How will the “NoSQL” architect help and ... will it help?
Recently, more and more people are talking about “NoSQL” - a straight “fashionable” trend has been formed. “Technology” is beginning to actively use well-known reputable companies, including in high-load projects with large amounts of data - and someone admires, and someone pours himself with gasoline and a torch jumps from the 35th floor with a shout: " SQL ACID forever!"

Moreover, no matter what product they talk about, be it MongoDB or Cassandra , one often has to observe religious enthusiasm and awe, as if it were a matter of something new and sacred.
And the brain-breaking sketches of architectures flashing in the network, such as a circle of data centers operating in the “master of replication” on several continents, are especially thrilling:
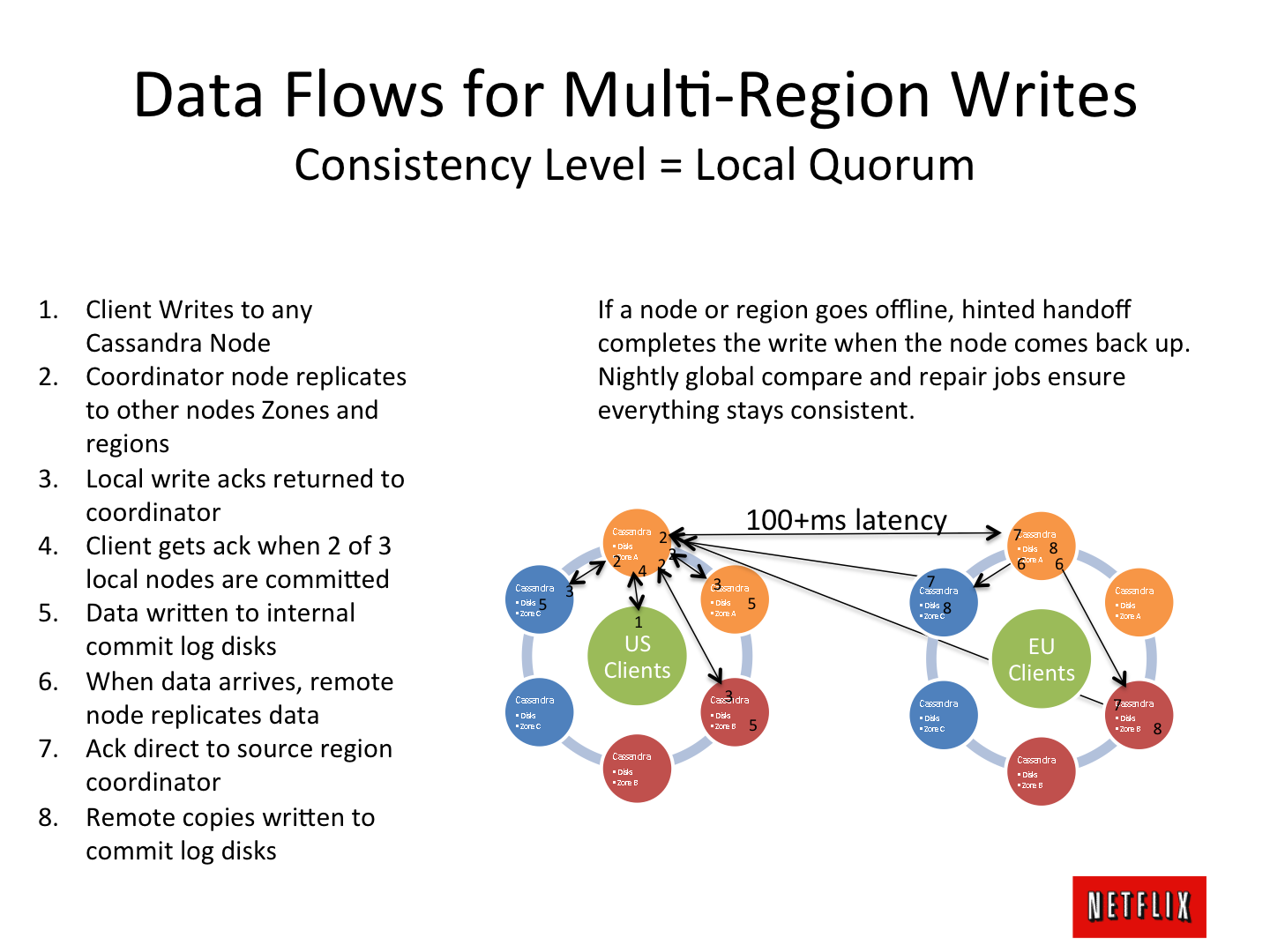
')
But ... when you begin to seriously use the "new" technology in combat projects, you understand where it all came from , what is the reason for these or other architectural solutions: data centers and other mysticism - a practical and simple, "muroch" understanding is formed - that you want to share with colleagues, so as not to make architectural mistakes and not floated on a raft across the ocean. About this, in principle, article.

Well, everything seems to be provided for - atomicity, consistency, transaction isolation, and secure commit. Try, build, exploit. ISO SQL registered transaction isolation levels - well, what else was not enough for complete happiness when you can determine everything?
What caused the appearance of the “CAP heresy” in the style to choose only 2 of the three? :-)

The answer is obvious - businesses need new, “supersonic” data storage capabilities:
From popular:
And e-business requires and requires:
It is clear that this stream of demands slowly but surely led to suicide ... but
... But if you ask programmers for a long time to do the impossible, they will!

So, not so much time passed as at the beginning of this century “NoSQL” products appeared and it became possible:
And, apparently, Amazon has made porridge with DynamoDB :
and then ideas began to be cloned as Facebook's Cassandra :
And of course, without Google, BigTable was not there.
What kind of silver bullet is this?
During the in-depth study of “NoSQL” products, and the last product with which I worked closely was Amazon DynamoDB (very similar to Apache Cassandra) - “hidden pitfalls and restrictions” began to appear, which can only be called “pay for permissiveness”:
And read, by default, outdatednon-consistent information :-) And as you like - the information is distributed with limited speed. Of course, you can check the box and read the information just recorded - but you have to wait, sir.
But again, you need to know that information takes time - so that it spreads across continents and the application should be able to handle it (we see the switch of responsibility, damn ... again to the programmer :-)).
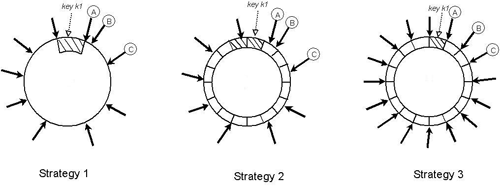
Cluster separation resistance is implemented using technologies similar to versioning - but from time to time it will be necessary to launch a search for mismatches of the “Anti-entropy using Merkle trees” type.
You can, but you still have to configure the rest of the nodes, sometimes with a crowbar and a soldering iron.
And then - more interesting.
In our projects, we use DynamoDB - the advanced “NoSQL” solution from Amazon. Let's look at it in more detail below.
Number, string, binary data. Forget about DATETIME (they can be emulated by timestamp, but sometimes it becomes uncomfortable).
Indices need to be specified immediately; there should be no more than them - 5 per table. And add them to the existing table - you can not, you need to delete it, recreate and reload the data there. Peaceful sleep architect - provided.
You can store any amount of data, but ... the size of one "table row" with the names and values of the "columns" should not exceed 64KB. True, the number of "columns" is not limited.
And on one cluster node (with a single value of the main hash key index), if there are additional indexes, you cannot store more than 10GB, so that.
Apparently nothing wrote "columns." In NoSQL, the notions of a data schema are often just not there, so there can be different “columns” or “attributes” in each “row of the table”.
You can select data only for one index (there is also a main (hash key) index, but you cannot make range selections on it - only constant ones). Sort by only one index.
Forget about the complex “WHERE, GROUP BY”, not to mention the subqueries - “NoSQL” engines simply emulate them and can execute very slowly.
You can perform more complex selections - but by using a full table scan (the notorious table scan) and then elementwise filtering the results on the server side, which is long and expensive.
Transactions ... sometimes they are needed :-), and only an atomic update of individual entities is guaranteed (there are really nice buns with readings-increments in one operation). So transactions will have to be emulated - otherwise you would like if the data is “smeared” across 20 servers / data centers of the entire terrestrial ball?
Often in “NoSQL”, incl. DynamoDB is starting to sneer at the founders of relational theory and create horror-like strings in lines:
user = john blog_post_ $ ts1 = 12 blog_post_ $ ts2 = 33 blog_post_ $ ts3 = 69 ...
where $ ts1-3 is the timestamp of the user's posts to the blog.
Yes, it is convenient to get a list of publications for one request. But the work of the programmer is increasing.
1) Before choosing a repository for the “NoSQL” project, recall the reasons for the appearance of aFrankenstein of this class of products, which is often nothing but a set of “memcached” similar servers with fairly simple logic built on and, accordingly, saving data and simple sampling will be Indeed, flying, but something more complicated ... will have to be shamanized on the application side.
2) Once again, reread Brewer's theorem and find the dirty tricks :-)
3) Carefully review the documentation for the product used - especially restrictions. Most likely you will meet many surprises - and you will need to carefully prepare for them.
4) And finally look at Codd’s eyes.

Yes, you get a very reliable, high-availability, flexible solution that supports flexible replication schemes - but you have to pay, alas, with the most severe denormalization and complexity of the application's logic (including emulating transactions, juggling with heavy data inside the application, etc.). The choice is yours!
Good luck to all!
Moreover, no matter what product they talk about, be it MongoDB or Cassandra , one often has to observe religious enthusiasm and awe, as if it were a matter of something new and sacred.
And the brain-breaking sketches of architectures flashing in the network, such as a circle of data centers operating in the “master of replication” on several continents, are especially thrilling:
')
But ... when you begin to seriously use the "new" technology in combat projects, you understand where it all came from , what is the reason for these or other architectural solutions: data centers and other mysticism - a practical and simple, "muroch" understanding is formed - that you want to share with colleagues, so as not to make architectural mistakes and not floated on a raft across the ocean. About this, in principle, article.
What is not satisfied with the good old ACID ?
Well, everything seems to be provided for - atomicity, consistency, transaction isolation, and secure commit. Try, build, exploit. ISO SQL registered transaction isolation levels - well, what else was not enough for complete happiness when you can determine everything?
What caused the appearance of the “CAP heresy” in the style to choose only 2 of the three? :-)
- data consistency
- availability
- resistance to separation
The answer is obvious - businesses need new, “supersonic” data storage capabilities:
- the base must always be available for writing and reading and server-type cases restart, the network has dropped - it hurts to hit
- intensive growth of data volumes and stricter requirements for their accessibility, incl. due to the rapid development of the global network - in one database, well, they just stopped to fit
- There are a lot of customers in different parts of the world and you need to save orders as quickly as possible, etc.
- the rapid growth of web services, the emergence of mobile devices
What is not satisfied with the "classic" cluster database?
From popular:
- Oracle RAC - apparently expensive and difficult, heavy, and how to scatter it across different continents?
- MySQL cluster is a quick wizard, but there are a lot of pitfalls and limitations, such as storing data only in memory, but it still works well for some cases.
- galera cluster for mysql - yes, honest master, write where you want (but should know where exactly), but there is no “separation resistance”, it can hang in the absence of a quorum or go insane, it creaks when it falls and drops when geo-distributed use because synchronously transmits data to all copies; yes and no sharding data between masters
And e-business requires and requires:
- the base must always be available, you can not lose a customer’s order or his cart; even if synchronization between database nodes is missing
- the base should be accessible everywhere (Europe and the USA), and, of course, synchronize data between copies
- the base should scale indefinitely with increasing data
- the base must scale to the load: write, read
It is clear that this stream of demands slowly but surely led to suicide ... but
The answer of programmers is possible!
... But if you ask programmers for a long time to do the impossible, they will!
Not everyone knows that C is enough for full-fledged programming, and for people with a sense of beauty, you can pour out your soul and in C ++ - not so, under pressure from business: “How can you program faster and everyone can?” - the technologies that are powerful the hardware now even works: C #, java, python, ruby ...
So, not so much time passed as at the beginning of this century “NoSQL” products appeared and it became possible:
- write to any cluster member, always!
- place cluster elements on different continents and read from local ones!
- cut down any node of the cluster and the system will not go crazy!
- add cluster nodes when the soul desires, and this will allow to scale both the recording and the reading!
And, apparently, Amazon has made porridge with DynamoDB :
DynamoDB is a result of 15 years of education.
and then ideas began to be cloned as Facebook's Cassandra :
It was the Avakash Lakshman and Prashant Malik. It was released on Google code in July 2008.
And of course, without Google, BigTable was not there.
What kind of silver bullet is this?
And sew seven hats? And seven I shall sew ...
During the in-depth study of “NoSQL” products, and the last product with which I worked closely was Amazon DynamoDB (very similar to Apache Cassandra) - “hidden pitfalls and restrictions” began to appear, which can only be called “pay for permissiveness”:
You can write to any node of the cluster, and read ...
And read, by default, outdated
You can place cluster nodes on different continents, but ...
But again, you need to know that information takes time - so that it spreads across continents and the application should be able to handle it (we see the switch of responsibility, damn ... again to the programmer :-)).
You can turn off any node in the cluster, chop network cables with an ax, but ...
Cluster separation resistance is implemented using technologies similar to versioning - but from time to time it will be necessary to launch a search for mismatches of the “Anti-entropy using Merkle trees” type.
Add cluster nodes when the soul desires
You can, but you still have to configure the rest of the nodes, sometimes with a crowbar and a soldering iron.
And then - more interesting.
Amazon DynamoDB Limitations
In our projects, we use DynamoDB - the advanced “NoSQL” solution from Amazon. Let's look at it in more detail below.
Data types - frankly little
Number, string, binary data. Forget about DATETIME (they can be emulated by timestamp, but sometimes it becomes uncomfortable).
Indices can be added only ... immediately
Indices need to be specified immediately; there should be no more than them - 5 per table. And add them to the existing table - you can not, you need to delete it, recreate and reload the data there. Peaceful sleep architect - provided.
Data size
You can store any amount of data, but ... the size of one "table row" with the names and values of the "columns" should not exceed 64KB. True, the number of "columns" is not limited.
And on one cluster node (with a single value of the main hash key index), if there are additional indexes, you cannot store more than 10GB, so that.
Apparently nothing wrote "columns." In NoSQL, the notions of a data schema are often just not there, so there can be different “columns” or “attributes” in each “row of the table”.
Requests ...
You can select data only for one index (there is also a main (hash key) index, but you cannot make range selections on it - only constant ones). Sort by only one index.
Forget about the complex “WHERE, GROUP BY”, not to mention the subqueries - “NoSQL” engines simply emulate them and can execute very slowly.
You can perform more complex selections - but by using a full table scan (the notorious table scan) and then elementwise filtering the results on the server side, which is long and expensive.
Transactions - and what is it?
Transactions ... sometimes they are needed :-), and only an atomic update of individual entities is guaranteed (there are really nice buns with readings-increments in one operation). So transactions will have to be emulated - otherwise you would like if the data is “smeared” across 20 servers / data centers of the entire terrestrial ball?
Attributes with dances
Often in “NoSQL”, incl. DynamoDB is starting to sneer at the founders of relational theory and create horror-like strings in lines:
user = john blog_post_ $ ts1 = 12 blog_post_ $ ts2 = 33 blog_post_ $ ts3 = 69 ...
where $ ts1-3 is the timestamp of the user's posts to the blog.
Yes, it is convenient to get a list of publications for one request. But the work of the programmer is increasing.
findings
1) Before choosing a repository for the “NoSQL” project, recall the reasons for the appearance of a
2) Once again, reread Brewer's theorem and find the dirty tricks :-)
3) Carefully review the documentation for the product used - especially restrictions. Most likely you will meet many surprises - and you will need to carefully prepare for them.
4) And finally look at Codd’s eyes.
Yes, you get a very reliable, high-availability, flexible solution that supports flexible replication schemes - but you have to pay, alas, with the most severe denormalization and complexity of the application's logic (including emulating transactions, juggling with heavy data inside the application, etc.). The choice is yours!
Good luck to all!
Source: https://habr.com/ru/post/193360/
All Articles