are installed and the necessary services are restarted.
The layout of the project takes about one minute.
The code is decomposed into production, it would seem, you can relax and unwind, but this should not be done. Testers, of course, are extremely clever and resourceful and sometimes find such errors that the developers didn’t even suspect, but real users will give a hundred points of handicap to any tester. You need to be able to monitor the status of the project.
Error logging
First of all, we are interested in the so-called "five hundred", that is, critical errors on the server. If they are (and they are, there is no way out of it), then something went wrong and you need to urgently prepare bug fixes. How to catch such errors? You can, of course, write everything to the log, and then with a simple “grep” (by searching the log file) we will always be aware of the number and type of errors, but there is a better option.
The logging system in the Calendar is configured in such a way as to send all errors, exceptions and simply varnings to a special system called Sentry . In it, we see not only statistics on errors (when, which errors and how many times have occurred), but also detailed information about these errors: a full traceback (order of function calls) with the value of all variables in the context of each function. There is also information about the user (email, OS, browser) and request (url, headers, GET and POST parameters). All browser errors also fall into Sentry, although the information is not so detailed (JavaScript, nothing can be done). All this makes it easy to localize problems and correct errors as soon as possible.
Basically, we write various warnings to Sentry. For example, in the process of refactoring, before abandoning any function, we always add warning to it, and only in the absence of messages in Sentry, at the next iteration, this function will be permanently removed from the code. There are, of course, mistakes, and there are a lot of mistakes (“packs”).
The Sentry of the Calendar gets, on average, about 100 messages per hour. Sentry withstands thousands of errors per minute (tested in practice =).
Logging is good, but this is not enough, statistics are vital for the project.
Statistics and graphs
Everyone loves statistics. Managers admire it, rejoicing in the increase in the number of hits and users, the developers receive information about the project's “health”. We use Graphite as a system for collecting and storing metrics, as well as StatsD - a server that processes and aggregates incoming metrics, transferring them for storage to all the same graphite.
What are graphics for? As I said, according to the charts, you can always judge the status of the project: the number of redirects suddenly increased, the average request time to the database doubled, or the number of I / O operations on one of the servers increased. All this allows you to detect the problem, and the presence of history (charts are stored for months and years) facilitate the analysis of sudden trouble with the project.
Graphics help refactor. It is enough, for example, to add statistic decorators to the functions that caused questions during profiling and to obtain reliable information about the code behavior under load. After laying out the iteration with edits, you can evaluate their effectiveness, for example, reducing the average operation time of a function ten times (from hundreds to tens and even units of milliseconds) or the number of requests to the database from hundreds (thousands) to units better than any words proves the refactoring.
The server performance graphs (we use Diamond for this) allow us to estimate the load in a timely manner and to order additional machines in advance, or to attend to program performance.
Every minute about 25 thousand different metrics are written into the graphite of the Calendar.
Any project is written not for logs and not for graphs: it is written for people, for our favorite users. And users are sometimes unhappy with the project.
Communication with users
In the Calendar there is a feedback form that people actively use. These are mostly messages about noticed errors, requests for the implementation of one or another functional, or just words of gratitude for our excellent service. These letters go to the customer support service (which uses a special system for working with user letters called OTRS ), and are also duplicated to us, that is, the project developers. This allows you to always be aware of all the problems and respond promptly to them: in difficult cases, we ourselves respond to the people who wrote and together with them solve the difficulties that have arisen.
I remember a funny case when one of the users wrote us a letter asking him to add the necessary functionality to the Calendar (if I’m not mistaken, it was about SMS notifications), and we just finished this task and did it on a live server. Fifteen minutes after the request, the user received the answer that, they say, we did everything as you requested. There was no limit to his surprise.
We get about ten messages a day. Half of them are thanks and positive feedback.
Instead of an afterword
The process of developing a calendar from scratch lasts just a year and a half, and the calendar’s release took place a little less than a year ago. The project is young, and we, its developers, are constantly improving its infrastructure. I'll tell you a little about our plans for the future.
I would like to try to use Vagrant in the development, it will allow even faster and easier to deploy developer environment. I'd like to try Selenium for automatic testing of the project (web version and mobile clients). For better testing, the new functionality lacks the ability to enable it by criteria, for example, only on company employees or on a certain percentage of users. We want to try the open-source Gargoyle project for this. In the near future, following the example of other Python-projects in our company, our team is going to implement Arcanist : add-on git to work with Phabricator from the command line in the project repository. This will simplify the code-review process and simplify development.
I tried to go through the whole development process, but touched only a small part of it. Development of the project is a difficult process, but thanks to all the resources access to which is possible in a large company, it is very interesting and fascinating. I suggest in the comments to ask questions that interest you, and I will try to answer them.
Vladimir Rudnykh,
Technical Director of the Mail.Ru Calendar.
Source: https://habr.com/ru/post/196184/
All Articles