Weather forecast
Considering the various data storage technologies and solutions offered by LSI, we forgot a little about the practical and practical sense of this all. Why do we need ever-increasing speeds and disk capacity? One of the first applications that come to mind is, of course, Big Data or Big Data. How does this Big Data differ from just big to earn a capital letter? This is commonly referred to as the “three V rule”.
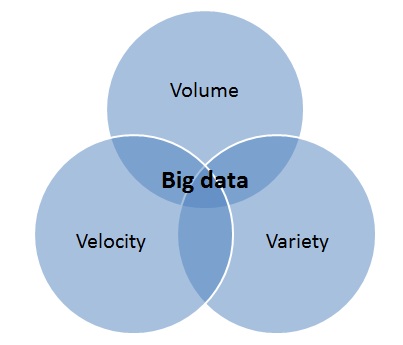
Volume (volume) - it is logical that “big data” is primarily distinguished by large volumes.
Velocity (speed) - in this case it means both the speed of accumulation of this data, and the need for high speed of their processing.
Variety (diversity) - data is often or poorly structured, or they are well structured, but many different structures must be processed at the same time.
')

The term “Big Data” itself appeared relatively recently, but it has already securely occupied the leading positions in the list of trends in modern IT technologies. As often happens, it is not always clear what is behind the fashionable term, so we decided to understand this with examples, the first of which would be weather forecasting.
We are all interested in weather forecasts: on TV, on the Internet, on the radio. Forecasts are correct and not so, but it is difficult to argue with a simple fact: the more data you have, both modern and historical, you have — the more accurate your forecasts for the coming hours, days, and even weeks.

Information about the set of measurements of the set of weather parameters in different places is just a typical example of Big Data. Usually, Apache Hadoop is used to analyze the huge number of sources used by meteorologists, since its flexibility allows you to create scalable analysis tools needed to “brush” and maximize data.
Experts in the processing of meteorological data joke that the weather generates a "shower of data", especially when information is being collected around the world. Using the results of observations, the most powerful supercomputers perform billions of calculations in order to simulate the real processes occurring in the atmosphere in order to obtain long-term forecasts for a given point on Earth. The most interesting was the fact that not all models are equally good.
While many companies and organizations are involved in weather modeling, the European Meteorological Community has shown the best results. Thanks to the superiority in hardware and software, European sites manage to achieve such success. American experts in the field of weather analysis almost always try to include the data of their colleagues in the Old World in their calculations, and in the event of a conflict between their model and the European one, they often prefer the latter. This firstly underlines the key role of information technologies and data mining solutions in weather forecasts, and secondly shows us that weather forecasts can often be a matter of life and death, so cooperation is so important here.

An example of such a situation was Hurricane Sandy (Hurricane Sandy) - a powerful tropical cyclone that formed in late October 2012 and affected Jamaica, Cuba, the Bahamas, Haiti, the coast of Florida and, subsequently, the northeastern United States and eastern Canada.


The hurricane caused the most severe damage to the northeastern states of the United States, in particular, New Jersey, New York and Connecticut, but without full-fledged weather forecasts and predictions regarding this hurricane - the damage would have been much greater. Almost unconditionally, US meteorologists recognized that if even one, even if small, source of data were omitted in Sandy’s motion analysis, the accuracy of predictions (for example, such an important question: exactly where a hurricane would “land” on land) would noticeably decrease, this could have disastrous, and maybe even lethal consequences for many people.

On this graph, you can see how, after 72 hours, the model of European meteorologists dramatically pulled ahead in the accuracy of the prediction of hurricane actions.
Hadoop technology is good for analyzing such large amounts of data, but for all its merits, it is only as good as the hardware of data analysis and processing systems allows it, and one of the key characteristics affecting Hadoop's efficiency is the speed of the disk subsystem. It doesn't matter what kind of big data you process, be it a weather forecast, or, for example, developing a vaccine for the flu - one of the globally recognized ways to speed up Hadoop is LSI Nytro series solutions. Read more about how Nytro allows you to speed up Hadoop and other applications on the site .
Volume (volume) - it is logical that “big data” is primarily distinguished by large volumes.
Velocity (speed) - in this case it means both the speed of accumulation of this data, and the need for high speed of their processing.
Variety (diversity) - data is often or poorly structured, or they are well structured, but many different structures must be processed at the same time.
')
The term “Big Data” itself appeared relatively recently, but it has already securely occupied the leading positions in the list of trends in modern IT technologies. As often happens, it is not always clear what is behind the fashionable term, so we decided to understand this with examples, the first of which would be weather forecasting.
We are all interested in weather forecasts: on TV, on the Internet, on the radio. Forecasts are correct and not so, but it is difficult to argue with a simple fact: the more data you have, both modern and historical, you have — the more accurate your forecasts for the coming hours, days, and even weeks.
Information about the set of measurements of the set of weather parameters in different places is just a typical example of Big Data. Usually, Apache Hadoop is used to analyze the huge number of sources used by meteorologists, since its flexibility allows you to create scalable analysis tools needed to “brush” and maximize data.
Experts in the processing of meteorological data joke that the weather generates a "shower of data", especially when information is being collected around the world. Using the results of observations, the most powerful supercomputers perform billions of calculations in order to simulate the real processes occurring in the atmosphere in order to obtain long-term forecasts for a given point on Earth. The most interesting was the fact that not all models are equally good.
While many companies and organizations are involved in weather modeling, the European Meteorological Community has shown the best results. Thanks to the superiority in hardware and software, European sites manage to achieve such success. American experts in the field of weather analysis almost always try to include the data of their colleagues in the Old World in their calculations, and in the event of a conflict between their model and the European one, they often prefer the latter. This firstly underlines the key role of information technologies and data mining solutions in weather forecasts, and secondly shows us that weather forecasts can often be a matter of life and death, so cooperation is so important here.
An example of such a situation was Hurricane Sandy (Hurricane Sandy) - a powerful tropical cyclone that formed in late October 2012 and affected Jamaica, Cuba, the Bahamas, Haiti, the coast of Florida and, subsequently, the northeastern United States and eastern Canada.
The hurricane caused the most severe damage to the northeastern states of the United States, in particular, New Jersey, New York and Connecticut, but without full-fledged weather forecasts and predictions regarding this hurricane - the damage would have been much greater. Almost unconditionally, US meteorologists recognized that if even one, even if small, source of data were omitted in Sandy’s motion analysis, the accuracy of predictions (for example, such an important question: exactly where a hurricane would “land” on land) would noticeably decrease, this could have disastrous, and maybe even lethal consequences for many people.
On this graph, you can see how, after 72 hours, the model of European meteorologists dramatically pulled ahead in the accuracy of the prediction of hurricane actions.
Hadoop technology is good for analyzing such large amounts of data, but for all its merits, it is only as good as the hardware of data analysis and processing systems allows it, and one of the key characteristics affecting Hadoop's efficiency is the speed of the disk subsystem. It doesn't matter what kind of big data you process, be it a weather forecast, or, for example, developing a vaccine for the flu - one of the globally recognized ways to speed up Hadoop is LSI Nytro series solutions. Read more about how Nytro allows you to speed up Hadoop and other applications on the site .
Source: https://habr.com/ru/post/194566/
All Articles