OpenNMS monitoring system
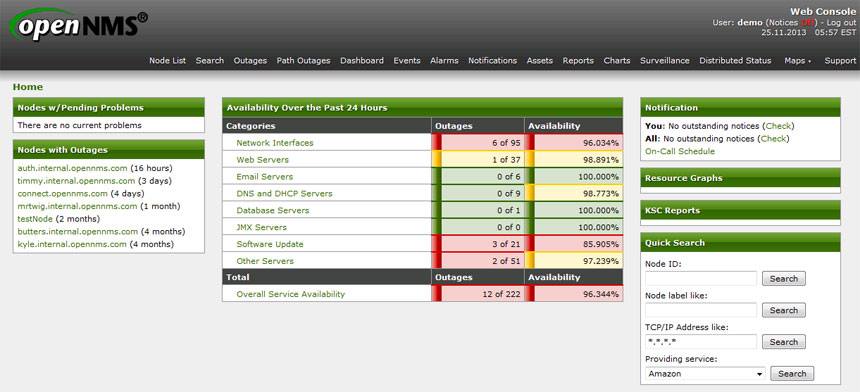
I don’t want to seem unpatriotic in the slightest, but historically, when choosing a corporate monitoring system for network infrastructure, OpenNMS won the enterprise in our company, having removed Grandma Cacti from this position and overtaken countryman Zabbix. Comparative analysis of Open Source monitoring systems is not included in my plans, so I’ll just talk in general terms about OpenNMS, since they didn’t write about it to Habré and generally don’t have much information about it.
The main function of the OpenNMS (Open Network Monitoring System) is to monitor various services and internal systems of network and server equipment. For the collection of information, so-called “collectors” are used, which operate using SNMP, HTTP, ITDITP protocols. OpenNMS does not have separate server agents. If the information turns out to be in demand, then I will describe examples of implementations of the "wrappers" in the following material in the section "User Cases". I do not want to repeat the mistakes with the publication of giant sheets of text that are difficult for the author and readers to understand.
a brief description of
OpenNMS is developing dynamically, is pretty well documented, but the community is fragmented, and the configuration in the form of editing a myriad of XML files can frighten off many. The system is written in Java with appendages on Perl and released a fair number of distributions for various platforms. If desired, it can be run on any machine with a Java SDK and a PostgreSQL server.
')
A 1 GHz Pentium III (or equivalent processor) or better. A minimum of 256 MB of RAM, although 512 MB is strongly recommended.
These system requirements from the official documentation, to put it mildly, are the most minimal and will allow just that to start the system itself. Therefore, let me correct them a bit: 64-bit CPU, 2 Gb RAM (this is the very minimum), high-performance hard disk.
The gluttony of the system depends on the number of nodes that it will monitor. A system with more than 1500 nodes and 5000 interfaces to them (VLANs, ports, services, etc.) feels comfortable on the Xeon E5520 with 12 Gb of RAM and SAS hard drives. In this case, the storage of rrd files is given to the 2Gb tmpfs partition. The power reserve is allocated more than twice - this is a reserve for the growth of the network and appetites of the system in the process of renewal and development.
Installation
Pre-install
ntp, net-snmp, net-snmp-utils, postgresql, postgresql-server, perl . Basely set up and run all the above services. Then install the latest version of the JDK by downloading it from the Oracle site, and finally you can connect the OpenNMS repository and install the system itself. rpm -Uvh http://yum.opennms.org/repofiles/opennms-repo-stable-rhel6.noarch.rpm yum install opennms iplike The last package is an addition to PostgreSQL from OpenNMS developers in the form of an IPLIKE stored procedure that helps to work with requests to IP addresses and network addresses using masks like
192.168.4-255.* , Which is actively used within the system itself.[!] If the host name on which the system is installed does not resolve on the DNS servers specified in resolv.conf, type it in the hosts. Otherwise, the system will not start. You should also pay attention to the initial configuration of PostgreSQL. After the default server installation in
/var/lib/pgsql/data/pg_hba.conf , put the method trust to all three local connections. /opt/opennms/bin/runjava -S /usr/java/latest/bin/java /opt/opennms/bin/install -dis /etc/init.d/opennms start After launch, the system will be available at
hostname:8980 hostname:8980 . It is not necessary to install a separate web server - the OpenNMS web interface works through a Jetty server. However, if you wish, you can reconfigure Jetty itself, or hang up Nginx or apache with mod_proxy on port 80 and do proxy_pass for all requests.When reinstalling the entire system, drop the database and delete
/var/opennms . Otherwise, there will be collisions with graphs and reports. For a full reinstall, we do yum reinstall opennms and /opt/opennms/bin/install -dis , for partial - only the second.It happens that OpenNMS displays the message
Started OpenNMS, but it has not finished starting up OpenNMS when it starts Started OpenNMS, but it has not finished starting up . First of all, you should check if there is a configuration error and if all services are running ( opennms -v status command). And if all services are running, then I have bad news for you - OpenNMS does not have enough resources and she wants relief. We create the $opennms/etc/opennms.conf with the content START_TIMEOUT=20 . The number in the parameter is the coefficient by which the 5-second interval of checking the neglect of all services will be multiplied. By default, this parameter is 10 and it turns out that if within 50 seconds all services fail to report a successful launch, an error will be returned. That is, START_TIMEOUT=20 is a 100-second wait for all systems to start.Interface and configuration
Perhaps, I’ll skip the part with a detailed description of the web interface - in general, the system will become clear after 10 minutes of walks through sections, but it is worth noting that you don’t have to get rid of the web interface while configuring the system in XML files.
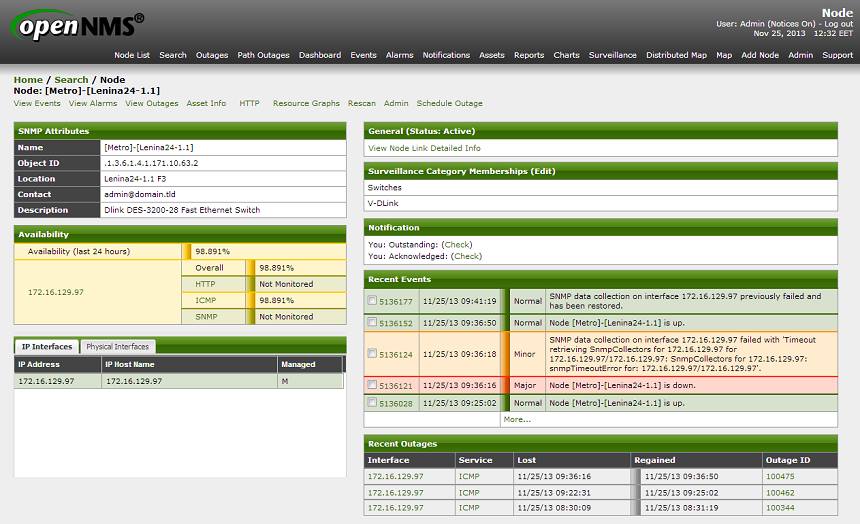
For example, you can easily add the SNMP community for a specific subnet via the web interface in the
Admin → Configure SNMP by IP section. But you can view and edit already added communities only in the corresponding XML file. In this case, the ranges of subnets for which you need to monitor ( network discovery ), you can fully edit from the web interface.Since there will be a lot of editing configuration files, I would recommend connecting any familiar CVS to track changes. Also, I would advise you to develop a habit after editing the configuration file to check it as
xmllint --noout filename.xml . And the final touch: changes to the configuration files are applied by restarting the opennms daemon, which takes quite some time.Internal mechanics
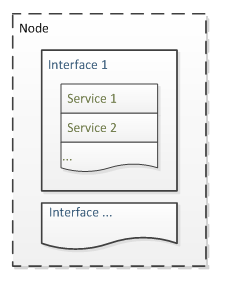 The basic unit of data collection is the interface that, under itself, unites certain services. All interfaces on the same device are grouped into a node. The interface may not necessarily be networked - in terms of OpenNMS, temperature sensors are also interfaces. Starting from version 1.9, single-type interfaces are organized into separate groups.
The basic unit of data collection is the interface that, under itself, unites certain services. All interfaces on the same device are grouped into a node. The interface may not necessarily be networked - in terms of OpenNMS, temperature sensors are also interfaces. Starting from version 1.9, single-type interfaces are organized into separate groups.When a new interface is
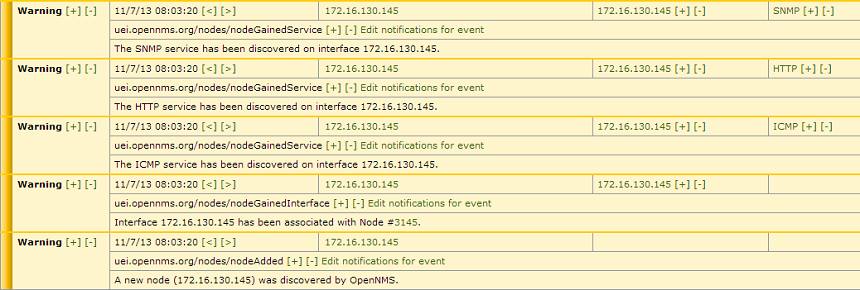
newSuspect , the newSuspect event is newSuspect , after which the system tries to detect services on this interface, find other interfaces on the device along a chain, and group the obtained information into a node. Obtain data on new interfaces OpenNMS can automatically (by searching the specified ranges with a certain frequency), manually (by calling the perl script) or by receiving the SNMP trap. # , : perl /opt/opennms/bin/send-event.pl --interface 192.168.11.11 uei.opennms.org/internal/discovery/newSuspect Now in Events → All Events you can observe the fascinating process of the birth of a new node. The speed of its appearance varies depending on the device and ranges from a few seconds to several minutes.
Of particular interest are Resource Graphs - graphics system resources. After adding a new node, we will see only the default data for each service (for example, ICMP and HTTP response time if the latter is present). However, it is possible to expand the amount of information received. For example, we want to capture more data from another server running CentOS. We will receive data via SNMP, so we install net-snmp on the target server and edit
/etc/init.d/snmp/snmpd.conf # com2sec, group, view # read-only rocommunity stat # location contact syslocation Datacenter N1, Rack 2 syscontact admin@domain.tld # disk / 10000 disk /var 10000 # load average load 12 14 14 Open 161 UDP port in iptables, launch snmpd and start a new SNMP community in OpenNMS (Admin → Operations → Configure SNMP Community Names by IP). After that, you can open the added node and make Rescan to it. After the scan is completed, the information will become more and the graphics will provide data on disk space, inodes and system load.
There is no formal requirement to restart opennms when adding the SNMP community through the admin panel. But sometimes updating this file or adding a new discovery group is picked up with a long delay and faster to restart opennms than to wait until it wakes up on its own.
Some more internal mechanics
Of course, OpenNMS can scan the network and detect the emergence of new devices on the network. The search process is configured in the web interface in the Admin → Configure Discovery section or in the
$opennms/etc/discovery-configuration.xml file.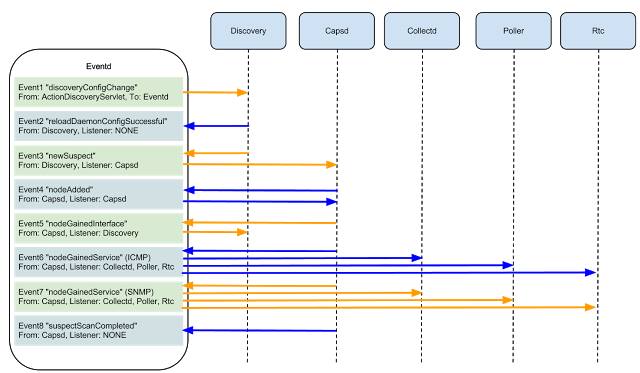
Image from oopsmonk
A little more detailed focus on the links between services in OpenNMS, starting after the discovery of the new interface and the operation of newSuspect. There are two services that define the availability of different services: capsd (capabilities daemon) and provisiond (provisioning daemon). By default, they run both, and for me it remains a mystery why this is done. Indeed, since version 1.8.0, capsd has been recognized as obsolete, although it retains the highest priority compared to provisiond.
Therefore, my personal recommendation is to disable capsd, shifting all the care of finding services onto provisiond. Working with the latter opens up access to provisioning conditions (provisioning requisitions), which allow you to flexibly configure the defined services, automatically turn on monitoring of the necessary interfaces on the nodes, sort the nodes into categories, etc.
Detectors that are part of provisiond are directly involved in service definition. Detectors are only involved in detecting and registering a service within the interface, while pollerd is collecting information. In earlier versions of the system, collectd and pollerd were involved in collecting and processing data; the first one collected the values for the graphs, and the second processed the values on demand. Then Collectd was integrated into Pollerd and there was less trouble with the configuration, although in some places you can still stumble on both concepts, which can cause some confusion.
Close the policy data processing chain (policies), which define the rules that apply to nodes that fall under certain initialization conditions. Currently three are available: MatchingIpInterfacePolicy, MatchingSnmpInterfacePolicy, NodeCategorySettingPolicy. Their names speak for themselves and the use of policies allows you to control the mechanics of obtaining information from the desired interfaces. As examples:
- Using MatchingSnmpInterfacePolicy, you can enable forced collection of information from interfaces that have a specific word in description (for example, [mon] ).
- Using NodeCategorySettingPolicy, send all D-Link switches to a separate category.
- With MatchingIpInterfacePolicy, we disabled the collection of information from port 80 from all switches on the same subnet. The HTTP response time graph in the case of switches is not needed - there is always an ICMP response and data from interfaces that indicate the magic word [mon]
Conclusion
Stability. The only serious glitch in the system was registered during the “leap second failure”. And then, this suffered a database system, not OpenNMS itself. For the rest, not a single complaint of stability over several years of work.
Complexity. The system is complex and complex. It is easy to use from the point of view of support - everything is beautiful, clearly and there is even a client for iPhone [x] . But the setup process (especially for the first time) can easily burn a lot of nerve cells. The documentation covers almost all the basic aspects of the system, but it is worth noting an unpleasant feature - many articles contain information for previous versions. Logically, the reasons for this are quite understandable: maintaining relevance for such an integrated system is not an easy task. But our life does not simplify it at all.
Flexibility. Having understood the system, you can connect your events, ladders and modules for monitoring. If the equipment gives some parameters via SNMP or HTTP, it can be monitored. Storing data in RRD allows you to flexibly customize the appearance of graphs (which by default do not shine with beauty) in the usual RRDTool syntax. Exceeding thresholds is processed in the form of notifications and alarms. External systems can receive data from OpenNMS via ReST or directly from the database.
I could not answer the questions “Why not% systemname%?” And deliberately did not take on a comparative analysis of different monitoring systems - after long work with one system and a certain binding to its functionality, an unbiased review would not work, but such resources the job would take too much. I will answer questions about the system itself with pleasure, and if the topic is at the very least relevant, then in continuation of this introductory material you can write examples of user cases.
Source: https://habr.com/ru/post/193682/
All Articles