Using short-term characteristics in speech processing
Below is a free translation of the record from the Sakshat Virtual Labs website .
Need for Short Term Processing of Speech
The article contains information on one of the methods for collecting speech signal characteristics and on the three main characteristics that underlie many audio signal and speech processing algorithms.
Most signal processing tools work in stationary systems, i.e. imply a stationary signal. Speech is reproduced by the vocal tract system and therefore it is non-stationary in nature. Therefore, conventional tools that are used to process signals are not suitable for speech processing. Using them directly violates the underlying assumptions. And even if you blindly use them, the result will still not be of practical importance. For example, the means for calculating the total energy is fundamental in the field of signal processing:
 Suppose you can use this formula to calculate speech energy. Undoubtedly, this will give us the energy present in the speech signal. However, the resulting value will not give us anything. The reason is in the nature of speech - we know that it has amplitude and energy varying in time, therefore a tool is needed that would provide information about changes in energy over time.
Suppose you can use this formula to calculate speech energy. Undoubtedly, this will give us the energy present in the speech signal. However, the resulting value will not give us anything. The reason is in the nature of speech - we know that it has amplitude and energy varying in time, therefore a tool is needed that would provide information about changes in energy over time.
It was proposed a solution for speech processing, which consisted in the use of already known methods from the field of signal processing with their small modification. That is, the processing tools used still assumed a stationary signal. A stationary speech signal is obtained when viewed in small blocks of 10-30ms each. Consequently, for speech processing by different signal processing means, it is considered in blocks of 10-30 ms (hereinafter, this section will be called a speech signal). Such processing is called Short Term Processing (STP).
Speech STP can be performed in the time or frequency domains. The choice of area depends on what information we want to extract from the speech. For example, parameters such as short term energy, short term zero crossing rate and short term autocorrelation can be calculated in the time domain, and Fourier transforms can be calculated in the frequency domain. Each of these parameters provides some information about speech, and can be used for processing.
')
Let us call energy an abstract quantity that characterizes a signal. Speech energy changes over time due to its nature and therefore, for any automatic processing it is important to know how this energy changes over time. By origin, the speech signal consists of speech / non-speech segments / silence. The energy of the section with speech is larger in magnitude than the energy of the non-speech section, while the energy of silence is close to zero. Thus, the characteristic of short term energy can be used in the classification of voice / non-voice areas on the basis of the presence of speech or silence.
The formula for finding short-term energy can be derived from the total energy formula defined in the signal processing area. There, the total signal energy is calculated as follows:
 To calculate the short-term energy, we consider a speech segment with a duration of 10-30ms. Assume that the samples in the frame are listed as “n = 0 to n = N-1”, where N is the frame duration (the number of samples). Outside the frame, the energy will be zero. Thus we get:
To calculate the short-term energy, we consider a speech segment with a duration of 10-30ms. Assume that the samples in the frame are listed as “n = 0 to n = N-1”, where N is the frame duration (the number of samples). Outside the frame, the energy will be zero. Thus we get:

That is, the formula gives the full energy in the speech block.
 where w (n) is a window function — several such functions are mentioned in the signal processing literature. Most commonly used
where w (n) is a window function — several such functions are mentioned in the signal processing literature. Most commonly used
rectangular window:
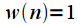 Hanna window:
Hanna window:
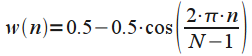 or Hamming window:
or Hamming window:
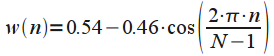 For all characteristics that are calculated in the time domain, we will use a rectangular window because of its simplicity.
For all characteristics that are calculated in the time domain, we will use a rectangular window because of its simplicity.
Now you can write the calculation formula for short term energy:
 where n is the shift in the samples. Since the changes in energy in the case of speech are insignificant, then there is no sense in considering short term energy with a small shift. Therefore, most often it is set equal to or less than half of the frame.
where n is the shift in the samples. Since the changes in energy in the case of speech are insignificant, then there is no sense in considering short term energy with a small shift. Therefore, most often it is set equal to or less than half of the frame.
 The last thing worth noting at the expense of short-term energy is the frame size. Since speech becomes approximately stationary in blocks of 10 to 30 ms, usually for a frame, a size of 20 ms is chosen. If you choose a larger size, we will get a smoother picture of energy and we may not notice how it changes.
The last thing worth noting at the expense of short-term energy is the frame size. Since speech becomes approximately stationary in blocks of 10 to 30 ms, usually for a frame, a size of 20 ms is chosen. If you choose a larger size, we will get a smoother picture of energy and we may not notice how it changes.
Zero Crossing Rate gives information on the number of changes in the sign of the function (the function of the OX axis function). If the number of crossings is large in some signal, then the signal contains high-frequency information and vice versa. Thus, ZCR provides information about the frequency content of a signal.
In the case of a stationary signal, the ZCR is considered as follows:
 This formula can be corrected for a non-stationary signal like speech and called short term ZCR:
This formula can be corrected for a non-stationary signal like speech and called short term ZCR:

 By the nature of speech, the signal changes with time after a few ms. In order to get some information, it is necessary to calculate ZCR on frames with the same duration of 10-30ms and a shift equal to half of the frame. Above is a schedule of processing the recorded sentence “she had your suit in your greasy wash water all year”. On the vowel sound "s", the characteristic value significantly exceeds the value on the vowel "a".
By the nature of speech, the signal changes with time after a few ms. In order to get some information, it is necessary to calculate ZCR on frames with the same duration of 10-30ms and a shift equal to half of the frame. Above is a schedule of processing the recorded sentence “she had your suit in your greasy wash water all year”. On the vowel sound "s", the characteristic value significantly exceeds the value on the vowel "a".
In signal processing, cross-correlation can be used to find similarities between two sequences, and autocorrelation requires only one sequence and determines how much the signal resembles itself in time.
For a non-stationary signal, the autocorrelation is calculated using the following formula:
 where s w = s (m) w (nm) is the window version of s (n). The result is a short term autocorellation sequence. The nature of this sequence is different for sections with and without speech.
where s w = s (m) w (nm) is the window version of s (n). The result is a short term autocorellation sequence. The nature of this sequence is different for sections with and without speech.

 And although the topic of autocorrelation is completely not disclosed, it would be inappropriate not to mention it in the context of this topic.
And although the topic of autocorrelation is completely not disclosed, it would be inappropriate not to mention it in the context of this topic.
PS The next article finally anticipates the implementation of the calculation of some of the characteristics in order for the material to be clearer.
Need for Short Term Processing of Speech
The article contains information on one of the methods for collecting speech signal characteristics and on the three main characteristics that underlie many audio signal and speech processing algorithms.
Most signal processing tools work in stationary systems, i.e. imply a stationary signal. Speech is reproduced by the vocal tract system and therefore it is non-stationary in nature. Therefore, conventional tools that are used to process signals are not suitable for speech processing. Using them directly violates the underlying assumptions. And even if you blindly use them, the result will still not be of practical importance. For example, the means for calculating the total energy is fundamental in the field of signal processing:
It was proposed a solution for speech processing, which consisted in the use of already known methods from the field of signal processing with their small modification. That is, the processing tools used still assumed a stationary signal. A stationary speech signal is obtained when viewed in small blocks of 10-30ms each. Consequently, for speech processing by different signal processing means, it is considered in blocks of 10-30 ms (hereinafter, this section will be called a speech signal). Such processing is called Short Term Processing (STP).
Speech STP can be performed in the time or frequency domains. The choice of area depends on what information we want to extract from the speech. For example, parameters such as short term energy, short term zero crossing rate and short term autocorrelation can be calculated in the time domain, and Fourier transforms can be calculated in the frequency domain. Each of these parameters provides some information about speech, and can be used for processing.
')
Short Term Energy
Let us call energy an abstract quantity that characterizes a signal. Speech energy changes over time due to its nature and therefore, for any automatic processing it is important to know how this energy changes over time. By origin, the speech signal consists of speech / non-speech segments / silence. The energy of the section with speech is larger in magnitude than the energy of the non-speech section, while the energy of silence is close to zero. Thus, the characteristic of short term energy can be used in the classification of voice / non-voice areas on the basis of the presence of speech or silence.
The formula for finding short-term energy can be derived from the total energy formula defined in the signal processing area. There, the total signal energy is calculated as follows:
That is, the formula gives the full energy in the speech block.
rectangular window:
Now you can write the calculation formula for short term energy:
Short Term Zero Crossing Rate (ZCR)
Zero Crossing Rate gives information on the number of changes in the sign of the function (the function of the OX axis function). If the number of crossings is large in some signal, then the signal contains high-frequency information and vice versa. Thus, ZCR provides information about the frequency content of a signal.
In the case of a stationary signal, the ZCR is considered as follows:
Short Term Autocorrelation
In signal processing, cross-correlation can be used to find similarities between two sequences, and autocorrelation requires only one sequence and determines how much the signal resembles itself in time.
For a non-stationary signal, the autocorrelation is calculated using the following formula:
PS The next article finally anticipates the implementation of the calculation of some of the characteristics in order for the material to be clearer.
Source: https://habr.com/ru/post/195448/
All Articles