How to measure content relevance
Content evaluation is one of the main components of the relevance formula. Knowledge of textual signs and the contribution of each of them to the evaluation of the site will allow you to get closer to more professional work with the resource. This article will review the model that allows you to restore the ranking formula for each specific request, indicates the significance of the definition of the site when promoting a specific request, and also addresses the issue of determining an unnatural text.
Restoration of the ranking formula
If we translate this problem into the field of mathematics, then the input data can be represented by a set of vectors, where each vector is the set of characteristics of each site, and the coordinates in the vector are the parameter by which the site is evaluated. In the described vector space, a function must be defined that determines the ratio of the order of two objects to each other. This function allows you to rank objects among themselves according to the principle “more - less”, however, at the same time, it is impossible to say just how much more or less of the other. These types of tasks are related to the tasks of estimating ordinal regression.
Our employees developed an algorithm based on a linear regression model with adjustable selectivity, which allowed us to restore the ranks of sites with a certain degree of error and predict the change in output with appropriate adjustments of site parameters. The first step of the algorithm is to train the model. In this case, the training sample represents the results of ranking sites within a single search query. The orderliness of sites within the search query actually means that there is a certain direction in the feature space, to which the objects of the training sample must be designed in the right order. This direction is required in the task of restoring the ranking formula. However, judging by Figure 1, there may be many such areas.
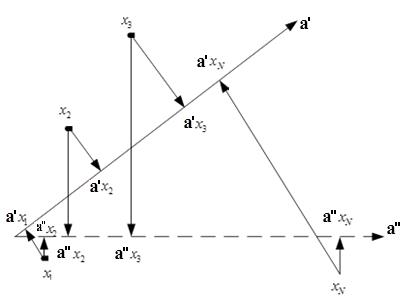
Fig. 1. The choice of the guiding vector
')
To address this issue, the approach underlying the method of anchor points was considered, namely, the choice of such a direction that will ensure maximum removal of objects from each other.
The next task that was solved was the choice of a learning strategy. Two options were considered - an abbreviated learning strategy, which takes into account the order of the two corresponding elements, and a complete strategy, which takes into account the entire order of objects. As a result of the experiments, an abbreviated strategy was chosen, which consists in solving the following equation: (1)
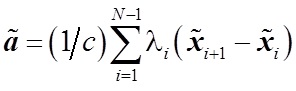 where
where 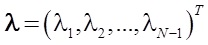 - solution of the standard quadratic programming problem with linear constraints:
- solution of the standard quadratic programming problem with linear constraints: 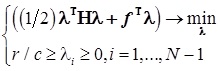 where
where
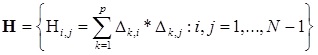 - symmetric matrix
- symmetric matrix
 - coefficient vector
- coefficient vector
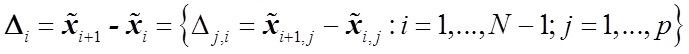 - the difference of the vectors of characteristics
- the difference of the vectors of characteristics
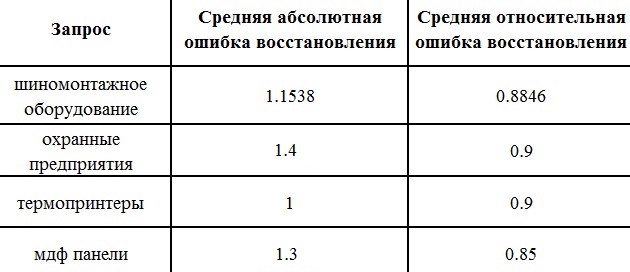
This approach on different samples (100 signs and 500 signs on 20 different sets of search queries) showed good results (see Table 1).
Table 1. Results of the reduced model

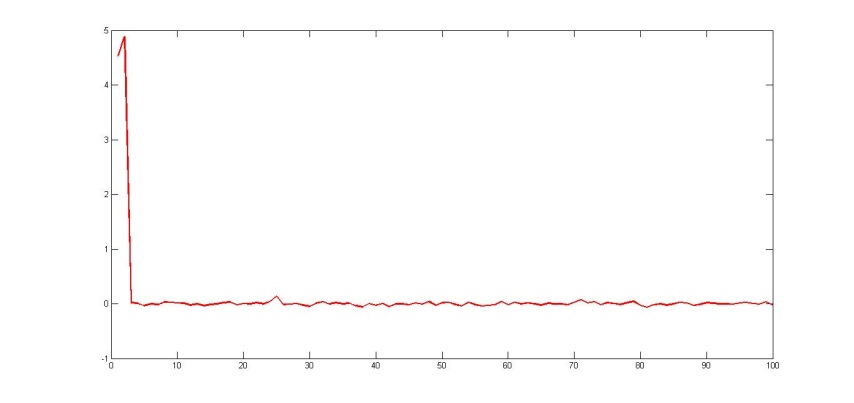
Fig. 2. Restored regression coefficients with n = 100
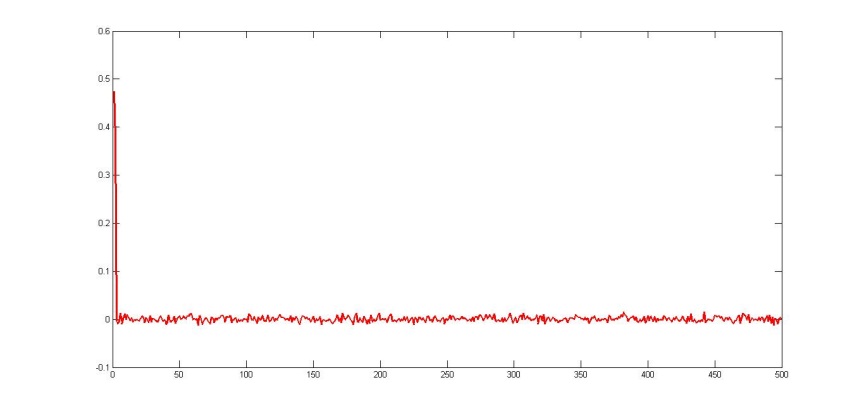
Fig. 3. Restored regression coefficients with n = 500
If we talk about the results on specific queries, the experiments performed give the following error indicator
Table 2. Calculation Errors
When working on a project, this approach was used to predict positions with a specific change on the site. Similar experiments were conducted on the basis of textual signs. Initially, data were collected from the TOP20 sites for the request under consideration, then the data were standardized using an appropriate algorithm. After that, the algorithm was performed directly on the calculation of "relevance" using the quadratic programming method.
The obtained values of the relevance of the site are sorted and the conclusion about the restored positions is drawn.
Table 3. Restoration of positions

It was found that the greatest impact on the position when ranking the request "tire fitting equipment" brings signs: the presence in the Yandex catalog, the entry of the first word from the query "tire", the entry in h1 of the first word of the query "tire", the entry in the title page of the second word of the query " equipment".
Appropriate adjustments were made to the site parameters and the program was launched. As a result, a forecast was given for the corresponding position.
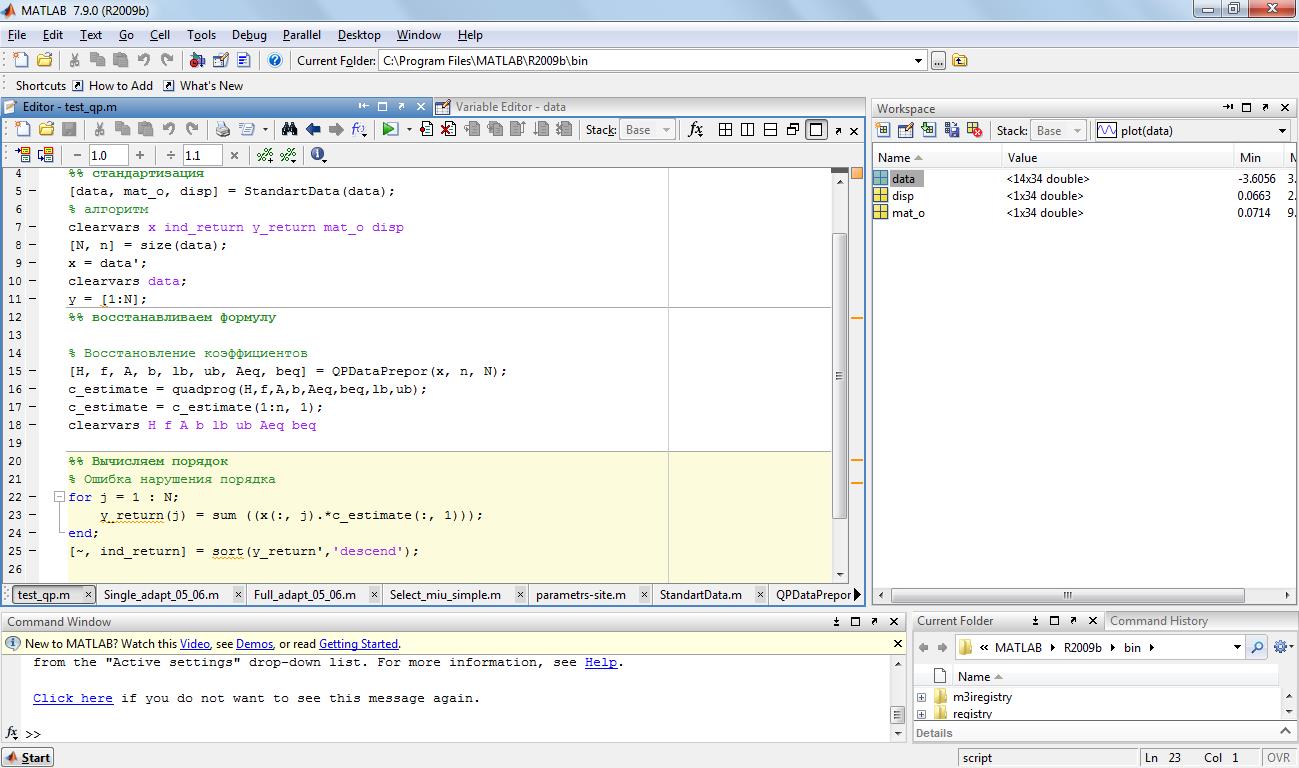
Fig. 4. Program restoring the ranking formula
All these changes were made on the site. After the next update, the site took positions close to those predicted. The initial position was 50, after these changes it amounted to the TOP20.
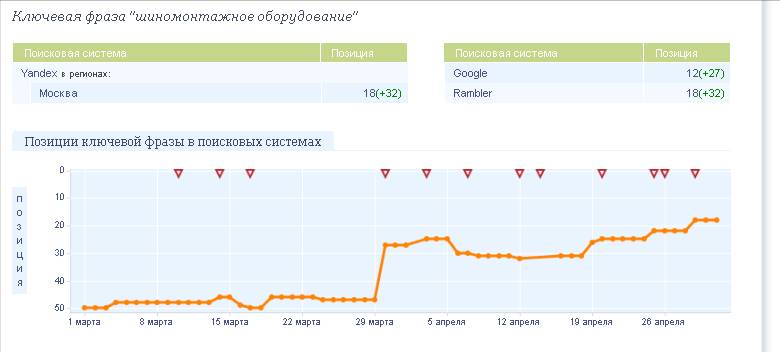
Fig.5. The results of the promotion request "tire equipment"
Text subject measurement
In working with the restoration of the ranking formula, the importance of measuring the thematic proximity of the subject matter of the text in relation to the subject of the entire site was confirmed. Such a metric can be constructed based on the calculation of the cosine between the vectors of the relevant subject of the page relevant to the query and the entire site: (2)
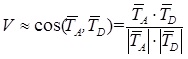
Where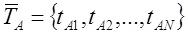 and
and  accordingly, the vector designation of the theme of the site and the document in question.
accordingly, the vector designation of the theme of the site and the document in question.
N is the number of words in the dictionary collection. The weight of each word j in the document Di is calculated by the formula: (3)

where countij is the number of occurrences of the word in the document, IDFwj is the inverse frequency of the word in the collection. After calculating the weight of each word in the document, the vector is normalized: (4)
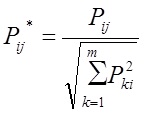
Similarly, the vector is constructed for the entire site, and the text of the site is obtained by combining the texts of all the documents included in it.
Thus, the algorithm for determining the thematic value of the document can be represented as follows:
1) A dictionary is defined, in which there are no rare and stop words, i.e. IDF words that form the dictionary, lies in the range of meaningful words.
2) An N-dimensional subject vector is built. for the document in question
for the document in question 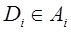 using formulas 3 and 4.
using formulas 3 and 4.
3) Built N-dimensional vector of subject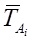 for the whole site
for the whole site 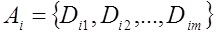 using formulas 3 and 4.
using formulas 3 and 4.
4) Using (2) establishes the proximity of the vectors and . The closer the vector, the thematic value of the document above.
On the basis of this model, a program was written, allowing to determine the thematic similarity of the considered document and the textual component of the site itself. The experiments were conducted on the basis of 3 groups of sites: with the same theme, with a similar theme, with different themes. A total of 200 articles were processed. As a result of processing, the following data was obtained for 20 groups of “1 test document / 9 training documents” presented in the table.
Table 4. Results of thematic completeness check
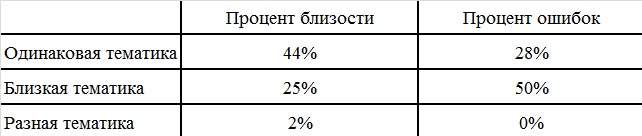
The table shows that the proposed method for determining the thematic completeness of an information resource works in practice: checked documents located on sites with a more comprehensive topic, have higher rates. However, the shortcomings of the developed system were also revealed. Firstly, sites often have uninformative or uninformative pages (order forms, feedback, contacts, etc.). Secondly, when choosing a randomly specified number of training texts, you can select non-thematic pages. Thirdly, non-specific content may come across as test texts, but they are similar in topics, for example, the spelling of a word. Fourthly, there are sites that cover different thematic areas, while intersecting in meaning (online shopping, news sites, banks of abstracts).
With the listed shortcomings, the overall picture allows us to evaluate the thematic fullness of the resource. As an example, consider the site of the logistics theme with requests for equipment (there is a catalog on the site, in addition to information about logistics). The site is registered in Yandex.Catalog and has a “forwarding and transportation of goods” rubric:
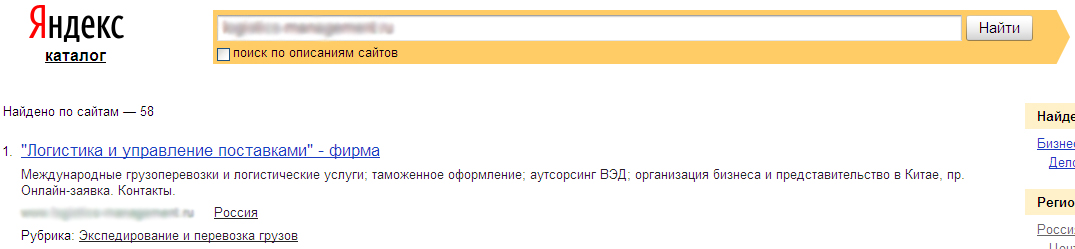
Fig. 6. The rubric assigned in the catalog. Yandex
When using the method discussed above, it was concluded that the thematic completeness of the pages promoted is not complete with respect to the requests of the “transportation and delivery from China” subject, but it is sufficiently large with respect to the subject “equipment”. The ratio of pages "logistics: equipment" was respectively "30: 200." Accordingly, the position and traffic was only in requests related to equipment. In this case, the priority was "logistics". To solve the problem, a letter was written to Yandex in order to obtain detailed information. However, the standard response of “Plato” about the improvement and development of the site was received, but in general everything is in order.
As a solution, there was a choice between the development of the required topics on the site and the separation of two topics into different subdomains. Won the need to get quick results. TK was compiled for transferring the “equipment” direction to the subdomain, and the main site saved information on “logistics”, as well as the development of the resource by adding new relevant subject pages. The result of the changes is shown in Fig. Requests for equipment successfully moved to the subdomain and took a positive position. And after adding thematic pages on logistics and requests for transportation, they began to show a positive trend.
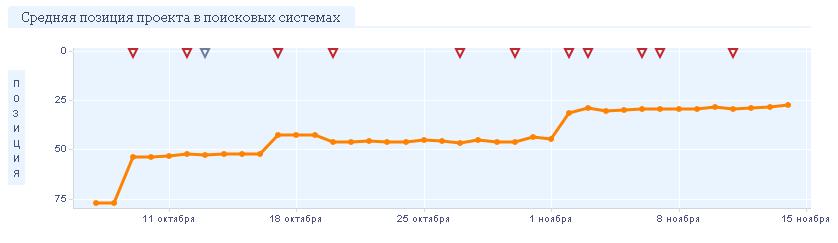
Fig. 6. Results of promotion, after breeding topics
Thus, due to the “subdomain + domain” scheme, it was possible to spread the topics without a loss and thereby increase the relevance of each of the topics separately and achieve a positive trend on requests.
Measuring the naturalness of the text
Requirements for entering Yandex.Catalog are being tightened. Recently, we have to deal with the fact that when checking a site, Yandex employees report low-quality content. Identifying this fact manually on a large site seems to be a problem. Therefore, at present, work is underway to analyze the characteristics of these texts. I will tell about some of them. There are two main approaches to receiving spam text: the replacement of Russian letters with Latin letters and the generation of content devoid of meaning.
The first approach is opened by identifying the modified words using an inverted frequency and comparing with the established empirical critical value. Words formed by replacing Russian letters with similar Latin letters are rare words from the point of view of usage statistics. With the help of the inverted frequency of the general collection can identify such words. Each element of the text node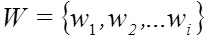 matched value
matched value  using the inverted frequency function fh: (5)
using the inverted frequency function fh: (5)
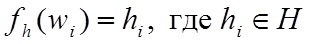
As a function of the inverted frequency were considered: (6), (7), (8).
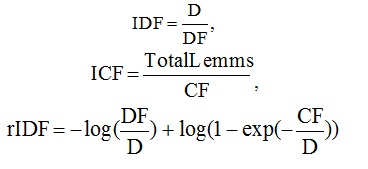
Here D is the number of documents in the collection, DF is the number of documents in which the lemma is found, CF is the number of occurrences of the lemma in the collection, TotalLemms is the total number of occurrences of all the lemmas in the collection. Of these options, the best result in the experiment, as well as in the research of Gulin A. showed ICF (7), therefore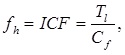 where is the number of occurrences of the lemma in the text under consideration, is the total number of occurrences of all the lemmas in the set.
where is the number of occurrences of the lemma in the text under consideration, is the total number of occurrences of all the lemmas in the set.
The greater the value of the function fh, the less often the word occurs. To obtain the ICF interval of significant words, a program was written, to the input of which texts of various contents were submitted (elimination of thematic influence). The program processed about 500 MB of textual information. As a result of processing, a dictionary of reverse frequencies of the ICF words in normal form was obtained. The lemmatization of words was carried out using the mystem parser, Yandex. All elements of the dictionary were sorted in order of increasing reverse frequency. As a result of the analysis of this dictionary, the interval of significant words was obtained: [500; 191703].
To establish the criterion for identifying spam texts, a critical value H crit is also entered and Hp percent of words are counted, whose characteristic exceeds the critical value H crit determined by empirically: (9)
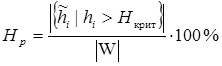
As a critical mark, the percentage of insignificant words is 50% (the highest indicator of the frequency of official words is 37.60%, and the average of the words created by the author is 5.63%). A large percentage of the use of Hp in one text of such word formations will indicate that the document is generated.
However, there are not enough websites with such spam texts. The second approach is more common. There is a class of unnatural texts generated by the use of generators based on Markov chains. Based on the research Pavlova A.S. A model has been proposed to identify such texts.
All textual component B of document D has a number of signs.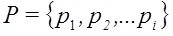 difficult to control by the author. To build an automatic classifier of unnatural texts, selected features in machine learning are used. The algorithm being developed is based on decision trees C4.5. The algorithm itself for determining unnatural text is as follows:
difficult to control by the author. To build an automatic classifier of unnatural texts, selected features in machine learning are used. The algorithm being developed is based on decision trees C4.5. The algorithm itself for determining unnatural text is as follows:
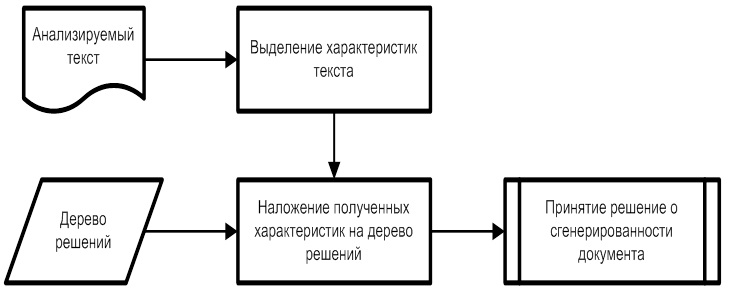
Fig. 7. Algorithm for determining generated content
To obtain a decision tree, a base of natural texts in the amount of 2000 was prepared and a base of unnatural texts of 2000 volume also, some found on the Internet, some generated, the rest obtained by synonymizing sample documents or by translating from foreign languages. The original collection was the ROMIP By.Web collection. Generation and synonymization tools were found on the Internet (TextoGEN, Generating The Web 2.2, SeoGenerator and others).
The resulting set of texts was divided into two equal parts. The first group was used as a training set, and the second part was a test set. Both samples had an equal number of sample documents and generated texts.
For the learning process, a program was written that, for each text, built a vector that evaluates parameters affecting the definition of the naturalness of the text. According to the study Pavlova A.S. The greatest contribution to learning is a list of parameters that determine the text diversity and frequency of use of parts of speech. The table contains a list of the most valuable features for the classification of Russian texts, for each feature the F-measure and type of feature are indicated.
Table 5. The most valuable features for the classification of texts

According to the obtained vectors P of each of the document D, a decision tree was built. This procedure was carried out using the analytical platform Deductor Studio Academic version 5.2. In the Deductor, the basis of the decision tree handler is a modified C4.5 algorithm that solves the classification problem. As a result, a tree was built with 157 nodes and 79 rules. In fig. presented part of the resulting tree. The obtained rules were used in the main program in determining the spam texts of the site.
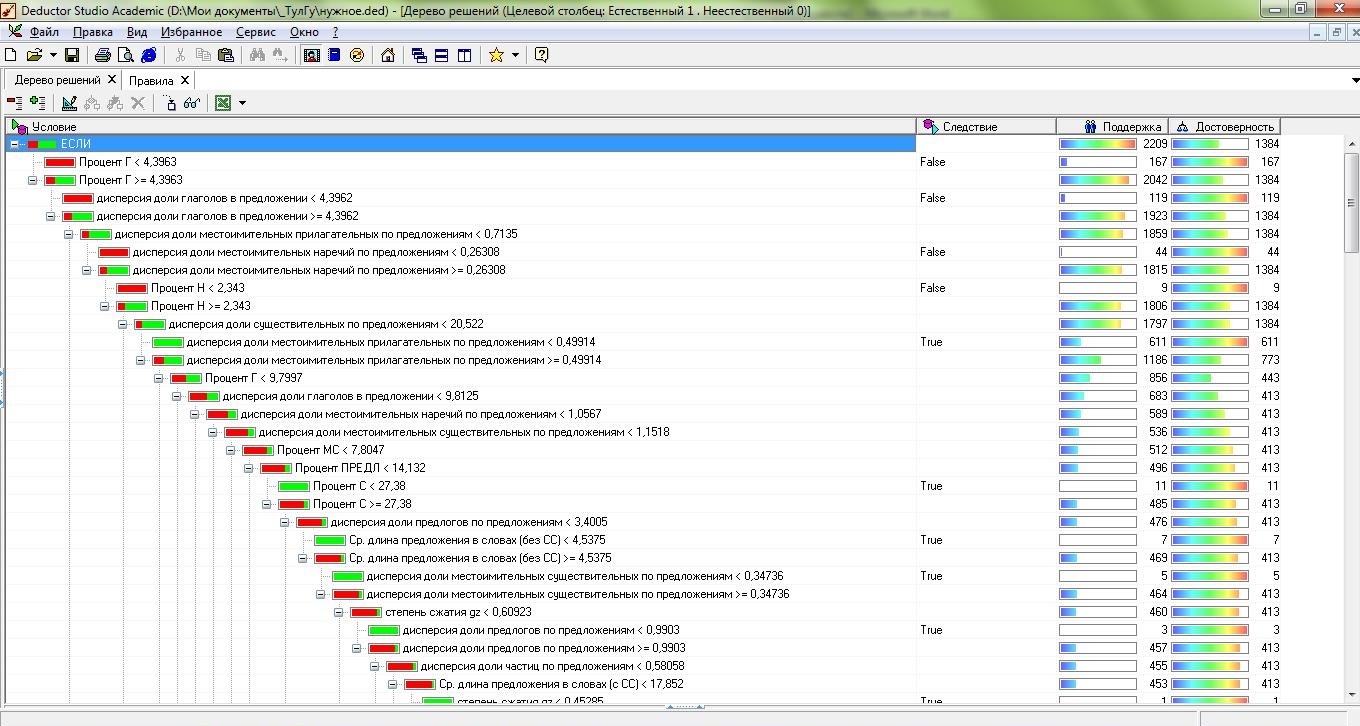
Fig. 8. Decision Tree. Analytical platform Deductor 5.2.

Fig. 9. The result of the program for analyzing texts
In practice, this approach helped to discover the reason for the lack of dynamics on requests. The program detected generated texts on all pages of the site categories. During the investigation, it was found out that they represent the machine translation content of the same site, but of the English version.
Fig. 10. Texts on category pages
After editing these texts, even only on pages that were promoted, good dynamics was obtained: requests from the TOP500 immediately hit the TOP10 in 9 weeks.
Fig. 11. An example of a modified text.
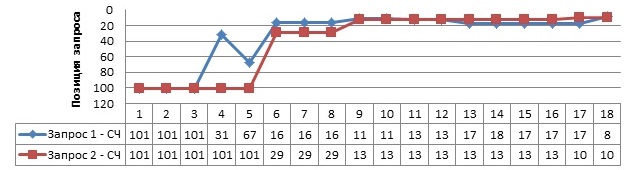
Fig. 12. Changing positions by weeks after laying out.
In conclusion, it should be noted that the development of the considered functionals is not obligatory! It is useful in global search engine research. When promoting a site, it is sufficient to develop an approach that allows point-to-point work with queries based on the analysis of the TOP. There are many natural tools for this:
1) Check how many relevant pages are available on request and compare with competitors - you can evaluate the text completeness of the site
2) Pay attention to the highlighted words in verbose queries in the saved copy - help in writing texts, how far words can stand apart
3) Use the query language. For example, analyzing the issue of exact request and without quotes, you can identify problems with the text component
4) Through the advanced search, search for specific sites and analyze which pages and why are higher than promoted
5) Results of Webmasters. Yandex and Webmasters. Google, these metrics and GA will also help to identify problems and work with them.
Purposeful activity on requests always gives a positive result.
Authors of the article: Neyolova N.V. (Candidate of Technical Sciences, head of the PP department of Ingate), Polenova Ye.A. (Ingate team leader)
Restoration of the ranking formula
If we translate this problem into the field of mathematics, then the input data can be represented by a set of vectors, where each vector is the set of characteristics of each site, and the coordinates in the vector are the parameter by which the site is evaluated. In the described vector space, a function must be defined that determines the ratio of the order of two objects to each other. This function allows you to rank objects among themselves according to the principle “more - less”, however, at the same time, it is impossible to say just how much more or less of the other. These types of tasks are related to the tasks of estimating ordinal regression.
Our employees developed an algorithm based on a linear regression model with adjustable selectivity, which allowed us to restore the ranks of sites with a certain degree of error and predict the change in output with appropriate adjustments of site parameters. The first step of the algorithm is to train the model. In this case, the training sample represents the results of ranking sites within a single search query. The orderliness of sites within the search query actually means that there is a certain direction in the feature space, to which the objects of the training sample must be designed in the right order. This direction is required in the task of restoring the ranking formula. However, judging by Figure 1, there may be many such areas.
Fig. 1. The choice of the guiding vector
')
To address this issue, the approach underlying the method of anchor points was considered, namely, the choice of such a direction that will ensure maximum removal of objects from each other.
The next task that was solved was the choice of a learning strategy. Two options were considered - an abbreviated learning strategy, which takes into account the order of the two corresponding elements, and a complete strategy, which takes into account the entire order of objects. As a result of the experiments, an abbreviated strategy was chosen, which consists in solving the following equation: (1)
where - solution of the standard quadratic programming problem with linear constraints: where - symmetric matrix - coefficient vector - the difference of the vectors of characteristicsThis approach on different samples (100 signs and 500 signs on 20 different sets of search queries) showed good results (see Table 1).
Table 1. Results of the reduced model
Fig. 2. Restored regression coefficients with n = 100
Fig. 3. Restored regression coefficients with n = 500
If we talk about the results on specific queries, the experiments performed give the following error indicator
Table 2. Calculation Errors
When working on a project, this approach was used to predict positions with a specific change on the site. Similar experiments were conducted on the basis of textual signs. Initially, data were collected from the TOP20 sites for the request under consideration, then the data were standardized using an appropriate algorithm. After that, the algorithm was performed directly on the calculation of "relevance" using the quadratic programming method.
The obtained values of the relevance of the site are sorted and the conclusion about the restored positions is drawn.
Table 3. Restoration of positions
It was found that the greatest impact on the position when ranking the request "tire fitting equipment" brings signs: the presence in the Yandex catalog, the entry of the first word from the query "tire", the entry in h1 of the first word of the query "tire", the entry in the title page of the second word of the query " equipment".
Appropriate adjustments were made to the site parameters and the program was launched. As a result, a forecast was given for the corresponding position.
Fig. 4. Program restoring the ranking formula
All these changes were made on the site. After the next update, the site took positions close to those predicted. The initial position was 50, after these changes it amounted to the TOP20.
Fig.5. The results of the promotion request "tire equipment"
Text subject measurement
In working with the restoration of the ranking formula, the importance of measuring the thematic proximity of the subject matter of the text in relation to the subject of the entire site was confirmed. Such a metric can be constructed based on the calculation of the cosine between the vectors of the relevant subject of the page relevant to the query and the entire site: (2)
Where
and accordingly, the vector designation of the theme of the site and the document in question.N is the number of words in the dictionary collection. The weight of each word j in the document Di is calculated by the formula: (3)
where countij is the number of occurrences of the word in the document, IDFwj is the inverse frequency of the word in the collection. After calculating the weight of each word in the document, the vector is normalized: (4)
Similarly, the vector is constructed for the entire site, and the text of the site is obtained by combining the texts of all the documents included in it.
Thus, the algorithm for determining the thematic value of the document can be represented as follows:
1) A dictionary is defined, in which there are no rare and stop words, i.e. IDF words that form the dictionary, lies in the range of meaningful words.
2) An N-dimensional subject vector is built.
for the document in question using formulas 3 and 4.3) Built N-dimensional vector of subject
for the whole site using formulas 3 and 4.4) Using (2) establishes the proximity of the vectors
and . The closer the vector, the thematic value of the document above.On the basis of this model, a program was written, allowing to determine the thematic similarity of the considered document and the textual component of the site itself. The experiments were conducted on the basis of 3 groups of sites: with the same theme, with a similar theme, with different themes. A total of 200 articles were processed. As a result of processing, the following data was obtained for 20 groups of “1 test document / 9 training documents” presented in the table.
Table 4. Results of thematic completeness check
The table shows that the proposed method for determining the thematic completeness of an information resource works in practice: checked documents located on sites with a more comprehensive topic, have higher rates. However, the shortcomings of the developed system were also revealed. Firstly, sites often have uninformative or uninformative pages (order forms, feedback, contacts, etc.). Secondly, when choosing a randomly specified number of training texts, you can select non-thematic pages. Thirdly, non-specific content may come across as test texts, but they are similar in topics, for example, the spelling of a word. Fourthly, there are sites that cover different thematic areas, while intersecting in meaning (online shopping, news sites, banks of abstracts).
With the listed shortcomings, the overall picture allows us to evaluate the thematic fullness of the resource. As an example, consider the site of the logistics theme with requests for equipment (there is a catalog on the site, in addition to information about logistics). The site is registered in Yandex.Catalog and has a “forwarding and transportation of goods” rubric:
Fig. 6. The rubric assigned in the catalog. Yandex
When using the method discussed above, it was concluded that the thematic completeness of the pages promoted is not complete with respect to the requests of the “transportation and delivery from China” subject, but it is sufficiently large with respect to the subject “equipment”. The ratio of pages "logistics: equipment" was respectively "30: 200." Accordingly, the position and traffic was only in requests related to equipment. In this case, the priority was "logistics". To solve the problem, a letter was written to Yandex in order to obtain detailed information. However, the standard response of “Plato” about the improvement and development of the site was received, but in general everything is in order.
As a solution, there was a choice between the development of the required topics on the site and the separation of two topics into different subdomains. Won the need to get quick results. TK was compiled for transferring the “equipment” direction to the subdomain, and the main site saved information on “logistics”, as well as the development of the resource by adding new relevant subject pages. The result of the changes is shown in Fig. Requests for equipment successfully moved to the subdomain and took a positive position. And after adding thematic pages on logistics and requests for transportation, they began to show a positive trend.
Fig. 6. Results of promotion, after breeding topics
Thus, due to the “subdomain + domain” scheme, it was possible to spread the topics without a loss and thereby increase the relevance of each of the topics separately and achieve a positive trend on requests.
Measuring the naturalness of the text
Requirements for entering Yandex.Catalog are being tightened. Recently, we have to deal with the fact that when checking a site, Yandex employees report low-quality content. Identifying this fact manually on a large site seems to be a problem. Therefore, at present, work is underway to analyze the characteristics of these texts. I will tell about some of them. There are two main approaches to receiving spam text: the replacement of Russian letters with Latin letters and the generation of content devoid of meaning.
The first approach is opened by identifying the modified words using an inverted frequency and comparing with the established empirical critical value. Words formed by replacing Russian letters with similar Latin letters are rare words from the point of view of usage statistics. With the help of the inverted frequency of the general collection can identify such words. Each element of the text node
matched value using the inverted frequency function fh: (5)As a function of the inverted frequency were considered: (6), (7), (8).
Here D is the number of documents in the collection, DF is the number of documents in which the lemma is found, CF is the number of occurrences of the lemma in the collection, TotalLemms is the total number of occurrences of all the lemmas in the collection. Of these options, the best result in the experiment, as well as in the research of Gulin A. showed ICF (7), therefore
where is the number of occurrences of the lemma in the text under consideration, is the total number of occurrences of all the lemmas in the set.The greater the value of the function fh, the less often the word occurs. To obtain the ICF interval of significant words, a program was written, to the input of which texts of various contents were submitted (elimination of thematic influence). The program processed about 500 MB of textual information. As a result of processing, a dictionary of reverse frequencies of the ICF words in normal form was obtained. The lemmatization of words was carried out using the mystem parser, Yandex. All elements of the dictionary were sorted in order of increasing reverse frequency. As a result of the analysis of this dictionary, the interval of significant words was obtained: [500; 191703].
To establish the criterion for identifying spam texts, a critical value H crit is also entered and Hp percent of words are counted, whose characteristic exceeds the critical value H crit determined by empirically: (9)
As a critical mark, the percentage of insignificant words is 50% (the highest indicator of the frequency of official words is 37.60%, and the average of the words created by the author is 5.63%). A large percentage of the use of Hp in one text of such word formations will indicate that the document is generated.
However, there are not enough websites with such spam texts. The second approach is more common. There is a class of unnatural texts generated by the use of generators based on Markov chains. Based on the research Pavlova A.S. A model has been proposed to identify such texts.
All textual component B of document D has a number of signs.
difficult to control by the author. To build an automatic classifier of unnatural texts, selected features in machine learning are used. The algorithm being developed is based on decision trees C4.5. The algorithm itself for determining unnatural text is as follows:Fig. 7. Algorithm for determining generated content
To obtain a decision tree, a base of natural texts in the amount of 2000 was prepared and a base of unnatural texts of 2000 volume also, some found on the Internet, some generated, the rest obtained by synonymizing sample documents or by translating from foreign languages. The original collection was the ROMIP By.Web collection. Generation and synonymization tools were found on the Internet (TextoGEN, Generating The Web 2.2, SeoGenerator and others).
The resulting set of texts was divided into two equal parts. The first group was used as a training set, and the second part was a test set. Both samples had an equal number of sample documents and generated texts.
For the learning process, a program was written that, for each text, built a vector that evaluates parameters affecting the definition of the naturalness of the text. According to the study Pavlova A.S. The greatest contribution to learning is a list of parameters that determine the text diversity and frequency of use of parts of speech. The table contains a list of the most valuable features for the classification of Russian texts, for each feature the F-measure and type of feature are indicated.
Table 5. The most valuable features for the classification of texts
According to the obtained vectors P of each of the document D, a decision tree was built. This procedure was carried out using the analytical platform Deductor Studio Academic version 5.2. In the Deductor, the basis of the decision tree handler is a modified C4.5 algorithm that solves the classification problem. As a result, a tree was built with 157 nodes and 79 rules. In fig. presented part of the resulting tree. The obtained rules were used in the main program in determining the spam texts of the site.
Fig. 8. Decision Tree. Analytical platform Deductor 5.2.
Fig. 9. The result of the program for analyzing texts
In practice, this approach helped to discover the reason for the lack of dynamics on requests. The program detected generated texts on all pages of the site categories. During the investigation, it was found out that they represent the machine translation content of the same site, but of the English version.
Fig. 10. Texts on category pages
After editing these texts, even only on pages that were promoted, good dynamics was obtained: requests from the TOP500 immediately hit the TOP10 in 9 weeks.
Fig. 11. An example of a modified text.
Fig. 12. Changing positions by weeks after laying out.
In conclusion, it should be noted that the development of the considered functionals is not obligatory! It is useful in global search engine research. When promoting a site, it is sufficient to develop an approach that allows point-to-point work with queries based on the analysis of the TOP. There are many natural tools for this:
1) Check how many relevant pages are available on request and compare with competitors - you can evaluate the text completeness of the site
2) Pay attention to the highlighted words in verbose queries in the saved copy - help in writing texts, how far words can stand apart
3) Use the query language. For example, analyzing the issue of exact request and without quotes, you can identify problems with the text component
4) Through the advanced search, search for specific sites and analyze which pages and why are higher than promoted
5) Results of Webmasters. Yandex and Webmasters. Google, these metrics and GA will also help to identify problems and work with them.
Purposeful activity on requests always gives a positive result.
Authors of the article: Neyolova N.V. (Candidate of Technical Sciences, head of the PP department of Ingate), Polenova Ye.A. (Ingate team leader)
Source: https://habr.com/ru/post/195134/
All Articles