Ranking in detail
The most important process of search engines for website promotion is ranking - the process of building up the elements of a set of web pages in a sequence determined by decreasing the ranking of the relevance of these resources. To determine the rank of relevance, algorithms are developed that determine what should influence the position, under what requests and conditions.
Every year the ranking algorithms are improved: new factors are added, information processing mechanisms become more complicated - and all in order to keep up with the times and respond to the user's request of always relevant and truly relevant output. As the demand determines the supply, the ranking algorithms stimulate the development of the site in the direction requested by the visitor.
The absence of a ranking mechanism would lead to chaos in issuing, when the necessary information would be far beyond the top ten, and having your own website would make no sense, except as an extra touch to the business card. The same goes for the complication of the relevance rank algorithms: if the definition was based on the citation index and key entries, then we would still look at one-page sites without design, without thinking about usability.
The ranking of relevance is influenced by various ranking factors, of which there are many today and which can be grouped together. Search engines operate on some concepts of grouping, optimizers on others. At the same time, the influence of the factor remains unchanged in the ranking algorithm. Some factors may be equivalent, which does not allow linear comparison between competitors. However, the main directions can be set and defined.
This article will focus on text and reference components.
')
The Yandex search engine is the most interesting object under investigation in this regard, not only because more frequent changes in the algorithm occur in it than in others, but also because this system is the first in RuNet to work with commercial or selling queries.
Ranking factors are those or other attributes of a request and pages on a site that are important for ranking and that give a page rating for a given query.
There are several groups. The first - static factors that are associated with the page itself, for example, the number of links to this page on the Internet. The second group includes dynamic factors associated with the query and the page at the same time — for example, the presence of the query words on the page, their number and location. The third group - query factors - attributes of a search query, for example, geo-dependency.
If search engines classify the classification on their belonging to a query or page, then seo-specialists form the direction of influence of factors as the basis for the division. Thus, a specialist in the promotion of all factors are divided into the following groups:
- Factors assessing the technical component of the site, which primarily affects the ability and quality of indexing the site;
- Factors evaluating the textual component of the page and the site, which shows the relevance of the content to the request;
- Factors evaluating the reference component, both external and internal, both anchor and trust, both pages and the entire site;
- Factors assessing the behavioral component, whether visitors like the site, whether it is convenient, meets the requirements of users;
- Additional assignment factors, such as determining whether the user specifies the request and the site correspond to the site, determine the presence of affiliates, and others.
Each direction of work with the site is important and it is necessary to approach comprehensively to work with the site in all directions in order to cover all the factors influencing the ranking.
In the ranking engine, the most important thing is to evaluate the content-relevant document for the query entered by the user. For ranking, use the text of the request, the text of the document and some elements of the html markup of the document. These are the main elements that the search engine uses to compile index databases and to determine the relevance of a document. Therefore, the first thing you need to work with is the textual component of a web page.
To understand the mechanism for evaluating the relevance, importance of the text and the indicated limitations, it is required to know exemplary search models, which are formulas and approaches that allow a search engine program to decide: which document to consider reliable and how to rank it. After adopting a model, the coefficients in formulas often acquire a physical meaning, allowing you to find your optimal value for improving the quality of the search.
The representation of the entire contents of the document can be different - set-theoretic models (Boolean, fuzzy sets, extended Boolean), algebraic (vector, generalized vector, latent-semantic, neural network) and probabilistic.
An example of the first model is full-text search, when a document is considered found if all the words of the query are found. However, the Boolean family of models is extremely tough and unsuitable for ranking. Therefore, at one time Joyce and Needham were asked to take into account the frequency characteristics of words, which resulted in the use of a vector model.
The ranking in the algebraic model is based on a natural statistical observation that the greater the local frequency of a term in a document (TF) and the greater the “rarity” (i.e., the reverse occurrence in documents) of a term in a collection (IDF), the higher the weight of this document in relation to to the term. The designation TF * IDF is widely used as a synonym for a vector model.
The essence of the metric TF * IDF - filter meaningful words from less significant (prepositions, conjunctions, etc.). TF (term frequency) is the ratio of the number of occurrences of a word to the total number of words in the document. Thus, the importance of the word is assessed within a single document:
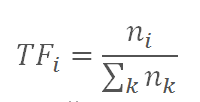
where ni is the number of occurrences of the word from the query in the document,
nk - the number of all words in the document.
IDF (inverse document frequency) - the inverse of the frequency with which a word occurs in collection documents is calculated differently:
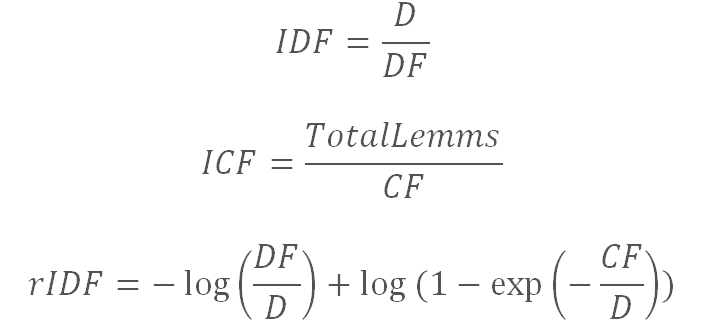
where D is the number of documents in the collection,
DF - the number of documents in which the lemma occurs,
CF is the number of occurrences of the lemma in the collection,
TotalLemms is the total number of occurrences of all lemmas in the collection.
According to the open-ended Yandex experiments, of all the options presented, the ICF showed the best result.
There is also a large variety of functions for rationing and smoothing the intra-document frequency when calculating the contrast TF * IDF.
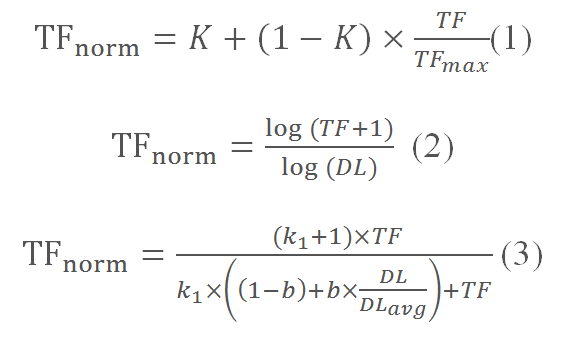
Over time, the above formulas are improved and undergo changes.
In 2006–2007, a formula similar to (2) was used when attempts were made to achieve high relevance at the expense of “nausea” - copying the text with keywords, and this should be punished.
When the need came to deal with the "footcloths" - large texts with keywords, the formula (3) was used. Then the formula became even more complicated; in the new algorithm, search engines use various thesauries that expand the query, determine the text re-spamming not only with a large number of keys, but also with its trail and inconvenience in the design of text with tags, illiterate spelling or a combination of words.
Relevance in probabilistic models is based on an assessment of the probability of whether the document in question will be interesting to the user. This implies the presence of an existing initial set of relevant documents selected by the user or automatically received under a simplified assumption. The probability of being relevant for each subsequent document is calculated based on the ratio of the occurrence of terms in the relevant set and in the rest of the “irrelevant” parts of the collection.
In each of the simplest models, there is an assumption about the interdependence of words and the filtering condition: documents that do not contain the query words are never found. To date, the models used in ranking and determining relevance do not consider query words to be mutually independent, but, in addition, allow us to find documents that do not contain a single word from the query.
Partially, this task is solved by the preprocessing mechanism of the query, which allows you to set empirically selected contextual constraints: at what distance to search for words from the query, whether all words should be present in the document, with which words you can expand the search. Also, the actual default merging of the content of the document and its anchor file into one search zone occurs.
The quorum filtering mechanism allows you to determine the relevant passages in the document. All complete passages and those incomplete are considered relevant, the sum of the word weights, which exceeds the required quorum.
In 2004, the following quorum formula was used:

where QuorumWeight is the quorum value;
Softness - softness, corresponds to a value from 0 to 1, in the documented records of Yandex the coefficient 0.06 is indicated;
QL - the length of the query in words.
Thus, based on known facts, the quorum for a phrase will have the following form, using this formula, it is determined which combination of words is necessary and which word can be neglected:

where QL * is the number of words from the request in an incomplete passage;
deg - the value of the degree of 0.38, derived experimentally
The ranking of the document is based on the calculated coefficient of contextual similarity to the request. In fact, all the information about the weight of the various passages of the document is combined, and a conclusion is drawn on the relevance indicator of the document. One of the articles in Yandex gives an example of an additive model, which is the sum of the weights of each word, pairs of words, all words, the entire query, many words in one sentence, and bonus documents similar to those marked by an expert, i.e. good ones. This shows that everything on the page will be appreciated, and proves that the writing of the text must be approached very responsibly.
Next, we consider the reference component.
According to the search theory, users of information retrieval systems determine the value of a document by means of information keys - the anchor of a link. And the presence of the links themselves increases the visitor’s hit on the page. Therefore, search engines use to highlight a single document among the cluster also the principle of citation.
The citation index is an indicator indicating the importance of this page and calculated on the basis of the referring pages to this one. This principle is borrowed from the scientific community, which was used to evaluate scientists and scientific organizations.
In the simplest form of citation index, only the number of links to the resource is taken into account. But he has a number of limitations. This factor does not reflect the structure of links in each topic, as well as weak references and links with great significance may have the same citation index. Therefore, the term popularity factor (eng. Popularity Factor) or weighted citation index or link weight was introduced; this factor is called differently by different search engines: PageRank in Google, CID in Yandex. The links themselves are involved in static weight transfer, showing the popularity of the resource, and anchor on the specified keys. There is also a thematic citation index (TCI), which also takes into account the themes of sites referring to the resource.
Initially, before they started working with the reference component to promote the site, the citation index actually reflected the popularity of the corresponding resource on the Internet. Once, in one of the articles, Yandex Technical Director Ilya Segalovich mentioned that the introduction of link search and static link popularity helped search engines cope with primitive text spam, which completely destroyed the traditional statistical information search algorithms obtained in due time for controlled collections.
In 1998, an article appeared describing the principles of the PageRank algorithm used by Google. The weighted citation index, like the other reference ranking factors, is calculated from the reference graph.
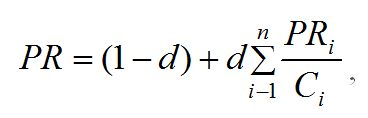
PR - PageRank of the page in question,
d is the attenuation coefficient (means the probability that a user visiting the page will follow one of the links on this page, and will not stop surfing the net),
PRi - PageRank of the i-th page that refers to the page,
Ci is the total number of links on the i-th page.
The basic idea is that the page transfers its weight by distributing it to all outgoing links, so the more links on the donor page, the less weight each will get. Another equally important idea is to understand the principle of citation - it is an estimate of the probability of a visitor’s transition through one of the links, and therefore, the probability of the popularity of the very page of the site to which links are placed. Accordingly, the more high-quality links, the higher the likelihood of resource popularity.
Today, links often harm the quality of the search, so search engines have begun to fight reference cheating - placing SEO links on third-party sites on a commercial basis and designed to manipulate ranking algorithms. They take all measures to ensure that sites selling links lose their ability to influence the ranking in this way, and buying links from sites could not lead to an increase in the rank of the site-buyer.
The algorithms used in modern search engines to evaluate the reference component have undergone great changes, but the quality and the number of links have retained their direct influence when selecting a page among a cluster of copies. The more authoritative and thematically the donor page is similar to your resource, the more weight will be transferred to the site, the higher will be its position in the search.
Author of the article: Neelova N.V. (Ph.D., head of PP Ingate).
Every year the ranking algorithms are improved: new factors are added, information processing mechanisms become more complicated - and all in order to keep up with the times and respond to the user's request of always relevant and truly relevant output. As the demand determines the supply, the ranking algorithms stimulate the development of the site in the direction requested by the visitor.
The absence of a ranking mechanism would lead to chaos in issuing, when the necessary information would be far beyond the top ten, and having your own website would make no sense, except as an extra touch to the business card. The same goes for the complication of the relevance rank algorithms: if the definition was based on the citation index and key entries, then we would still look at one-page sites without design, without thinking about usability.
The ranking of relevance is influenced by various ranking factors, of which there are many today and which can be grouped together. Search engines operate on some concepts of grouping, optimizers on others. At the same time, the influence of the factor remains unchanged in the ranking algorithm. Some factors may be equivalent, which does not allow linear comparison between competitors. However, the main directions can be set and defined.
This article will focus on text and reference components.
')
The Yandex search engine is the most interesting object under investigation in this regard, not only because more frequent changes in the algorithm occur in it than in others, but also because this system is the first in RuNet to work with commercial or selling queries.
Ranking factors are those or other attributes of a request and pages on a site that are important for ranking and that give a page rating for a given query.
There are several groups. The first - static factors that are associated with the page itself, for example, the number of links to this page on the Internet. The second group includes dynamic factors associated with the query and the page at the same time — for example, the presence of the query words on the page, their number and location. The third group - query factors - attributes of a search query, for example, geo-dependency.
If search engines classify the classification on their belonging to a query or page, then seo-specialists form the direction of influence of factors as the basis for the division. Thus, a specialist in the promotion of all factors are divided into the following groups:
- Factors assessing the technical component of the site, which primarily affects the ability and quality of indexing the site;
- Factors evaluating the textual component of the page and the site, which shows the relevance of the content to the request;
- Factors evaluating the reference component, both external and internal, both anchor and trust, both pages and the entire site;
- Factors assessing the behavioral component, whether visitors like the site, whether it is convenient, meets the requirements of users;
- Additional assignment factors, such as determining whether the user specifies the request and the site correspond to the site, determine the presence of affiliates, and others.
Each direction of work with the site is important and it is necessary to approach comprehensively to work with the site in all directions in order to cover all the factors influencing the ranking.
In the ranking engine, the most important thing is to evaluate the content-relevant document for the query entered by the user. For ranking, use the text of the request, the text of the document and some elements of the html markup of the document. These are the main elements that the search engine uses to compile index databases and to determine the relevance of a document. Therefore, the first thing you need to work with is the textual component of a web page.
To understand the mechanism for evaluating the relevance, importance of the text and the indicated limitations, it is required to know exemplary search models, which are formulas and approaches that allow a search engine program to decide: which document to consider reliable and how to rank it. After adopting a model, the coefficients in formulas often acquire a physical meaning, allowing you to find your optimal value for improving the quality of the search.
The representation of the entire contents of the document can be different - set-theoretic models (Boolean, fuzzy sets, extended Boolean), algebraic (vector, generalized vector, latent-semantic, neural network) and probabilistic.
An example of the first model is full-text search, when a document is considered found if all the words of the query are found. However, the Boolean family of models is extremely tough and unsuitable for ranking. Therefore, at one time Joyce and Needham were asked to take into account the frequency characteristics of words, which resulted in the use of a vector model.
The ranking in the algebraic model is based on a natural statistical observation that the greater the local frequency of a term in a document (TF) and the greater the “rarity” (i.e., the reverse occurrence in documents) of a term in a collection (IDF), the higher the weight of this document in relation to to the term. The designation TF * IDF is widely used as a synonym for a vector model.
The essence of the metric TF * IDF - filter meaningful words from less significant (prepositions, conjunctions, etc.). TF (term frequency) is the ratio of the number of occurrences of a word to the total number of words in the document. Thus, the importance of the word is assessed within a single document:
where ni is the number of occurrences of the word from the query in the document,
nk - the number of all words in the document.
IDF (inverse document frequency) - the inverse of the frequency with which a word occurs in collection documents is calculated differently:
where D is the number of documents in the collection,
DF - the number of documents in which the lemma occurs,
CF is the number of occurrences of the lemma in the collection,
TotalLemms is the total number of occurrences of all lemmas in the collection.
According to the open-ended Yandex experiments, of all the options presented, the ICF showed the best result.
There is also a large variety of functions for rationing and smoothing the intra-document frequency when calculating the contrast TF * IDF.
Over time, the above formulas are improved and undergo changes.
In 2006–2007, a formula similar to (2) was used when attempts were made to achieve high relevance at the expense of “nausea” - copying the text with keywords, and this should be punished.
When the need came to deal with the "footcloths" - large texts with keywords, the formula (3) was used. Then the formula became even more complicated; in the new algorithm, search engines use various thesauries that expand the query, determine the text re-spamming not only with a large number of keys, but also with its trail and inconvenience in the design of text with tags, illiterate spelling or a combination of words.
Relevance in probabilistic models is based on an assessment of the probability of whether the document in question will be interesting to the user. This implies the presence of an existing initial set of relevant documents selected by the user or automatically received under a simplified assumption. The probability of being relevant for each subsequent document is calculated based on the ratio of the occurrence of terms in the relevant set and in the rest of the “irrelevant” parts of the collection.
In each of the simplest models, there is an assumption about the interdependence of words and the filtering condition: documents that do not contain the query words are never found. To date, the models used in ranking and determining relevance do not consider query words to be mutually independent, but, in addition, allow us to find documents that do not contain a single word from the query.
Partially, this task is solved by the preprocessing mechanism of the query, which allows you to set empirically selected contextual constraints: at what distance to search for words from the query, whether all words should be present in the document, with which words you can expand the search. Also, the actual default merging of the content of the document and its anchor file into one search zone occurs.
The quorum filtering mechanism allows you to determine the relevant passages in the document. All complete passages and those incomplete are considered relevant, the sum of the word weights, which exceeds the required quorum.
In 2004, the following quorum formula was used:
where QuorumWeight is the quorum value;
Softness - softness, corresponds to a value from 0 to 1, in the documented records of Yandex the coefficient 0.06 is indicated;
QL - the length of the query in words.
Thus, based on known facts, the quorum for a phrase will have the following form, using this formula, it is determined which combination of words is necessary and which word can be neglected:
where QL * is the number of words from the request in an incomplete passage;
deg - the value of the degree of 0.38, derived experimentally
The ranking of the document is based on the calculated coefficient of contextual similarity to the request. In fact, all the information about the weight of the various passages of the document is combined, and a conclusion is drawn on the relevance indicator of the document. One of the articles in Yandex gives an example of an additive model, which is the sum of the weights of each word, pairs of words, all words, the entire query, many words in one sentence, and bonus documents similar to those marked by an expert, i.e. good ones. This shows that everything on the page will be appreciated, and proves that the writing of the text must be approached very responsibly.
Next, we consider the reference component.
According to the search theory, users of information retrieval systems determine the value of a document by means of information keys - the anchor of a link. And the presence of the links themselves increases the visitor’s hit on the page. Therefore, search engines use to highlight a single document among the cluster also the principle of citation.
The citation index is an indicator indicating the importance of this page and calculated on the basis of the referring pages to this one. This principle is borrowed from the scientific community, which was used to evaluate scientists and scientific organizations.
In the simplest form of citation index, only the number of links to the resource is taken into account. But he has a number of limitations. This factor does not reflect the structure of links in each topic, as well as weak references and links with great significance may have the same citation index. Therefore, the term popularity factor (eng. Popularity Factor) or weighted citation index or link weight was introduced; this factor is called differently by different search engines: PageRank in Google, CID in Yandex. The links themselves are involved in static weight transfer, showing the popularity of the resource, and anchor on the specified keys. There is also a thematic citation index (TCI), which also takes into account the themes of sites referring to the resource.
Initially, before they started working with the reference component to promote the site, the citation index actually reflected the popularity of the corresponding resource on the Internet. Once, in one of the articles, Yandex Technical Director Ilya Segalovich mentioned that the introduction of link search and static link popularity helped search engines cope with primitive text spam, which completely destroyed the traditional statistical information search algorithms obtained in due time for controlled collections.
In 1998, an article appeared describing the principles of the PageRank algorithm used by Google. The weighted citation index, like the other reference ranking factors, is calculated from the reference graph.
PR - PageRank of the page in question,
d is the attenuation coefficient (means the probability that a user visiting the page will follow one of the links on this page, and will not stop surfing the net),
PRi - PageRank of the i-th page that refers to the page,
Ci is the total number of links on the i-th page.
The basic idea is that the page transfers its weight by distributing it to all outgoing links, so the more links on the donor page, the less weight each will get. Another equally important idea is to understand the principle of citation - it is an estimate of the probability of a visitor’s transition through one of the links, and therefore, the probability of the popularity of the very page of the site to which links are placed. Accordingly, the more high-quality links, the higher the likelihood of resource popularity.
Today, links often harm the quality of the search, so search engines have begun to fight reference cheating - placing SEO links on third-party sites on a commercial basis and designed to manipulate ranking algorithms. They take all measures to ensure that sites selling links lose their ability to influence the ranking in this way, and buying links from sites could not lead to an increase in the rank of the site-buyer.
The algorithms used in modern search engines to evaluate the reference component have undergone great changes, but the quality and the number of links have retained their direct influence when selecting a page among a cluster of copies. The more authoritative and thematically the donor page is similar to your resource, the more weight will be transferred to the site, the higher will be its position in the search.
Author of the article: Neelova N.V. (Ph.D., head of PP Ingate).
Source: https://habr.com/ru/post/196162/
All Articles