Direct data transfer between FPGA Virtex-7 over the bus PCI Express
annotation
This article discusses the data transmission on the PCI Express bus with the simultaneous participation of several FPGAs. In a computer system, to the PCI Express bus of which several (in our case, 8) terminal devices (PCIe endpoints) are connected to the FPGA, several data transfer transactions of two types are launched simultaneously: A) DMA transfer between RAM and FPGA (read / write) and B) direct data transfer between two FPGAs (write). Using a PCI Express x4 Gen 2.0 connection when accessing memory, a write speed of 1451 MB / s (90% of the maximum) was obtained. The data writing speed between the FPGA was equal to 1603 MB / s (99% of the maximum) with a packet length of 128 bytes and 1740 MB / s (99% of the maximum) with a packet length of 256 bytes. The latency of data transfer between the FPGA depends on the number of intermediate switches, and was equal to 0.7 µs for one switch and 1 µs for three. It is also shown that during simultaneous transmissions through a common channel, the speed of individual transmissions does not decrease until the total transmission speed exceeds the throughput of the common channel; then the channel is used at 100%, and its bandwidth is divided equally between the devices.
Introduction
PCI Express has de facto become the standard for transferring data between CPUs, system memory, and hardware accelerators (GPUs, FPGAs) in High Performance Computing (HPC) tasks. Firstly, the PCI Express bus has a low latency, and secondly, it has a high data transfer rate (about 7 GB / s with a PCI Express x8 Gen 3.0 connection). Finally, PCIe bus has good scalability: usually on motherboards there is no shortage of PCI Express connectors, to which you can connect several GPU or FPGA accelerator cards. Also recently, technical solutions have appeared that allow expanding the PCI Express bus through cable connections and connecting additional peripheral devices outside the computer case (1).
In modern HPC systems, it is not enough to have a single hardware accelerator. It has already become customary to see two GPU cards on the local PCI Express bus of the computing node. To provide data exchange directly between the GPU, GPUDirect technology was developed (2). Using this technology, it is possible to organize data exchange between GPU devices over the PCI Express bus directly without using RAM as a buffer, which can significantly reduce the overhead of data transfer.
Other examples of many accelerators on the PCI Express bus include systems in which both GPU and FPGA work simultaneously. In the first example, a team of researchers from Australia assembled a personal computer from an Intel motherboard, a Core i7 processor, a nVidia Tesla C2070 GPU and an Altera DE-530 motherboard with a Stratix-IV FPGA chip (3) installed. They called him "Chimera" in honor of the mythical monster of Ancient Greece Chimera, which has 3 heads (goat, snake, lion) on one body. They have successfully solved several problems (Monte-Carlo integration, pattern search in a 2D array) and are working on using this system to analyze continuous gravity waves. A key feature of their project was that the GPU and the FPGA worked simultaneously on the same task, and the data was transferred from the GPU to the FPGA via the PCI Express bus. However, it should be noted that this exchange went under the control of the central processor and through a buffer in RAM.
Another team of researchers from Brussels assembled a hybrid computer with nVidia Tesla C2050 GPU boards and Pico Computing EX-500 FPGAs (4). The last board can include from 1 to 6 Xilinx Virtex6 FPGA crystals, each with its own PCI Express interface to the host. The details of the project are still unclear, the message is available only in the form of a preprint.
')
Finally, a team of developers from Microsoft investigated data transfer directly between the GPU and the FPGA over the PCI Express bus (5). The GPU nVidia GeForce GTX 580 and Xilinx ML605 FPGAs with 1 Virtex6 chip were installed in their system. The developers have found a way to initiate a direct transfer of data between the GPU and the FPGA, using the CUDA API, GPUDirect technology and the redesign of the Linux FPGA device driver. This made it possible to increase the speed and reduce the latency of data transmission in comparison with the approach that uses RAM as an intermediate buffer. In this case, the GPU was the master device, and the FPGA was the slave.
The PCI Express bus can also be used to transfer data directly between the FPGAs. Xilinx has demonstrated this capability (6). Xilinx engineers connected two FPGAs directly over the PCI Express bus without using switches and without a computer at all with a central processor. One chip independently configured its PCI Express interface, established connection with the second one and configured it. After that, it was possible to transfer data in both directions between two FPGA crystals. This approach demonstrates the fundamental possibility of transferring data between the FPGAs via the PCI Express bus, but cannot be used when several FPGAs are connected to a computer with a central processor via PCI Express switches.
This article describes the transfer of data in a system that contains many FPGAs on a PCI Express bus. The issues of simultaneous data transfer between system memory and several FPGAs, as well as simultaneous data transfer between several FPGAs directly with each other are discussed. According to our information this message is the first in the part of the description of data transfer between the FPGA via PCI Express computer bus.
System description
The experiments were carried out in the following system. In the motherboard with an Intel Core i7 processor, a RHA-25 adapter manufactured by Rosta (1) was installed into the PCI Express 2.0 x8 slot, expanding the PCI Express bus through cable connections. The RHA-25 adapter is equipped with a PCI Express switch (PLX Technology), three ports of which are used for external connections: one blade upstream x8 Gen 3.0 port and two cable downstream x4 Gen 3.0 ports. The computer unit RB-8V7 (1) was connected to this system via 2 PCI Express x4 Gen 3.0 cable connections. The RB-8V7 unit has a symmetric architecture and structurally consists of two RC-47 boards. Each RC-47 board has a PLX PCI Express switch with one cable upstream port and four downstream ports, each connected to its own Xilinx Virtex-7 FPGA (XC7V585T). Thus, in our system, 8 FIRMs Virtex-7 (V7) were connected to the host via a PCI Express bus using one RHA-25 adapter. All FPGAs were connected to the PLX switchboard via PCI Express x4 Gen 2.0 interface.
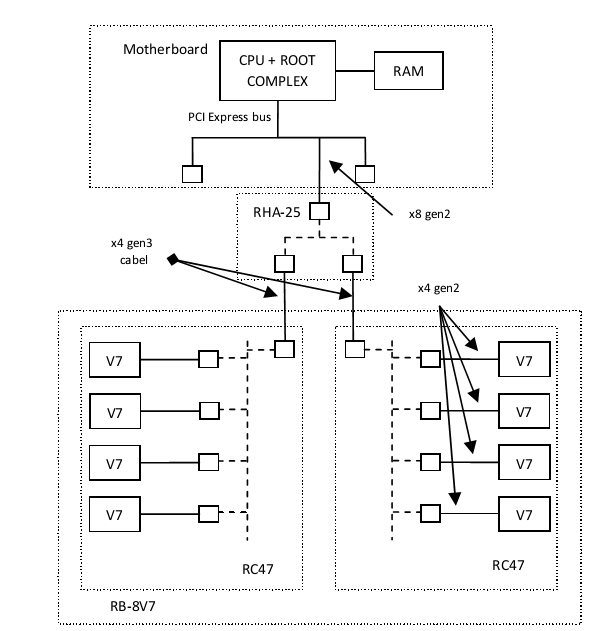
Fig. 1 Hardware. The RB-8V7 is connected via cable PCIe connections and an RHA-25 adapter to the host computer.
Inside the FPGA, the following scheme was implemented (Fig. 2). The project uses the PCI Express IP core of Xilinx (7). The Rosta DMA Engine block determines the functionality of the device on the PCI Express bus. FPGA can act as both a master and slave device. As a slave, the FPGA provides the CPU with read and write access to its registers, and it can also receive large data packets from other devices on the bus (for example, from other FPGAs) while storing the received data in the EP_RX_FIFO queue. As a master device, the FPGA is able to access the computer's RAM in DMA (read / write) mode. In this case, when writing to memory, data will be read from TX_FIFO, and when reading from memory, it will be written to RX_FIFO. The device is also capable of generating write transactions at an arbitrary address on the bus (for example, for transferring data to other FPGAs), in this case, the data to be transferred is read from the EP_TX_FIFO queue. The reception of incoming packets is organized by the RX_STATE_MACHINE machine; the TX_STATE_MACHINE machine is responsible for the transmission of packets. Reception and transmission of packets can go simultaneously. The TX_ARBITER block determines which packet to generate for transmission as follows: absolute priority is given to generating responses in the process of reading registers by the central processor, other packets (read / write memory requests or write requests to an arbitrary address) are scheduled with equal priority (round-robin) .
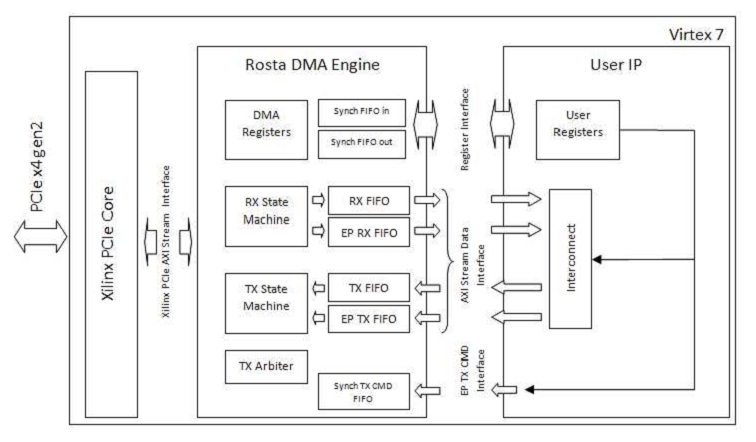
Fig. 2 Block diagram of the FPGA project
DMA data transfer between the FPGA and RAM is handled by the central processor (by writing to the DMA_REGISTERS block), and there is an internal hardware interface EP TX CMD for controlling the process of writing data to an arbitrary address to another FPGA. There is a Register Interface for access to user registers in the User IP block, and for block data transfer between the PCI Express space and the user circuit there are four AXI Stream interfaces connected to the RX_FIFO, TX_FIFO, EP_RX_FIFO, EP_TX_FIFO queues. Finally, in the direction of the PCI Express core Xilinx, the Rosta DMA Engine supports the Xilinx PCIe AXI Stream Interface, which is 64 bits wide. The unit operates at two clock frequencies: at the PCIe frequency of the Xilinx core (250 MHz), the left side of the circuit, and at an arbitrary user frequency, the right side of the circuit. The decoupling of frequencies occurs through the FIFO queues. But in all the experiments described below, the user frequency was equal to the frequency at which the PCIe core worked (250 MHz).
The User IP block defines the device behavior at the application level. In this work, we used several different schemes for different purposes.
First, the scheme was used to verify the correctness of data transfer between the FPGA and RAM. In this case, in the Interconnect block, the RX_FIFO output was simply closed at the TX_FIFO input. This made it possible to write into memory exactly the same data that was read from it. The program on the central processor (hereinafter simply the host) wrote the data into the FPGA, read it, compared it, and made sure that the data were correctly compared.
Secondly, the scheme was used to measure the maximum data transfer rate between the FPGA and RAM in both directions. To do this, from RX_FIFO, the data was constantly read, i.e. the queue was always empty, and there were no delays in receiving data due to its overflow, and in TX_FIFO there was a constant data record, i.e. There were no delays in the transmission due to lack of data in the queue.
Thirdly, a scheme was developed to verify the correctness of direct data transfer between the FPGAs. In the Interconnect block, the switching circuit of the RX_FIFO and EP_RX_FIFO outputs and the TX_FIFO and EP_TX_FIFO inputs was implemented. In the first case, the output RX_FIFO was closed to the input TX_FIFO, and the output EP_RX_FIFO - to the input EP_TX_FIFO. In the second case, the output RX_FIFO is closed to the input EP_TX_FIFO, and the output EP_RX_FIFO - to the input TX_FIFO. This switching scheme was controlled by a bit from one of the user registers. Registers have been added to the User Registers block to control the EP TX CMD interface. In this case, the host itself controlled the transfer of data between the FPGA, but in general the EP TX CMD interface was designed in such a way that the FPGA scheme itself could initiate the transfer of data.
Fourth, to measure the maximum data transfer rate between the FPGAs, a special scheme was developed, which constantly transferred data to EP_TX_FIFO when transmitting data, and when receiving it constantly read data from EP_RX_FIFO. At the same time, a hardware timer was implemented inside the circuit, the values of which were saved and then sent to the host. The EP TX CMD interface controlled the host through user registers.
Finally, to measure latency, a scheme was used that transmits data to another FPGA. The host FPGA data immediately recorded them back into the same device. In the transmitting FPGA, simultaneously with the start of the transfer, a hardware timer started, which stopped at the moment when the data began to arrive in the EP_RX_FIFO queue. Further, the timer value could be read to the host through user registers.
The host has been running Linux. To work with the equipment used drivers and libraries of its own design.
PCI Express bus bandwidth
Before proceeding to the description of experiments on measuring the speed of data transmission, it is necessary to determine its theoretical limit. It is known that due to the use of 8B / 10B coding, the maximum theoretical information transfer rate over one PCI Express line at 2.5 GHz (gen1) is equal to V_theory = 2.0 Gbit / s. For the second generation Gen 2.0 protocol with a frequency of 5 GHz, this speed is 2 times higher (V_theory = 4.0 Gbit / s). The information transfer rate for the third generation is higher by 2 times and is equal to V_theory = 8.0 Gbit / s per line (despite the fact that the frequency is 8 GHz, the third generation protocol uses another 128B / 130B character encoding method that reduces the additional load).
However, data is transmitted at a slightly lower rate due to the fact that the transmission is transmitted in packets that include additional information (start / stop bits, header, checksum, etc.). As a result, when transferring one batch of transaction records, in addition to the data, an additional 20 bytes are transmitted, related to the same batch. Also on the PCI Express bus, packets are transmitted that do not contain data at all, but perform purely utility functions. These include confirmations of the reception of data packets, the requirement to repeat the transfer in case of a checksum mismatch, packets that update the buffer counters of free space in the switches, and others. It is difficult to estimate their impact on the data transfer rate accurately (it depends on the specific implementation), however, it is possible to estimate on average their contribution as 3 additional bytes per 1 data packet (8). In total, we assume that an average of 23 additional service bytes are transmitted for the transmission of one packet of data. For more details, see (8). In the future, unless otherwise specified, by the length of the packet we will understand the amount of data in the packet.
The bus PCI Express data can be transmitted packets of different lengths. The maximum amount of data during transmission of one packet is determined by the parameter MAX_PAYLOAD_SIZE, the value of which is equal to the power of two. Each device has a parameter MAX_PAYLOAD_SIZE_SUPPORTED, which determines the maximum packet size that can be sent by this device. The configuration software (BIOS program) sets the MAX_PAYLOAD_SIZE parameter for all devices in the system to the smallest of the values supported by the devices in the system. As a rule, modern chipsets support packet sizes up to 128 bytes, however there are systems with 256 bytes. In our experiments, the chipset parameter MAX_PAYLOAD_SIZE_SUPPORTED was 128 bytes, and although the FPGA devices and PCI Express switches on the RHA-25 and RC-47 boards supported large packet sizes (up to 512), the BIOS configured the MAX_PAYLOAD_SIZE parameter for all devices in the system is 128 bytes.
The larger the size of the transmitted packets, the closer the throughput approaches the theoretical limit of information transfer. If the theoretical limit is taken equal to 1, then using the following formula, you can calculate the practical limit of data transfer depending on the packet size (see Table 1):
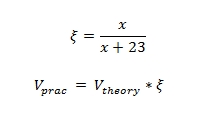
where x is the packet size.

Table 1. Dependence of the relative data transfer rate on the packet size
In tab. 2 compares the maximum theoretical and practical data transfer rates for a packet length of 128 and 256 bytes.
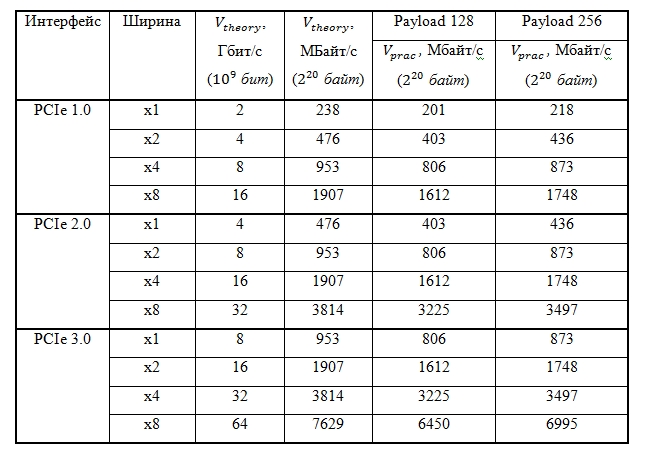
Table 2. Maximum information transfer and data rates on the PCI Express bus for 128 and 256 byte packets
Transfer HOST-FPGA
When transferring data between the FPGA and system memory, a direct memory access mechanism is used. A user application on the host prepares a buffer in RAM and makes a write or read system call. The PCI Express device driver captures user buffer pages in memory and uses the scatter / gather DMA mechanism. The list of descriptors (address-length pair) of pages is written into the internal memory of the FPGA device, and then the FPGA itself is stored in the memory at addresses from this list. After completing the data transfer, the FPGA generates an interrupt that completes the system call. When the user application intends to write data to the FPGA, the device contacts the RAM with read transactions, and when reading from the FPGA the device generates write transactions. Further everywhere it will be implied that the words “writing” and “reading” refer to FPGA, i.e. write speed refers to the speed of the write process started by the FPGA.
The write transactions generated on the PCI Express bus are always unidirectional. The initiator of the write transaction forms a packet consisting of a header and data. The initiator itself determines the size of the data, taking into account only the constraint MAX_PAYLOAD_SIZE. All that was said about the data transfer rate in the previous paragraph refers specifically to write transactions. For write transactions, the data transfer rate is easy to estimate theoretically and measure its dependence on the size of the transmitted packet.
With read transactions, things are a little more complicated. The initiator of the read transaction first creates a read request — a short packet consisting of only the header. This package indicates from where (from which address) and how much data to read. The maximum amount of data that can be requested at one time is determined by the MAX_READ_REQUEST_SIZE parameter and is usually 4 KB. Typically, peripheral devices request reads in RAM, but can also request data from another device. When a device (peripheral or RAM controller) receives a read request, it first requests the required data from its memory, and then returns it to the initiator of the transaction via the PCI Express bus, generating completion request packets. At the same time, it itself determines the size of the returned packets, again considering only the limit MAX_PAYLOAD_SIZE. The initiator of the transaction can not affect the size of the returned packets. As a rule, the RAM controller will return packets with a data length of MAX_PAYLOAD_SIZE.
The data transfer rate for read transactions is difficult to estimate for several reasons. First, two types of packets are generated, moving in opposite directions — read requests and final responses. Secondly, the data transfer rate will be affected by delays arising from reading from RAM. Finally, it is unclear how to trace the dependence of the data transfer rate on the amount of data in the packet. Therefore, in this work, we simply measured the integral time from sending the first read request to the arrival of the last byte of data, calculated the speed at which data was read from RAM and did not track its dependence on the packet size.
The PCI Express bus provides reliable data transfer at the transaction level, i.e., sending data, agents (end devices and intermediate switches) automatically calculate the checksum of the packet, compare it with the encoded packet itself, and require retransmission if an error is detected during transmission data. However, this does not mean that the application on the host or the FPGA scheme cannot generate and transmit incorrect data as a result of a programmer's error. Therefore, to verify the correctness of our scheme, which includes the application, the driver, and the FPGA circuit, we checked the correctness of the data transfer. For this, the first User IP scheme was used, in which the output RX_FIFO was closed to the input TX_FIFO. FIFO queue sizes were 4 KB. Two experiments were conducted. In the first, the host sequentially wrote down 4 KB of data in the FPGA, then read them and compared them. The second experiment used the fact that the paths for receiving and transmitting data in the FPGA can work in parallel. The host first programmed both write and read operations, and then the FPGA began reading data from RAM, and as soon as they entered first into RX_FIFO and then into TX_FIFO, they immediately began writing them back to RAM. This made it possible to transfer a much larger amount of data at a time compared to the size of the RX_FIFO and TX_FIFO queues (in our experiment 4 MB). In both experiments, the comparison of the transmitted and received data was successful, which allowed us to judge the correctness of the operation of our scheme.
Experiments on measuring data transfer rates began with measuring the dependence of the write speed in the RAM of one FPGA device on the size of the data in the transmitted packets. Experiments were conducted with payload values of 8, 16, 32, 64, and 128 bytes. In each experiment, 4 MB were transferred in one direction. The bottleneck in the Virtex7-RAM path was the PCI Express x4 Gen 2.0 connection between the FPGA and the PCI Express switch on the RC47 (see Figure 1). The results are presented in Fig. 3. The upper Vtheory curve represents a theoretical dependence (formula 1) of the maximum achievable data transfer rate on the packet length (for PCI Express x4 Gen 2.0 interface). The curve in the middle of Vhard is the speed measured by the hardware timer in the FPGA and takes into account only the data transfer on the PCI Express bus (the time was measured from the beginning of the transfer of the first packet of data to the end of the transfer of the last). Finally, the Vapp curve represents the speed measured in the application on the host (the time taken to perform the read system call was measured).
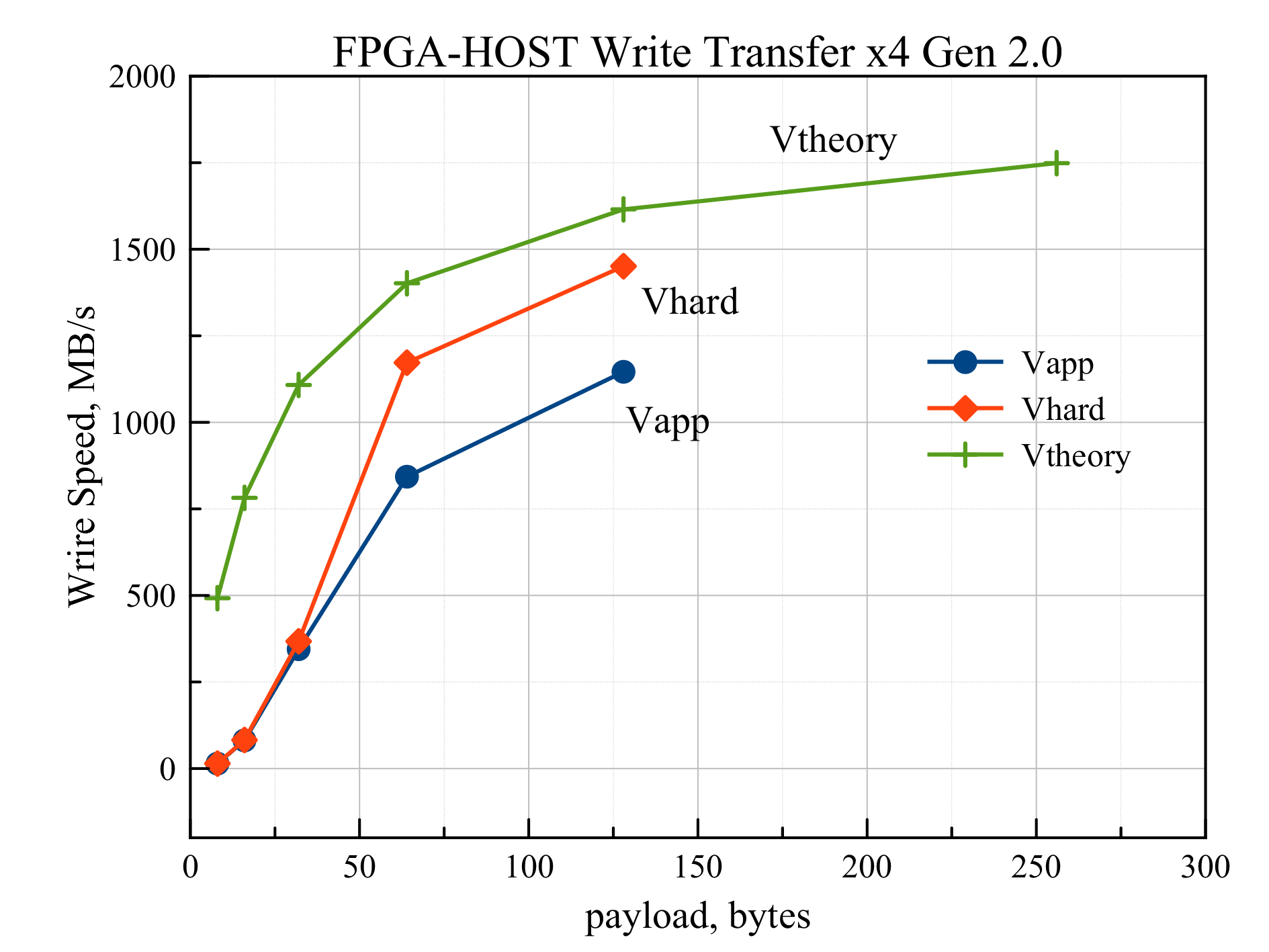
Fig. 3 The dependence of the write speed in RAM on the packet length for the interface PCI Express x4 Gen 2.0
From the graph it is clear that with payload values less than 64 bytes, the Vhard and Vapp speeds are much less than Vtheory. This is because the data receiver in this case is DDR RAM memory, which provides high write speed only in burst mode, transferring a large amount of data per transaction. For a packet of 128 bytes in size, Vhard = 1451 MB / s, which is 90% of the maximum value of 1612 MB / s. You can also see that the speed measured in the Vapp application (1146 MB / s with payload = 128) is much lower than the Vhard for payload values, starting from 64 bytes. This is due to the fact that when transferring 4 MB of data, about 1000 page descriptors are generated, which the processor writes to the FPGA. This initial delay (of the order of 1 ms) significantly affects the data transfer rate. The total execution time of the read system call for payload = 128 bytes is approximately 3.7 ms. If we take away from this time the initial delay of 1 ms, then we get a speed of approximately 1450 MB / s, which coincides with the speed of Vhard, measured by hardware.
Our plans include changing the driver logic and the Rosta DMA Engine scheme to reduce the initial delay when programming a DMA transfer. The idea of the improvement is not to transfer the entire list of page descriptors of the user buffer in the FPGA, and instead save it in the area accessible to the FPGA in the RAM. Then the FPGA itself will be able to read the descriptors from the RAM, according to which the data will already be transmitted. The process of reading the descriptors from the memory and the actual data transfer can be run in parallel, thereby significantly reducing the initial delay and, as a result, increasing the data transfer speed. In the meantime, we will focus on the speed measured by the hardware. Also, in subsequent experiments, data transfer with payload less than 128 bytes will not be investigated.
In the next experiment, several data transfers were launched simultaneously with the participation of different FPGAs. pthreads – . , . . 4 , 128 . 8 Virtex7, RB-8V7. . four.
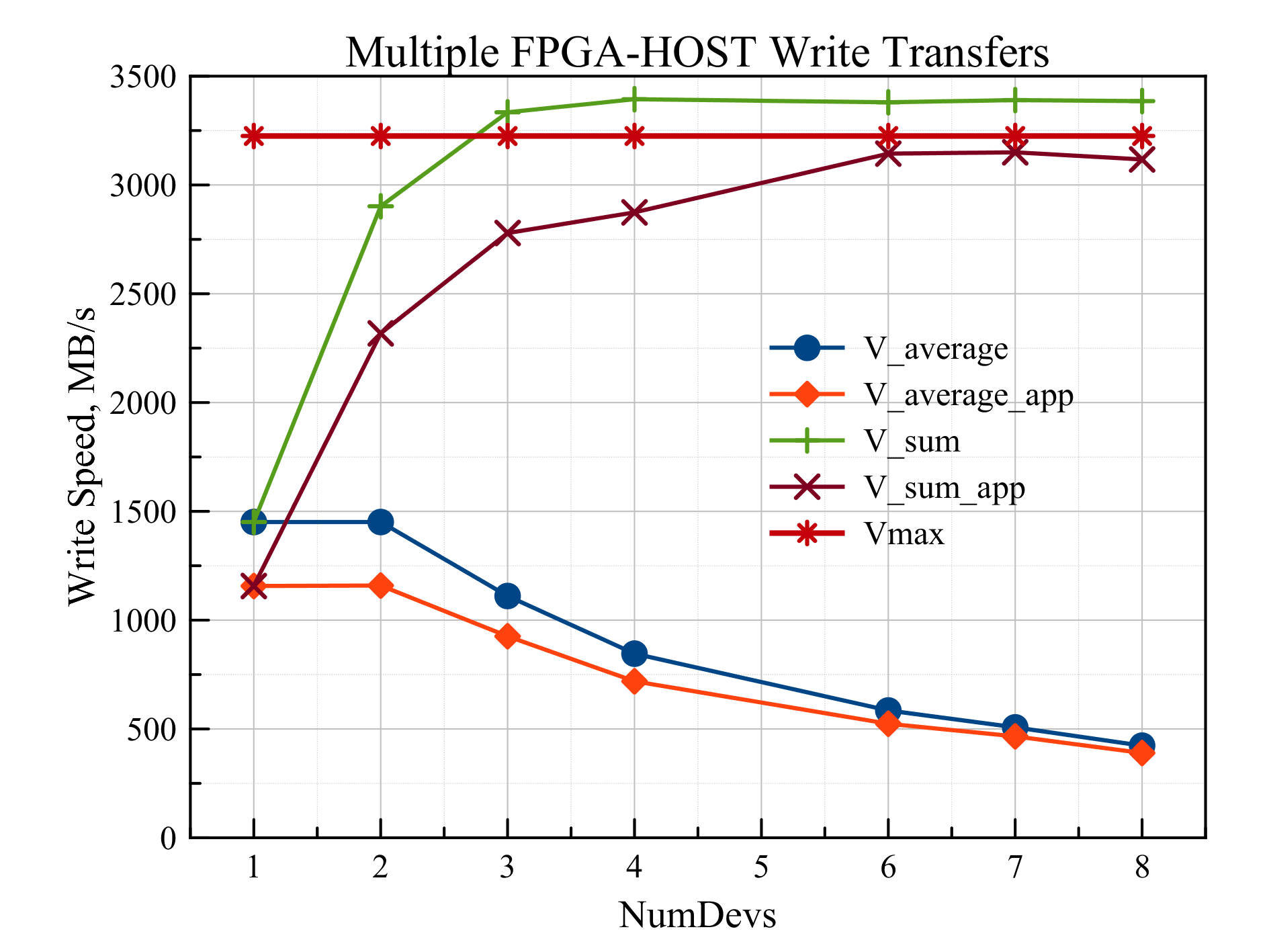
Fig. 4
The lower two curves (V_average and V_average_app) represent the average write speed measured by hardware and in the application, respectively. Each individual FPGA is limited in speed by the maximum data writing speed via the PCI Express x4 Gen 2.0 interface, in our case 1451 MB / s. The V_sum and V_sum_app curves are the sum of the data rates of individual devices. Direct Vmax = 3225 MB / s is the maximum data transfer rate through a system bottleneck, limiting the speed of simultaneous data transfer. This bottleneck is the connection of a PCI Express x8 Gen 2.0 RHA-25 adapter to a computer motherboard. For one and two simultaneous transfers, the recording speed is the same (1451 MB / s), because the total speed of two broadcasts is less than Vmax. Starting with three gears, the write speed of a separate device drops,however, the total velocity is the same and equal to Vmax. The fact that on the graph the total speed for three or more devices exceeds Vmax is explained by the “pseudo-simultaneity” of data transmission. No matter how well the threads are distributed in parallel between the cores of the CPU, on the PCI Express bus the teams still go in series. Therefore, some devices begin to transfer earlier, others later. This leads to the fact that during a short period of time at the beginning and at the end of the data transfer, the common connection channel between the adapter and the motherboard is not used by all devices involved in the transfer. Therefore, for them, the transfer rate is higher, and the sum of all speeds exceeds the maximum. In reality, it turns out that the common channel is used at 100%, and the bandwidth is divided between the devices in equal shares.that on the graph, the total speed for three or more devices exceeds Vmax, is explained by the “pseudo-simultaneity” of data transmission. No matter how well the threads are distributed in parallel between the cores of the CPU, on the PCI Express bus the teams still go in series. Therefore, some devices begin to transfer earlier, others later. This leads to the fact that during a short period of time at the beginning and at the end of the data transfer, the common connection channel between the adapter and the motherboard is not used by all devices involved in the transfer. Therefore, for them, the transfer rate is higher, and the sum of all speeds exceeds the maximum. In reality, it turns out that the common channel is used at 100%, and the bandwidth is divided between the devices in equal shares.that on the graph, the total speed for three or more devices exceeds Vmax, is explained by the “pseudo-simultaneity” of data transmission. No matter how well the threads are distributed in parallel between the cores of the CPU, on the PCI Express bus the teams still go in series. Therefore, some devices begin to transfer earlier, others later. This leads to the fact that during a short period of time at the beginning and at the end of the data transfer, the common connection channel between the adapter and the motherboard is not used by all devices involved in the transfer. Therefore, for them, the transfer rate is higher, and the sum of all speeds exceeds the maximum. In reality, it turns out that the common channel is used at 100%, and the bandwidth is divided between the devices in equal shares.due to "pseudo-time" data transfer. No matter how well the threads are distributed in parallel between the cores of the CPU, on the PCI Express bus the teams still go in series. Therefore, some devices begin to transfer earlier, others later. This leads to the fact that during a short period of time at the beginning and at the end of the data transfer, the common connection channel between the adapter and the motherboard is not used by all devices involved in the transfer. Therefore, for them, the transfer rate is higher, and the sum of all speeds exceeds the maximum. In reality, it turns out that the common channel is used at 100%, and the bandwidth is divided between the devices in equal shares.due to "pseudo-time" data transfer. No matter how well the threads are distributed in parallel between the cores of the CPU, on the PCI Express bus the teams still go in series. Therefore, some devices begin to transfer earlier, others later. This leads to the fact that during a short period of time at the beginning and at the end of the data transfer, the common connection channel between the adapter and the motherboard is not used by all devices involved in the transfer. Therefore, for them, the transfer rate is higher, and the sum of all speeds exceeds the maximum. In reality, it turns out that the common channel is used at 100%, and the bandwidth is divided between the devices in equal shares.on the PCI Express bus, the teams still go consistently. Therefore, some devices begin to transfer earlier, others later. This leads to the fact that during a short period of time at the beginning and at the end of the data transfer, the common connection channel between the adapter and the motherboard is not used by all devices involved in the transfer. Therefore, for them, the transfer rate is higher, and the sum of all speeds exceeds the maximum. In reality, it turns out that the common channel is used at 100%, and the bandwidth is divided between the devices in equal shares.on the PCI Express bus, the teams still go consistently. Therefore, some devices begin to transfer earlier, others later. This leads to the fact that during a short period of time at the beginning and at the end of the data transfer, the common connection channel between the adapter and the motherboard is not used by all devices involved in the transfer. Therefore, for them, the transfer rate is higher, and the sum of all speeds exceeds the maximum. In reality, it turns out that the common channel is used at 100%, and the bandwidth is divided between the devices in equal shares.that during a short period of time at the beginning and at the end of the data transfer, the common channel of the connection between the adapter and the motherboard is not used by all devices involved in the transfer. Therefore, for them, the transfer rate is higher, and the sum of all speeds exceeds the maximum. In reality, it turns out that the common channel is used at 100%, and the bandwidth is divided between the devices in equal shares.that during a short period of time at the beginning and at the end of the data transfer, the common channel of the connection between the adapter and the motherboard is not used by all devices involved in the transfer. Therefore, for them, the transfer rate is higher, and the sum of all speeds exceeds the maximum. In reality, it turns out that the common channel is used at 100%, and the bandwidth is divided between the devices in equal shares.
Similarly, we can consider the case of reading from RAM (Fig. 5).
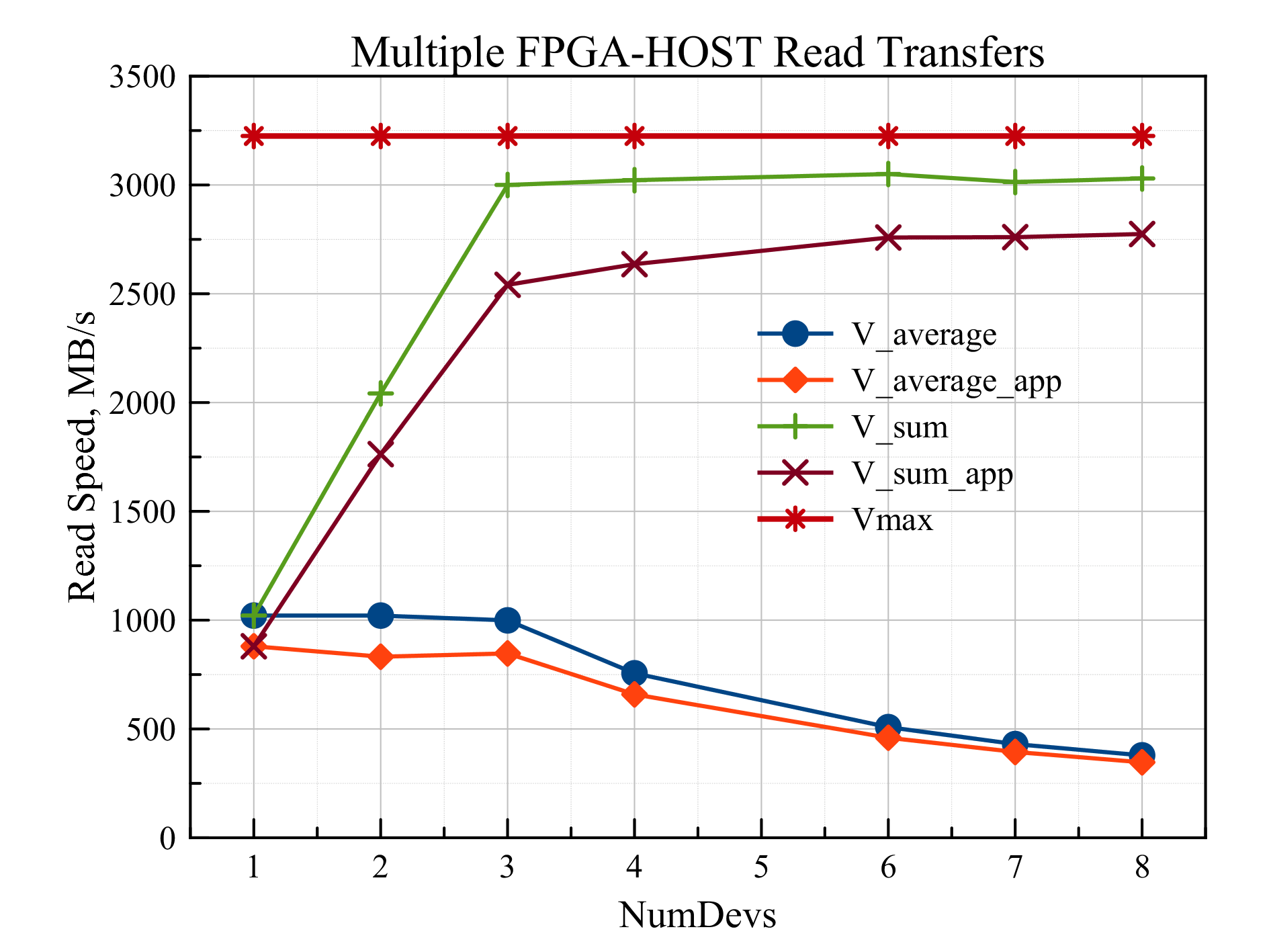
Fig.5 The dependence of the speed of reading from the RAM on the number of simultaneous transactions.
Here you can see that for transferring data involving one to three devices, the reading speed for each device is the same and is 1000 MB / s. Starting with four devices, the speed is limited by the bandwidth of the communication channel with the host.
Transmission FPGA-FPGA
Requests to write and read memory on the PCI Express bus are sent according to the address encoded in the packet headers. The master device is able to generate a packet with an arbitrary address. This address may point to RAM, or it may belong to addresses allocated to another peripheral device. In the latter case, the request packet will be sent from one device to another. In our case, thus, write requests were sent between different FPGAs. There were no tests for reading.
BIOS , . B, A ( User IP) B. Rosta DMA Engine EP TX CMD, . EP_TX_FIFO EP TX CMD . TX_STATE_MACHINE Rosta DMA Engine EP_TX_FIFO . EP_RX_FIFO.
For a start, it was necessary to make sure that the data transfer between the FPGAs was correct. For this, the following experiment was made. A sequence of all 8 Virtex7 FPGAs that make up the RB-8V7 was used in the transmission (Fig. 6).
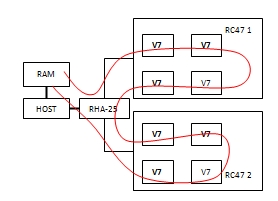
Fig. 6 Data transfer scheme HOST-PLIS-HOST
In the first 7 FPGAs, the host recorded the base addresses of the devices as follows. In the first device - the base address of the second, three times - the third and so on. The first host device was programmed to read data from the RAM and to transfer the read data to the second device. To do this, in User IP, the Interconnect switching unit through User IP registers was configured to connect the RX_FIFO output to the EP_TX_FIFO input. Devices 2-7 were configured to transfer data to the next in the chain. In them, the Interconnect block was configured to connect EP_RX_FIFO with the input EP_TX_FIFO. Finally, the eighth device was programmed to transfer the data received in EP_RX_FIFO via TX_FIFO back to RAM. After the end of the transfer, the host compared the data. In this experiment, the data rate in the path was also measured. It was equal to the speed of reading from the RAM with one FPGA device.
Having ascertained the correctness of the data transfer, one could proceed to the measurement of speed. Due to the fact that the maximum packet length supported by the chipset was 128 bytes, the MAX_PAYLOAD_SIZE parameter for all switches and end devices in the system was set to 128 bytes. Therefore, by default, data transfer between the FPGAs went packets of the same length. However, it was observed that the intermediate PCI Express switches located on the RC-47 cards and the RHA-25 adapter, as well as the PCI Express interfaces inside the FPGA, supported a packet length of 256 bytes. At the same time, the chipset itself was not involved in the transfer of data between the FPGAs. It was assumed that if you set MAX_PAYLOAD_SIZE for all devices in the FPGA-FPGA data transmission path to 256, you can start the transmission of 256 byte packets, despite the fact thatthat the chipset only supports 128.
To change the MAX_PAYLOAD_SIZE parameter using the setpci Linux command, a record was written to the PCI Express Device Control register for all the device and switch ports on the RHA-25 and RC-47 boards. The Rosta DMA Engine block was also modified so that it was possible to generate a packet of 256 bytes in length. After that, it was indeed possible to organize the transfer of data from pancake packs 256, and the data transfer rate increased.
FPGA-FPGA recording speed measurements were performed for a different number of simultaneous transmissions. The results are presented in Table 3.

Table 3. Dependence of the FPGA-FPGA recording speed on the number of simultaneous transmissions with packet lengths of 128 and 256 bytes.
In the first four cases, transmissions went between devices on the same RC47 board. The maximum write speed was obtained during one data transfer and amounted to 1603 MB / s for a packet length of 128 bytes and 1740 MB / s for a packet length of 256 bytes. In both cases, the rate was 99% of the maximum possible for the corresponding packet length.
Diagrams of interaction of devices for cases 8.1 and 8.2 are presented in fig. 7
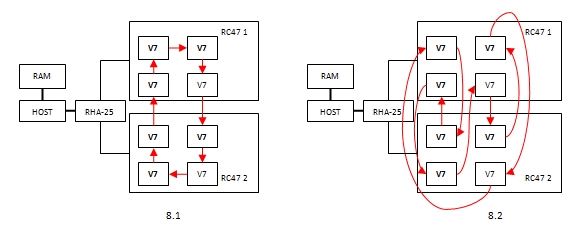
Fig. 7 FPGA interaction in case of 8 simultaneous transmissions
8.1 , RHA-25 . , . RHA-25 , PCI Express x4 Gen 3.0 . 8.2 , . RHA-25 8 , 4 . 128 4*1520 = 6080 /, PCI Express x4 Gen 3.0 3225 /. , 3225/4 = 806 /. 808 /. , 100%. 256 .
Finally, an experiment was conducted to measure the latency of data transmission. The idea of the experiment was as follows. FPGA A sends data to FPGA B and starts a hardware timer. Clocks in different devices are difficult to synchronize, so the timer is used only in FPGA A. As soon as FPGA B receives data, it immediately starts recording it back into FPGA A. The timer stops as soon as FPGA A receives the first data byte. The timer value represents the doubled data transfer latency between the User IP block of one FPGA and the User IP of another. Latency was measured in two cases: during transmission between the FPGA on one RC-47 board (Fig. 8A) and between the FPGA on different boards (Fig. 8 B).
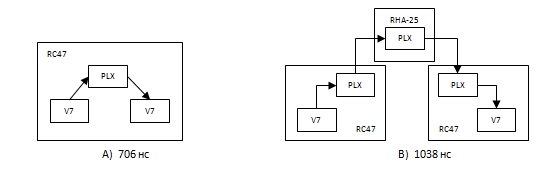
Fig.8 Data Transmission Schemes for Latency Measurements
When transmitting data between devices on one RC-47 board, there was one PLX switch in the transmission path, and the delay was 706 ns. When transmitting from board to board, there were three intermediate switches, and the delay was equal to 1038 ns. From these data, you can determine the delay occurring in the FPGA and introduced by the switch. The delay in FPGAs for receiving and transmitting is equal to 270 ns, and in the switch it is 166 ns, which is in good agreement with the latency of its switches, which is 150 ns declared by PLX Technology.
Conclusion
In this paper, data transmission over the PCI Express bus with simultaneous participation of several FPGAs was described. When writing to RAM, a speed equal to 90% of the maximum for a PCIe x4 Gen 2.0 connection was obtained with a packet length of 128 bytes (1,451 MB / s). When reading from RAM, the speed was 1000 MB / s. In the case of simultaneous FPGA-HOST transmissions, the data transfer rate did not decrease until the number of simultaneous transmissions saturated the narrow communication channel with the host, the channel was subsequently used 100%, and its bandwidth was divided evenly between devices.
- 256 , 128. 1740 /, 99% PCI Express x4 Gen 2.0 256 . , -, , , 100%, .
-, 706 1038 .
All this suggests that the approach based on the use of FPGAs and the IP core of the PCI Express Xilinx interface and PLX Technology switches can be effectively used to organize data exchange between a large number of FPGAs connected to the local PCI Express computer bus.
Bibliography
1. Rosta LTD, 2013. www.rosta.ru .
2. nVidiaCorporation. GPUDirect. developer.nvidia.com/gpudirect .
3. Ra Inta, David J. Bowman, Susan M. Scott, “The“ Chimera ”: An Off-The-Shelf CPU GPGPU FPGA Hybrid Computing Platform, International Journal of Reconfigurable Computing, 2012.
4. Bruno da Silva, An Braeken, Erik H. D'Hollander, Abdellah Touhafi, Jan G. Cornelis, Jan Lemeire, “Performance and toolchain of the combined GPU / FPGA desktop”, Proceedings of the ACM / SIGDA international symposium on Field programmable gate arrays, 2013.
5 Ray Bittner, Erik Ruf, Alessandro Forin, Direct GPU / FPGA Communication Via PCI Express, Cluster Computing, 2013.
6. Sunita Jain, Guru Prasanna, «Point-to-Point Connectivity Using Integrated Endpoint Block for PCI Express Designs», Xilinx Corporation, XAPP869, 2007.
7. 7 Series FPGAs Integrated Block for PCI Express v1.7 Product Guide, Xilinx Corporation, 2012.
8. Alex Goldhammer, John Ayer, «Understanding Performance of PCI Express Systems», Xilinx Corporation, WP350, 2008.
Source: https://habr.com/ru/post/193646/
All Articles