More about testing in Yandex with robots
From the point of view of testing, Yandex is thousands of man-hours of work for checking a large number of services. A lot of functionality, interaction scenarios - millions. We try to make people do only complex and interesting tasks, and all the routine work could be entrusted to the robot.
Ideally, it is the robot that should check that as a result of a simple page load or a complex interaction with the input form, no exceptions are thrown, “NaN”, “undefined” or empty lines at the place of the loaded data. The experimental project for the creation and implementation of such a robot has the code name “Robotster”.

')
We have already told how to implement it and teach how to work with forms. Today we will talk about how our robot tries to find the maximum amount of service functionality, and then "understand" it.
Once each site was a static page, the content of which was formed using a single request to the server. Now, many sites can be classified as Rich Internet Applications (RIA): they have become much more interactive and their content changes depending on the user behavior on the page. Web applications are different from traditional sites using technologies such as Javascript and AJAX, which allow you to significantly change the look and content of the application without changing the address in the browser.
To test a site, a robot tester needs not only to complete the task of a search crawler and walk through all pages of the site, but also to visit all their states, or rather, to visit all states of all pages where you can perform various actions.
In the most general form, you can think of a website as a state graph and look for approaches like visiting all the vertices in the graph, or at least their maximum number. But in this form, the task is of little comprehension - even in a simple Yandex service, the number of states is so large that it can be considered infinite. For example, entering each new query into the search field and pressing the “find” button leads us to a new state. That is, there are at least as many of them as you can enter various search queries. Therefore, we use the standard for testing approach, when states are divided into a relatively small number of classes. For example, it will be reasonable to divide the set of pages with search results into such groups: lack of results, a small amount of results, several pages of results. All classes must be defined by some equivalence relation, after which we try to test at least one representative of this class. But how to teach this robotester?
We did the following. Still, the task was divided into two parts: “by the crawler of pages” we go around the site by links, selecting a certain number of pages, and then on each of the selected pages we launch the “crawler of forms”, which, according to the algorithm described below, changes the page and stops going to a new one. We did this because these two crawlers have somewhat different tasks: if the maximum “depth” of clicking on links is rarely more than 5-6, then in order to go to a new page using forms, sometimes you need to perform a hundred or two other actions. As an example, you can look at the form for creating a campaign in Yandex.Direct , which you will see after authorization. Therefore, it is reasonable to use different traversal algorithms.
Of course, there are both obsolete sites, where almost no reasonable elements (only the first crawler actually works there), and, conversely, modern RIAs, where the url of the page may not change at all (then only the second crawler will work). Nevertheless, we have a fairly flexible system that is easy to configure for almost any service.
How the pages crawler works
So, our first task is to select the pages on which the form crawler will be launched. How to get a set of these "input points"? At first we decided that it could be compiled manually. Let's take as an example a short list of pages:
As you can see, the page address contains a large number of parameters. If any of the parameters change, the link becomes invalid. In addition, new classes of pages appear, and some of them become obsolete. Therefore, it became clear to us that we must be able to dynamically compile and maintain a list of pages that need to be tested.
Suppose a graph of the pages of our site has the form shown in the figure:
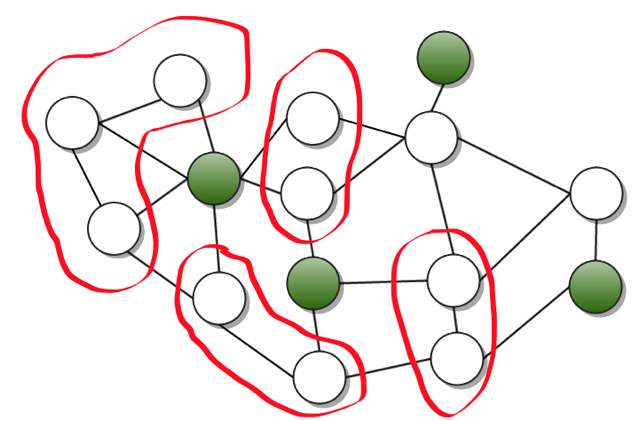
Let each edge of the graph be a link. A tool like CrawlJax starts from one vertex in all possible ways. This way to crawl a site can work for a very long time. We decided that we would act differently: we would select the “entry points” in the graph (green vertices in the figure) so that, ideally, the set of green vertices would become a 1-net . As a rule, in this case the entry points are pages with forms, and those accessible at a distance of 1 page is the result of the search. Thus, to test the site, it is enough for us to find the entry points, perform various actions on them and check for errors on the page to which we switched. It is worth noting that most of the pages in a 1-vicinity of an entry point are identical in functionality, so not all representatives of such a neighborhood can be tested.
So, to test a site, a robot must have a list of some of its pages.
Web crawler is a fairly standard and very widely lit task. In the classic interpretation, the crawler needs to find as many pages as possible. The more pages, the larger the index, the better the search. In the context of our task, to the crawler such requirements:
Requirement # 1: time
It may be necessary to control the duration of the testing process. Suppose you need to roll out a release and you want to quickly check the main functionality. The length of the crawling can be put in some frames with the help of restrictions on the depth and number of pages visited.
Requirement # 2: Coating
The second requirement arises from the need to cover with tests as much functionality as possible in the least possible time. Obviously, the content service has classes of equivalent (in functionality) pages. Clustering such pages can be based on the URL of the page and its html-code. We have developed a way to quickly and fairly accurately divide these pages into clusters.
We use two types of page spacing:
It should be noted that the implementation of the second requirement must be consistent with the first requirement. Suppose we need to select pages for testing the Yandex.Market site. Suppose there are N links from each page and we are interested in crawling depth K. To compare all the pages, we will have to load the html-code of O (N K ) pages. This may take a lot of time, considering that the links leading to each page of the content site may be 20-30. This method does not suit us. We will filter the pages not at the very end, but at each step.
So, at our disposal a list of links from the current page, from which you need to select the most different.
Thus, we need to load the code only for O (L · K) pages. With all these data, simplifying the process of filtering pages, the quality of the resulting "entry points" suits us!
Requirement number 3: the number of test pages
The implementation of the third requirement will allow us to limit the number of pages on which tests will be conducted. Roughly speaking, we are telling the robot to “take away the N most different in functionality pages and test them.”
Requirement number 4: consider dynamically loaded content
To collect links even from blocks loaded dynamically and to follow only visually accessible links (modeling human behavior) allows WebDriver .
Requirement # 5: context
To take into account a context like region or user rights (different output, different functionality), the crawler must be able to work with cookies . For example, did you know that even the Yandex home page may be different in different regions?
So, we have fulfilled all of these requirements and were able to quickly and efficiently find the largest possible amount of site functionality. The robot found "entry points". Now you need to visit the 1-neighborhood, or, more simply, to interact with the form.
To test the functionality of the site, you need to be able to use it. If you start to click thoughtlessly on everything and enter any values into the text input fields (how to enter not any), then you will not be able to qualitatively test the form in a reasonable time. For example, with such forms on Yandex.Direct, as in the figure below, it is quite difficult to interact.
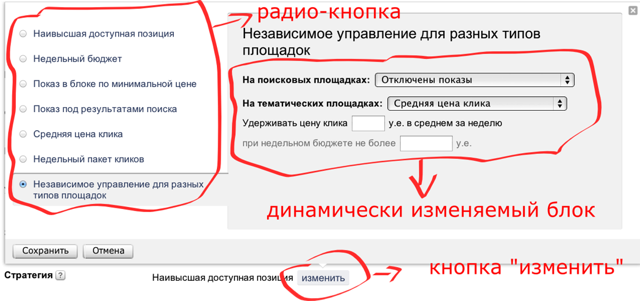
So, when you click on the “change” button, a new block appears, in which, when you select the next value of the radio button, the form changes on a gray background, which in turn also dynamically changes when the fields are filled. Obviously, with so many input fields, as in this form, some strategy is needed, otherwise the robot will remain in place for a long time.
Let's formalize the problem. We can assume that all input fields are drop-down lists. In fact, the text entry field for us actually becomes a drop-down list when we determine its type and select the finite number of values that we can enter in it. Our task is to test the form in an optimal way, which means the maximum coverage with a fixed number of test cases or the minimum number of test cases for a given coverage (depending on which is more important to us - the speed of testing, or the level of coverage).
A simple case . The input fields are a fixed number, and they do not change, that is, do not depend on each other. This task is quite popular and widely covered. We, for example, use a program with a beautiful name Jenny .
It takes at the input the desired depth of coverage and a set of numbers responsible for the number of options in each input field. Consider the example of a small form. Suppose we are interested in coverage of degree 2 for a form of three input fields, each of which has two options. The instructions for filling will look like this:

The number is the number of the input field, the letter is the number of the option to be selected. Covering a degree N means that if we fix any N columns, then they will meet all possible combinations.
Difficult case . The form is dynamic and the number of input fields changes. For example, according to the result of filling in the first three fields, the fourth and fifth input fields appear, or the “send” button immediately appears. A “state graph” is suitable as a model of this form. Each vertex of the graph is a form state. It may change by removing the input field from the form, changing the value of the input field or adding a new one.
We formulated several non-critical assumptions for us, under which the algorithm should work:
The transition to another vertex is done by changing the state of one input field.
Suppose the form initially consists of the elements A 1 ... A n . For each A i execute:
With this approach, the algorithm can work for a very long time, since the number of interaction methods will grow exponentially with the number of elements. In order for the crawling of the form to end in the foreseeable future, the search for all possible ways of interaction is carried out only for elements that are at a depth of no more than 2, and for all the others we choose one random value. This approach is necessary for testing forms that require filling in a certain number of required fields.
Suppose the form initially consists of the elements A 1 ... A n . For each A i execute:
1. We try to interact with A i in all possible ways. Let these methods k pieces.
2. Fix those elements B i1 ... B ik that appeared with different fillings A i .
3. For each element B ij , until we reach the end of filling out the form, run:
3.1. Let us deal with the element B ij in all possible ways.
3.2. With each element that becomes available when filling B ij , we interact only randomly.

Optimal coverage is generated on the basis that A i is a drop-down list, which has as many options as there are ways to level 3 from it.
We give a specific example.
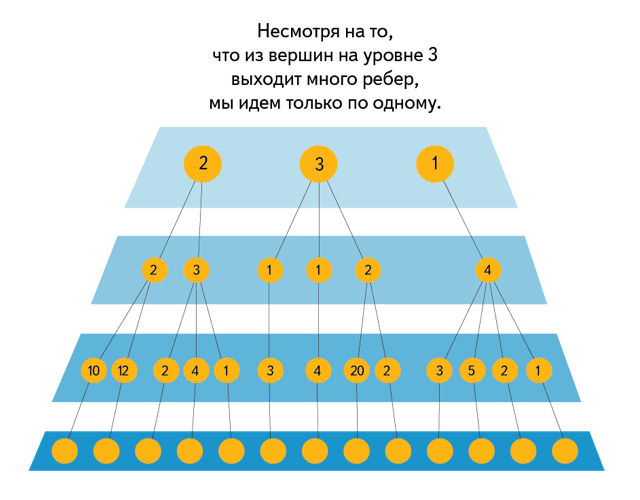
From vertex A 1 there are five paths to level 3, from vertex A 2 there are four, and from vertex A 3 there are also four. Accordingly, it is possible to present 1 as a drop-down list with five fields, and 2 and 3 - with four. Therefore, the robot will run Jenny with the arguments "5 4 4".
We taught the robot to find the functionality of the service and thoughtlessly (relative to the person) to use it. Of course, one should not expect that in the near future he will register with Yandex.Direct, independently create an advertising campaign for his beloved and become famous throughout the world, although he already knows how to create projects on the internal service (although they, oddly enough, have not yet fired :)). However, we do not expect this from him! He fills out the forms correctly and to the end. We expect quality testing of web interfaces from it, and it justifies our expectations.
Ideally, it is the robot that should check that as a result of a simple page load or a complex interaction with the input form, no exceptions are thrown, “NaN”, “undefined” or empty lines at the place of the loaded data. The experimental project for the creation and implementation of such a robot has the code name “Robotster”.
')
We have already told how to implement it and teach how to work with forms. Today we will talk about how our robot tries to find the maximum amount of service functionality, and then "understand" it.
Once each site was a static page, the content of which was formed using a single request to the server. Now, many sites can be classified as Rich Internet Applications (RIA): they have become much more interactive and their content changes depending on the user behavior on the page. Web applications are different from traditional sites using technologies such as Javascript and AJAX, which allow you to significantly change the look and content of the application without changing the address in the browser.
To test a site, a robot tester needs not only to complete the task of a search crawler and walk through all pages of the site, but also to visit all their states, or rather, to visit all states of all pages where you can perform various actions.
In the most general form, you can think of a website as a state graph and look for approaches like visiting all the vertices in the graph, or at least their maximum number. But in this form, the task is of little comprehension - even in a simple Yandex service, the number of states is so large that it can be considered infinite. For example, entering each new query into the search field and pressing the “find” button leads us to a new state. That is, there are at least as many of them as you can enter various search queries. Therefore, we use the standard for testing approach, when states are divided into a relatively small number of classes. For example, it will be reasonable to divide the set of pages with search results into such groups: lack of results, a small amount of results, several pages of results. All classes must be defined by some equivalence relation, after which we try to test at least one representative of this class. But how to teach this robotester?
We did the following. Still, the task was divided into two parts: “by the crawler of pages” we go around the site by links, selecting a certain number of pages, and then on each of the selected pages we launch the “crawler of forms”, which, according to the algorithm described below, changes the page and stops going to a new one. We did this because these two crawlers have somewhat different tasks: if the maximum “depth” of clicking on links is rarely more than 5-6, then in order to go to a new page using forms, sometimes you need to perform a hundred or two other actions. As an example, you can look at the form for creating a campaign in Yandex.Direct , which you will see after authorization. Therefore, it is reasonable to use different traversal algorithms.
Of course, there are both obsolete sites, where almost no reasonable elements (only the first crawler actually works there), and, conversely, modern RIAs, where the url of the page may not change at all (then only the second crawler will work). Nevertheless, we have a fairly flexible system that is easy to configure for almost any service.
How the pages crawler works
So, our first task is to select the pages on which the form crawler will be launched. How to get a set of these "input points"? At first we decided that it could be compiled manually. Let's take as an example a short list of pages:
- market.yandex.ru/catalogmodels.xml?CAT_ID=160043&hid=91491 - mobile phones, search by parameters;
- market.yandex.ru/guru.xml?CMD=-RR=9,0,0,0-VIS=70-CAT_ID=160043-EXC=1-PG=10&hid=91491 - mobile phones, advanced search;
- market.yandex.ru/model.xml?modelid=8478341&hid=91491 - product page;
- market.yandex.ru/product/8478341/reviews/add?retpath=http://market.yandex.ru/product/8478341/reviews - the form in which you want to leave a review.
As you can see, the page address contains a large number of parameters. If any of the parameters change, the link becomes invalid. In addition, new classes of pages appear, and some of them become obsolete. Therefore, it became clear to us that we must be able to dynamically compile and maintain a list of pages that need to be tested.
Suppose a graph of the pages of our site has the form shown in the figure:
Let each edge of the graph be a link. A tool like CrawlJax starts from one vertex in all possible ways. This way to crawl a site can work for a very long time. We decided that we would act differently: we would select the “entry points” in the graph (green vertices in the figure) so that, ideally, the set of green vertices would become a 1-net . As a rule, in this case the entry points are pages with forms, and those accessible at a distance of 1 page is the result of the search. Thus, to test the site, it is enough for us to find the entry points, perform various actions on them and check for errors on the page to which we switched. It is worth noting that most of the pages in a 1-vicinity of an entry point are identical in functionality, so not all representatives of such a neighborhood can be tested.
So, to test a site, a robot must have a list of some of its pages.
Web crawler is a fairly standard and very widely lit task. In the classic interpretation, the crawler needs to find as many pages as possible. The more pages, the larger the index, the better the search. In the context of our task, to the crawler such requirements:
- It should be possible to crawl in a reasonable time.
- Crawler should select as different pages as possible in structure.
- The number of pages to be tested at the output should be limited.
- Crawler should collect from the page, even those links that are loaded dynamically (not originally contained in the page code).
- It should be possible to support authorization, region-dependent and other settings of Yandex services.
Requirement # 1: time
It may be necessary to control the duration of the testing process. Suppose you need to roll out a release and you want to quickly check the main functionality. The length of the crawling can be put in some frames with the help of restrictions on the depth and number of pages visited.
Requirement # 2: Coating
The second requirement arises from the need to cover with tests as much functionality as possible in the least possible time. Obviously, the content service has classes of equivalent (in functionality) pages. Clustering such pages can be based on the URL of the page and its html-code. We have developed a way to quickly and fairly accurately divide these pages into clusters.
We use two types of page spacing:
- UrlDistance is responsible for the difference in urls. If the length of two URLs is the same, then the distance between URLs is inversely proportional to the number of matched characters. If the length is different, then the distance is proportional to the difference in length.
- TagDistance is responsible for distinguishing html-code pages. The distance between two DOM trees is the difference in the number of tags of the same name.
It should be noted that the implementation of the second requirement must be consistent with the first requirement. Suppose we need to select pages for testing the Yandex.Market site. Suppose there are N links from each page and we are interested in crawling depth K. To compare all the pages, we will have to load the html-code of O (N K ) pages. This may take a lot of time, considering that the links leading to each page of the content site may be 20-30. This method does not suit us. We will filter the pages not at the very end, but at each step.
So, at our disposal a list of links from the current page, from which you need to select the most different.
- The first stage of filtering: compare urls by UrlDistance, leaving L the most different.
- The second stage of filtering: load the html-code L of the pages that differ the most in the UrlDistance metric and sranim them using TagDistance.
Thus, we need to load the code only for O (L · K) pages. With all these data, simplifying the process of filtering pages, the quality of the resulting "entry points" suits us!
Requirement number 3: the number of test pages
The implementation of the third requirement will allow us to limit the number of pages on which tests will be conducted. Roughly speaking, we are telling the robot to “take away the N most different in functionality pages and test them.”
Requirement number 4: consider dynamically loaded content
To collect links even from blocks loaded dynamically and to follow only visually accessible links (modeling human behavior) allows WebDriver .
Requirement # 5: context
To take into account a context like region or user rights (different output, different functionality), the crawler must be able to work with cookies . For example, did you know that even the Yandex home page may be different in different regions?
So, we have fulfilled all of these requirements and were able to quickly and efficiently find the largest possible amount of site functionality. The robot found "entry points". Now you need to visit the 1-neighborhood, or, more simply, to interact with the form.
Crawler forms
To test the functionality of the site, you need to be able to use it. If you start to click thoughtlessly on everything and enter any values into the text input fields (how to enter not any), then you will not be able to qualitatively test the form in a reasonable time. For example, with such forms on Yandex.Direct, as in the figure below, it is quite difficult to interact.
So, when you click on the “change” button, a new block appears, in which, when you select the next value of the radio button, the form changes on a gray background, which in turn also dynamically changes when the fields are filled. Obviously, with so many input fields, as in this form, some strategy is needed, otherwise the robot will remain in place for a long time.
Let's formalize the problem. We can assume that all input fields are drop-down lists. In fact, the text entry field for us actually becomes a drop-down list when we determine its type and select the finite number of values that we can enter in it. Our task is to test the form in an optimal way, which means the maximum coverage with a fixed number of test cases or the minimum number of test cases for a given coverage (depending on which is more important to us - the speed of testing, or the level of coverage).
A simple case . The input fields are a fixed number, and they do not change, that is, do not depend on each other. This task is quite popular and widely covered. We, for example, use a program with a beautiful name Jenny .
It takes at the input the desired depth of coverage and a set of numbers responsible for the number of options in each input field. Consider the example of a small form. Suppose we are interested in coverage of degree 2 for a form of three input fields, each of which has two options. The instructions for filling will look like this:
The number is the number of the input field, the letter is the number of the option to be selected. Covering a degree N means that if we fix any N columns, then they will meet all possible combinations.
Difficult case . The form is dynamic and the number of input fields changes. For example, according to the result of filling in the first three fields, the fourth and fifth input fields appear, or the “send” button immediately appears. A “state graph” is suitable as a model of this form. Each vertex of the graph is a form state. It may change by removing the input field from the form, changing the value of the input field or adding a new one.
We formulated several non-critical assumptions for us, under which the algorithm should work:
- Input fields are rarely removed, so we do not consider this case.
- If while filling the field A, the field B has changed, then we need to make a topological sorting of the input fields, getting the order in which we will first fill in A, and then B, if B depends on A. In practice, we assume that the superior ones (in physical positioned on the page) elements do not depend on the downstream.
- If as a result of the interaction, a new input field has appeared, then we consider that it depends only on one of the previous input fields. In reality, this is not the case, but this assumption greatly simplifies the task.
The transition to another vertex is done by changing the state of one input field.
Suppose the form initially consists of the elements A 1 ... A n . For each A i execute:
- We try to interact with A i in all possible ways. Let these methods k pieces.
- Fix those elements B i1 ... B ik , which appeared at different fillings Ai.
- Recursively repeat the procedure for each of B ij .
With this approach, the algorithm can work for a very long time, since the number of interaction methods will grow exponentially with the number of elements. In order for the crawling of the form to end in the foreseeable future, the search for all possible ways of interaction is carried out only for elements that are at a depth of no more than 2, and for all the others we choose one random value. This approach is necessary for testing forms that require filling in a certain number of required fields.
Algorithm
Suppose the form initially consists of the elements A 1 ... A n . For each A i execute:
1. We try to interact with A i in all possible ways. Let these methods k pieces.
2. Fix those elements B i1 ... B ik that appeared with different fillings A i .
3. For each element B ij , until we reach the end of filling out the form, run:
3.1. Let us deal with the element B ij in all possible ways.
3.2. With each element that becomes available when filling B ij , we interact only randomly.
Optimal coverage is generated on the basis that A i is a drop-down list, which has as many options as there are ways to level 3 from it.
We give a specific example.
From vertex A 1 there are five paths to level 3, from vertex A 2 there are four, and from vertex A 3 there are also four. Accordingly, it is possible to present 1 as a drop-down list with five fields, and 2 and 3 - with four. Therefore, the robot will run Jenny with the arguments "5 4 4".
We taught the robot to find the functionality of the service and thoughtlessly (relative to the person) to use it. Of course, one should not expect that in the near future he will register with Yandex.Direct, independently create an advertising campaign for his beloved and become famous throughout the world, although he already knows how to create projects on the internal service (although they, oddly enough, have not yet fired :)). However, we do not expect this from him! He fills out the forms correctly and to the end. We expect quality testing of web interfaces from it, and it justifies our expectations.
Source: https://habr.com/ru/post/193918/
All Articles