Load testing in Skyforge, or Bots - server orderlies. Part 2
Hello again, habrauzer!
This is the second article dedicated to testing the Skyforge server. Just in case, I remind you that Skyforge is a MMORPG, the server of which is designed for hundreds of thousands of players and is written in Java.
Unlike the first part , which deals with the role of bots, this article talks about load testing and metrics.

')
Habr's readers know that load testing is a collection of software performance indicators to verify compliance.
Our requirements for such tests are quite simple: the load on the server in “combat” conditions should be within the normal range, and the user experience should not suffer. Therefore, when organizing load testing, it is necessary first of all to determine what conditions to consider “combat”. For example, for us this means the following: on two servers of game mechanics, one server of databases and one server with different support services, 5,000 players frolic at the same time. Secondly, you need to determine which load is considered normal. We believe that the server copes with the load if it spends in processing less than 20 milliseconds per server "tick".
We have a service-oriented architecture - this means that the topology of services during the test must coincide with the topology in "combat" conditions. The volume of content should also be close to the volume that will be on the "combat". In general, load testing is production in miniature, where, instead of real users, there are bots.
All tests, including those using bots, are run on our project in a continuous integration system. At the beginning of the test, the build agent updates and starts the server, starts the bots and waits for a specified time, after which it stops the server, analyzes the results and proceeds to the next test.
Due to the fact that we are limited in resources (we have only one bot platform), we need to somehow synchronize their use. Therefore, all tests that use bots are run on a dedicated build agent.
The main load test, during which all content is checked, goes at night for 8 hours. Why was this duration chosen? It was experimentally observed that the most serious mistakes occur at the turn of 4.5–6 hours, and in order to find them, we simply have to carry out such lengthy tests. This interval accounts for FullGC-pause ( more about this phenomenon ), the fight against which is also the goal of the tests. In our plans to implement constant tests lasting 56 hours over the weekend. But so far, unfortunately, these are only plans.
And now I will allow myself to give some tips on the organization of load testing, in passing talking about how it works with us. Yes, I understand that for some people these tips will seem like the notes of the notorious Captain, but for some they may still be useful.
The most important stage of load testing is the selection and preparation of servers for tests. Since we have no combat servers, we chose as close as possible to those that will be at the time of the game's release. Otherwise, it would be necessary to use servers similar to the “combat”.
Servers must be configured exactly as they will be used in the "combat" mode. By the way, we are considering the possibility of using the technology of Thread Affinity , which allows you to assign individual processor cores to specific streams, for example, to the flows of game mechanics. And if this technology "shoots", it will mean that this setting should be enabled when conducting load testing. Otherwise, the server's behavior under load in a test environment and in reality will differ significantly.
You also need to remember that on modern servers there are “green environment” or “electricity saving” modes. I recommend turning them off immediately, exposing the processors to full performance, because “in battle” the servers will not have to rest, but to fix non-existent performance problems during the test in eco mode - this is a bad idea.
It is important that you have full access to your site, so that you can go in at any time and see what is happening there, what processes are running, etc. There should not be an army of evil admins who control every thing between you and the server. This is necessary for two reasons. First, by setting up your stand by yourself and being responsible for its condition, you better understand the problems that may arise. Secondly, you will have complete information about what is happening with your test site. This is very useful when analyzing data anomalies.
Full access also means that you are there alone. If you do load testing, you need to make sure that the server does not have your colleague employed by the same one, and also find out if the database is backing up. You need to be 100% sure that you are there alone.
The easiest and most visual way to analyze load data is to visualize it. We use the Highcharts library for charting , which confidently supplanted jqPlot . Let's look at the examples.
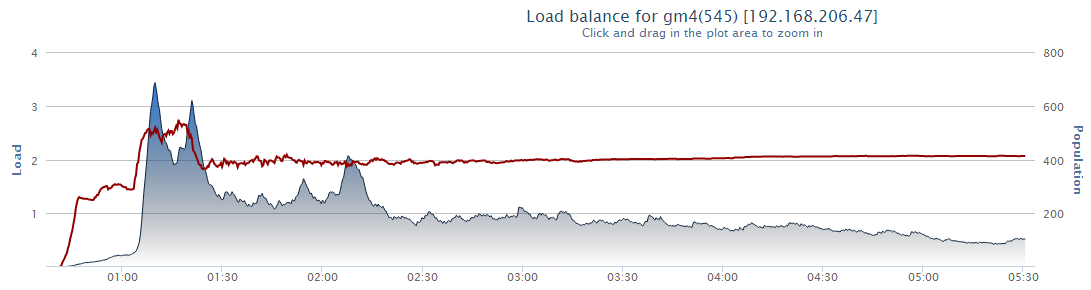
I see a similar schedule every morning. It allows you to track the load. The load on the server is a value equal to the ratio of time in milliseconds spent in processing data for 1 server “tick” to 20 milliseconds. If on the graph the indicator is more than one (more than the norm), then everything is bad, if less - everything is good.
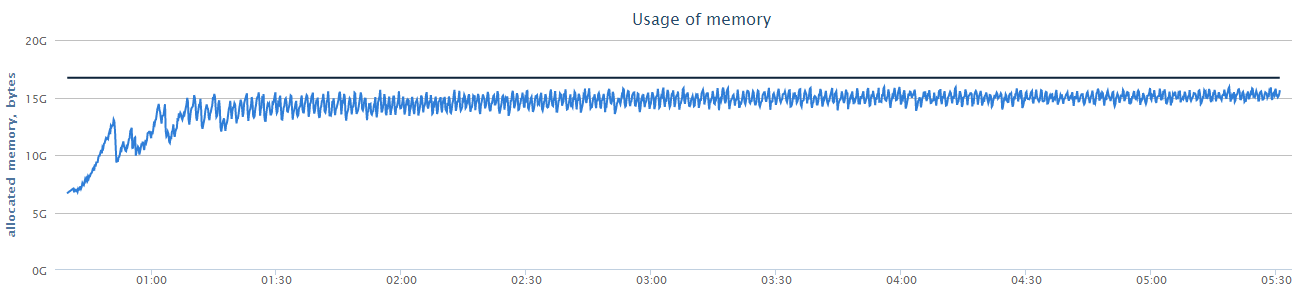
This is a general graph of memory usage. It allows you to roughly evaluate the work of the "garbage collector".
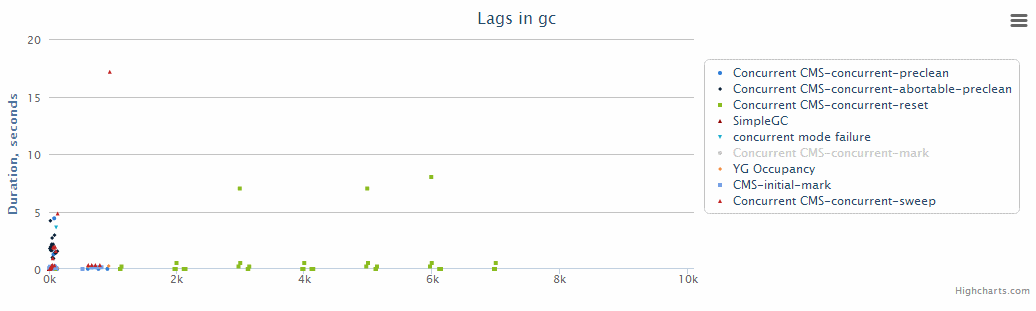
This is probably one of the most important graphs for Java servers. It is unlikely that players will not notice a pause during a complete garbage collection. On it, on the Y axis, the duration of a particular phase of the garbage collector operation is marked.
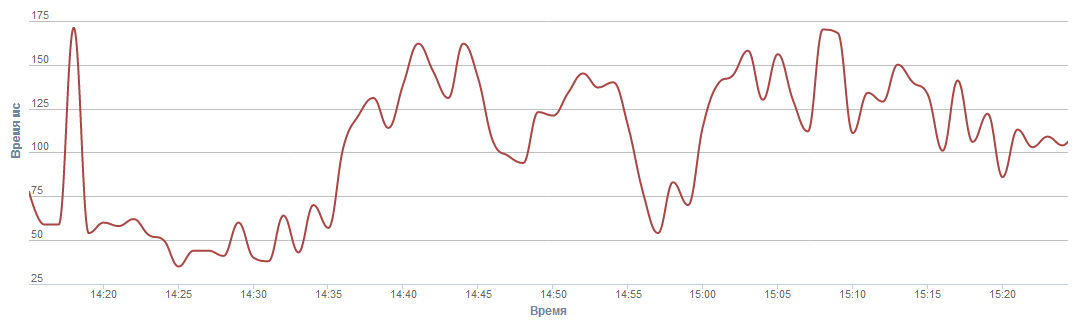
Safepoint is a point in the Java Virtual Machine, where a stop occurs each time you need to collect a stack trace or to collect garbage. Read more about safepoints here . This graph shows how many milliseconds in 1 minute the server spends at these points.
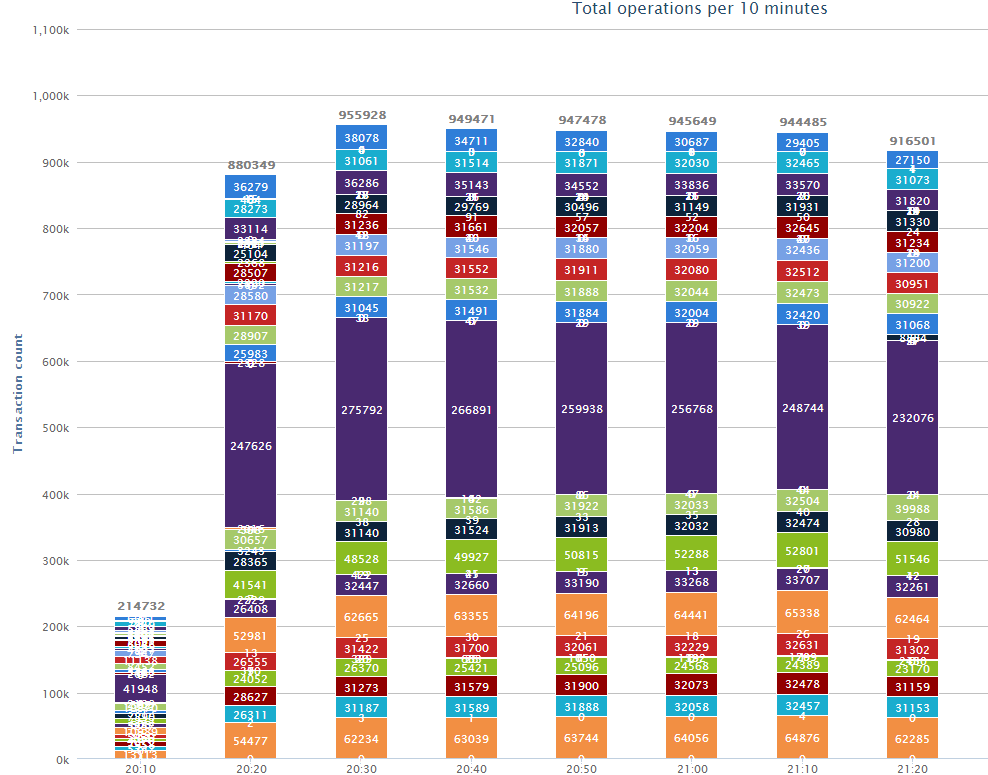
But the beautiful "scarves", which were commissioned by Randll , whose report on the databases you could read earlier. These "scarves" allow us to evaluate which database-operations and in what quantity we are performing.
In addition, several dozens of statisticians are logged, who can tell about high-level indicators (the number of mobs in a single player battle), and low-level indicators (the number of transmitted packets). Most of these statisticians were instituted during investigations regarding the growth load.
For the same purpose, using the Yourkit API, we automatically removed the memory dump and load profile at the end of the test. Now they are analyzed only in manual mode, but it is planned to automate this process as well.
At the end of the test, a so-called error analyzer is launched. We take all the mistakes - and they sometimes go up to 100 gigabytes for the night - and put them on the shelves. We compare which mistakes are repeated most often and which are rare, and we divide them into groups. We sort by type — an error, warning, or informational message — and find out if this is a content error. We transmit the content errors to the QA-specialists in content, and we ourselves investigate errors in the server code.
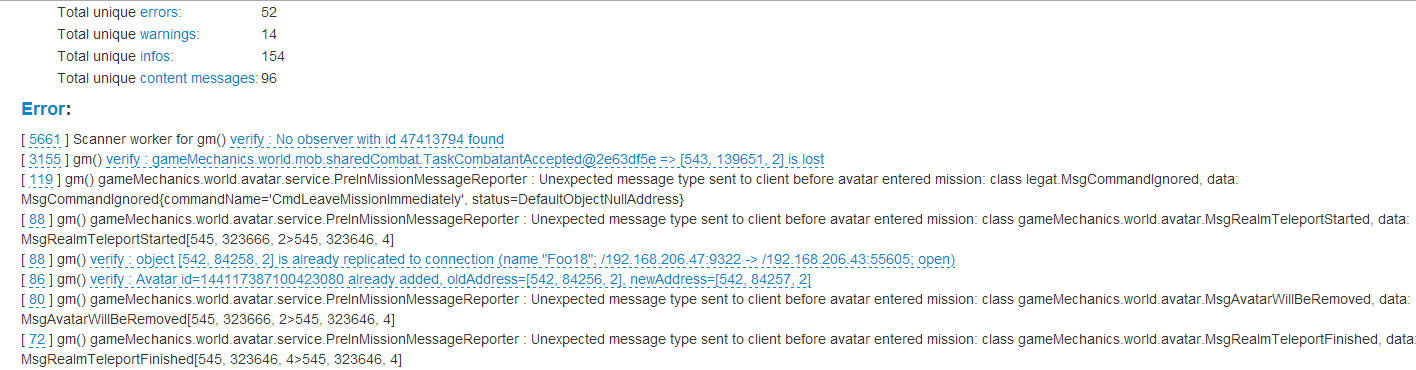
The report indicates how many times and at what time intervals the error was repeated. The number indirectly characterizes the difficulty of repeating this error, its cost for the server (do not forget that when collecting each callstack on the server, the kitten dies) and priority in the bug tracker.
The time of occurrence allows you to evaluate the distribution of errors on the test time. It's one thing if errors are spread evenly, and quite another if they begin and end in a certain time period.
In the future, we plan to develop this system so that we can associate errors with tasks in JIRA and find a revision in which the error was noticed for the first time.
Load night tests have very expensive iterations. The cost of each test is a day. Of course, we make every effort to pass the test every night, but in reality it passes less often and iterations become even more expensive. Any failure in any infrastructure node can disrupt the test.
Regular load testing with the use of various statistics is the best tool for healthy sleep of developers. Now I can’t imagine how it is possible to live without this kind of testing, because thanks to him every morning I see where we havea lot of trouble. It helps us move in the right direction. Thanks for attention!
Other materials can be viewed on the Skyforge developers website and in our Vkontakte community .
Thank you for helping to create a report and writing an article for the entire Skyforge server team.
This is the second article dedicated to testing the Skyforge server. Just in case, I remind you that Skyforge is a MMORPG, the server of which is designed for hundreds of thousands of players and is written in Java.
Unlike the first part , which deals with the role of bots, this article talks about load testing and metrics.
')
Stress Testing
Habr's readers know that load testing is a collection of software performance indicators to verify compliance.
Our requirements for such tests are quite simple: the load on the server in “combat” conditions should be within the normal range, and the user experience should not suffer. Therefore, when organizing load testing, it is necessary first of all to determine what conditions to consider “combat”. For example, for us this means the following: on two servers of game mechanics, one server of databases and one server with different support services, 5,000 players frolic at the same time. Secondly, you need to determine which load is considered normal. We believe that the server copes with the load if it spends in processing less than 20 milliseconds per server "tick".
We have a service-oriented architecture - this means that the topology of services during the test must coincide with the topology in "combat" conditions. The volume of content should also be close to the volume that will be on the "combat". In general, load testing is production in miniature, where, instead of real users, there are bots.
Testing organization
All tests, including those using bots, are run on our project in a continuous integration system. At the beginning of the test, the build agent updates and starts the server, starts the bots and waits for a specified time, after which it stops the server, analyzes the results and proceeds to the next test.
Due to the fact that we are limited in resources (we have only one bot platform), we need to somehow synchronize their use. Therefore, all tests that use bots are run on a dedicated build agent.
Night bots test
The main load test, during which all content is checked, goes at night for 8 hours. Why was this duration chosen? It was experimentally observed that the most serious mistakes occur at the turn of 4.5–6 hours, and in order to find them, we simply have to carry out such lengthy tests. This interval accounts for FullGC-pause ( more about this phenomenon ), the fight against which is also the goal of the tests. In our plans to implement constant tests lasting 56 hours over the weekend. But so far, unfortunately, these are only plans.
Server
And now I will allow myself to give some tips on the organization of load testing, in passing talking about how it works with us. Yes, I understand that for some people these tips will seem like the notes of the notorious Captain, but for some they may still be useful.
The most important stage of load testing is the selection and preparation of servers for tests. Since we have no combat servers, we chose as close as possible to those that will be at the time of the game's release. Otherwise, it would be necessary to use servers similar to the “combat”.
Servers must be configured exactly as they will be used in the "combat" mode. By the way, we are considering the possibility of using the technology of Thread Affinity , which allows you to assign individual processor cores to specific streams, for example, to the flows of game mechanics. And if this technology "shoots", it will mean that this setting should be enabled when conducting load testing. Otherwise, the server's behavior under load in a test environment and in reality will differ significantly.
You also need to remember that on modern servers there are “green environment” or “electricity saving” modes. I recommend turning them off immediately, exposing the processors to full performance, because “in battle” the servers will not have to rest, but to fix non-existent performance problems during the test in eco mode - this is a bad idea.
It is important that you have full access to your site, so that you can go in at any time and see what is happening there, what processes are running, etc. There should not be an army of evil admins who control every thing between you and the server. This is necessary for two reasons. First, by setting up your stand by yourself and being responsible for its condition, you better understand the problems that may arise. Secondly, you will have complete information about what is happening with your test site. This is very useful when analyzing data anomalies.
Full access also means that you are there alone. If you do load testing, you need to make sure that the server does not have your colleague employed by the same one, and also find out if the database is backing up. You need to be 100% sure that you are there alone.
Statistics removed
The easiest and most visual way to analyze load data is to visualize it. We use the Highcharts library for charting , which confidently supplanted jqPlot . Let's look at the examples.
Load schedule
I see a similar schedule every morning. It allows you to track the load. The load on the server is a value equal to the ratio of time in milliseconds spent in processing data for 1 server “tick” to 20 milliseconds. If on the graph the indicator is more than one (more than the norm), then everything is bad, if less - everything is good.
Memory usage graph
This is a general graph of memory usage. It allows you to roughly evaluate the work of the "garbage collector".
GC work schedule
This is probably one of the most important graphs for Java servers. It is unlikely that players will not notice a pause during a complete garbage collection. On it, on the Y axis, the duration of a particular phase of the garbage collector operation is marked.
The keys that we use to collect data on the work of the GC
-verbose: gc
-XX: + PrintGCTimeStamps
-XX: + PrintGCDetails
-XX: + PrintGCDateStamps
-XX: + PrintTenuringDistribution
-XX: + PrintGCApplicationStoppedTime
-XX: + PrintPromotionFailure
-XX: + PrintClassHistogramBeforeFullGC
-XX: + PrintClassHistogramAfterFullGC
-XX: + PrintGCApplicationConcurrentTime
-XX: + PrintGCTimeStamps
-XX: + PrintGCDetails
-XX: + PrintGCDateStamps
-XX: + PrintTenuringDistribution
-XX: + PrintGCApplicationStoppedTime
-XX: + PrintPromotionFailure
-XX: + PrintClassHistogramBeforeFullGC
-XX: + PrintClassHistogramAfterFullGC
-XX: + PrintGCApplicationConcurrentTime
Safepoint Stops Schedule
Safepoint is a point in the Java Virtual Machine, where a stop occurs each time you need to collect a stack trace or to collect garbage. Read more about safepoints here . This graph shows how many milliseconds in 1 minute the server spends at these points.
Schedule of date operations
But the beautiful "scarves", which were commissioned by Randll , whose report on the databases you could read earlier. These "scarves" allow us to evaluate which database-operations and in what quantity we are performing.
In addition, several dozens of statisticians are logged, who can tell about high-level indicators (the number of mobs in a single player battle), and low-level indicators (the number of transmitted packets). Most of these statisticians were instituted during investigations regarding the growth load.
For the same purpose, using the Yourkit API, we automatically removed the memory dump and load profile at the end of the test. Now they are analyzed only in manual mode, but it is planned to automate this process as well.
Cherry
At the end of the test, a so-called error analyzer is launched. We take all the mistakes - and they sometimes go up to 100 gigabytes for the night - and put them on the shelves. We compare which mistakes are repeated most often and which are rare, and we divide them into groups. We sort by type — an error, warning, or informational message — and find out if this is a content error. We transmit the content errors to the QA-specialists in content, and we ourselves investigate errors in the server code.
The report indicates how many times and at what time intervals the error was repeated. The number indirectly characterizes the difficulty of repeating this error, its cost for the server (do not forget that when collecting each callstack on the server, the kitten dies) and priority in the bug tracker.
The time of occurrence allows you to evaluate the distribution of errors on the test time. It's one thing if errors are spread evenly, and quite another if they begin and end in a certain time period.
In the future, we plan to develop this system so that we can associate errors with tasks in JIRA and find a revision in which the error was noticed for the first time.
Problems
Load night tests have very expensive iterations. The cost of each test is a day. Of course, we make every effort to pass the test every night, but in reality it passes less often and iterations become even more expensive. Any failure in any infrastructure node can disrupt the test.
Conclusion
Regular load testing with the use of various statistics is the best tool for healthy sleep of developers. Now I can’t imagine how it is possible to live without this kind of testing, because thanks to him every morning I see where we have
Other materials can be viewed on the Skyforge developers website and in our Vkontakte community .
Thank you for helping to create a report and writing an article for the entire Skyforge server team.
Source: https://habr.com/ru/post/193452/
All Articles