Pandorama BigData Infrastructure and Protecting Its Data from Failure
If the Google mantra sounds like “searching all the information in the world with one click”, then the mantra of the young Russian project Pandorama goes further: “we will find all the information interesting for you without a click”.
The Pandorama application offers its users a “endless” personalized news feed, compiled based on their personal information preferences, without requiring the reader to work with “tags”, “categories” or “likes” of friends. First you need to answer a couple of questions about some funny pandas, and then you just need to ... read the proposed tape. Those news that you have read will be automatically analyzed and processed by the system, so that in future this kind of news in the tape becomes more and more, and the news that did not cause you interest - less.
')
Pandorama already brings together more than 40 thousand users worldwide, and this number is constantly growing. This article discusses the BigData infrastructure of this project, which operates in 24x7 mode, the mechanisms for ensuring its resiliency, and protecting its data from failures, built using Veeam Backup & Replication Cloud Edition .
So how does the Pandorama web service work? Every day, his robot is constantly looking for new information, bypassing many pages on the network (about 35 thousand sources are analyzed daily). Each article found is processed using its own linguistic algorithms, after which it is automatically assigned one or more tags like “iPhone 5s” depending on the content. The end user receives a personalized feed of articles based on his personal interests identified by the Pandorama system. The Pandorama project was originally planned by the founders as an international one, aimed at the mass market, therefore English was chosen as the language of the news feed.
Figure 1. Registration window in Pandorama
Pandorama currently leases four dedicated physical servers on which more than 30 virtual machines (VMs) are deployed. The following set of technologies is used to ensure scalability and fault tolerance:
- Ethernet Networking Channeling (LACP)
- Web Load Balancing (HAProxy)
- Balancing network connections (DNS Round Robin and NLB)
- Geographically distributed caching of images and static resources (CDN)
- NoSQL, including sharding and mirroring (MongoDB)
- SQL mirroring
- VM replication and VM backup locally and to the cloud using Veeam Backup & Replication Cloud Edition
More on this will be discussed below.
Pandorama Infrastructure
Like any startup, the Pandorama budget is severely limited, so the team is trying to invest money in everything, including infrastructure, as efficiently as possible. Initially, several hosting options were considered. First of all, they thought about Amazon, however, preliminary calculations showed that this option is too expensive. In general, in many cases, Amazon is a good starting point if the architecture is built on small, well-replicated modules. However, in the case of Pandorama, this scheme did not work - the project infrastructure includes several “heavy” servers involved in linguistic analysis. Large memory and fast drives are important here, and renting such virtual machines (with additional fault tolerance measures) for Pandorama was too expensive. Another hosting option is to rent physical servers with their VMs installed on them. This path turned out to be more suitable for the price.
At the moment, at the physical level now, Pandorama is the following infrastructure.
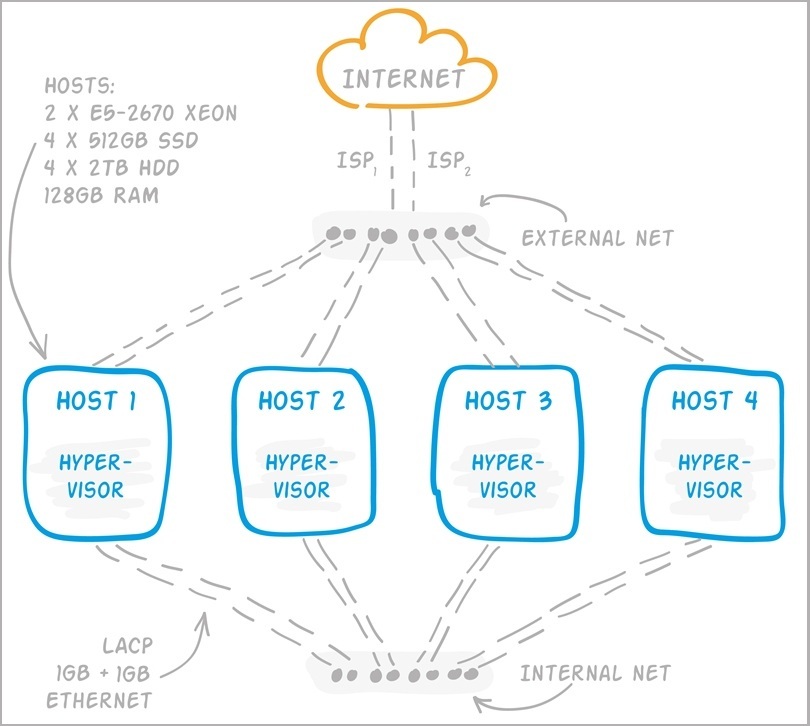
Figure 2. Schematic representation of the Pandorama infrastructure — physical servers and network connectivity
The whole system is balanced in terms of load and has some redundancy in the volume of stored data for fault tolerance. For example, if one of the VMs fails, the data will not be lost, while the other VMs will take over the load themselves. Somewhere this is achieved through VM replication, somewhere due to data replication by the application inside the VM (for example, in the case of MongoDB). As you noted, there is no single storage in the Pandorama infrastructure (expensive), but all the VMs are balanced in physical servers.
Each of the four hosts has 128 GB of RAM and 2 Xeon E5-2670 processors. With Hyper-Threading, 32 vCPUs are obtained. A RAID-10 array of SATA disks for hosting VMs and data that do not require fast access. For VMs with active I / O array of SSDs. In order to increase the lifespan of SSD, Pandorama architects made sure that guest OS file systems work with TRIM through a hypervisor. Of course, you also need to regularly check the status of the disks themselves.
Since each server has a 4 x 1Gb Ethernet NIC (in addition to KVM Over IP), it was decided to organize 2 networks inside the infrastructure. The external network through the infrastructure of the hosting provider is connected to the Internet via a gigabit channel, and the internal network is isolated. At the same time, in each of the networks, 2 x 1Gb is combined with LACP into one logical connection. Separation into the internal and external networks made it possible to conveniently and simply eliminate the influence of internal service traffic on external “client” traffic. And LACP simultaneously improves both performance (by balancing TCP connections between interfaces) and fault tolerance through redundancy of channels.
Logically, the Pandorama infrastructure can be divided into 3 separate blocks.

Figure 3. Schematic representation of the Pandorama infrastructure “by module”
Core content delivery. The workload of this block depends on the number of sources that need to be circumvented (now about 35 thousand per day), and the number of articles and texts that need to be processed. This unit should not suffer from user load on the site. Conversely, the Front End, which interacts with the user, should not experience supply problems. These parts are separated. The third unit, connecting, transmits and stores data.
Pandorama uses many different mechanisms for collecting and processing text and graphics, for example:
- Crawling articles with filtering out irrelevant content (just like getpocket.com or readability.com does )
- Automatic tagging of articles: this is about "cakes", and this is about "cameras"
- Finding similar articles or duplicate pictures
About 40 services work on content delivery, and for some of them, computer-training methods are used (this is the topic of a separate article :). Delivery services are packaged in units that can operate relatively independently (it turns out a VM containing about 40 services in a certain configuration). Further, these units are replicated on different hosts, which ensures the scalability and resiliency of the delivery.
A little bit about the data core. Intermediate data that does not require storage is transmitted via the RabbitMQ bus. This tire is light and unpretentious. RabbitMQ has several options for protection against failures. You can make the message queue transactional, i.e. each of them will be forcibly saved to disk. You can set up a cluster with mirroring queues. For Pandorama, these mechanisms turned out to be redundant, so a cold copy was simply created, a replica VM with RabbitMQ on a neighboring host, which will start if the main VM stops working.
Another thing is the database. The main database is MongoDB. Sharding , mirror replicas and backup, which will be discussed below, are used to improve performance and reliability. One of the problem points is a poorly scalable SQL database. The fact is that in Pandorama a lot of code that has not yet been transferred to work with MongoDB. Therefore, in some cases, SQL is used, and its resiliency has been achieved through a hot spare — mirroring.
And now about what users interact with - Front-end.
Figure 4. An example of a personalized Pandorama tape.
It applies a whole bunch of technologies to improve reliability and performance. There are 2 web server clusters:
- The first cluster serves the user and generates a personalized content feed for him. Protection against failures and load balancing is performed using HAProxy. At the same time, so that the instance of HAProxy itself does not become a point of failure, several of them are deployed with the DNS Round Robin configured. This is a good old lamp technology that just works when a user chooses a random IP address from the list. This allows you to distribute the load without a dedicated balancer, but what about the user session? This problem is solved by HAProxy, which knows which of the cluster's web servers is served by the current user.
- The second cluster is designed to deliver static content, where there is no concept of a user session. This is where DNS Round Robin would be useful, but, unfortunately, the CDN , which is used in Pandorama, does not yet support this technology, so NLB is configured in Pandorama.
A few words about the CDN. The download traffic for pictures is many times the rest of the traffic with Pandorama. CloudFlare is used as a CDN on Pandorama. With the exception of a few remarks, this service is completely satisfied and allows you to save more than 85% of the traffic.
Pandorama data protection against failures
The question of data protection and fault tolerance arose at the design stage of the service infrastructure. In terms of fault tolerance, the system is now configured in such a way that when one physical server fails, the remaining three will take over the load. In terms of protecting data from failures, Veeam Backup & Replication Cloud Edition protects the virtual part of the infrastructure through backups and replication of key running virtual machines to neighboring hosts.
How is data protection in Pandorama?
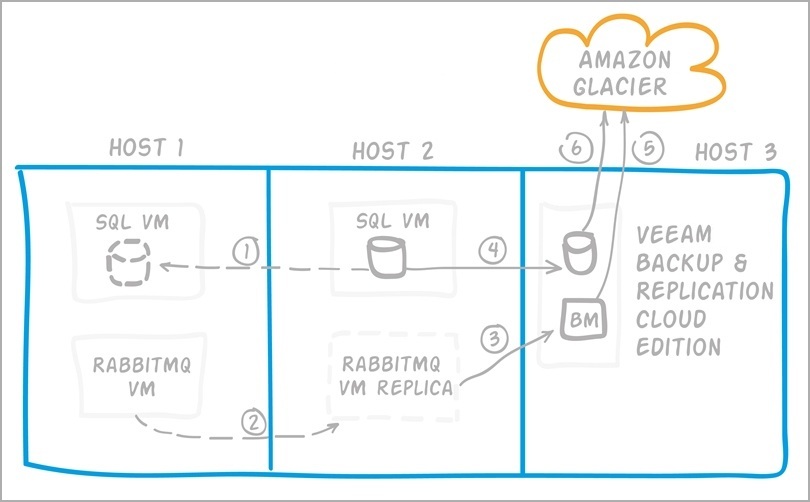
Figure 5. Principles of data backup in Pandorama
- If the application inside the VM allows replication to be done in an integrated way, then this functionality is used. For example, this is how MongoDB and SQL are mirrored and the cache of pictures in the web cluster is synchronized.
- If this is not possible, then the entire VM is replicated, for example, RabbitMQ VM - once every 4 hours.
- In addition to replication, there must be full and differential backups ... If the application allows you to make a backup using the built-in functionality, you can use it, as, for example, in the case of SQL or saving logs of web servers as separate files.
- Otherwise, a backup copy of the entire VM is made. For example, the Pandorama team comes from MongoDB in the absence of an acceptable backup solution.
- Once a week, VM backups are uploaded to the Amazon Glacier cloud. Moreover, deduplication and compression in Veeam Backup reduce the size of the backup from 140GB (the size of the original VM) to 10GB.
- Other backups are also sent to the cloud. It is important to note here that Veeam helps not only to make backups in a virtual environment, but is also used in Pandorama to upload other files to the cloud.
In fact, in terms of data protection, Pandorama successfully implemented a 3-2-1 backup rule : copies of data are stored in at least three copies (source data, local replica, and one copy in the cloud), in two different physical environments (locally on disk and in a cloud), and one copy is taken out on off-site storage.
Recovery testing
The relevance of backup recovery testing was discussed earlier in this post . The Pandorama team is testing the recoverability of the system after various “accidents”.
The following possible scenarios are considered:
- Disconnect one VM or physical server. The team emulated various events, for example, by disconnecting the VMs one by one or a whole host, and looked at how this would affect the entire system. At the same time, a user load imitation occurred. Testing revealed certain problems that were later fixed.
- Burnt down the entire data center. Data protection in the event of such a development is a simple backup in Amazon Glacier. This is the worst case scenario, and it is acceptable for Pandorama that system recovery will occur within a couple of days. Why is that? Because protection with a lower RTO from such an accident costs more than a startup can afford, and there is no need for that.
Conclusion
The example of the Pandorama project proves once again: that storing large amounts of unstructured data (BigData) and their protection, system resiliency, and solutions for providing multiple users with simultaneous access to the Internet service - everything can be configured relatively simply, functionally, and not expensively .
Useful links:
- Pandorama (in English)
- Backup Rule 3-2-1
- Whiteboard Russia! Virtualization from scratch (video, duration 1:27)
- 10 principles of a protected virtual environment (video, duration 1:20)
- Hundreds of virtual machines: data protection guidelines
- 10 recommendations for monitoring the VMware environment
- How to start a billion company
Authors: Maria Levkina (Veeam) [ vMaria ], Konstantin Pichugov (Pandorama), Alexander Shirmanov (Veeam) [ sysmetic ]
Source: https://habr.com/ru/post/193672/
All Articles