Methods of forming a measurement with attributes type 1 and 2
We are working on DWH in telecommunications, so the example I’m considering is called “Subscriber”. The principle is universal and it could be “Client” or “Patient” - depending on the industry. I hope the methodology will be useful for DWH developers from different industries.
If you do not understand what DWH is, measurements and facts, I recommend reading Ralph Kimball’s book Dimensional Modeling. This is a database for analytics and consolidated reporting of an enterprise, specifically on the formation and updating of dimensions - tables that store the attributes (fields) for selection (WHERE) in future queries.
Our methodology is designed for Microsoft SQL Server.
')
The definition of the change of attributes of type 1 (rewritable) and 2 (with the history stored in measurement records) is made on the basis of comparison of checksums of the fields.
For calculating checksums, the T-SQL CHECKSUM function is used, which does not support text, ntext, image types, which should not be placed in the measurements. Using BINARY_CHECKSUM in practice has shown that false detection of changes in fields containing NULL is possible. With this technique, it is possible to use custom checksum functions developed on .NET.
The dimension must be declared with a primary key containing a clustered index.
Example of the SQL script of the “Subscriber” dimension ad:
It is necessary to impose on the measurement a conditional index on the business key with the condition [EndTime] IS NULL, containing the checksum fields. The inclusion of checksums in the index, provided the cluster index of the primary key of the dimension table ([AccountKey]), allows you not to read the dimension table itself when performing the initial query. At the same time, the index performs the function of controlling uniqueness - one valid entry for one business key.
An example of an index for measuring “Subscriber”:
The initial SQL query contains an internal subquery [i], which receives fields from the source copy tables and an external query [o], which generates checksums, and appends the current dimension row to the business key.
An example of the initial request for the dimension “Subscriber”:
Type casting (this is typically CAST (... AS NVARCHAR (..)) or IIF (ISDATE ([...]) = 1, CAST ([...] AS DATE), NULL)), as well as all the binding source tables (LEFT JOIN) and conditional formation of fields (CASE, IIF) must be done in an internal query - inside FROM (...) AS [i].
If the logic of linking source tables is too complicated (for example, you need to pull some data out of the hierarchy) and it cannot be done inside FROM, then before data flow in SSIS, you will have to insert a SQL Task that forms intermediate data in separate tables (following your naming scheme). objects). Temporary tables will not work because SSIS will not be able to determine output stream metadata.
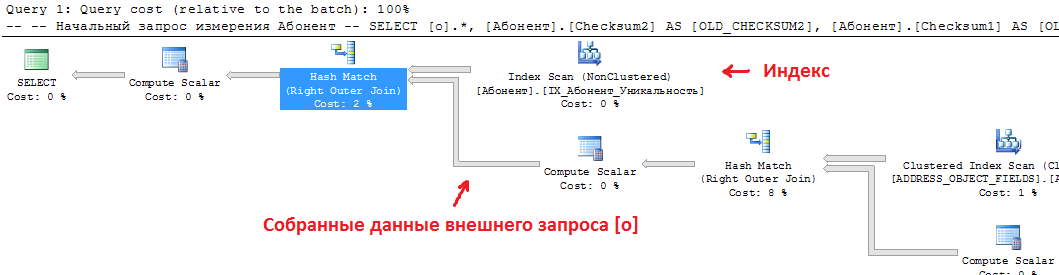
You can make sure that the interaction between the index and the initial query is correct by looking at its execution plan. At the end of the execution plan there should be no reference to the table:
The data of the formation of the dimension exits the initial SQL query described above and implements the further logic of the change.
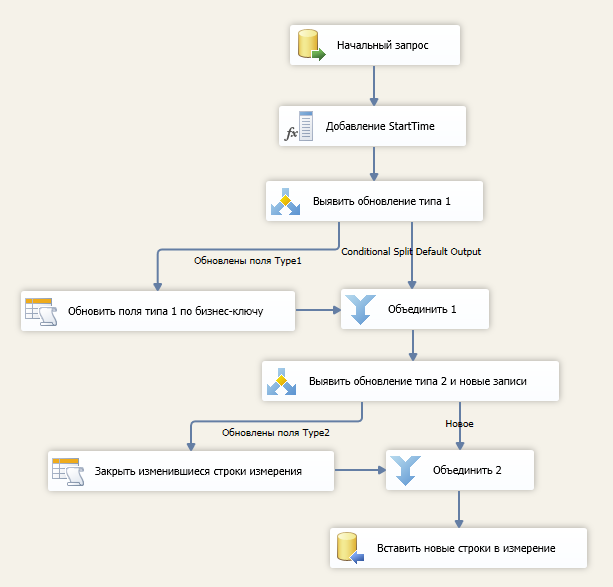
In the operation “Adding StartTime” we add to the StartTime stream using the start time of the SSIS package (take the variable @ [System :: StartTime])
In the operation “Detect type 1 update”, we single out one stream - “Type1 fields are updated” based on the expression! ISNULL (OLD_CHECKSUM1) && CHECKSUM1! = OLD_CHECKSUM1.
In the operation “Update type 1 fields by business key” we update all measurement records (including already closed records containing historical values of type 2 fields) in which attributes of the first type have changed - for this we use the business key without the cutoff condition of irrelevant records (without condition on [EndTime]). Example for “Subscriber”:
In the operation “Identify type 2 update and new records”, we distinguish two streams:
In the operation “Close Measured Measurement Lines”, update [EndTime] for measurement records with the StartTime value from the stream. Example for “Subscriber”:
In the operation “Insert lines into dimension” we insert new lines, while in the [StartTime] field we insert StartTime from the stream, the measurement key and [EndTime] are ignored (NULL generated in the [EndTime] field will be a sign of the current record).
When inserting on the last operation, it will not be possible to use Fast Load mode because the insertion performed in the same stream with updates must operate with a string without extending the lock to the table level, otherwise there will be conflicts between simultaneous operations. Alternatively, you can spread the operations along different steps of the control flow, keeping intermediate results in Raw or Cache and following the order of operations.
At the level of the data flow container (or the general container, if you split the operations into steps of the control flow), it is desirable to enable the transaction. To do this, set TransactionOption = Required (requires DTC) and IsolationLevel not lower than ReadCommitted.
If there is no transaction, if the data flow is interrupted, a portion of the measurement records may remain closed without inserting the corresponding actual records. At the next start, the missing entries will be inserted as new ones, but with a starting time different from the closing time of the previous line. This should be taken into account if the facts are attached to the measurement by the method of attaching the record that is relevant at the moment of the occurrence of the fact - to operate with the measurement binding only the closing time.
Compared to using the standard SQL Server Integration Services component, called Slowly Changing Dimension, this method does not use a comparison of each field with each field in a dimension row — it does not even refer to the table to perform such a comparison. This gives the main advantage - speed. In addition, the standard Slowly Changing Dimension controls the whole chain of elements at once, and this creates difficulty with their customization. For reasons unknown to me, the standard SSIS component may falsely detect changes (perhaps this is also related to NULL fields).
Before the commercial components of third-party vendors there is a fundamental advantage of the method in that it is based on the standard components and functions supplied with the release of SQL Server. Thus, it is not necessary to wait for updated components to upgrade to the next version of SQL Server.
A modified method is possible, in which the join is performed not in the SQL query, but in the SSIS data stream through the Lookup operation. This leads to more calls to the database and replacing the effective Hash Match with less effective single requests. On the other hand, this allows you to separate the source tables (copy tables that are formed at the boot stage from the source systems) and the measurement tables to different servers. But the benefits of such an opportunity I doubt.
It is possible to join in the SSIS stream through the Merge Join operation, but it will require retrieving the table and sorting it, which will negate the advantages of the index.
The calculation of the checksum is also possible in the data stream, for example, a separate component, but in this case the advantage of not having the need for separate components disappears.
Calculating the checksum in the data stream using Script Transformation on C # is a possible modification option if this complication makes sense.
An overview of the implementation (with screenshots) of the modified method (in fact, the previous version) using the free third-party component for calculating checksums from Konesans and using a custom Lookup (to use the index) can be seen here .
If you do not understand what DWH is, measurements and facts, I recommend reading Ralph Kimball’s book Dimensional Modeling. This is a database for analytics and consolidated reporting of an enterprise, specifically on the formation and updating of dimensions - tables that store the attributes (fields) for selection (WHERE) in future queries.
Our methodology is designed for Microsoft SQL Server.
')
Principle of change
The definition of the change of attributes of type 1 (rewritable) and 2 (with the history stored in measurement records) is made on the basis of comparison of checksums of the fields.
For calculating checksums, the T-SQL CHECKSUM function is used, which does not support text, ntext, image types, which should not be placed in the measurements. Using BINARY_CHECKSUM in practice has shown that false detection of changes in fields containing NULL is possible. With this technique, it is possible to use custom checksum functions developed on .NET.
Measurement announcement
The dimension must be declared with a primary key containing a clustered index.
Example of the SQL script of the “Subscriber” dimension ad:
USE [DWH] GO /* Dim */ IF SCHEMA_ID('Dim') IS NULL EXECUTE('CREATE SCHEMA [Dim] AUTHORIZATION [dbo]') GO /* */ IF EXISTS ( SELECT * FROM dbo.sysobjects WHERE id = OBJECT_ID(N'[Dim].[]') AND OBJECTPROPERTY(id, N'IsUserTable') = 1 ) DROP TABLE [Dim].[] GO /* */ CREATE TABLE [Dim].[] ( [AccountKey] INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED, [ ] INT NULL, [ ] NVARCHAR(13) NOT NULL CHECK ([ ] IN (N'.', N'.', N' ')) DEFAULT N' ', [] NVARCHAR(16) NOT NULL DEFAULT N' ', [ ] NVARCHAR(50) NOT NULL DEFAULT ' ', [ ] DATE, [ ] DATE, [] NVARCHAR(100) NOT NULL DEFAULT ' ', [] NVARCHAR(100) NOT NULL DEFAULT ' ', [] NVARCHAR(100) NOT NULL DEFAULT ' ', [ ] DATE, [] AS [] + CASE WHEN [] != N' ' THEN N' ' + [] ELSE N'' END + CASE WHEN [] != N' ' THEN N' ' + [] ELSE N'' END, [ ] NVARCHAR(100) NOT NULL DEFAULT N' ', ... [] NVARCHAR(200) NOT NULL DEFAULT N' ', [ SMS] NVARCHAR(20) NOT NULL DEFAULT N' ', [] NVARCHAR(200) NOT NULL DEFAULT N' ', [E-mail] NVARCHAR(50) NOT NULL DEFAULT N' ', [ ] AS N': ' + [] + N', ' + N' SMS: ' + [ SMS] + N', ' + N': ' + [] + N', ' + N'E-mail: ' + [E-mail], [StartTime] DATETIME2 NOT NULL, [EndTime] DATETIME2 NULL, [Checksum1] INT NULL, [Checksum2] INT NULL ) /* */ SET IDENTITY_INSERT [Dim].[] ON INSERT INTO [Dim].[] ([AccountKey],[ ],[StartTime]) VALUES (-1, NULL, GETDATE()) SET IDENTITY_INSERT [Dim].[] OFF GO It is necessary to impose on the measurement a conditional index on the business key with the condition [EndTime] IS NULL, containing the checksum fields. The inclusion of checksums in the index, provided the cluster index of the primary key of the dimension table ([AccountKey]), allows you not to read the dimension table itself when performing the initial query. At the same time, the index performs the function of controlling uniqueness - one valid entry for one business key.
An example of an index for measuring “Subscriber”:
CREATE UNIQUE INDEX IX__ ON [Dim].[] ([ ], [EndTime]) INCLUDE ([Checksum1], [Checksum2]) WHERE [EndTime] IS NULL Typical initial SQL query
The initial SQL query contains an internal subquery [i], which receives fields from the source copy tables and an external query [o], which generates checksums, and appends the current dimension row to the business key.
An example of the initial request for the dimension “Subscriber”:
SELECT [o].*, [].[Checksum2] AS [OLD_CHECKSUM2], [].[Checksum1] AS [OLD_CHECKSUM1], [].[AccountKey] AS [OLD_AccountKey] FROM ( SELECT i.*, CHECKSUM( [ ], [], [ ], [ ], [], [], [], [ ], [], [], [], [], [ ], [ ] ) AS [CHECKSUM2], CHECKSUM( [], [ SMS], [E-mail], [ ] ) AS [CHECKSUM1] FROM ( SELECT FROM [Raw].... LEFT JOIN [Raw].... ) AS [i] -- ) AS [o] -- LEFT JOIN [Dim].[] ON [o].[ ] = [].[ ] AND [].[EndTime] IS NULL -- Type casting (this is typically CAST (... AS NVARCHAR (..)) or IIF (ISDATE ([...]) = 1, CAST ([...] AS DATE), NULL)), as well as all the binding source tables (LEFT JOIN) and conditional formation of fields (CASE, IIF) must be done in an internal query - inside FROM (...) AS [i].
If the logic of linking source tables is too complicated (for example, you need to pull some data out of the hierarchy) and it cannot be done inside FROM, then before data flow in SSIS, you will have to insert a SQL Task that forms intermediate data in separate tables (following your naming scheme). objects). Temporary tables will not work because SSIS will not be able to determine output stream metadata.
You can make sure that the interaction between the index and the initial query is correct by looking at its execution plan. At the end of the execution plan there should be no reference to the table:
Typical data stream
The data of the formation of the dimension exits the initial SQL query described above and implements the further logic of the change.
In the operation “Adding StartTime” we add to the StartTime stream using the start time of the SSIS package (take the variable @ [System :: StartTime])
In the operation “Detect type 1 update”, we single out one stream - “Type1 fields are updated” based on the expression! ISNULL (OLD_CHECKSUM1) && CHECKSUM1! = OLD_CHECKSUM1.
In the operation “Update type 1 fields by business key” we update all measurement records (including already closed records containing historical values of type 2 fields) in which attributes of the first type have changed - for this we use the business key without the cutoff condition of irrelevant records (without condition on [EndTime]). Example for “Subscriber”:
UPDATE [Dim].[] SET [] = ?, [ SMS] = ?, [E-mail] = ?, [ ] = ? [Checksum1] = ? WHERE [ ] = ? In the operation “Identify type 2 update and new records”, we distinguish two streams:
- “New” based on the expression ISNULL (OLD_AccountKey)
- “Updated Type2 fields” based on the expression CHECKSUM2! = OLD_CHECKSUM2
In the operation “Close Measured Measurement Lines”, update [EndTime] for measurement records with the StartTime value from the stream. Example for “Subscriber”:
UPDATE [Dim].[] SET [EndTime] = ? WHERE [AccountKey] = ? In the operation “Insert lines into dimension” we insert new lines, while in the [StartTime] field we insert StartTime from the stream, the measurement key and [EndTime] are ignored (NULL generated in the [EndTime] field will be a sign of the current record).
When inserting on the last operation, it will not be possible to use Fast Load mode because the insertion performed in the same stream with updates must operate with a string without extending the lock to the table level, otherwise there will be conflicts between simultaneous operations. Alternatively, you can spread the operations along different steps of the control flow, keeping intermediate results in Raw or Cache and following the order of operations.
Transaction use
At the level of the data flow container (or the general container, if you split the operations into steps of the control flow), it is desirable to enable the transaction. To do this, set TransactionOption = Required (requires DTC) and IsolationLevel not lower than ReadCommitted.
If there is no transaction, if the data flow is interrupted, a portion of the measurement records may remain closed without inserting the corresponding actual records. At the next start, the missing entries will be inserted as new ones, but with a starting time different from the closing time of the previous line. This should be taken into account if the facts are attached to the measurement by the method of attaching the record that is relevant at the moment of the occurrence of the fact - to operate with the measurement binding only the closing time.
Comparison with other methods
Compared to using the standard SQL Server Integration Services component, called Slowly Changing Dimension, this method does not use a comparison of each field with each field in a dimension row — it does not even refer to the table to perform such a comparison. This gives the main advantage - speed. In addition, the standard Slowly Changing Dimension controls the whole chain of elements at once, and this creates difficulty with their customization. For reasons unknown to me, the standard SSIS component may falsely detect changes (perhaps this is also related to NULL fields).
Before the commercial components of third-party vendors there is a fundamental advantage of the method in that it is based on the standard components and functions supplied with the release of SQL Server. Thus, it is not necessary to wait for updated components to upgrade to the next version of SQL Server.
Method modifications
A modified method is possible, in which the join is performed not in the SQL query, but in the SSIS data stream through the Lookup operation. This leads to more calls to the database and replacing the effective Hash Match with less effective single requests. On the other hand, this allows you to separate the source tables (copy tables that are formed at the boot stage from the source systems) and the measurement tables to different servers. But the benefits of such an opportunity I doubt.
It is possible to join in the SSIS stream through the Merge Join operation, but it will require retrieving the table and sorting it, which will negate the advantages of the index.
The calculation of the checksum is also possible in the data stream, for example, a separate component, but in this case the advantage of not having the need for separate components disappears.
Calculating the checksum in the data stream using Script Transformation on C # is a possible modification option if this complication makes sense.
An overview of the implementation (with screenshots) of the modified method (in fact, the previous version) using the free third-party component for calculating checksums from Konesans and using a custom Lookup (to use the index) can be seen here .
Source: https://habr.com/ru/post/195838/
All Articles