Fault tolerance: how to provide reliable service in case of equipment failure
Providing fault tolerance is not a trivial task. For her, there is no standard solution. There are some common patterns, components. But even within the same organization, different solutions are applied to ensure the tolerance of different nodes. What to say about the comparison of approaches in different organizations.
Someone leaves the problem on the "random", someone hangs a banner on the "five hundred" and trying to make money on the failures. Someone uses standard solutions from database vendors or network devices. And someone goes into fashionable now "clouds".

')
One thing is clear - as business grows, ensuring resilience to failures (not even recovery procedures after failures) becomes an increasingly acute problem. The company's reputation begins to depend on the number of accidents per year, with large downtime it becomes inconvenient to use the service, etc. There are many reasons.
In this article, we will look at one of our ways to ensure resiliency. Stability is understood to mean the preservation of the system’s working capacity in the event of the failure of as many units of this system as possible.
Typically, a web application architecture is structured as follows (and our architecture is no exception):

The web server is engaged in preprocessing and dispatching requests, it performs most of the domain logic, it knows where to get the data, what to do with it, where to put the new data. It does not make much difference what specific web server will handle the user request. If the software is written more or less correctly, any web server will successfully complete the work required of it (if it is not overloaded, of course). Therefore, the failure of one of the servers will not lead to serious problems: there will be a simple transfer of the load to the surviving servers, and the web application will continue to work (ideally, all incomplete transactions will be rolled out and the user request can be re-processed on another server) .
The main difficulties begin at the data storage level. The main task of this subsystem is to preserve and increase the information necessary for the functioning of the entire system as a whole. Some of this data can sometimes be lost, and the rest is irreplaceable, and their loss means the actual death of the project. In any case, if the data is partially lost, damaged, or temporarily unavailable, the performance of the system decreases dramatically.
In fact, of course, everything is much more complicated. If the web server fails, the system usually does not return to the previous point. This is due to the fact that within one business transaction it is necessary to make changes in several different storages (the mechanism of distributed transactions in the data storage layer is usually not implemented, and is too expensive to implement and operate). Other possible reasons for discrepancies in the data are errors in the program code, unaccounted scenarios, the disorder of developers and administrators (the “human factor”), severe restrictions on the development time and a lot of other important and unimportant reasons for which programmers write not quite perfect code. But in most situations this is not necessary (not all applications are written for the banking and financial sector). Either the system is automatically able to restore the consistency of its data, or there are semi-manual tools for restoring the system after failures, or even this is not required (example: the user edited his settings, but due to failure, some of the settings have not changed. In most cases this is not fatal, if the interface honestly tells the user that it was unable to apply the changes).
Given all the above considerations, having a good storage system and data access gives a tangible bonus to the ability of the system to handle accidents. That is why we will further focus on how to ensure resilience to failures in the data access subsystem.
In recent years, we have been using the Tarantula as a database (this is our open source project, a very fast, convenient database that is easily expanded using stored procedures. See http://tarantool.org ).
So, our goal is maximum data availability. Tarantula as a software usually does not cause problems, because it is stable, the load on the server is well predicted, the server will not leave unexpectedly due to the increased load. We face the problem of reliability of the equipment. Sometimes servers fail, disks fall out, racks are cut down, routers fail, links to data centers disappear ... And we need, in spite of everything, to serve our users.
In order not to lose data, you need to duplicate the database server, place it in another rack, behind another router or even in another data center and set up replication of data from the main server to the duplicate one. We must not forget about the mandatory and regular backup data. In the event of a technical breakdown, the data will remain alive and accessible. But there is one caveat: the data will be available at a different address. And applications will continue to habitually knock on a broken server.
The easiest and most common option is to wake up one of the system administrators so that he understands the problem and reconfigures all our applications to use the new data server. Not the best solution: switching takes a lot of time, it is likely to forget something, and irregular work schedule is very bad.
There is a less reliable, but more automated option - the use of specialized software to determine whether the server is alive and whether it is time to switch to the backup. Let the administrators and gentlemen correct me, but it seems to me that there is a non-zero probability of false positives, which will lead to discrepancies in the data between different repositories. However, the number of false positives can be reduced by increasing the response time of the system to failure (which, in turn, leads to an increase in downtime).
Alternatively, you can put a master copy of the data in each data center and write software so that everything works correctly in this configuration. But for most problems, such a solution is fantastic.
I would also like to be able to handle cases of network splitting, when for a part of the cluster a master copy of the data remains available.
As a result, we chose a compromise option - in case of problems with access to the database, automatically switch to a replica (but already in read-only access mode). Moreover, each server makes the decision to switch to the replica and back to the master on its own, based on its own information about the availability of the master and the replicas. If the server with the master copy of the data is really broken, system administrators will take all necessary steps to fix it, and the system will work with a slightly reduced functionality at this time (for example, some users will not have the contact editing function available). Depending on the criticality of the service, administrators can take different actions to eliminate the problem - from the immediate introduction of the replacement to the “raise in the morning”. The main thing is that the web application continues to work, albeit in a slightly truncated version. Automatically.
I can not tell you about one component commonly used in our country that we have on each server. We call him Kapron. Kapron performs the functions of database query multiplexer (MySQL and Tarantool), maintaining a pool of persistent connections with them, encapsulates all the information about database configuration, sharding and load balancing. Kapron allows you to hide the features of the database protocol, providing its customers with a simpler and clearer interface. Very handy thing. And the ideal candidate for putting there the logic described earlier.
So, the application needs to perform some actions with data. It forms a request and sends it to Capron. Kapron determines which shard to send a request to, establishes a connection (or uses an already created connection) to the required server and sends a command to it. If the server is unavailable or the response times out, the request is duplicated into one of the replicas. In case of failure, the request will be sent to the next replica, and so on, until the replicas run out or the request is processed. Server availability status is maintained between requests. And in case the master was unavailable, the next request will immediately go to the replica. Kapron in the background continues to knock on the master server, and as soon as he comes to life, he immediately starts sending requests to him again. When you try to make changes on a replica, the request fails - this allows us not to worry about where the request goes, to the master or the replica.
Due to the large flow of requests, knowledge about the inaccessibility of certain database servers is quickly updated, and this allows you to respond as quickly as possible to a change of situation.
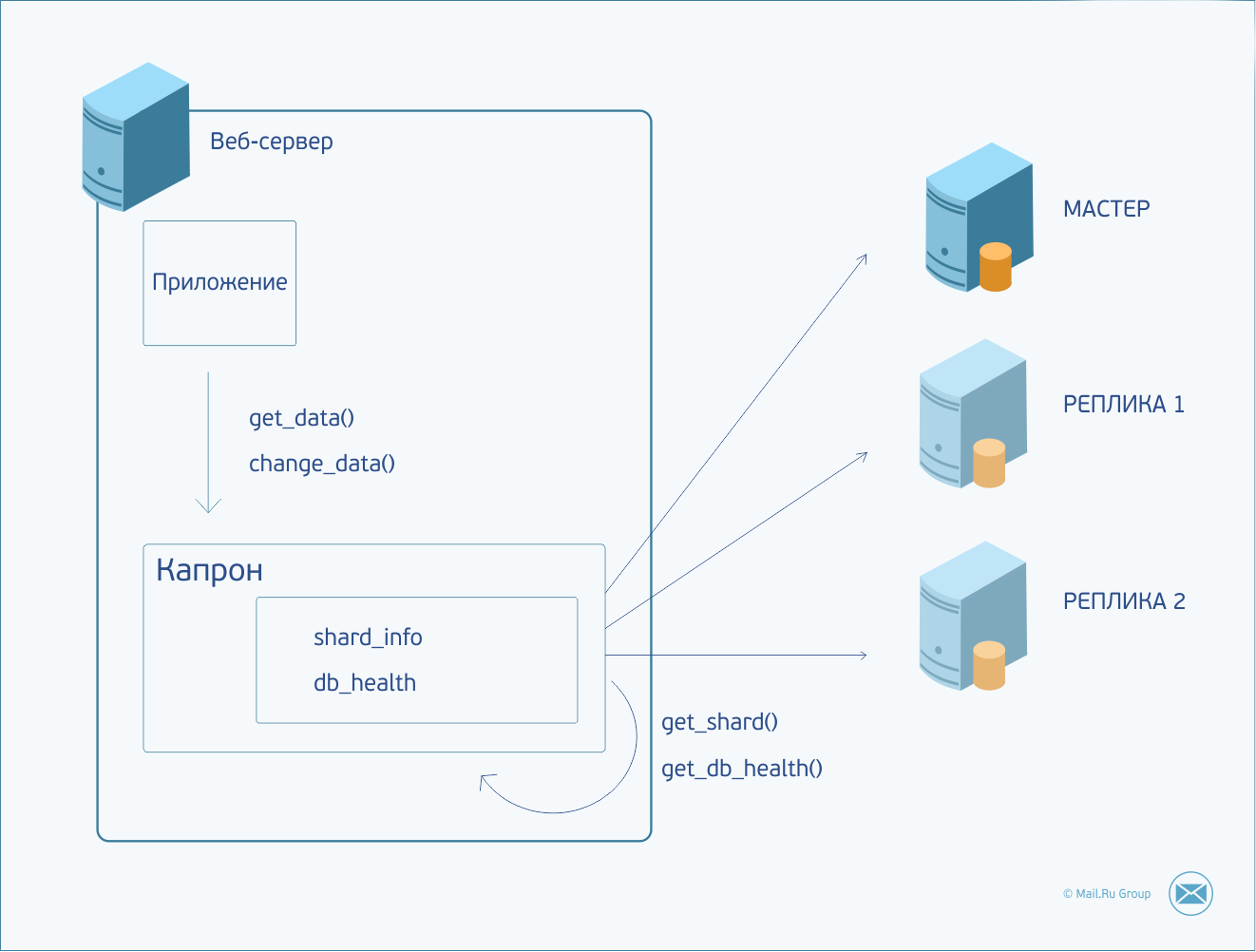
The result was a fairly simple and universal scheme. Perfectly handles not only the cases of falling master data, but also the usual network delays. If the master is Stymutil, the request will be redirected to the replica (and in the case of a non-changing query, it has been successfully processed). In general, this allows you to reduce the threshold values of network expectations for reading requests, and during the brakes on the master server, it is faster to return the result to the client.
Second bonus. Now it is possible to carry out software updates and other planned work on database servers more painlessly (less painfully). Since read requests are usually the vast majority, for most requests restarting the wizard will not result in denial of service.
We plan to not stop on our laurels and try to eliminate some obvious flaws:
1) In the case of a network timeout, we try to send a request to the replica. In the case of a modifying query, this is a waste of labor, since the replica will not be able to process it. It makes sense not to send modifying commands to the replica a priori. Solved at the level of manual configuration of command types.
2) Now the network timeout does not mean that the data on the master will not be changed. Although we will return to the client that we could not process his request. In fairness it should be noted that this drawback was present before. The situation can be corrected by introducing restrictions on the time of command processing on the Tarantula side (if the changes are not applied within the specified time, they are automatically rolled back and the request is filed). We set the timeout for processing for 1 second, and the network timeout in Kapron - 2 seconds.
3) And of course, we are waiting for the synchronous master replication master from the Tarantula developers. This will allow you to evenly distribute requests between multiple master copies and successfully process requests even if one of the servers is unavailable!
Dmitry Isaikin, Lead Mail.Ru Developer
Someone leaves the problem on the "random", someone hangs a banner on the "five hundred" and trying to make money on the failures. Someone uses standard solutions from database vendors or network devices. And someone goes into fashionable now "clouds".
')
One thing is clear - as business grows, ensuring resilience to failures (not even recovery procedures after failures) becomes an increasingly acute problem. The company's reputation begins to depend on the number of accidents per year, with large downtime it becomes inconvenient to use the service, etc. There are many reasons.
In this article, we will look at one of our ways to ensure resiliency. Stability is understood to mean the preservation of the system’s working capacity in the event of the failure of as many units of this system as possible.
Typically, a web application architecture is structured as follows (and our architecture is no exception):
The web server is engaged in preprocessing and dispatching requests, it performs most of the domain logic, it knows where to get the data, what to do with it, where to put the new data. It does not make much difference what specific web server will handle the user request. If the software is written more or less correctly, any web server will successfully complete the work required of it (if it is not overloaded, of course). Therefore, the failure of one of the servers will not lead to serious problems: there will be a simple transfer of the load to the surviving servers, and the web application will continue to work (ideally, all incomplete transactions will be rolled out and the user request can be re-processed on another server) .
The main difficulties begin at the data storage level. The main task of this subsystem is to preserve and increase the information necessary for the functioning of the entire system as a whole. Some of this data can sometimes be lost, and the rest is irreplaceable, and their loss means the actual death of the project. In any case, if the data is partially lost, damaged, or temporarily unavailable, the performance of the system decreases dramatically.
In fact, of course, everything is much more complicated. If the web server fails, the system usually does not return to the previous point. This is due to the fact that within one business transaction it is necessary to make changes in several different storages (the mechanism of distributed transactions in the data storage layer is usually not implemented, and is too expensive to implement and operate). Other possible reasons for discrepancies in the data are errors in the program code, unaccounted scenarios, the disorder of developers and administrators (the “human factor”), severe restrictions on the development time and a lot of other important and unimportant reasons for which programmers write not quite perfect code. But in most situations this is not necessary (not all applications are written for the banking and financial sector). Either the system is automatically able to restore the consistency of its data, or there are semi-manual tools for restoring the system after failures, or even this is not required (example: the user edited his settings, but due to failure, some of the settings have not changed. In most cases this is not fatal, if the interface honestly tells the user that it was unable to apply the changes).
Given all the above considerations, having a good storage system and data access gives a tangible bonus to the ability of the system to handle accidents. That is why we will further focus on how to ensure resilience to failures in the data access subsystem.
In recent years, we have been using the Tarantula as a database (this is our open source project, a very fast, convenient database that is easily expanded using stored procedures. See http://tarantool.org ).
So, our goal is maximum data availability. Tarantula as a software usually does not cause problems, because it is stable, the load on the server is well predicted, the server will not leave unexpectedly due to the increased load. We face the problem of reliability of the equipment. Sometimes servers fail, disks fall out, racks are cut down, routers fail, links to data centers disappear ... And we need, in spite of everything, to serve our users.
In order not to lose data, you need to duplicate the database server, place it in another rack, behind another router or even in another data center and set up replication of data from the main server to the duplicate one. We must not forget about the mandatory and regular backup data. In the event of a technical breakdown, the data will remain alive and accessible. But there is one caveat: the data will be available at a different address. And applications will continue to habitually knock on a broken server.
The easiest and most common option is to wake up one of the system administrators so that he understands the problem and reconfigures all our applications to use the new data server. Not the best solution: switching takes a lot of time, it is likely to forget something, and irregular work schedule is very bad.
There is a less reliable, but more automated option - the use of specialized software to determine whether the server is alive and whether it is time to switch to the backup. Let the administrators and gentlemen correct me, but it seems to me that there is a non-zero probability of false positives, which will lead to discrepancies in the data between different repositories. However, the number of false positives can be reduced by increasing the response time of the system to failure (which, in turn, leads to an increase in downtime).
Alternatively, you can put a master copy of the data in each data center and write software so that everything works correctly in this configuration. But for most problems, such a solution is fantastic.
I would also like to be able to handle cases of network splitting, when for a part of the cluster a master copy of the data remains available.
As a result, we chose a compromise option - in case of problems with access to the database, automatically switch to a replica (but already in read-only access mode). Moreover, each server makes the decision to switch to the replica and back to the master on its own, based on its own information about the availability of the master and the replicas. If the server with the master copy of the data is really broken, system administrators will take all necessary steps to fix it, and the system will work with a slightly reduced functionality at this time (for example, some users will not have the contact editing function available). Depending on the criticality of the service, administrators can take different actions to eliminate the problem - from the immediate introduction of the replacement to the “raise in the morning”. The main thing is that the web application continues to work, albeit in a slightly truncated version. Automatically.
I can not tell you about one component commonly used in our country that we have on each server. We call him Kapron. Kapron performs the functions of database query multiplexer (MySQL and Tarantool), maintaining a pool of persistent connections with them, encapsulates all the information about database configuration, sharding and load balancing. Kapron allows you to hide the features of the database protocol, providing its customers with a simpler and clearer interface. Very handy thing. And the ideal candidate for putting there the logic described earlier.
So, the application needs to perform some actions with data. It forms a request and sends it to Capron. Kapron determines which shard to send a request to, establishes a connection (or uses an already created connection) to the required server and sends a command to it. If the server is unavailable or the response times out, the request is duplicated into one of the replicas. In case of failure, the request will be sent to the next replica, and so on, until the replicas run out or the request is processed. Server availability status is maintained between requests. And in case the master was unavailable, the next request will immediately go to the replica. Kapron in the background continues to knock on the master server, and as soon as he comes to life, he immediately starts sending requests to him again. When you try to make changes on a replica, the request fails - this allows us not to worry about where the request goes, to the master or the replica.
Due to the large flow of requests, knowledge about the inaccessibility of certain database servers is quickly updated, and this allows you to respond as quickly as possible to a change of situation.
The result was a fairly simple and universal scheme. Perfectly handles not only the cases of falling master data, but also the usual network delays. If the master is Stymutil, the request will be redirected to the replica (and in the case of a non-changing query, it has been successfully processed). In general, this allows you to reduce the threshold values of network expectations for reading requests, and during the brakes on the master server, it is faster to return the result to the client.
Second bonus. Now it is possible to carry out software updates and other planned work on database servers more painlessly (less painfully). Since read requests are usually the vast majority, for most requests restarting the wizard will not result in denial of service.
We plan to not stop on our laurels and try to eliminate some obvious flaws:
1) In the case of a network timeout, we try to send a request to the replica. In the case of a modifying query, this is a waste of labor, since the replica will not be able to process it. It makes sense not to send modifying commands to the replica a priori. Solved at the level of manual configuration of command types.
2) Now the network timeout does not mean that the data on the master will not be changed. Although we will return to the client that we could not process his request. In fairness it should be noted that this drawback was present before. The situation can be corrected by introducing restrictions on the time of command processing on the Tarantula side (if the changes are not applied within the specified time, they are automatically rolled back and the request is filed). We set the timeout for processing for 1 second, and the network timeout in Kapron - 2 seconds.
3) And of course, we are waiting for the synchronous master replication master from the Tarantula developers. This will allow you to evenly distribute requests between multiple master copies and successfully process requests even if one of the servers is unavailable!
Dmitry Isaikin, Lead Mail.Ru Developer
Source: https://habr.com/ru/post/193906/
All Articles