What's new in SQLite (2013)?
In the last SQLite update, the query planner has undergone major changes and is now called the Next Generation Query Scheduler . We decided to make a small review of the new scheduler and some other significant SQLite updates in the current year. New features may be useful to developers.
The scheduler builds a query execution plan to get the data as quickly as possible. In SQLite version 3.8.0, the scheduler was radically redesigned to work faster and better.
')
If a query is made on a single table, it is easy to optimize it. If a query joins many tables, there are one thousand and one possible variants of its execution. The scheduler must, based on incomplete information, decide which of these options will work most effectively.
Queries connecting several tables are executed by SQLite using nested loops, one for each of the tables (plus additional loops, if the condition contains OR or IN). A loop can use one or more indexes or do a full crawl of the table. Thus, planning consists of two tasks:
1) select the order of nesting cycles;
2) select the index for each cycle;
The first task is much more difficult than the second. After choosing the order of bypassing the tables, the selection of indexes is usually trivial.
The SQLite query scheduler is “stable,” that is, it chooses the same plan, provided that:
1) the database schema has not changed in terms of indices;
2) has not been exceeded ANALYZE;
3) SQLITE_ENABLE_STAT3 option is not set;
4) SQLite version has not changed.
This means that if testing works "well" for testing, they will also "work well" in the combat system on the same version of SQLite. “Large” databases, as a rule, do not provide such guarantees since all the time they update index statistics.
SQLite versions prior to 3.8.0 did not work well with complex queries. An example of such a "difficult case": "TPC-H Q8" from the Transaction Processing Performance Council . This query connects 8 tables:
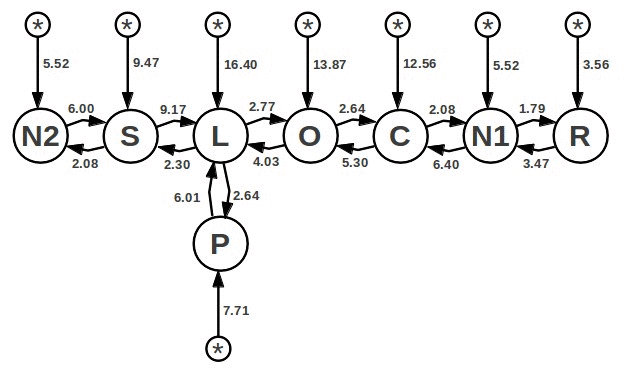
In this diagram, a circle means a table from the FROM query. On the arc connecting the circles, an approximate “cost” of execution of each cycle is written, on the assumption that the cycle from which the arc originates is external to this one. For example, if you put the cycle S in the cycle L, then the cost will be 2.30. And if you put the cycle L in S, then the cost will be 9.17.
“Costs” are logarithmic and, when nesting cycles, their values are multiplied rather than added. The advantage of 6.87 from the attachment of the cycle S to L means that the query is executed 963 times faster if S is nested in L than if L is nested in S.
Circles with asterisks mean the price of a run of the cycle without dependencies. Thus, the graph is bidirectional and the solution to the scheduling problem is to find a route with a minimum cost that goes around each vertex once.
This description of the task is a simplification, since in reality the cost estimates are always approximate and are represented not by one figure, but by several “weights” of different behaviors. For example, the "starting" weight, which laid the time to build an automatic index. Not all requests are representable in the form of a similar graph. If the query includes ORDER BY, then it will be useful to use an index to avoid additional sorting. And so on. But to consider the case of the TPC-H Q8, all these difficulties will be excluded to understand the point.
Prior to version 3.8.0, SQLite used the heuristic “Nearest Neighbor”, “BS”. In this case, a single bypass of the graph along the lowest cost arc is made. Oddly enough, it works well in many cases. And it works fast. But, alas, for the “TPC-H Q8” this method selects the R-N1-N2-SCOLP route cost 36.92. This record means that R is an external loop, N1 is embedded in it, etc. In reality, the best route here is PLOC-N1-RS-N2. Its cost is 27.38, the difference seems to be insignificant, but one should not forget that these are logarithmic values. So optimal performance is 750 times faster. The solution may be a complete enumeration of all routes, but the running time of such sorting is proportional to the factorial of the number of cycles.
The new Planner uses the new heuristics to find the route in the column: “N Nearest Neighbors”. The algorithm leads N paths instead of choosing a single neighbor with minimal cost. Suppose that N = 4. Then on the TPC-H Q8 graph, the following best routes are selected:
R (cost: 3.56)
N1 (cost: 5.52)
N2 (cost: 5.52)
P (cost: 7.71)
Next, for each route, select the next step with a minimum cost:
R-N1 (cost: 7.03)
R-N2 (cost: 9.08)
N2-N1 (cost: 11.04)
RP (cost: 11.27)
The third step:
R-N1-N2 (cost: 12.55)
R-N1-C (cost: 13.43)
R-N1-P (cost: 14.74)
R-N2-S (cost: 15.08)
Etc. In total, there are 8 steps in the number of tables. In the general case for K cycles, the computational time is O (K * N), which is far from O (2 ^ K).
But what value of N should be used? Maybe N = K?
In reality, “N Closest Neighbors” finds the optimal execution variant of TPC-H Q8 with N = 10. And now the following constants are embedded in SQLite: N = 1 for simple queries, N = 5 for queries of two cycles, and N = 10 for all requests in which more than two cycles. Perhaps these constants will change in the future.
When switching to SQLite 3.8.0, some queries may start to work slowly.
Run ANALYZE!
The new scheduler is strongly tied to statistics, which is collected by indices.
Partial indexes allow you to specify a condition to exclude some records from the index. "Classic" method of use:
Only entries that have a non-empty parent_po will be included in the po_parent index . If there are many records in the table with empty parent_po , then a significant saving of resources is achieved, since the index does not contain these records at all.
More cunning way to use. Suppose people are divided into teams. Each team has a leader in the team. For example:
How to ensure that the team will have no more than one leader? Of course, you cannot simply make a unique index by (team_id, is_team_leader) . Since it will not allow the inclusion of several "non-leaders" in the team. The solution is to create a partial index:
This index will help you quickly find the team leader:
And at the same time will not allow to add a second leader to the team.
SQLite works in a “virtual environment”. It uses a special table of calls, which hides the "external world" of the operating system with its reading files, locks, etc. Before version 3.7.17, reading and writing data used calls xRead () and xWrite () environment. These calls are usually translated into API "read from file" and "write to file" of the operating system. From version 3.7.17, SQLite can use memory mapped I / O (new calls: xFetch () and xUnfetch ()) instead of the usual I / O.
During normal data reading, SQLte allocates a buffer and asks the system to read data into it page by page. This always copies the data in memory. When using in-memory mapping, SQLite gets a memory location pointer. If the file has already been uploaded before, then copying does not take place and this leads to an increase in performance (up to146,200 %). It also achieves memory savings by sharing it between the system and SQLite.
However, there are disadvantages. Buffer overflow errors immediately spoil the database, since the memory will be synchronized with the disk instantly by the system. However, this is not the saddest thing. The bad news is that the input / output error is not caught by SQLite using the new scheme. Instead, the application receives a signal for termination (the behavior on Windows systems is unknown to me - maybe someone will write in the comments).
Also on certain work patterns, performance degradation is also possible.
To enable memory mapped I / O, use the command:
The value specifies the maximum size of the memory buffer per database. Disable:
That's all the news. We hope the review will be useful. Here you can see a detailed release history for SQLite.
Ps. Use a modern manager to administer the SQLite database.
Next Generation Query Scheduler (NGQP, from version 3.8.0)
The scheduler builds a query execution plan to get the data as quickly as possible. In SQLite version 3.8.0, the scheduler was radically redesigned to work faster and better.
')
If a query is made on a single table, it is easy to optimize it. If a query joins many tables, there are one thousand and one possible variants of its execution. The scheduler must, based on incomplete information, decide which of these options will work most effectively.
Queries connecting several tables are executed by SQLite using nested loops, one for each of the tables (plus additional loops, if the condition contains OR or IN). A loop can use one or more indexes or do a full crawl of the table. Thus, planning consists of two tasks:
1) select the order of nesting cycles;
2) select the index for each cycle;
The first task is much more difficult than the second. After choosing the order of bypassing the tables, the selection of indexes is usually trivial.
The SQLite query scheduler is “stable,” that is, it chooses the same plan, provided that:
1) the database schema has not changed in terms of indices;
2) has not been exceeded ANALYZE;
3) SQLITE_ENABLE_STAT3 option is not set;
4) SQLite version has not changed.
This means that if testing works "well" for testing, they will also "work well" in the combat system on the same version of SQLite. “Large” databases, as a rule, do not provide such guarantees since all the time they update index statistics.
SQLite versions prior to 3.8.0 did not work well with complex queries. An example of such a "difficult case": "TPC-H Q8" from the Transaction Processing Performance Council . This query connects 8 tables:
In this diagram, a circle means a table from the FROM query. On the arc connecting the circles, an approximate “cost” of execution of each cycle is written, on the assumption that the cycle from which the arc originates is external to this one. For example, if you put the cycle S in the cycle L, then the cost will be 2.30. And if you put the cycle L in S, then the cost will be 9.17.
“Costs” are logarithmic and, when nesting cycles, their values are multiplied rather than added. The advantage of 6.87 from the attachment of the cycle S to L means that the query is executed 963 times faster if S is nested in L than if L is nested in S.
Circles with asterisks mean the price of a run of the cycle without dependencies. Thus, the graph is bidirectional and the solution to the scheduling problem is to find a route with a minimum cost that goes around each vertex once.
This description of the task is a simplification, since in reality the cost estimates are always approximate and are represented not by one figure, but by several “weights” of different behaviors. For example, the "starting" weight, which laid the time to build an automatic index. Not all requests are representable in the form of a similar graph. If the query includes ORDER BY, then it will be useful to use an index to avoid additional sorting. And so on. But to consider the case of the TPC-H Q8, all these difficulties will be excluded to understand the point.
Prior to version 3.8.0, SQLite used the heuristic “Nearest Neighbor”, “BS”. In this case, a single bypass of the graph along the lowest cost arc is made. Oddly enough, it works well in many cases. And it works fast. But, alas, for the “TPC-H Q8” this method selects the R-N1-N2-SCOLP route cost 36.92. This record means that R is an external loop, N1 is embedded in it, etc. In reality, the best route here is PLOC-N1-RS-N2. Its cost is 27.38, the difference seems to be insignificant, but one should not forget that these are logarithmic values. So optimal performance is 750 times faster. The solution may be a complete enumeration of all routes, but the running time of such sorting is proportional to the factorial of the number of cycles.
The new Planner uses the new heuristics to find the route in the column: “N Nearest Neighbors”. The algorithm leads N paths instead of choosing a single neighbor with minimal cost. Suppose that N = 4. Then on the TPC-H Q8 graph, the following best routes are selected:
R (cost: 3.56)
N1 (cost: 5.52)
N2 (cost: 5.52)
P (cost: 7.71)
Next, for each route, select the next step with a minimum cost:
R-N1 (cost: 7.03)
R-N2 (cost: 9.08)
N2-N1 (cost: 11.04)
RP (cost: 11.27)
The third step:
R-N1-N2 (cost: 12.55)
R-N1-C (cost: 13.43)
R-N1-P (cost: 14.74)
R-N2-S (cost: 15.08)
Etc. In total, there are 8 steps in the number of tables. In the general case for K cycles, the computational time is O (K * N), which is far from O (2 ^ K).
But what value of N should be used? Maybe N = K?
In reality, “N Closest Neighbors” finds the optimal execution variant of TPC-H Q8 with N = 10. And now the following constants are embedded in SQLite: N = 1 for simple queries, N = 5 for queries of two cycles, and N = 10 for all requests in which more than two cycles. Perhaps these constants will change in the future.
When switching to SQLite 3.8.0, some queries may start to work slowly.
Run ANALYZE!
The new scheduler is strongly tied to statistics, which is collected by indices.
Partial indexes (partial indexes, from version 3.8.0)
Partial indexes allow you to specify a condition to exclude some records from the index. "Classic" method of use:
CREATE INDEX po_parent ON purchaseorder(parent_po) WHERE parent_po IS NOT NULL; Only entries that have a non-empty parent_po will be included in the po_parent index . If there are many records in the table with empty parent_po , then a significant saving of resources is achieved, since the index does not contain these records at all.
More cunning way to use. Suppose people are divided into teams. Each team has a leader in the team. For example:
CREATE TABLE person( person_id INTEGER PRIMARY KEY, team_id INTEGER REFERENCES team, is_team_leader BOOLEAN, -- ); How to ensure that the team will have no more than one leader? Of course, you cannot simply make a unique index by (team_id, is_team_leader) . Since it will not allow the inclusion of several "non-leaders" in the team. The solution is to create a partial index:
CREATE UNIQUE INDEX team_leader ON person(team_id) WHERE is_team_leader; This index will help you quickly find the team leader:
SELECT person_id FROM person WHERE is_team_leader AND team_id=?1; And at the same time will not allow to add a second leader to the team.
Input / output using memory mapping (memory-mapped I / O, from version 3.7.17)
SQLite works in a “virtual environment”. It uses a special table of calls, which hides the "external world" of the operating system with its reading files, locks, etc. Before version 3.7.17, reading and writing data used calls xRead () and xWrite () environment. These calls are usually translated into API "read from file" and "write to file" of the operating system. From version 3.7.17, SQLite can use memory mapped I / O (new calls: xFetch () and xUnfetch ()) instead of the usual I / O.
During normal data reading, SQLte allocates a buffer and asks the system to read data into it page by page. This always copies the data in memory. When using in-memory mapping, SQLite gets a memory location pointer. If the file has already been uploaded before, then copying does not take place and this leads to an increase in performance (up to
However, there are disadvantages. Buffer overflow errors immediately spoil the database, since the memory will be synchronized with the disk instantly by the system. However, this is not the saddest thing. The bad news is that the input / output error is not caught by SQLite using the new scheme. Instead, the application receives a signal for termination (the behavior on Windows systems is unknown to me - maybe someone will write in the comments).
Also on certain work patterns, performance degradation is also possible.
To enable memory mapped I / O, use the command:
PRAGMA mmap_size=268435456; The value specifies the maximum size of the memory buffer per database. Disable:
PRAGMA mmap_size=0; That's all the news. We hope the review will be useful. Here you can see a detailed release history for SQLite.
Ps. Use a modern manager to administer the SQLite database.
Source: https://habr.com/ru/post/193238/
All Articles