Scale a real-life project database using SQL Azure Federations. Part 2: Baseline
Last time, we looked at the theoretical part of SQL Azure Federations. What you should think about and what to consider when migrating to using SQL Azure Federations. I note that the essence is not even in the technology itself. If there is a database scaling task, no matter using Federations, MySQL Cluster or another method, the first thing to think about is the database architecture. The database that needs to be scaled must first be architecturally oriented towards this.
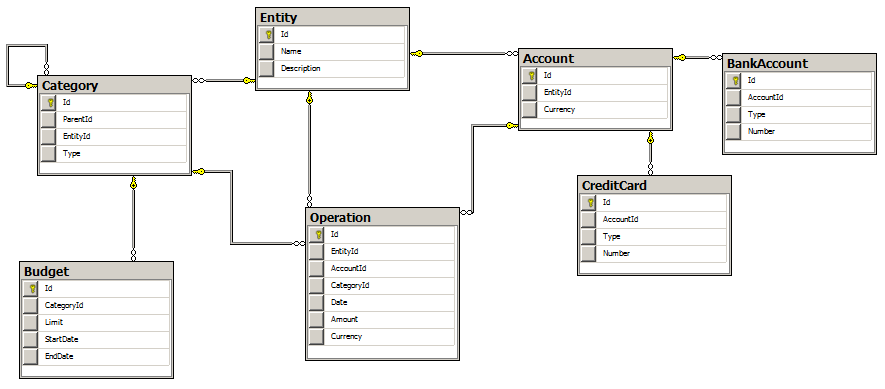
So back to our project. The subject area of the database is personal finance accounting. The database diagram is shown in the figure.
')
As we can see the database is quite simple. Each object of the system is an entity with basic properties (Id, Name, Description). Specific entities are Account (inherited from it: Bank account, Credit card), Category of expenses (inherited from it: Budget, as well as child categories) and Account transactions.
In addition to the tables, the database contains some logic for adding entities to the database (framed in the form of stored procedures), as well as a couple of View, for displaying the results of typical database queries.
The SQL source code of the database creation script can be found here .
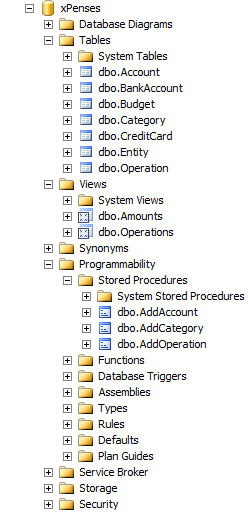
It is clear that in a real project the number of artifacts in the database can be an order of magnitude greater, but even migrating such a small database can reveal the main rakes that can be encountered when using SQL Azure Federations.
Before rushing to migrate a database to use SQL Azure Federations, you must determine which data in the database is logically independent. What kind of data can be distributed across different databases. In essence, it is necessary to choose a table whose data will be divided into several databases, the so-called federated table.
If we look at the structure of the database, the basic entity table (Entity) comes first. The script for creating this table is as follows:
At first glance, this table is ideal for splitting. However, it is not. Yes, it does not contain foreign keys, has a fairly simple structure, and the number of records stored in it is maximum. However, according to the logic of the database, this table is associated with the data of the "tables-heirs". That is, all entities created in the system have an entry in the entity table.
Consider this example. Suppose we split the data by a range of identifiers (fieldID) of entities. Suppose records with ID 1-50 are stored in the first shard, 51-100 - in the second, and so on.
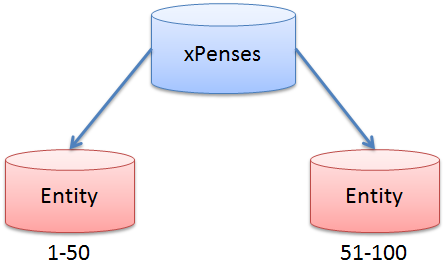
The user is trying to add a new entry to the Operations table. Let it be data on the purchase of a package of milk. The account entity ID is assumed to be 1, the expense category ID is 6. Also suppose that there are already 50 entries in the first database, which means the new entry should get the identifier equal to 51, that is, get into the second shard.
A request to add new data to the table will look like this:
The request will be executed absolutely correctly. Let's try now to get a list of all transactions for this account (ID = 1). In the database for this there is a corresponding view. Its code is as follows:
As we remember, the data of one account is stored on different shards. Therefore, in order for this query to return correct results, it must be performed on each shard separately.
I think it is not necessary to explain what a huge blow to the performance of the application from this approach. Even if the simplest query now needs to be executed twice! It is obvious that the entity table (Entity) does not suit us.
If we recall the multi-tenant approach to database design, when each user works with his own database and their data does not overlap, the question arises. Is it possible to implement something like this in SQL Azure Federations? Where each shard will contain data of one user (Account). Indeed, this approach will be quite logical. From the point of view of business logic, it would look like this:
Suppose one program is used by several family members. Each of them keeps a budget separately. Also let's say the husband keeps his accounting, his wife - his. Thus, the husband’s data (AccountId = 1) does not overlap with the wife’s data (AccountId = 2). In this case, splitting into shards according to the table of accounts seems quite logical.
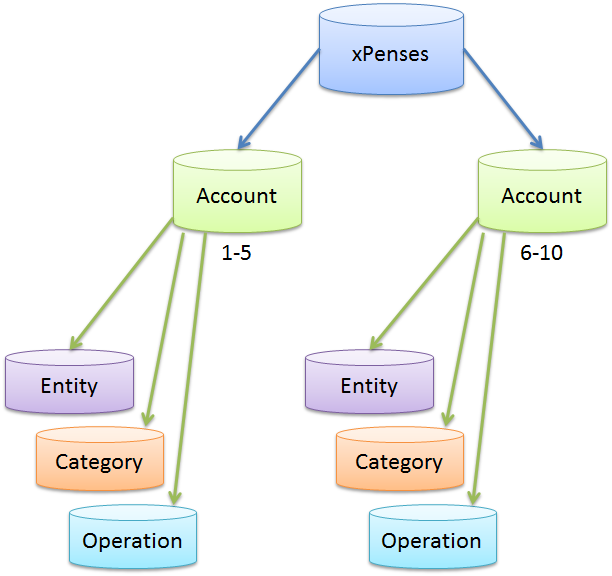
Adding a new account will correspond to adding a shard. Frequent operations, such as: working with a list of categories, operations, etc., will not lead to a drop in performance.
After the execution of such a request, it is immediately clear with the data of which user we are currently working. So the same operation will be performed only once.
So, we have considered two options for partitioning an existing database. Now we have decided on which field we will logically separate data from different databases. Next time we will directly distribute the data to different shards. Do not switch! All the good start to the new work week. Thanks for attention!
So back to our project. The subject area of the database is personal finance accounting. The database diagram is shown in the figure.
')
As we can see the database is quite simple. Each object of the system is an entity with basic properties (Id, Name, Description). Specific entities are Account (inherited from it: Bank account, Credit card), Category of expenses (inherited from it: Budget, as well as child categories) and Account transactions.
In addition to the tables, the database contains some logic for adding entities to the database (framed in the form of stored procedures), as well as a couple of View, for displaying the results of typical database queries.
The SQL source code of the database creation script can be found here .
It is clear that in a real project the number of artifacts in the database can be an order of magnitude greater, but even migrating such a small database can reveal the main rakes that can be encountered when using SQL Azure Federations.
Analysis
Before rushing to migrate a database to use SQL Azure Federations, you must determine which data in the database is logically independent. What kind of data can be distributed across different databases. In essence, it is necessary to choose a table whose data will be divided into several databases, the so-called federated table.
If we look at the structure of the database, the basic entity table (Entity) comes first. The script for creating this table is as follows:
CREATE TABLE Entity ([Id] INTEGER NOT NULL PRIMARY KEY IDENTITY(1,1),[Name] NVARCHAR(MAX) NOT NULL,[Description] NVARCHAR(MAX) NOT NULL,)At first glance, this table is ideal for splitting. However, it is not. Yes, it does not contain foreign keys, has a fairly simple structure, and the number of records stored in it is maximum. However, according to the logic of the database, this table is associated with the data of the "tables-heirs". That is, all entities created in the system have an entry in the entity table.
Consider this example. Suppose we split the data by a range of identifiers (fieldID) of entities. Suppose records with ID 1-50 are stored in the first shard, 51-100 - in the second, and so on.
The user is trying to add a new entry to the Operations table. Let it be data on the purchase of a package of milk. The account entity ID is assumed to be 1, the expense category ID is 6. Also suppose that there are already 50 entries in the first database, which means the new entry should get the identifier equal to 51, that is, get into the second shard.
A request to add new data to the table will look like this:
USE FEDERATION Entities(EntityId = 51) WITH RESET, FILTERING = OFFGOINSERT INTO Operation VALUES (51, -- EntityId1, -- AccountId6, -- CategoryIdGETDATE(), -- Date10, -- Amount'USD' -- Currency)The request will be executed absolutely correctly. Let's try now to get a list of all transactions for this account (ID = 1). In the database for this there is a corresponding view. Its code is as follows:
SELECTAccount_Entity.Description AS 'Account',Operation_Entity.Name AS 'Operation',Operation_Entity.Description,Operation.Amount,Operation.Currency,Operation.DateFROMOperationINNER JOIN Entity AS Operation_Entity ON Operation.EntityId = Operation_Entity.IdINNER JOIN Account ON Operation.AccountId = Account.IdINNER JOIN Entity AS Account_Entity ON Account.EntityId = Account_Entity.IdINNER JOIN Category ON Operation.CategoryId = Category.IdINNER JOIN Entity AS Category_Entity ON Category.EntityId = Category_Entity.IdWHEREAccount.Id = 1As we remember, the data of one account is stored on different shards. Therefore, in order for this query to return correct results, it must be performed on each shard separately.
USE FEDERATION Entities(EntityId = 1) WITH RESET, FILTERING = OFFGO...USE FEDERATION Entities(EntityId = 51) WITH RESET, FILTERING = OFFGO...I think it is not necessary to explain what a huge blow to the performance of the application from this approach. Even if the simplest query now needs to be executed twice! It is obvious that the entity table (Entity) does not suit us.
If we recall the multi-tenant approach to database design, when each user works with his own database and their data does not overlap, the question arises. Is it possible to implement something like this in SQL Azure Federations? Where each shard will contain data of one user (Account). Indeed, this approach will be quite logical. From the point of view of business logic, it would look like this:
Suppose one program is used by several family members. Each of them keeps a budget separately. Also let's say the husband keeps his accounting, his wife - his. Thus, the husband’s data (AccountId = 1) does not overlap with the wife’s data (AccountId = 2). In this case, splitting into shards according to the table of accounts seems quite logical.
Adding a new account will correspond to adding a shard. Frequent operations, such as: working with a list of categories, operations, etc., will not lead to a drop in performance.
USE FEDERATION Accounts(AccountId = 1) WITH RESET, FILTERING = OFFGOAfter the execution of such a request, it is immediately clear with the data of which user we are currently working. So the same operation will be performed only once.
So, we have considered two options for partitioning an existing database. Now we have decided on which field we will logically separate data from different databases. Next time we will directly distribute the data to different shards. Do not switch! All the good start to the new work week. Thanks for attention!
Source: https://habr.com/ru/post/193874/
All Articles