Subtleties of successful git-merge
opening speech
It is believed that the "killer feature" SLE Git is a lightweight branching. I felt this advantage in full, because I switched to Git from SVN, where branching was quite an expensive process: to create a branch, you had to copy the entire working directory. In Git, everything is simpler: creating a branch only means creating a new pointer to a specific commit in the
.git/refs/heads folder, which is a file with 40 bytes of text, a commit hash.The main user-level commands for branching in Git are git-branch, git-checkout, git-rebase, git-log and, of course, git-merge. For myself, I consider the git-merge zone of greatest responsibility, a point of tremendous magical energy and great opportunities. But this is a fairly complex team, and even a fairly long experience with Git is sometimes not enough to master all its subtleties and the ability to apply it most effectively in a non-standard situation.
Let's try to understand the subtleties of git-merge and tame this great magic.
')
Here I want to consider only the case of a successful merger, by which I mean a merger without conflicts. Handling and conflict resolution is a separate interesting topic worthy of a separate article. I highly recommend also reading the Git Internal article : data storage and merge , which contains a lot of important information that I rely on.
Team anatomy
If you believe the manual , the command has the following syntax:
git merge [-n] [--stat] [--no-commit] [--squash] [- [no-] edit] [-s <strategy>] [-X <strategy-option>] [- [no-] rerere-autoupdate] [-m <msg>] [<commit> ...] git merge <msg> HEAD <commit> ... git merge --abort
By and large, there are two types of merge in Git: fast-forward merge (fast-forward merge) and true merge (true merge). Consider a few examples of both cases.
“True” merge (true merge)
We deviate from the master branch in order to introduce several
master: A - B - C - D
\
feature: X - Y
Run on the master
git merge feature branch:
master: A - B - C - D - (M)
\ /
feature: X - Y
This is the most common merge pattern. In this case, a new commit is created in the master branch (M), which will refer to two parents: commit D and commit Y; and the master pointer is set to commit (M). Thus, Git will understand which changes correspond to commit (M) and which commit is the last one in the master branch. Usually a merge commit is done with a message like “Merge branch 'feature'”, but you can define your own commit message with the
-m .Let's look at the history of commits in the test repository, which I created specifically for this case:
$ git log --oneline 92384bd (M) bceb5a4 D 5dce5b1 Y 76f13e7 X d1920dc C 3a5c217 B 844af94 A
And now let's look at the information about commit (M):
$ git cat-file -p 92384bd tree 2b5c78f9086384bd86a2ab9d00c7e41a56f01d04 parent bceb5a4ad88e80467404473b94c3e0758dd8e0be parent 5dce5b1edef64bd0d4e1039061a77be4d7182678 author Andre <andrey.prokopyuk@gmail.com> 1380475972 +0400 committer Andre <andrey.prokopyuk@gmail.com> 1380475972 +0400 (M)
We see two parents, a tree object corresponding to a given state of the repository files, as well as information about who is responsible for the commit.
Let's see where the master pointer refers to:
$ cat .git / refs / heads / master 92384bd77304c09b81dcc4485da165923b96ed5f
Indeed, he is now moved to a commit (M).
Squash and no commit
But what if the content of the feature branch can beat you? For example, the improvement was small, and it could fit in one logical commit, but it turned out that in the middle of work you had to run off by train and continue at home? In this case, there are two ways out: exporting the repository and then importing it on another machine, or (especially when it’s 10 minutes to the train, and about a kilometer to the train station) - to do a
push origin feature .Pouring incomplete commits into the main branch is bad, and something needs to be done about it. One of the ways, and perhaps the easiest, is the
--squash option.git merge feature --squash changes of all commits of the feature branch, transfers them to the master branch and adds them to the index. When this commit merge will not be created, you will need to make it manually.You can achieve the same behavior without the squash parameter by passing the
--no-commit parameter when merging.In the case of such a merge, the commits of the feature branch will not be included in our history, but the Sq commit will contain all their changes:
master: A - B - C - D - Sq
\
feature: X - Y
Later, if you run the “classic”
git merge feature you can fix it. Then the story will take the following form:
master: A - B - C - D - Sq - (M)
\ /
feature: X - Y
If you did a merge without a commit, and then realized that you made a fatal error, you can cancel everything with a simple command:
git merge --abort . The same command can be applied if conflicts occurred during the merge, but you do not want to resolve them at the moment.Rewind (fast-forward merge)
Consider another case of commit history:
master: A - B - C
\
feature: X - Y
Everything is the same as last time, but now there are no commits after the branch in the master branch. In this case, fast-forward merge (rewind) occurs. In this case, there is no merge commit, the master pointer (branch) is simply set to commit Y, and the feature branch also points there:
master, feature: A - B - C - X - Y
To prevent rewinding, you can use the
--no-ff option.In case we execute the
git merge feature --no-ff -m '(M)' , we will get the following picture:
master: A - B - C - (M)
\ /
feature: X - Y
If for us the only acceptable behavior is fast-forward, we can specify the option
--ff-only . In this case, if the rewind is not applicable to the merge, a message will be displayed that it is impossible to merge. This would be the case if we added the --ff-only option in the very first example, where after tapping the feature in the master branch, a commit C was made.It can be added that when
git pull origin branch_name , the git pull origin branch_name is used as something like --ff-only . That is, if during the merge with the origin / branch_name branch, rewinding is not acceptable, the operation is canceled and a message about the impossibility of execution is displayed.Merge strategies
The git-merge command has an interesting parameter,
--strategy strategy, strategy. Git supports the following merge strategies:- resolve
- recursive
- ours
- octopus
- subtree
Resolve strategy
The resolve strategy is a classic three-way merge (three-way merge). The standard three-way merge algorithm is used for two files with a common ancestor. Conventionally, this algorithm can be represented in the form of the following steps:
- search for a common ancestor
- search for blocks that have changed in both versions relative to a common ancestor,
- unchanged blocks are written,
- blocks that have changed only in one of the descendants are written as changed,
- blocks that have changed in both versions are recorded only if the changes are identical, otherwise a conflict is declared, the resolution of which is granted to the user.
This strategy has one drawback: the earliest common commit is always selected as the common ancestor of the two branches. For the case of our first example, this is not terrible, you can safely use the
git merge feature -s resolve , and the result will be expected:
master: A - B - C - D - (M)
\ /
feature: X - Y
Here C is a common commit of two branches, the file tree corresponding to this commit is taken as a common ancestor. The changes made in the master and feature branches since the time of this commit are analyzed, after which a new version of the file tree is created for commit (M) in accordance with clauses 4 and 5 of our conditional algorithm.
In which case is the lack of the strategy resolve? It manifests itself if we had to resolve conflicts for commit (M), after which we continued to develop and once again want to perform the
git merge feature -s resolve . In this case, commit C will be used again as a common ancestor, and conflicts will occur again and will need our intervention.Recursive strategy
This strategy solves the problems of the resolve strategy. It also implements a three-way merger, but the real “virtual” ancestor is used as an ancestor, which is constructed according to the following conventional algorithm:
- A search for all candidates for a common ancestor,
- a chain of candidates is merged, resulting in a new “virtual” ancestor, with more recent commits having a higher priority, thus avoiding the re-emergence of conflicts.
The result of this action is taken as a common ancestor and is carried out a trilateral merger.
To illustrate this strategy, let's take an example from the article Merge recursive strategy from the blog “The plasticscm blog”:

So, we have two branches: main and task001. And so it turned out that our developers know a lot about perversions: they merged commit 15 from the main branch with commit 12 from the task001 branch, as well as commit 16 with commit 11. When we needed to merge the branches, it turned out that finding a real ancestor is ungrateful , but the recursive strategy with its construction of a “virtual” ancestor will help us. As a result, we get the following picture:
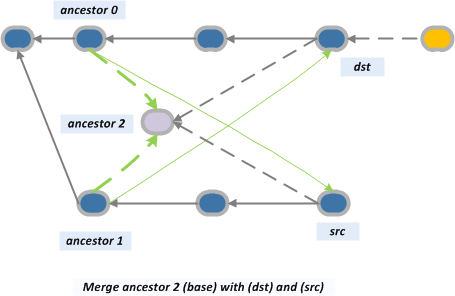
The recursive strategy has many options that are passed to the
git-merge command with the -X option:- ours and theirs
Used to automatically resolve conflicts. Ours - to prefer "our" version, the version of "dst", theirs - to prefer "their" version. - renormalize (no-renormalize)
Prevents false conflicts when merging options with different types of line breaks. - diff-algorithm = [patience | minimal | histogram | myers] , as well as the patience option
The choice of file differentiation algorithm.
More information about these options can be found in the git-diff documentation . In short, the properties of these algorithms are as follows:
default, myers is a standard, greedy algorithm. It is used by default.
minimal - it searches for the smallest changes, which takes extra time.
patience - use the patience diff algorithm. You can read about it from the author of the algorithm , or in an abbreviated version on SO .
histogram - extends the patience algorithm with the goal described as "support low-occurrence common elements". To be honest, I could not find a sufficiently clear answer to the question of what specific cases are implied and I would be very happy if someone helps me find this answer. - ignore-space-change, ignore-all-space, ignore-space-at-eol
The roots of these options are, again, in git-diff and relate to the differentiation of files when merging.
ignore-space-change - ignores differences in the number of spaces in a row, as well as spaces at the end of the line,
ignore-all-space - spaces are absolutely ignored when comparing,
ignore-space-at-eol - ignores differences in spaces at the end of the line. - rename-threshold = <n>
This option sets a threshold upon reaching which a file can be considered not a new, but a renamed file, of which the git-diff was not counted. For example,-Xrename-threshold=90%implies that a file that contains 90% of the content of some deleted file is considered renamed. - subtree [= <path>]
Performing a recursive merge with this option will be a more advanced version of the subtree strategy, where the algorithm is based on the assumption of how the trees should fit together in the merge. Instead, a specific option is indicated in this case.
Octopus strategy
This strategy is used to merge more than two branches. The resulting commit will have, respectively, more than two parents.
This strategy involves more caution about potential conflicts. In this regard, sometimes you can get a refusal to merge when applying the strategy of octopus.
Strategy ours
Do not confuse ours strategy with ours strategy option recursive.
When performing
git merge -s ours obsolete , you kind of say: I want to merge the stories of the branches, but ignore all the changes that have occurred in the obsolete branch. Sometimes it is recommended to use the following option instead of ours strategy:$ git checkout obsolete $ git merge -s recursive -Xtheirs master
Ours strategy is a more radical means.
Subtree strategy
To illustrate this strategy, let's take an example from the chapter Merging the subtrees of the Pro Git book.
Add a new remote repository to our project, rack:
$ git remote add rack_remote git@github.com: schacon / rack.git $ git fetch rack_remote warning: no common commits remote: Counting objects: 3184, done. remote: Compressing objects: 100% (1465/1465), done. remote: Total 3184 (delta 1952), reused 2770 (delta 1675) Receiving objects: 100% (3184/3184), 677.42 KiB | 4 KiB / s, done. Resolving deltas: 100% (1952/1952), done. From git@github.com: schacon / rack * [new branch] build -> rack_remote / build * [new branch] master -> rack_remote / master * [new branch] rack-0.4 -> rack_remote / rack-0.4 * [new branch] rack-0.9 -> rack_remote / rack-0.9 $ git checkout -b rack_branch rack_remote / master Branch ref_branch set up to track remote branch refs / remotes / rack_remote / master. Switched to a new branch "rack_branch"
It is clear that the master and rack_branch branches have completely different working directories. Add files from rack_branch to master using squash in order to avoid clogging the history with unnecessary facts:
$ git checkout master $ git merge --squash -s subtree --no-commit rack_branch Squash commit - not updating HEAD Automatic merge went well; stopped before committing as requested
Now the files of the project rack are in our working directory.
Final word
So, I have gathered together all the knowledge that I gained while working with Git regarding the successful git-merge. I will be happy if it helps someone, but I will also be happy if someone helps me to supplement the material or correct inaccuracies and errors, if suddenly I made such.
Source: https://habr.com/ru/post/195674/
All Articles