PACS server do it yourself
Not so long ago, our company finished work on the implementation of a PACS server ( Picture Archiving and Communication System ) in one of our medical diagnostic centers. Prior to that, there was an open source PACS server - dcm4chee , which did not shine with high speed, since it was written in Java. In addition, one of the customer's requirements was to have access to the internal structure of the server. Therefore, it was decided to write your own. In addition, the company had experience of similar developments in both client and server parts of PACS systems, so a compromise solution was to create its own PACS archive that satisfies customer requirements. Most of the implementation of the server core I had to deal with and during that time I had gained specific experience in this area, which I want to share with the Habra community. But first things first.
For a common understanding, consider the role of the PACS system in the diagnostic center. Any diagnostic center has diagnostic equipment: MRI, CT scanners, ultrasound stations or ECG devices (any of these devices in terms of the DICOM protocol is called Modality) and diagnostic software (our doctors used OsiriX ). Having received images on the tomograph, it is necessary to send them to the diagnostic station. Obviously, this requires a kind of integrating link that collects images from tomographs, ultrasound stations, ECG devices, and is able to search for and transmit images over the network. This link is the PACS server:
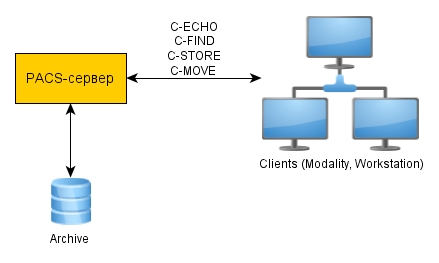
It is obvious that a single protocol is needed for the interaction of different-quality medical equipment. And just such a protocol is DICOM ( Digital Imaging and Communications in Medicine ), which over the past 20 years has been seriously improved, making it easy to integrate medical equipment into a common information system. Almost all manufacturers of medical equipment follow this protocol. Therefore, DICOM protocol support was a natural requirement for a PACS server. It was decided to implement a multi-threaded high-loaded PACS that can work in a cluster. The server was developed in C ++ and the most adequate library to work with the DICOM protocol, written in C ++ - DCMTK, was used today . Thanks to this library, it became possible to quickly implement high-load PACS-systems.
The database in the PACS system allows you to store information about the saved images and search for them. Images also need to be able to transmit over the network, and with it, meta-information about the image (who is in the picture, at what clinic they were made, who did the research, etc.). For these purposes, the DICOM protocol provides a special 4-level data model, which can be briefly found here . A complete list of various file attributes can be found on the official protocol site [1]. In the images obtained from different devices, the list of these attributes will be different, which is completely normal. However, some attributes remain mandatory to support universal image search. There are few of them - only ten of them, among them Patient Name, Patient ID, Patient Birthday, Modality Type (CT, MRI, ultrasound, etc.), Study Date (study date), etc. In addition to the required parameters, there are optional, quite a lot of them and support they are in the database as practice shows - is superfluous.
The presence of a large number of optional parameters in image meta-information is one of the drawbacks of the DICOM protocol. Some devices expose some parameters, some - others. Therefore, maintaining them in the database for search is meaningless. As a result, having worked several options, we stopped at this version of the database:
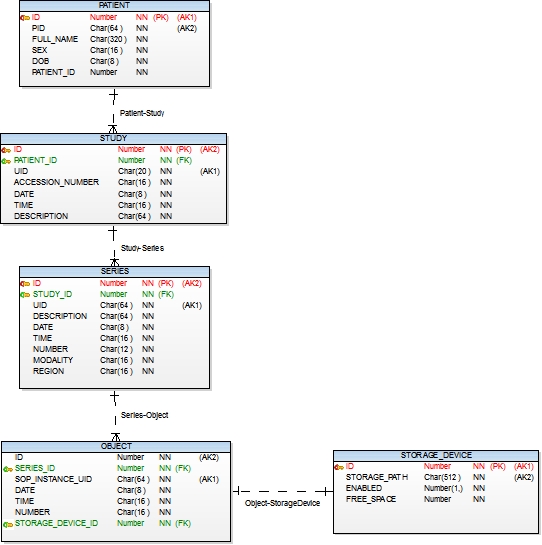
As you can see, the database schema corresponds to the multi-level structure of DICOM files. One patient can have many stages (read studies). The study is a series of series defined by the study protocol. The series stores many images.
')
Consider briefly the main functions (services) of a standard PACS system, almost all of which I have already mentioned. Since any interaction of workstations with the PACS system is client-server, all operations are also implemented in two versions - client and server. In DCMTK there are implementations of both options. PACS implements the server side.
The prefix 'C-' for operations means Composite, which implies that the operation is holistic and self-sufficient and is performed without being tied to other operations. There are also operations with the prefix 'N -' (N-CREATE, N-SET, N-GET, etc.), which are performed as part of some more general operation (set statuses, inform about the start of the study, etc.). These operations are not related to the topic of this article.
C-ECHO is a command to find out whether a client is available on the network. Similar to the ping command in Windows. In the implementation, the command is very simple - you just need to send a response with the status STATUS_Success:
where assoc is the connection established by the client, request is the incoming request.
C-STORE is a command that allows you to save images on a PACS server in DCM format.
Here is a piece of code that does this:
Kolleback storeSCPCallback works on each package, not on each file. The completion of the file download is indicated by the condition
I would also like to say that the OBJECT table is filled very intensively. One study on an MRI tomograph lasts an average of 20 minutes, during which time the tomograph produces 100-300 images, a CT scanner 500-700 images. Total images per day can reach 1440/20 * 500 = 36000 images per day. In our diagnostic center, there are practically no breaks in the work of tomographs day or night. Therefore, the OBJECT table should store the minimum possible amount of data.
C-MOVE is a command that allows you to transfer images from a PACS to a work station or a diagnostic station. The command is transmitted by the calling station (source) to the PACS and it indicates which station (destination) the images should be uploaded to. In the particular case, if source = destination, then just download files.
The C-MOVE team is more versatile than the C-GET team, which only allows downloading images. C-MOVE can download images not only for its own, but also for any other. The command indicates the AETitle station to which you want to upload images. AETitle is the name of the client, usually in capital letters (for example, CLIENT_SCU). It is installed when you start dicom-listener (server).
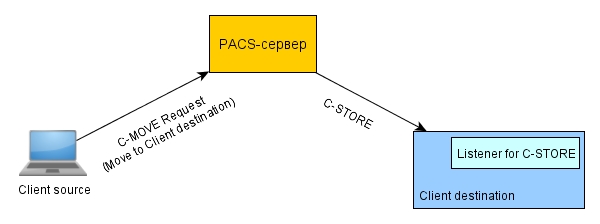
That is, the client initiating the C-MOVE command to the PACS server must run a mini-PACS in itself that allows only the C-STORE command to be received. And the PACS server, in turn, with the C-MOVE team, should establish a new connection with the client, pick up images from the storage and, for each of the bottom, execute the client version of the C-STORE command back to the client. By the way, only the C-MOVE command allows you to transfer both compressed images (JPEG) and uncompressed due to the establishment of a new connection.
The C-GET team, however, is able to load images without establishing a new connection and, therefore, without having to raise the server on the client side. In this case, the PACS also performs the client version of the C-STORE command, only through the connection established by the C-GET command.
C-FIND is a command that allows you to search for images at different levels. That is, in fact, there are four types of C-FIND command: C-FIND at the PATIENT level, at the STUDY level, at the SERIES level and at the IMAGE level.
That is, in the callback, you need to fill in the response objects — the response parameters and responseDataSet — the patient information / stage / series / image you want to find. The DIMSE_findProvider () function from DCMTK will take care of sending them back to the client.
The C-FIND command is dangerous in that the client can specify a very general search criteria and the client will have to give a large amount of information. For example, you can request all stages for the last year. If you try to first load all the data on the server, the server is likely to hang. Therefore, it is impossible to make large requests, you need to load data as the callbacks are triggered. To do this, you need to implement a query to the database as an iterator and, as the callbacks are triggered, call next () and thus take the next object. In addition, the search can be canceled only when a callback arrives, so if the search on PACS hangs for a while on a sample of the database, and the client causes the request to be canceled, then no response will occur on the client. This is relevant for searching at the level of patients and stages. This is irrelevant for searching at the series level, since we have not encountered any stages containing more than 15 series. Similarly, for searching at the level of images - a series with more than 1000 images, we have not seen in practice.
So, we reviewed the main functions of the PACS system and its role in the overall structure of the diagnostic center. Practical aspects and various aspects of the implementation of medical industrial PACS systems are also covered. However, as a rule, PACS systems are not limited to this functionality. There is also a WADO (Web Access to DICOM Objects) service and a work task management service (Modality worklist), also included in the functions of PACS systems. I hope for someone the article will be useful and save a lot of time.
1. List of all DICOM tags (http://medical.nema.org/Dicom/2011/11_06pu.pdf, p. 8).
2. The official page of the DICOM protocol - medical.nema.org/standard.html
3. About PACS systems in Russian - ru.wikipedia.org/wiki/PACS
4. About DICOM in Russian - en.wikipedia.org/wiki/DICOM
Preamble
For a common understanding, consider the role of the PACS system in the diagnostic center. Any diagnostic center has diagnostic equipment: MRI, CT scanners, ultrasound stations or ECG devices (any of these devices in terms of the DICOM protocol is called Modality) and diagnostic software (our doctors used OsiriX ). Having received images on the tomograph, it is necessary to send them to the diagnostic station. Obviously, this requires a kind of integrating link that collects images from tomographs, ultrasound stations, ECG devices, and is able to search for and transmit images over the network. This link is the PACS server:
It is obvious that a single protocol is needed for the interaction of different-quality medical equipment. And just such a protocol is DICOM ( Digital Imaging and Communications in Medicine ), which over the past 20 years has been seriously improved, making it easy to integrate medical equipment into a common information system. Almost all manufacturers of medical equipment follow this protocol. Therefore, DICOM protocol support was a natural requirement for a PACS server. It was decided to implement a multi-threaded high-loaded PACS that can work in a cluster. The server was developed in C ++ and the most adequate library to work with the DICOM protocol, written in C ++ - DCMTK, was used today . Thanks to this library, it became possible to quickly implement high-load PACS-systems.
Design database
The database in the PACS system allows you to store information about the saved images and search for them. Images also need to be able to transmit over the network, and with it, meta-information about the image (who is in the picture, at what clinic they were made, who did the research, etc.). For these purposes, the DICOM protocol provides a special 4-level data model, which can be briefly found here . A complete list of various file attributes can be found on the official protocol site [1]. In the images obtained from different devices, the list of these attributes will be different, which is completely normal. However, some attributes remain mandatory to support universal image search. There are few of them - only ten of them, among them Patient Name, Patient ID, Patient Birthday, Modality Type (CT, MRI, ultrasound, etc.), Study Date (study date), etc. In addition to the required parameters, there are optional, quite a lot of them and support they are in the database as practice shows - is superfluous.
The presence of a large number of optional parameters in image meta-information is one of the drawbacks of the DICOM protocol. Some devices expose some parameters, some - others. Therefore, maintaining them in the database for search is meaningless. As a result, having worked several options, we stopped at this version of the database:
As you can see, the database schema corresponds to the multi-level structure of DICOM files. One patient can have many stages (read studies). The study is a series of series defined by the study protocol. The series stores many images.
')
The main functions of the PACS system
Consider briefly the main functions (services) of a standard PACS system, almost all of which I have already mentioned. Since any interaction of workstations with the PACS system is client-server, all operations are also implemented in two versions - client and server. In DCMTK there are implementations of both options. PACS implements the server side.
The prefix 'C-' for operations means Composite, which implies that the operation is holistic and self-sufficient and is performed without being tied to other operations. There are also operations with the prefix 'N -' (N-CREATE, N-SET, N-GET, etc.), which are performed as part of some more general operation (set statuses, inform about the start of the study, etc.). These operations are not related to the topic of this article.
C-ECHO is a command to find out whether a client is available on the network. Similar to the ping command in Windows. In the implementation, the command is very simple - you just need to send a response with the status STATUS_Success:
DIMSE_sendEchoResponse(assoc, presID, request, STATUS_Success, NULL) where assoc is the connection established by the client, request is the incoming request.
C-STORE is a command that allows you to save images on a PACS server in DCM format.
Here is a piece of code that does this:
OFCondition storeSCP() { T_DIMSE_C_StoreRQ* req = &m_msg->msg.CStoreRQ; DcmDataset* dset = 0x0; OFCondition cond = DIMSE_storeProvider(m_assoc, m_presID, req, NULL, OFTrue, &dset,storeSCPCallback, 0x0, DIMSE_BLOCKING, 0); if (cond.bad()) Log::error("C-STORE provider failed. Text: %s", cond.text()); return cond; } void storeSCPCallback( void* /*callbackData*/, T_DIMSE_StoreProgress *progress, T_DIMSE_C_StoreRQ* /*request*/, char * /*imageFileName*/, DcmDataset **imageDataSet, T_DIMSE_C_StoreRSP* response, DcmDataset **statusDetail) { if (progress->state == DIMSE_StoreEnd) { if ((imageDataSet != NULL) && (*imageDataSet != NULL)) { DcmFileFormat dcmff(*imageDataSet); // some error if (!commandStore(&dcmff)) response->DimseStatus = STATUS_STORE_Refused_OutOfResources; delete *imageDataSet; *imageDataSet = 0x0; } } delete *statusDetail; *statusDetail = 0x0; } bool ServerCoreImpl::commandStore(DcmFileFormat* file) { // // 1. , () PATIENT, STUDY, SERIES, OBJECT. // 2. , // 3. , ( // ) // true, , false } Kolleback storeSCPCallback works on each package, not on each file. The completion of the file download is indicated by the condition
progress->state == DIMSE_StoreEnd , then we can save the file. The only difficulty with the implementation of this command is the choice of the directory structure when saving the file. In order not to store the path to the file in the OBJECTS table, we calculate it from the rest of the data. We settled on the following directory structure: PATH_K_DOOR / STUDY.DATE (YEAR) /STUDY.DATE (MONTH) /STUDY.DATE (DAY) /STUDY.TIME (HOUR) /PATIENT.PID (first letter) / PATIENT.PID/STUDY .UID / {images}. This hierarchical structure allows you to minimize the number of nested folders, which allows you to work with this directory structure without time lags.I would also like to say that the OBJECT table is filled very intensively. One study on an MRI tomograph lasts an average of 20 minutes, during which time the tomograph produces 100-300 images, a CT scanner 500-700 images. Total images per day can reach 1440/20 * 500 = 36000 images per day. In our diagnostic center, there are practically no breaks in the work of tomographs day or night. Therefore, the OBJECT table should store the minimum possible amount of data.
C-MOVE is a command that allows you to transfer images from a PACS to a work station or a diagnostic station. The command is transmitted by the calling station (source) to the PACS and it indicates which station (destination) the images should be uploaded to. In the particular case, if source = destination, then just download files.
The C-MOVE team is more versatile than the C-GET team, which only allows downloading images. C-MOVE can download images not only for its own, but also for any other. The command indicates the AETitle station to which you want to upload images. AETitle is the name of the client, usually in capital letters (for example, CLIENT_SCU). It is installed when you start dicom-listener (server).
That is, the client initiating the C-MOVE command to the PACS server must run a mini-PACS in itself that allows only the C-STORE command to be received. And the PACS server, in turn, with the C-MOVE team, should establish a new connection with the client, pick up images from the storage and, for each of the bottom, execute the client version of the C-STORE command back to the client. By the way, only the C-MOVE command allows you to transfer both compressed images (JPEG) and uncompressed due to the establishment of a new connection.
The C-GET team, however, is able to load images without establishing a new connection and, therefore, without having to raise the server on the client side. In this case, the PACS also performs the client version of the C-STORE command, only through the connection established by the C-GET command.
C-FIND is a command that allows you to search for images at different levels. That is, in fact, there are four types of C-FIND command: C-FIND at the PATIENT level, at the STUDY level, at the SERIES level and at the IMAGE level.
void HandlerFind::findSCPCallback ( /* in */ void* callbackData, OFBool cancelled, T_DIMSE_C_FindRQ* request, DcmDataset* requestIdentifiers, int responseCount, /* out */ T_DIMSE_C_FindRSP *response, DcmDataset** responseDataSet, DcmDataset** statusDetail) { // if (cancelled) { strcpy(response->AffectedSOPClassUID, request->AffectedSOPClassUID); response->MessageIDBeingRespondedTo = request->MessageID; response->DimseStatus = STATUS_FIND_Cancel_MatchingTerminatedDueToCancelRequest; response->DataSetType = DIMSE_DATASET_NULL; return; } if (responseCount == 1) { // // . // requestIdentifiers // } /* responseDataSet */ if (/* */) { strcpy(response->AffectedSOPClassUID, request->AffectedSOPClassUID); response->MessageIDBeingRespondedTo = request->MessageID; response->DimseStatus = STATUS_Success; response->DataSetType = DIMSE_DATASET_NULL; return; } } OFCondition HandlerFind::find() { OFCondition cond = EC_Normal; T_DIMSE_C_FindRQ *req = &m_msg->msg.CFindRQ; FindCallbackData cdata; cond = DIMSE_findProvider(m_assoc, m_presID, req, findSCPCallback, &cdata, DIMSE_BLOCKING, 0); if (cond.bad()) Log::loggerDicom.error("C-FIND provider failed. Text: %s", cond.text()); return cond; } That is, in the callback, you need to fill in the response objects — the response parameters and responseDataSet — the patient information / stage / series / image you want to find. The DIMSE_findProvider () function from DCMTK will take care of sending them back to the client.
The C-FIND command is dangerous in that the client can specify a very general search criteria and the client will have to give a large amount of information. For example, you can request all stages for the last year. If you try to first load all the data on the server, the server is likely to hang. Therefore, it is impossible to make large requests, you need to load data as the callbacks are triggered. To do this, you need to implement a query to the database as an iterator and, as the callbacks are triggered, call next () and thus take the next object. In addition, the search can be canceled only when a callback arrives, so if the search on PACS hangs for a while on a sample of the database, and the client causes the request to be canceled, then no response will occur on the client. This is relevant for searching at the level of patients and stages. This is irrelevant for searching at the series level, since we have not encountered any stages containing more than 15 series. Similarly, for searching at the level of images - a series with more than 1000 images, we have not seen in practice.
Summarize
So, we reviewed the main functions of the PACS system and its role in the overall structure of the diagnostic center. Practical aspects and various aspects of the implementation of medical industrial PACS systems are also covered. However, as a rule, PACS systems are not limited to this functionality. There is also a WADO (Web Access to DICOM Objects) service and a work task management service (Modality worklist), also included in the functions of PACS systems. I hope for someone the article will be useful and save a lot of time.
Links
1. List of all DICOM tags (http://medical.nema.org/Dicom/2011/11_06pu.pdf, p. 8).
2. The official page of the DICOM protocol - medical.nema.org/standard.html
3. About PACS systems in Russian - ru.wikipedia.org/wiki/PACS
4. About DICOM in Russian - en.wikipedia.org/wiki/DICOM
Source: https://habr.com/ru/post/193134/
All Articles