Knowledge Base. Part 1 - Introduction
One of the reasons for the poor use of Linked Data bases in conventional, non-scientific applications is that we are not used to inventing casebooks, seeing only data in front of us. It is hard to argue with the fact that very little interconnected data is being produced in Russia now. However, this does not mean that the developer who creates the application for the Russian-speaking audience is completely cut off from the world of the semantic web: we still have something.
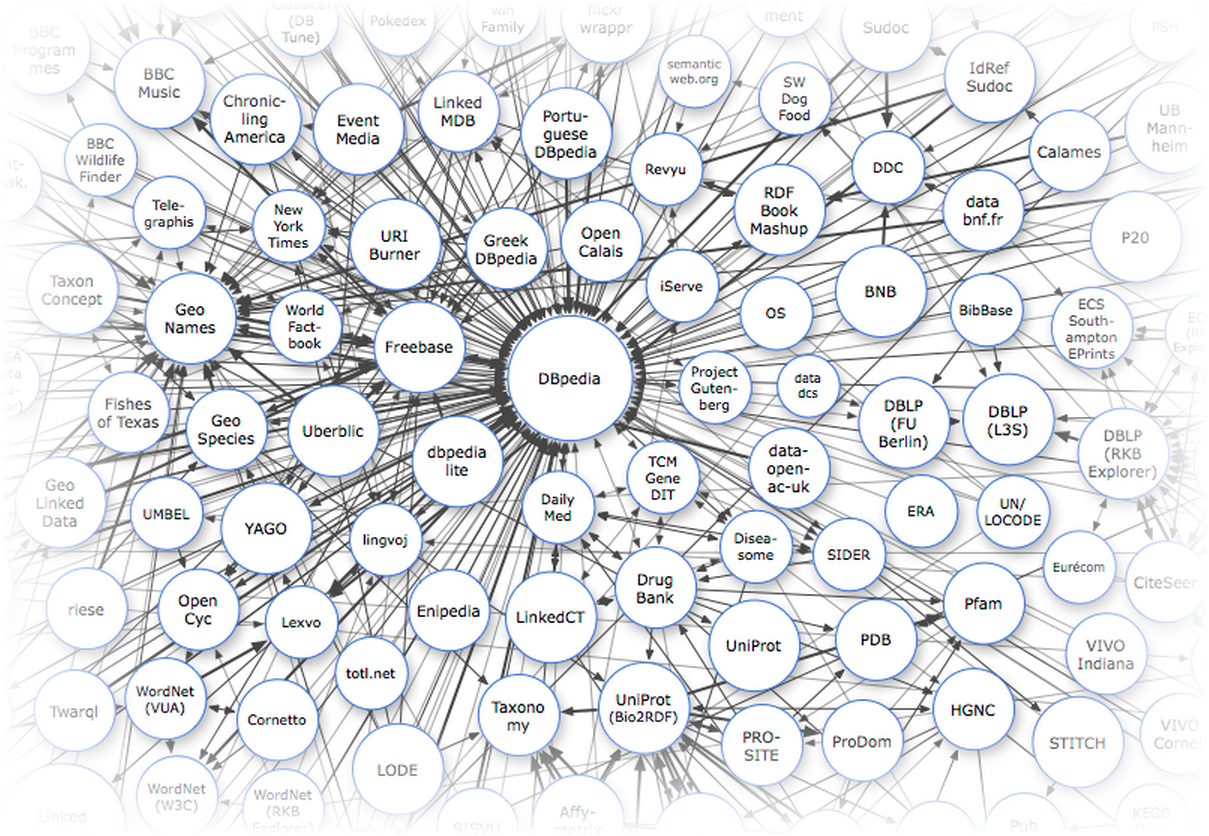
The main data sources for us are the international knowledge base, which includes Russian-language content: DBpedia , Freebase and Wikidata . First of all, it is reference, linguistic and encyclopedic data. Every time when you get the idea to parse a piece of Wikipedia or Wiktionary, pinch yourself as it should and remember that everything that is stored in categories, infoboxes or tables is already parsed and available through the API using the SPARQL or MQL interface.
I will try to give a few examples of useful encyclopedic data that you will not find anywhere else but Linked Data.
This article is the first of the Knowledge Base series. Keep for updates.
')
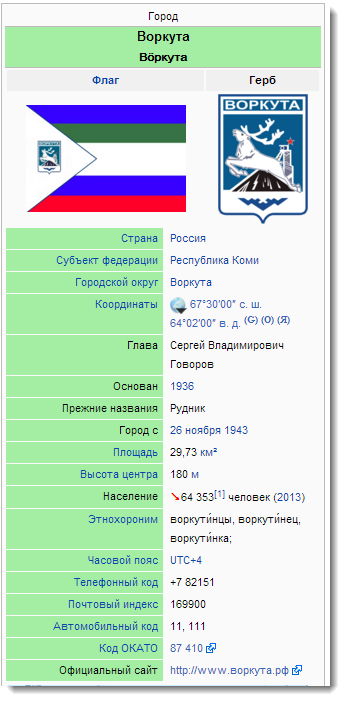 If you are interested in cities and countries, then in Linked Data you will find not only information about their location (which, to be honest, it is better to haul from other sources), but also:
If you are interested in cities and countries, then in Linked Data you will find not only information about their location (which, to be honest, it is better to haul from other sources), but also:
Please note that when we speak here, for example, of places of interest, we do not mean a pathetic list of titles sorted alphabetically. All data is divided into categories, are linked to time and place, the names of architects, eras, artistic directions. If you stumble upon a museum, you can pull out the most important exhibits displayed in it. Of course, information about the creators of these exhibits will also be available.
As elsewhere in the semantic web, we will receive lists of objects related to other objects and sometimes pointing to alternative descriptions in other databases. Tourist applications immediately come to my mind: the user can be given not just the opportunity to “see the sights in the Moscow Avenue”, but to allow him to filter only objects belonging to the neoclassicism of the first quarter of the 20th century. And if you use the DBPedia categories tree, but you can offer the user more related styles, for example, early modern.
Some geographic points are tied to events - you can learn quite a lot about them too. For example, it is quite simple to get the correlation of forces and the number of those killed in the Kulikovo or Borodino battles. Of course, the personalities with which the events are connected are not forgotten.
Such dates are often needed in analytics. For example, in order to calculate which university produces the most oligarchs / scientists / writers worthy of mention in Wikipedia.
As for films, everything looks more than strong: Freebase, Dbpedia and Linkedmdb have very, very good datasets on cinematography.
ileriseviye.wordpress.com/2012/07/11/is-semantic-web-and-linked-data-good-enough-sparql-dbpedia-vs-python-imdbpy
We not only can easily see which actor filmed where, in which year the film was released and who released it, but also find out who influenced the actor when he was born, that he has a marital status and whether he does something except filming.
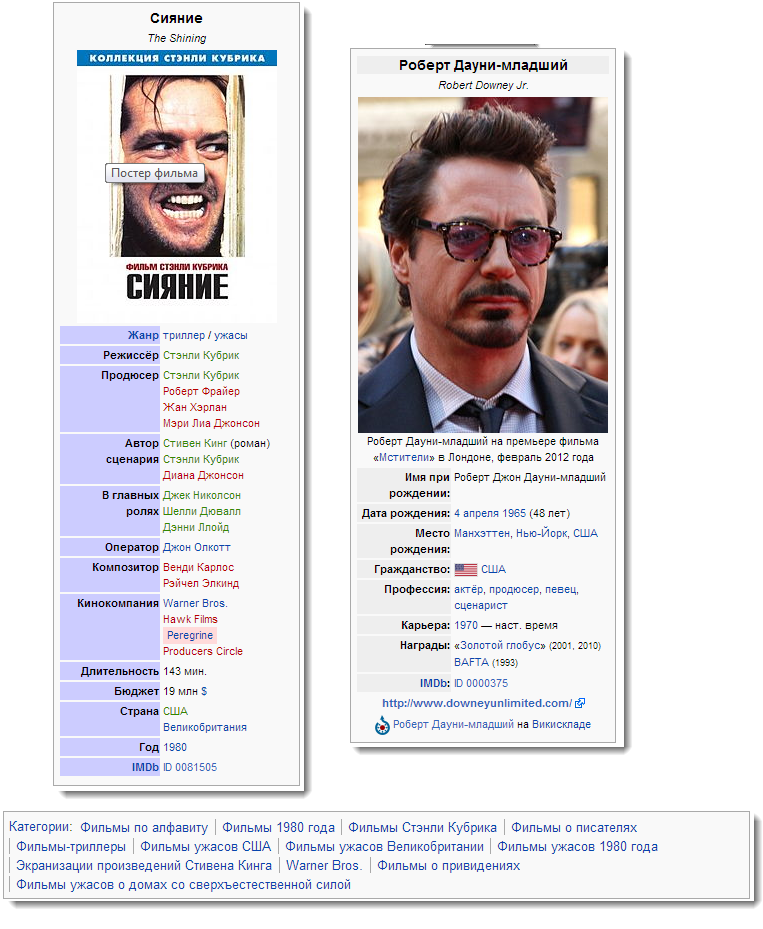
For example, this request for Dbpedia will display all the actors who have been filmed in The Shining , and in Hoffa :

The most remarkable source of data in the field of music, perhaps, is MusicBrainz . Of course, it is also in RDF, and of course, you will use traditional APIs to access them. However, Freebase and Dbpedia can be useful here too - in the latter there is, for example, information about the tours of musical groups. Well, dates of birth, influence, styles and genres - encyclopedic data for music is also present. Actually in the training materials Freebase just a musical example is used: retrieving data about the group The Police:
It would probably be interesting to use this in conjunction with the Last.fm API
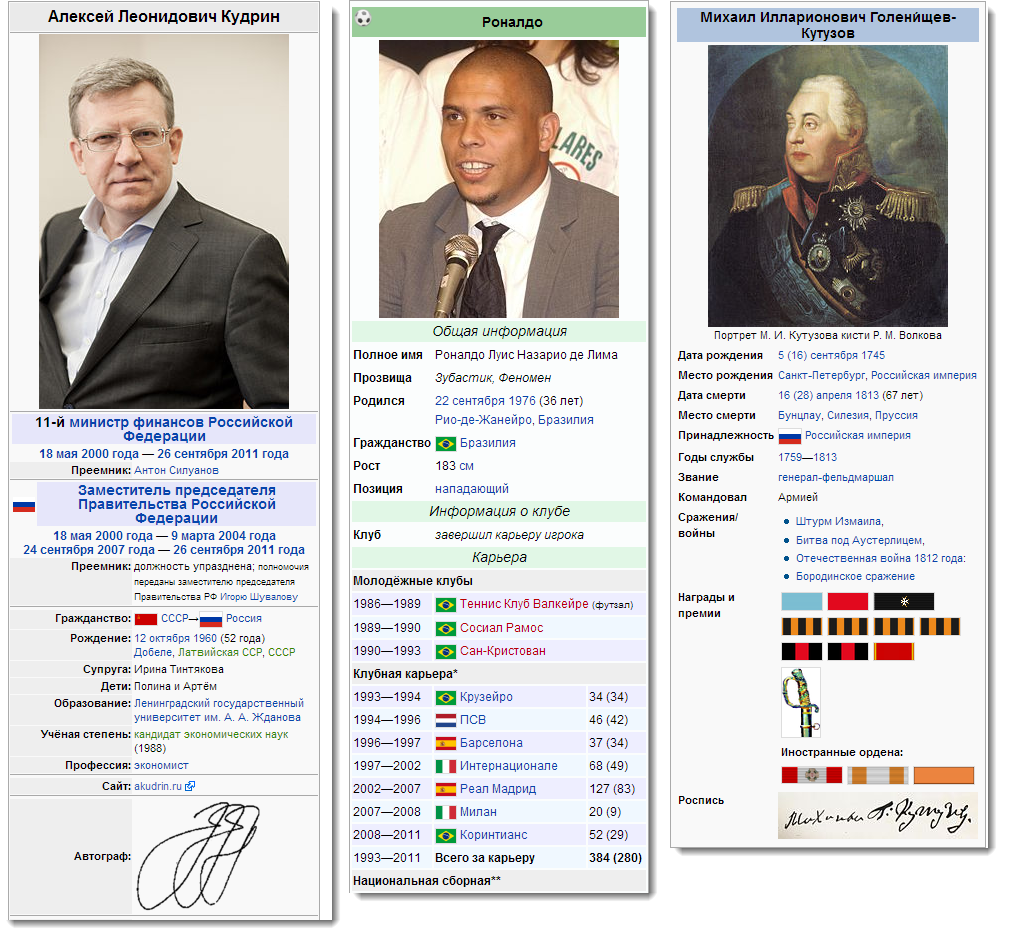
When describing personalities in Wikipedia, information boxes are used quite intensively - this gives the article a strict look. Therefore, if you are a social activist and write a website with information about politicians, you will find in Dbpedia who studied where, what awards it has and what positions it held. Applications related to sports can use athlete’s career data, height, weight, and important biography facts.
For the needs of classification and clustering, as well as problems of mathematical linguistics, hierarchies of concepts are often needed. For example, that finger is a type of body part. The Semantic Web hurries to the rescue and allows you not to parse Wikipedia categories, but to get them ready from Dbpedia or www.mpi-inf.mpg.de/yago-naga YAGO. If the size of the hierarchy is less important to you than its quality, you can look at the manually created ontologies Dbpedia, Cyc, Umbel.
At the end of 2012, the Dbpedia team launched the Wiktionary project - access to Wiktionary as a database. Now you can make requests to the English, German, French, Russian, Greek and Vietnamese. Let's try to pull out the translations for some good Russian word through the SPARQL-point Wiktionary :

There are quite a few linguists among Semantic Web enthusiasts, and therefore the linguistic world has its own cloud of interconnected data.
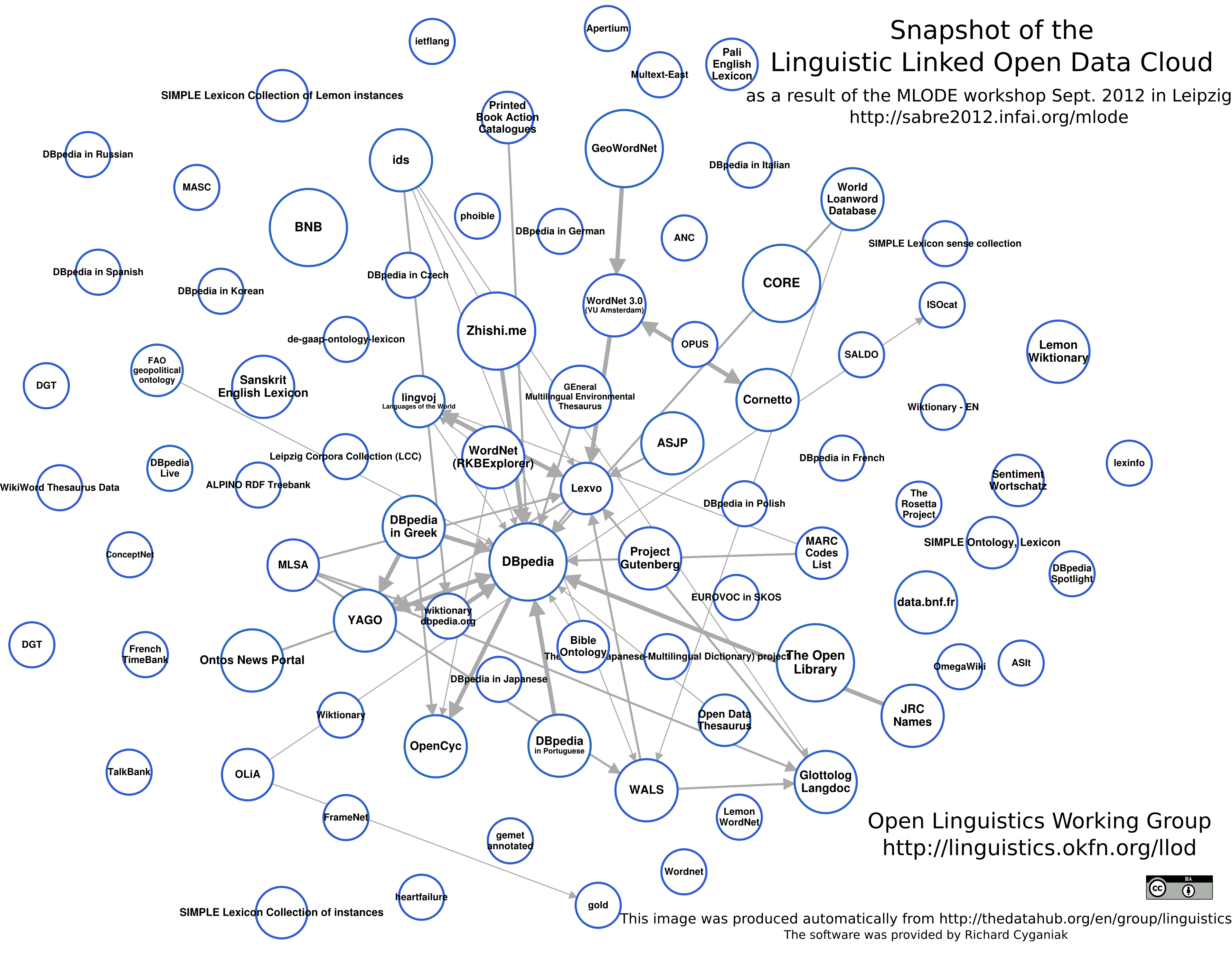
A lot of useful information on Linked and non-Linked data can be obtained from the Open Knowledge Foundation portals and our Russian NLPub .
For Freebase, on the main page there is a visualization of which categories contain the largest number of objects.
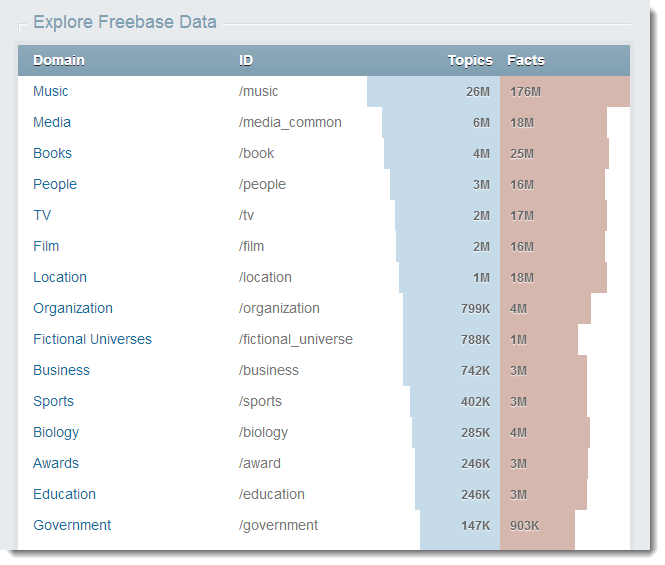
For DBPedia, an easy way to understand where quality data is hidden is also there. Refer to the Mappings.DBpedia application and its statistical summary .
Mappings are a great tool that allows DBpedia users to influence how parsers work. I will definitely tell you about the following articles in detail, but for now we will limit ourselves to this page:
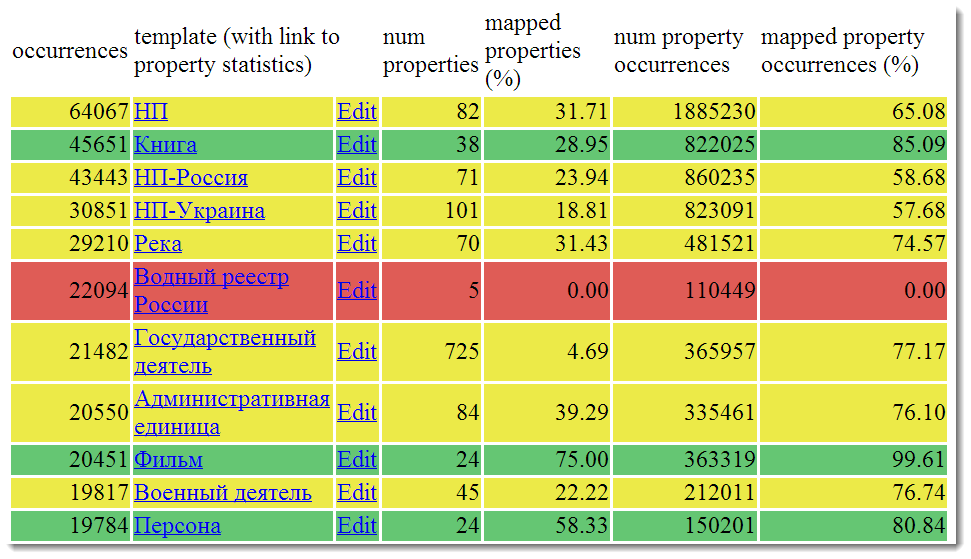
In the cells are written the names of wikipedic templates. Redder cells contain data automatically parsed automatically, greener ones indicate that the parsing was done with the participation of people, and therefore the quality of the data should be higher.
Well, what can I say, search, he is the search. We use Sig.ma , Sindice and Swoogle engines . All of them allow you to search within a single dataset or across the entire set of LInked Data.
Next time I will try to describe how to learn how to build SPARQL queries to the knowledge base Dbpedia.
The main data sources for us are the international knowledge base, which includes Russian-language content: DBpedia , Freebase and Wikidata . First of all, it is reference, linguistic and encyclopedic data. Every time when you get the idea to parse a piece of Wikipedia or Wiktionary, pinch yourself as it should and remember that everything that is stored in categories, infoboxes or tables is already parsed and available through the API using the SPARQL or MQL interface.
I will try to give a few examples of useful encyclopedic data that you will not find anywhere else but Linked Data.
This article is the first of the Knowledge Base series. Keep for updates.
')
- Part 1 - Introduction
- Part 2 - Freebase: making queries to the Google Knowledge Graph
- Part 3 - Dbpedia - Linked Data World Core
- Part 4 - Wikidata - Semantic Wikipedia
Cities, countries, historical data
If you are interested in cities and countries, then in Linked Data you will find not only information about their location (which, to be honest, it is better to haul from other sources), but also:- attractions like palaces and monuments
- born and dead famous people
- meteostatistics like monthly precipitation and time of sunrise
- coats of arms, flags
- demographics
- related historical events
Please note that when we speak here, for example, of places of interest, we do not mean a pathetic list of titles sorted alphabetically. All data is divided into categories, are linked to time and place, the names of architects, eras, artistic directions. If you stumble upon a museum, you can pull out the most important exhibits displayed in it. Of course, information about the creators of these exhibits will also be available.
As elsewhere in the semantic web, we will receive lists of objects related to other objects and sometimes pointing to alternative descriptions in other databases. Tourist applications immediately come to my mind: the user can be given not just the opportunity to “see the sights in the Moscow Avenue”, but to allow him to filter only objects belonging to the neoclassicism of the first quarter of the 20th century. And if you use the DBPedia categories tree, but you can offer the user more related styles, for example, early modern.
Some geographic points are tied to events - you can learn quite a lot about them too. For example, it is quite simple to get the correlation of forces and the number of those killed in the Kulikovo or Borodino battles. Of course, the personalities with which the events are connected are not forgotten.
SELECT DISTINCT? Strength,? Result,? Longitute,? Latitude,? Commander WHERE {
dbpedia: Battle_of_Kulikovo dbpprop: strength? strength;
dbpprop: result? result;
geo: long? longitute;
geo: lat? latitude;
dbpedia-owl: commander? commander
}
LIMIT 1000
Information about institutions, organizations, government agencies
Such dates are often needed in analytics. For example, in order to calculate which university produces the most oligarchs / scientists / writers worthy of mention in Wikipedia.
- number of staff / students / professors, for students - the number of tanks, masters, foreign students
- annual revenue
- place in ratings
- founding dates
- subsidiaries and parent companies
- executive information
Composers, musicians, films
As for films, everything looks more than strong: Freebase, Dbpedia and Linkedmdb have very, very good datasets on cinematography.
ileriseviye.wordpress.com/2012/07/11/is-semantic-web-and-linked-data-good-enough-sparql-dbpedia-vs-python-imdbpy
We not only can easily see which actor filmed where, in which year the film was released and who released it, but also find out who influenced the actor when he was born, that he has a marital status and whether he does something except filming.
For example, this request for Dbpedia will display all the actors who have been filmed in The Shining , and in Hoffa :
The most remarkable source of data in the field of music, perhaps, is MusicBrainz . Of course, it is also in RDF, and of course, you will use traditional APIs to access them. However, Freebase and Dbpedia can be useful here too - in the latter there is, for example, information about the tours of musical groups. Well, dates of birth, influence, styles and genres - encyclopedic data for music is also present. Actually in the training materials Freebase just a musical example is used: retrieving data about the group The Police:
{
"type": "/ music / album",
"name": "Synchronicity",
"artist": "The Police",
"track": [{
"name": null,
"length": null
}]
} It would probably be interesting to use this in conjunction with the Last.fm API
Personalia: politicians, athletes, historical figures
When describing personalities in Wikipedia, information boxes are used quite intensively - this gives the article a strict look. Therefore, if you are a social activist and write a website with information about politicians, you will find in Dbpedia who studied where, what awards it has and what positions it held. Applications related to sports can use athlete’s career data, height, weight, and important biography facts.
Linguistic applications. Category Hierarchy
For the needs of classification and clustering, as well as problems of mathematical linguistics, hierarchies of concepts are often needed. For example, that finger is a type of body part. The Semantic Web hurries to the rescue and allows you not to parse Wikipedia categories, but to get them ready from Dbpedia or www.mpi-inf.mpg.de/yago-naga YAGO. If the size of the hierarchy is less important to you than its quality, you can look at the manually created ontologies Dbpedia, Cyc, Umbel.
Linguistic applications. Wiktionary and translations
At the end of 2012, the Dbpedia team launched the Wiktionary project - access to Wiktionary as a database. Now you can make requests to the English, German, French, Russian, Greek and Vietnamese. Let's try to pull out the translations for some good Russian word through the SPARQL-point Wiktionary :
There are quite a few linguists among Semantic Web enthusiasts, and therefore the linguistic world has its own cloud of interconnected data.
A lot of useful information on Linked and non-Linked data can be obtained from the Open Knowledge Foundation portals and our Russian NLPub .
How to find good data
For Freebase, on the main page there is a visualization of which categories contain the largest number of objects.
For DBPedia, an easy way to understand where quality data is hidden is also there. Refer to the Mappings.DBpedia application and its statistical summary .
Mappings are a great tool that allows DBpedia users to influence how parsers work. I will definitely tell you about the following articles in detail, but for now we will limit ourselves to this page:
In the cells are written the names of wikipedic templates. Redder cells contain data automatically parsed automatically, greener ones indicate that the parsing was done with the participation of people, and therefore the quality of the data should be higher.
Search
Well, what can I say, search, he is the search. We use Sig.ma , Sindice and Swoogle engines . All of them allow you to search within a single dataset or across the entire set of LInked Data.
Next time I will try to describe how to learn how to build SPARQL queries to the knowledge base Dbpedia.
Source: https://habr.com/ru/post/195650/
All Articles