HBase, loading large data arrays through bulk load
Hello colleagues.
I want to share my experience using HBase, namely, to tell about bulk loading . This is another method for loading data. It is fundamentally different from the usual approach (writing to the table through the client). It is believed that with the bulk load you can very quickly load huge data arrays. This is what I decided to understand.
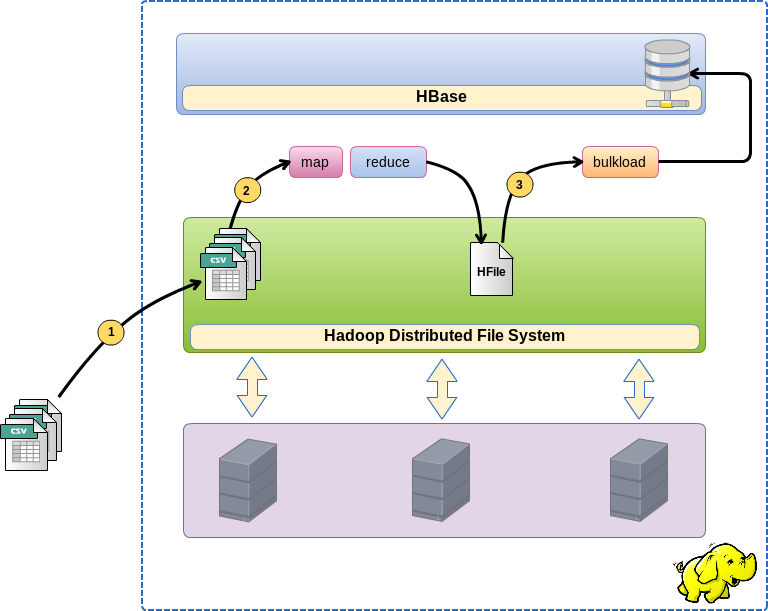
And so, first things first. Loading through bulk load occurs in three stages:
')
In this case, I needed to feel this technology and understand it in numbers: what is the speed, how it depends on the number and size of files. These numbers are too dependent on external conditions, but they help to understand the orders between normal loading and bulk load.
Cluster running Cloudera CDH4, HBase 0.94.6-cdh4.3.0.
Three virtual hosts (on the hypervisor), in the configuration CentOS / 4CPU / RAM 8GB / HDD 50GB
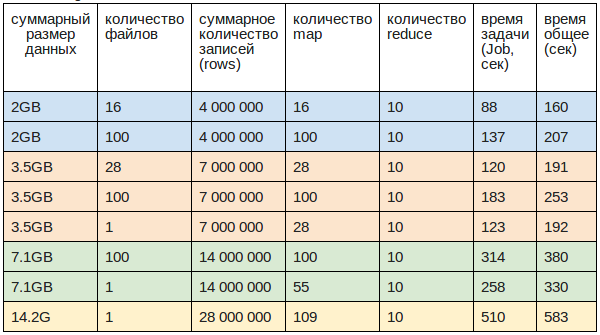
Test data was stored in CSV files of various sizes, with a total volume of 2GB, 3.5GB, 7.1GB and 14.2GB
First, about the results:
Bulk loading
Speed:
Size of one record (row): 0.5Kb
MapReduce Job Initialization Time: 70 sec
Downloading files to HDFS from the local file system:
Loading was carried out from 2 hosts on 8 flows on each.
Clients were launched over the crown at the same time, the CPU load did not exceed 40%
The size of one record (row), as in the previous case, was equal to 0.5Kb.
I decided to implement this test in the wake of talking about bulk load as a method of ultrafast data loading. It should be said that the official documentation deals only with reducing the load on the network and the CPU. Anyway, I do not see a gain in speed. Tests show that bulk load is only one and a half times faster, but let's not forget that this is without taking into account the initialization of m / r Joba. In addition, the data must be delivered in HDFS, it will also take some time.
I think it’s worthwhile to treat bulk load simply as another way to load data, architecturally different (in some cases, very convenient).
Theoretically, everything is quite simple, but in practice there are several technical nuances.
Therefore, you must run Job on behalf of the user hbase or distribute rights to the output files (this is how I did).
In general, that's all. I want to say that this is a rather rough test, without tricky optimizations, so if you have something to add, I will be glad to hear.
All project code is available on GitHub: github.com/2anikulin/hbase-bulk-load
I want to share my experience using HBase, namely, to tell about bulk loading . This is another method for loading data. It is fundamentally different from the usual approach (writing to the table through the client). It is believed that with the bulk load you can very quickly load huge data arrays. This is what I decided to understand.
And so, first things first. Loading through bulk load occurs in three stages:
- We put data files in HDFS
- We launch the MapReduce task, which converts the source data directly into HFile files, in the future, HBase stores its data in such files.
- We start bulk load function which will flood (will tie) the received files in the table HBase.
')
In this case, I needed to feel this technology and understand it in numbers: what is the speed, how it depends on the number and size of files. These numbers are too dependent on external conditions, but they help to understand the orders between normal loading and bulk load.
Initial data:
Cluster running Cloudera CDH4, HBase 0.94.6-cdh4.3.0.
Three virtual hosts (on the hypervisor), in the configuration CentOS / 4CPU / RAM 8GB / HDD 50GB
Test data was stored in CSV files of various sizes, with a total volume of 2GB, 3.5GB, 7.1GB and 14.2GB
First, about the results:
Bulk loading
Speed:
- Max 29.2 Mb / sec or 58K rec / sec (3.5GB in 28 files)
- Average 27 Mb / sec or 54K rec / sec (working speed, closer to reality)
- Min 14.5 Mb / sec or 29K rec / sec (2GB in 100 files)
- 1 file is loaded 20% faster than 100
Size of one record (row): 0.5Kb
MapReduce Job Initialization Time: 70 sec
Downloading files to HDFS from the local file system:
- 3.5GB / 1 file - 65 sec
- 7.5GB / 100 - 150 sec
- 14.2G / 1 file - 285 sec
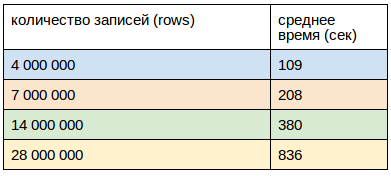
Download via clients:
Loading was carried out from 2 hosts on 8 flows on each.
Clients were launched over the crown at the same time, the CPU load did not exceed 40%
The size of one record (row), as in the previous case, was equal to 0.5Kb.
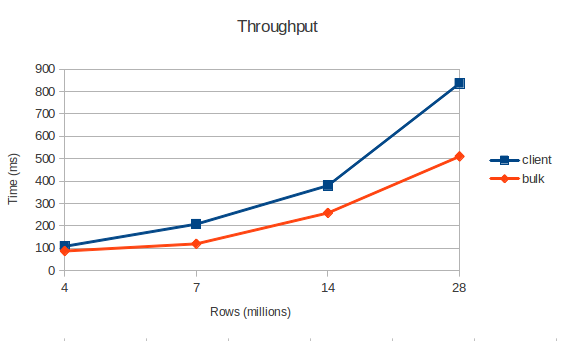
What is the result?
I decided to implement this test in the wake of talking about bulk load as a method of ultrafast data loading. It should be said that the official documentation deals only with reducing the load on the network and the CPU. Anyway, I do not see a gain in speed. Tests show that bulk load is only one and a half times faster, but let's not forget that this is without taking into account the initialization of m / r Joba. In addition, the data must be delivered in HDFS, it will also take some time.
I think it’s worthwhile to treat bulk load simply as another way to load data, architecturally different (in some cases, very convenient).
And now about the implementation
Theoretically, everything is quite simple, but in practice there are several technical nuances.
// Job job = new Job(configuration, JOB_NAME); job.setJarByClass(BulkLoadJob.class); job.setMapOutputKeyClass(ImmutableBytesWritable.class); job.setMapOutputValueClass(Put.class); job.setMapperClass(DataMapper.class); job.setNumReduceTasks(0); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(HFileOutputFormat.class); FileInputFormat.setInputPaths(job, inputPath); HFileOutputFormat.setOutputPath(job, new Path(outputPath)); HTable dataTable = new HTable(jobConfiguration, TABLE_NAME); HFileOutputFormat.configureIncrementalLoad(job, dataTable); // ControlledJob controlledJob = new ControlledJob( job, null ); JobControl jobController = new JobControl(JOB_NAME); jobController.addJob(controlledJob); Thread thread = new Thread(jobController); thread.start(); . . . // output setFullPermissions(JOB_OUTPUT_PATH); // bulk-load LoadIncrementalHFiles loader = new LoadIncrementalHFiles(jobConfiguration); loader.doBulkLoad( new Path(JOB_OUTPUT_PATH), dataTable ); - MapReduce Job creates output files with the rights of the user on whose behalf it was launched.
- bulk load always runs as hbase, so it cannot read files prepared for it, and crashes with this exception: org.apache.hadoop.security.AccessControlException: Permission denied: user = hbase
Therefore, you must run Job on behalf of the user hbase or distribute rights to the output files (this is how I did).
- It is necessary to create a table HBase. By default, it is created with one region. This leads to the fact that only one reducer is created and the recording goes only to one node, loading it 100% while the rest smoke.
Therefore, when creating a new table, you need to make a pre-split. In my case, the table was divided into 10 regions uniformly scattered throughout the cluster.
// - HTableDescriptor descriptor = new HTableDescriptor( Bytes.toBytes(tableName) ); descriptor.addFamily( new HColumnDescriptor(Constants.COLUMN_FAMILY_NAME) ); HBaseAdmin admin = new HBaseAdmin(config); byte[] startKey = new byte[16]; Arrays.fill(startKey, (byte) 0); byte[] endKey = new byte[16]; Arrays.fill(endKey, (byte)255); admin.createTable(descriptor, startKey, endKey, REGIONS_COUNT); admin.close(); - MapReduce Job writes to the output directory, which we specify to it, but at the same time creates subdirectories of the same name with column family. Files are created there
In general, that's all. I want to say that this is a rather rough test, without tricky optimizations, so if you have something to add, I will be glad to hear.
All project code is available on GitHub: github.com/2anikulin/hbase-bulk-load
Source: https://habr.com/ru/post/195040/
All Articles