What could be the schedule of the university
Using the slow and inconvenient information resources on the network, you can curse their creators and lose time, or you can write a spider that will collect and classify information as needed. Already processed information will be available in any plane and with the response that is required. This article is about one of these experiences. With a practical example of parsing and improving the timetable of the NSU (Novosibirsk State University).
I would like to note that it will not go about replacing one ugly table with a beautiful table with different properties, adding pictures and soft colors, all this is of course wonderful, but I am not an artist and when it comes to getting information I don’t see much difference between the styles of tables as long as it does not interfere with reading.
')
The idea was to simplify access to the schedule. The original schedule, available on the NSU website, can be found here . In order to find my own schedule, I had to start my journey from the main page of the site, go to the “old site”, then “information systems”, then “class schedule”, select the building, department, group, total - 6 clicks. Most of these transitions seemed to be quite meaningful, except for the choice of corps: it would seem, why choose corpus if the faculties are still different, and their total number is not so large as to be split into two pages (about 10 in total)? But the situation became a little more difficult if it was necessary to find the schedule of a teacher or friend. For the teacher it was necessary in the worst case to check both buildings, and for a friend it was necessary to find him first in the lists of groups, find out the group number, and then everything else. The steps are quite doable, but you don’t always want to perform them, and nothing prevents you from gathering this information and making it possible to make such selections simply by typing in the line the name of the person whose schedule you want to learn - as in search engines to which everyone is already used.
Let's start with the list of students: fortunately, it is available as xml, and for each group it looks like this:
In order to export such data, use the following code:
In addition, you need to select lists of groups by faculty, but this is done in a similar way from similar xml files.
The class schedule itself is not available in xml, in addition, the html generated by the NSU timetable system turned out to be invalid, which put me before a choice: convert it to a valid one or parse it with regular expressions. I must say that somehow I really didn't want to resort to regexp. Looking at the html files, I realized that not too much needed to be done in order for the documents to become valid, namely, add one <tr> tag (missing) and specify the encoding. It turned out the following:
After these manipulations, the schedule was dealt with in a remarkable way. It should be noted that it was possible not to transcode to utf, but since all the other project data was in utf, and the encoding in these files was not specified - I preferred to do the conversion at this step.
In this way, I got a schedule of groups and teachers, as well as lists of students.
The schedule in the resulting structure refers to the group or teacher, but not to the student. To search for students, teachers, groups and faculties required a complex query or a few queries to the database server. Making such a request is not a problem, but I was afraid for its speed. It was decided to make a separate table for the search “searchable”, which would contain in one column the aliases for which the search is performed, and in the other - the address of the document. First of all - to optimize access time. It also made it possible to process requests like “Mathematician Vasily 1 course”, but at the same time allowed to have inconsistent database states, since the address of the document (url) is contained in several different tables. The latter is not a plus, but the advantages in this case, I saw much more significant than this minus.
In order for others not to have the need to perform all this routine again, I published an open REST API, which seems to be used in two third-party projects. The request to the API contains the search string and the type of the requested schedule: for the day, for the week and the closest pair. The response contains a schedule in JSON format or the possible names and addresses of the respective schedules, when several schedules correspond to a given string.
After publication, quite a few people said that the schedule uses incomprehensible abbreviations that are difficult to interpret (for example, “O. chemistry” is “Fundamentals of General and Inorganic Chemistry”, and “SPTF” - “Theory of Complex Variable Functions”). I have seen two ways to solve this problem: 1. Provide students with the opportunity to specify the full names themselves and 2. Try to decipher them in some way. The first option was simple and fun, but controversial, because it was necessary to introduce a moderation system and the ability to look without decryption, because I myself could not determine how the correct name was provided, and finding experts from each department practically means asking several people to decipher these abbreviations. I tried to find the possibility of automatic decryption, found lists of departments and teachers with subjects. These lists were not complete, but I must say that the lists of students did not differ completely. In addition, the names of teachers in the list of departments are given with the decoding of the name and patronymic, and in the schedule with initials, but this is not such a big problem. The first idea was to find such teachers who teach only one subject and determine all the names from them (at the NSU, the majority combine teaching with another job and those who teach one discipline quite a lot), but this method unexpectedly failed and gave the wrong ones. results. Perhaps the fact is that teachers with one subject were not often included in the department lists that I was able to get. Then I tried to compare the number of matching letters, but it also turned out quite strange results. The best was the method that establishes the correspondence between the abbreviated name and the full one only if this teacher has the only subject starting with this letter. Thus managed to decipher most of the items.
In addition, my hands were very much itchy to conduct a statistical study of the workload of audiences / teachers, and I got the idea that it is possible to display information from the current schedule: who and what audiences are now, how many people, how many male students, and how many female. Of course, the last characteristic was invented just to make the project more fun, you could just bring all the names, but the problem was that the group numbers in the schedule did not always correspond well to the numbers in the student lists. For example, there could be groups 123.1, 123.2, 123.3 in the schedule, and only 123 in the lists. Thus, one can say approximately how many people are in each group, but it is impossible to say exactly who is in which. I used student names to determine gender. I must say that the definition was as accurate as I can accurately distinguish a male name from a female one; this was not always possible, but in most cases it works fine. Based on this information, an audience map was built, which is updated automatically every 10 minutes and displays the number of students, students, the number of places (the maximum number found in the schedule) and the numbers of groups that are currently in this audience. It can be very useful if you are looking for an empty audience or have lost something and would like to interview everyone who could see it.
Audiences were selected from the timetable, postfixes denoting the corpus were disassembled, and then displayed on the page so that a list of the following type was obtained:

For each audience / corps a load chart is displayed for any day entered.
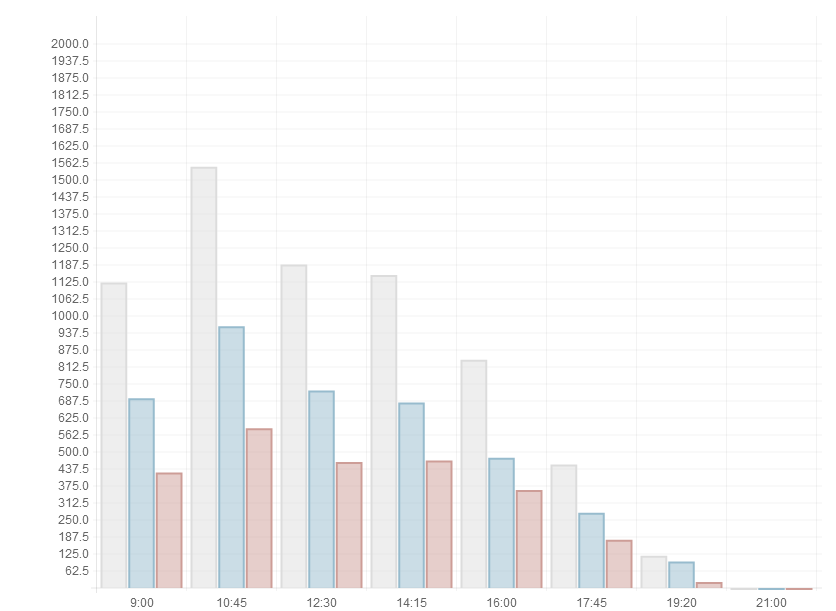
This is the schedule for the main building of the NSU on Friday; the service allows you to watch such for any audience or corpus on any school day (non-training schedule is empty). Here Y is the number of people, time is the beginning of pairs. Red column - students, blue - students, gray - amount. The fractional scale on Y is striking, the fact is that I couldn’t manage to set up a graph drawing library to display only integers, but it seems to me that it’s not very important. Yes, there is no fractional number of people, but the bars do not run into non-integer numbers.
Before writing an article, I decided to see how everything works at Moscow State University and found a schedule, even a map of empty audiences, but it turned out that in order to obtain information, you need to be patient; and the matter is not in the number of clicks, which are also abundant, but in a very slow response. From periodically appearing SQL errors, it is possible to draw conclusions about the use of the DBMS, but apparently it’s somehow not very optimally arranged.
Available data also provided some more global figures.
The average audience load with a maximum capacity is 28% (the amount of students involved is divided by the total audience capacity, averaged by day and time)
The average audience load in the NSU, if it is considered fully loaded, when at least one student is engaged - 60%
The most female audience is 500, 431 and 608 - about 89% of girls
The most male audience - 312, only 10% of girls
The most female time is 14:15, 53% of girls
The most masculine time is 19:20, 46.8% of girls
The most feminine day is Tuesday, 52.3% of girls
The most masculine day is Monday 49.2% of girls
From this we can conclude that there are audiences in which there are practically only girls, but there is not any time or day when the number of girls in the university would prevail in a serious way.
The statistics was obtained solely for entertainment purposes, I will be happy if this article inspires someone from the Internet users to other experiences in the field of systematization of open data or just to create a similar schedule for your university.
original schedule
www.nsu.ru/education/schedule
disassembled prototype
nsu-schedule.ru
on-line audience map
nsu-schedule.ru/now
mentioned schedule of MSU
cacs.law.msu.ru
I would like to note that it will not go about replacing one ugly table with a beautiful table with different properties, adding pictures and soft colors, all this is of course wonderful, but I am not an artist and when it comes to getting information I don’t see much difference between the styles of tables as long as it does not interfere with reading.
')
The idea was to simplify access to the schedule. The original schedule, available on the NSU website, can be found here . In order to find my own schedule, I had to start my journey from the main page of the site, go to the “old site”, then “information systems”, then “class schedule”, select the building, department, group, total - 6 clicks. Most of these transitions seemed to be quite meaningful, except for the choice of corps: it would seem, why choose corpus if the faculties are still different, and their total number is not so large as to be split into two pages (about 10 in total)? But the situation became a little more difficult if it was necessary to find the schedule of a teacher or friend. For the teacher it was necessary in the worst case to check both buildings, and for a friend it was necessary to find him first in the lists of groups, find out the group number, and then everything else. The steps are quite doable, but you don’t always want to perform them, and nothing prevents you from gathering this information and making it possible to make such selections simply by typing in the line the name of the person whose schedule you want to learn - as in search engines to which everyone is already used.
Parsing lists
Let's start with the list of students: fortunately, it is available as xml, and for each group it looks like this:
<group name="0502, - , ()"> <student name=" " status=""/> <student name=" " status=""/> <student name=" " status=""/> ... </group> In order to export such data, use the following code:
public function exportGroup($groupFile, $groupName, $department, $course) { $grouplist=file_get_contents($groupFile); $dom2 = new domDocument; $dom2->loadXML($grouplist); $s2 = simplexml_import_dom($dom2); for ($k=0;$k<count($s2->student);$k++) { $attrs=$s2->student[$k]->attributes(); $student=new Student(); $student->name=$attrs["name"]; $student->group=$groupName; $student->department=$department; $student->course=$course; $student->save(); } } In addition, you need to select lists of groups by faculty, but this is done in a similar way from similar xml files.
Correction to valid
The class schedule itself is not available in xml, in addition, the html generated by the NSU timetable system turned out to be invalid, which put me before a choice: convert it to a valid one or parse it with regular expressions. I must say that somehow I really didn't want to resort to regexp. Looking at the html files, I realized that not too much needed to be done in order for the documents to become valid, namely, add one <tr> tag (missing) and specify the encoding. It turned out the following:
$text=file_get_contents($url); $text = iconv ( "CP1251" , "UTF-8" , $text ); $doc = new DOMDocument(); $doc->loadHTML(str_replace("</HEAD>", '<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" /> </HEAD>', str_replace("<TH Width=10%>", "<TR><TH Width=10%>", $text))); $s = simplexml_import_dom($doc); After these manipulations, the schedule was dealt with in a remarkable way. It should be noted that it was possible not to transcode to utf, but since all the other project data was in utf, and the encoding in these files was not specified - I preferred to do the conversion at this step.
Search
In this way, I got a schedule of groups and teachers, as well as lists of students.
The schedule in the resulting structure refers to the group or teacher, but not to the student. To search for students, teachers, groups and faculties required a complex query or a few queries to the database server. Making such a request is not a problem, but I was afraid for its speed. It was decided to make a separate table for the search “searchable”, which would contain in one column the aliases for which the search is performed, and in the other - the address of the document. First of all - to optimize access time. It also made it possible to process requests like “Mathematician Vasily 1 course”, but at the same time allowed to have inconsistent database states, since the address of the document (url) is contained in several different tables. The latter is not a plus, but the advantages in this case, I saw much more significant than this minus.
REST API
In order for others not to have the need to perform all this routine again, I published an open REST API, which seems to be used in two third-party projects. The request to the API contains the search string and the type of the requested schedule: for the day, for the week and the closest pair. The response contains a schedule in JSON format or the possible names and addresses of the respective schedules, when several schedules correspond to a given string.
Abbreviations
After publication, quite a few people said that the schedule uses incomprehensible abbreviations that are difficult to interpret (for example, “O. chemistry” is “Fundamentals of General and Inorganic Chemistry”, and “SPTF” - “Theory of Complex Variable Functions”). I have seen two ways to solve this problem: 1. Provide students with the opportunity to specify the full names themselves and 2. Try to decipher them in some way. The first option was simple and fun, but controversial, because it was necessary to introduce a moderation system and the ability to look without decryption, because I myself could not determine how the correct name was provided, and finding experts from each department practically means asking several people to decipher these abbreviations. I tried to find the possibility of automatic decryption, found lists of departments and teachers with subjects. These lists were not complete, but I must say that the lists of students did not differ completely. In addition, the names of teachers in the list of departments are given with the decoding of the name and patronymic, and in the schedule with initials, but this is not such a big problem. The first idea was to find such teachers who teach only one subject and determine all the names from them (at the NSU, the majority combine teaching with another job and those who teach one discipline quite a lot), but this method unexpectedly failed and gave the wrong ones. results. Perhaps the fact is that teachers with one subject were not often included in the department lists that I was able to get. Then I tried to compare the number of matching letters, but it also turned out quite strange results. The best was the method that establishes the correspondence between the abbreviated name and the full one only if this teacher has the only subject starting with this letter. Thus managed to decipher most of the items.
By classroom
In addition, my hands were very much itchy to conduct a statistical study of the workload of audiences / teachers, and I got the idea that it is possible to display information from the current schedule: who and what audiences are now, how many people, how many male students, and how many female. Of course, the last characteristic was invented just to make the project more fun, you could just bring all the names, but the problem was that the group numbers in the schedule did not always correspond well to the numbers in the student lists. For example, there could be groups 123.1, 123.2, 123.3 in the schedule, and only 123 in the lists. Thus, one can say approximately how many people are in each group, but it is impossible to say exactly who is in which. I used student names to determine gender. I must say that the definition was as accurate as I can accurately distinguish a male name from a female one; this was not always possible, but in most cases it works fine. Based on this information, an audience map was built, which is updated automatically every 10 minutes and displays the number of students, students, the number of places (the maximum number found in the schedule) and the numbers of groups that are currently in this audience. It can be very useful if you are looking for an empty audience or have lost something and would like to interview everyone who could see it.
Audiences were selected from the timetable, postfixes denoting the corpus were disassembled, and then displayed on the page so that a list of the following type was obtained:
For each audience / corps a load chart is displayed for any day entered.
This is the schedule for the main building of the NSU on Friday; the service allows you to watch such for any audience or corpus on any school day (non-training schedule is empty). Here Y is the number of people, time is the beginning of pairs. Red column - students, blue - students, gray - amount. The fractional scale on Y is striking, the fact is that I couldn’t manage to set up a graph drawing library to display only integers, but it seems to me that it’s not very important. Yes, there is no fractional number of people, but the bars do not run into non-integer numbers.
Before writing an article, I decided to see how everything works at Moscow State University and found a schedule, even a map of empty audiences, but it turned out that in order to obtain information, you need to be patient; and the matter is not in the number of clicks, which are also abundant, but in a very slow response. From periodically appearing SQL errors, it is possible to draw conclusions about the use of the DBMS, but apparently it’s somehow not very optimally arranged.
Statistics
Available data also provided some more global figures.
The average audience load with a maximum capacity is 28% (the amount of students involved is divided by the total audience capacity, averaged by day and time)
The average audience load in the NSU, if it is considered fully loaded, when at least one student is engaged - 60%
The most female audience is 500, 431 and 608 - about 89% of girls
The most male audience - 312, only 10% of girls
The most female time is 14:15, 53% of girls
The most masculine time is 19:20, 46.8% of girls
The most feminine day is Tuesday, 52.3% of girls
The most masculine day is Monday 49.2% of girls
From this we can conclude that there are audiences in which there are practically only girls, but there is not any time or day when the number of girls in the university would prevail in a serious way.
The statistics was obtained solely for entertainment purposes, I will be happy if this article inspires someone from the Internet users to other experiences in the field of systematization of open data or just to create a similar schedule for your university.
References:
original schedule
www.nsu.ru/education/schedule
disassembled prototype
nsu-schedule.ru
on-line audience map
nsu-schedule.ru/now
mentioned schedule of MSU
cacs.law.msu.ru
Source: https://habr.com/ru/post/194212/
All Articles