Intellectual Internet Spider Architecture
It was necessary to somehow extract information from the Internet. Found a suitable site, looked at the device pages. It turned out that much is hidden from the eye of all downloading wget. The standard HTTrack assembly did not help either. I wanted to write a spider for Scrapy, but I didn't get a feeling of reliability and scalability. I began to think twice, and to reinvent the wheel, more precisely, to write my own web crawler.
I found various articles on the development of tools for downloading sites on the Internet, but I didn’t like them because of their limitations, which is acceptable only for examples, but not for real tasks. I will cite only two main ones. First, it is necessary to foresee the analysis of all types of pages. Secondly, almost always the information is unloaded at a time, and in case of an error, everything just starts up again.
I forgot about my previous crafts for the time, put it aside, and directed all my concentration on architecture, an article about which is not shameful and will be laid out on Habré.
')
Simplification for the sake of narration was the name chosen by “InCr” (InCr), which is an abbreviation from Intellectual Crawler, and also the beginning of the word Incredible (incredible).
InKr should be a platform that itself implements the basic functions of managing tasks, downloading and storing documents. From the developer’s side, it is necessary to write parsers for a specific site. During the analysis, the following basic requirements were formulated:
1. Possibility of flexible load settings: limiting the number of threads, suspending processing for authentication, captcha recognition, etc .;
2. Independence of loading pages and their analysis, the possibility of re-analysis of previously downloaded pages;
3. Support for the development of the parser: separately all documents that could not be completely disassembled are marked;
4. The possibility of supplementing the data obtained on the basis of information of several pages;
5. Continue the process of loading pages after stopping;
6. Correct processing of changes;
7. Simultaneous work with several sites and sets of rules.
As a task, consider downloading and parsing information from the forum. For definiteness, let it be the phpBB forum www.phpbb.com/community . Interested in users, forums, topics and posts. It should be provided to download new messages and topics, as well as authorization to display hidden sections. Immediately, the analysis itself presents no difficulties, but when implementing the loading of a new site, this should limit the efforts of the developer.
Maybe now I think that I am engaged in a meaningless business, since such decisions and articles already exist. I will be grateful if in the comments or in a personal message let me know about them.
Further in the article I will describe the proposed IncR architecture, as well as implementation paths. If there is no ready-made solution, then in the next article I will give the implementation itself, taking into account your comments.
In Inkra select the following main modules (functional blocks):
1. Preparation (Initialization, I): responsible for authentication, receiving cookies, recognizing captcha, caching DNS records, etc .;
2. Download (Download, D): downloads a specific page;
3. Check (Check, C): check the correctness of the download, for example, on the page size, timeout, error 404, etc .;
4. Parsing (Parse, P): parsing the page according to the rules;
5. Extraction (E): retrieving data from a parsed page, possibly using additional directories and data;
6. Update (Update, U): update data in the database;
7. Monitoring (M): processing data from other modules, logging, providing information about the current status.
The diagram briefly presents the main ways of interaction between the modules.
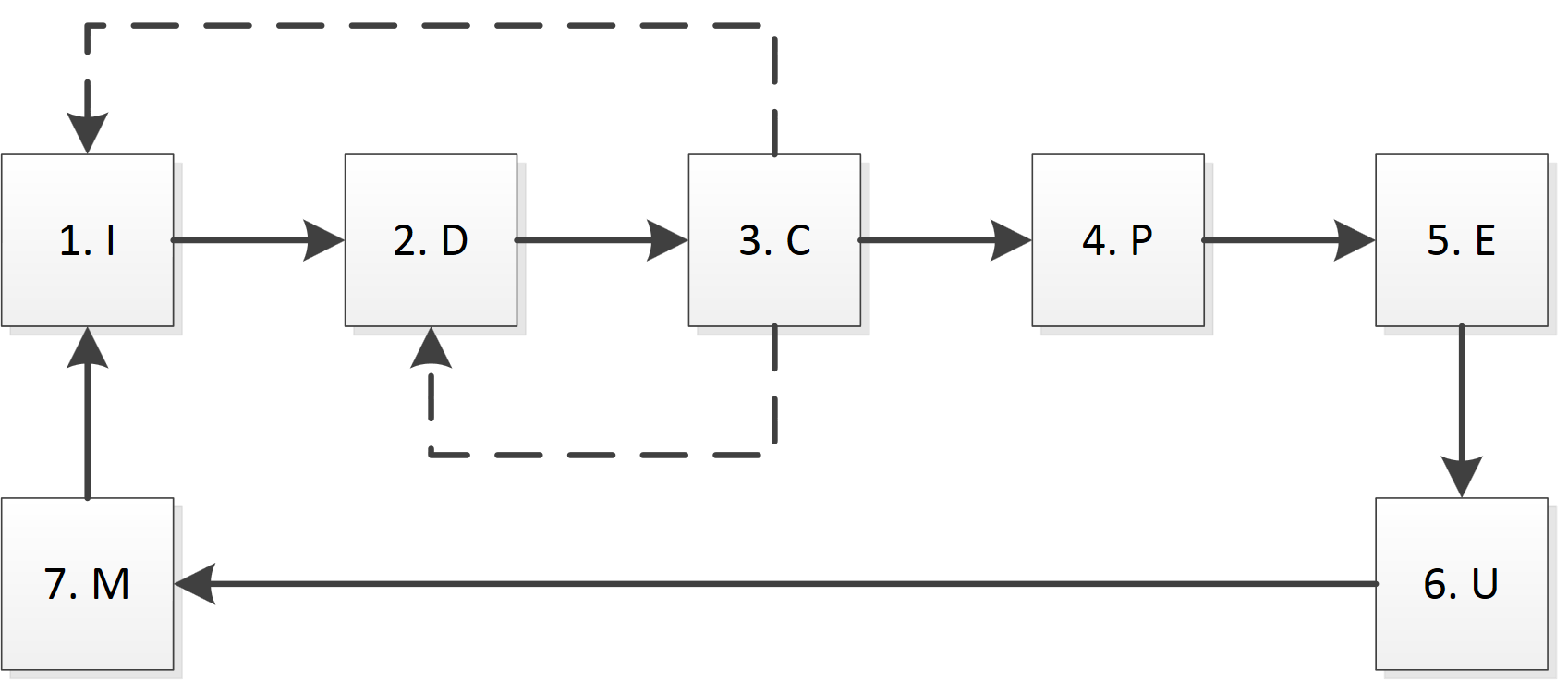
I want to emphasize the importance of the first and third blocks. In the preparation block (I), all operations are performed that are necessary to start working with a specific server, as well as the processing of "non-standard" pages. It is possible that before receiving pages with data it is necessary to perform port knocking, download a specific page (or picture) to receive a cookie, and prove that a person visits the page (captcha, security question). It also defines and creates threads and queues for a specific server. In fact, this module can make decisions about pausing the download, as well as resuming it after eliminating the cause of the error. Within the system, this block should be one for each site, since, for example, re-authentication can lead to a session reset.
The verification module is necessary for the rapid assessment of the correctness of loading a specific page. Although in time it works immediately after the download block (D), but often it has an individual implementation for each site. A correct page does not mean that there is exactly what you need, because the site may report an authorization error, the need to authenticate, retry after some time, the inability to find a suitable page, etc. As a recognition criteria, you can use the abbreviated parsing module (P), but in addition you need to learn how to handle error messages.
Also, the parsing unit (P) and the extraction unit (E) are separated from each other. The reason for this is that the purpose of parsing is to analyze the page and extract fragments with data, and the extraction already binds the data to specific objects. Parsing works at the HTML level and is limited to a specific page, and the extraction block is already working with data and can use information from previously loaded pages.
In the update block (U), the task is complicated by the fact that the data must be combined, and they may contain a different number of fields and be correct only at certain points in time.
The purpose of the control module (M) is not only to obtain information on the current status and process of operations, but also to identify failures and the possibility of restarting from any stage. For example, we created the first version of the parser, with the help of which the phpBB forum was successfully downloaded. Then it turned out that there are poll topics, then it is enough just to refine the parser and re-start the parsing for all pages that are already downloaded.
InKr of the first version will be described in the next article, if it does not appear that there is a ready-made solution that is comparable in functionality with the stated above.
I will be glad to your comments.
What are the flaws in architecture? What needs to be corrected? Where do you feel the emergence of potential problems?
Source: https://habr.com/ru/post/194914/
All Articles