Unicode and .NET
From the translator. On Habré, articles have been repeatedly published both on Unicode and on lines in .NET. However, there was no article about Unicode in relation to .NET yet, so I decided to translate the article by the generally recognized .NET guru John Skit. It closes the cycle I had promised from three articles by J. Skeet translations devoted to strings in .NET. As always, I will be happy with comments and corrections.

The topic of this article is quite extensive, and do not expect from it a detailed and deep analysis of all the nuances. If you think that you are well-versed in Unicode, encodings, etc., this article may be almost or even completely useless for you. However, quite a few people do not understand the difference between binary and textual data ( binary and text ), or what character encoding is. This article was written for such people. Despite, in general, a superficial description, it touches upon some difficult points, however, this is done more so that the reader has an idea of their existence, rather than to give detailed explanations and guidelines for action.
The links below are at least as useful as this article, and maybe more useful. I myself used them when writing this article. There are a lot of useful and high-quality materials in them, and if in this article you notice any inaccuracies, then these resources should be more accurate.
Most modern programming languages (like some old ones) draw a clear line between binary (binary) content and symbolic (or textual) content. Although this difference is understood at the instinctive level, I still make the definition.
')
Binary (binary) data is a sequence of octets (an octet consists of 8 bits) without any natural meaning or interpretation attached to it. And even if there is an external “interpretation” of one or another set of octets as, say, an executable file or graphic image, the data itself is just a set of octets. Further, instead of the term “octet,” I will use “byte,” although, to be precise, not every byte is an octet. For example, there were computer architectures with 9-bit bytes. However, in this context, such details are not very necessary, so that further by the term "byte" I will mean exactly 8-bit byte.
Character (text) data is a sequence of characters.
The Unicode Glossary defines a character as:
This definition may or may not be useful for you, but in most cases you can use an intuitive understanding of a symbol, as something like some element denoting a large letter "A" or the number "1", etc. However, there are other characters that are far from being so intuitively obvious. These include modifying characters, which are intended to change other characters (for example, acute stress, it is acute ), control characters (for example, a newline character), formatting characters (invisible, but affect other characters). Text data - this is a set of characters, and this is important.
Unfortunately, in the recent past, the distinction between binary and textual data was very vague, fuzzy. For example, for programmers in C language, the terms "byte" and "character" in most cases meant the same thing. In modern platforms such as .NET and Java, where the distinction between characters and bytes is clear and fixed in the I / O libraries, old habits can have negative consequences (for example, people can try to copy the contents of a binary file by reading character strings from it will distort the contents of this file).
The Unicode Consortium is trying to standardize the processing of character data, including conversions from binary to text and vice versa (what is called decoding and encoding, respectively). In addition, there is a set of ISO standards (10646 in various versions) that do the same; Unicode and ISO 10646 can be considered one and the same, since they are almost completely compatible. (In theory, ISO 10646 defines a wider potential character set, but this is unlikely to ever become a problem.) Most modern programming languages and platforms, including .NET and Java, use Unicode to represent characters.
Unicode defines, among other things:
The difference between the form of character encoding and the character encoding scheme is quite subtle, however, it takes into account the byte order ( endianness ). (For example, in the UCS-2 encoding, the sequence of code units 0xC2 0xA9 can be serialized as 0xC2 0xA9 or as 0xA9 0xC2 - this is what the character encoding scheme decides.)
The repertoire of abstract Unicode characters may contain, in theory, up to 1,114,112 characters, although many are already reserved as unsuitable, and the rest will most likely never be assigned. Each character is encoded with a nonnegative integer from 0 to 1114111 (0x10FFFF). For example, the capital A is encoded with a decimal number 65. A few years ago it was believed that all the characters "fit" in the range between 0 and 2 16 -1, which meant that any character can be represented using two bytes. Unfortunately, over time, it took more characters, which led to the emergence of the so-called. “Surrogate pair”. Everything became much more difficult with them (at least for me), and therefore most of this article will not touch them - I will briefly describe them in the “Difficult moments” section .
Do not worry if all of the above looks weird. You should be aware of the differences described above, but in fact they do not often come to the fore. Most of your tasks will most likely “spin” around converting a certain set of bytes into some text and vice versa. In such situations, you will work with the System.Char structure (known in C # as the
The
The
The
The .NET class library contains various encoding schemes. Below is a description of these schemes and how to use them.
ASCII is one of the most common and at the same time one of the most misunderstood character encodings. Contrary to popular misconception, ASCII is a 7-bit encoding, not an 8-bit one: there are no characters with codes (code points) greater than 127. If someone declares that he uses, for example, the code "ASCII 154", then we can assume that this someone does not understand what he does and says. However, as an excuse, he may declare something about "extended ASCII" ( extended ASCII ). So - there is no scheme called "extended ASCII". There are many 8-bit encoding schemes that are a superset for ASCII, and the term “extended ASCII” is sometimes used to designate them, which is not entirely correct. The code point of each ASCII character coincides with the code point of a similar character in Unicode: in other words, the lower case ASCII character of the Latin letter “x” and the Unicode character of the same character are denoted by the same number - 120 (0x78 in hexadecimal). The .NET class ASCIIEncoding (an instance of which can be easily obtained via the Encoding.ASCII property), in my opinion, is a bit strange, since it seems that it performs encoding by simply discarding all bits after the base 7. This means that, for example, a Unicode character 0xB5 (the sign “micro” - µ ), after encoding into ASCII and decoding back into Unicode, will turn into the character 0x35 (digit “5”). (Instead, I would prefer that some special character be output, indicating that the original character was missing in ASCII and was lost.)
UTF-8 is a good and common way to represent Unicode characters. Each character is encoded by a sequence of bytes in the number from one to four inclusive. (All characters with code points less than 65536 are encoded with one, two or three bytes; I did not check how .NET encodes surrogate pairs: with two sequences of 1-3 bytes or one sequence of 4 bytes.) UTF-8 can display all Unicode characters are compatible with ASCII so that any sequence of ASCII characters will be converted into UTF-8 without changes (i.e. a sequence of bytes representing the characters in ASCII and a sequence of bytes representing the same characters in UTF-8 are the same). Moreover, the first byte encoding a character is enough to determine how many more bytes encode the same character, if any. UTF-8 itself does not require a Byte order mark (BOM), although it can be used as a way of indicating that the text is in UTF-8 format. UTF-8 text containing a BOM always starts with a sequence of three bytes 0xEF 0xBB 0xBF. To encode a string in UTF-8 in .NET, simply use the Encoding.UTF8 property. In fact, in most cases you don’t even have to do this — many classes (including StreamWriter ) use UTF-8 by default, when no other encoding is explicitly specified. (Don't be mistaken, Encoding.Default does not apply here, it is completely different.) Nevertheless, I advise you to always explicitly specify the encoding in your code, if only for readability and understanding.
UTF-16 is just the encoding in which .NET works with characters. Each character is represented by a sequence of two bytes; accordingly, the surrogate pair takes 4 bytes. The ability to use surrogate pairs is the only difference between UTF-16 and UCS-2: UCS-2 (also known simply as Unicode) does not allow surrogate pairs and can represent characters in the range 0-65535 (0-0xFFFF). UTF-16 can have a different byte order (Endianness): it can be from high to low ( big-endian ), from low to high ( little-endian ), or be machine-dependent with an optional BOM (0xFF 0xFE for little ). endian, 0xFE 0xFF for big-endian). In .NET itself, as far as I know, the problem of surrogate pairs was “hammered”, and each character in a surrogate pair is considered as an independent symbol, which results in a kind of “leveling” between UCS-2 and UTF-16. (The exact difference between UCS-2 and UTF-16 is a much deeper understanding of surrogate pairs, and I am not competent in this aspect.) UTF-16 in big-endian representation can be obtained using the Encoding.BigEndianUnicode property, and little endian - using Encoding.Unicode . Both properties return an instance of the System.Text.UnicodeEncoding class, which can also be created using various constructor overloads: here you can specify whether or not to use the BOM and what byte order to set. I suppose (although I did not test this) that when decoding binary content, the BOM present in the content overrides the byte order settings set in the encoder, so the programmer should not make any extra gestures if he decodes any content, even if the byte order and / or the presence of BOM in this content are unknown to him.
UTF-7, judging by my experience, is rarely used, but it allows you to transcode Unicode (probably only the first 65535 characters) into ASCII characters (not bytes!). This can be useful when working with e-mail in situations where mail gateways support only ASCII characters, or even just a subset of ASCII (for example, EBCDIC encoding). My description looks slurred because I have never climbed into the details of UTF-7 and am not going to do that in the future. If you need to use UTF-7, then you probably already know enough, and if you don’t have the absolute need to use UTF-7, then I advise you not to. An instance of a class for encoding in UTF-7 can be obtained using the Encoding.UTF7 property.
Windows Code Pages are typically single- or double-byte character sets, encoding up to 256 or 65,536 characters, respectively. Each code page has its own number, and the encoder for the code page with a known number can be obtained using the static method Encoding.GetEncoding (Int32) . In most cases, code pages are useful for working with old data, which is often stored in the default code page . The encoder for the default code page can be obtained using the Encoding.Default property. Again, avoid using code pages whenever possible. For more information, contact MSDN.
As in ASCII, each character in the Latin-1 code page has the same code as the code for the same character in Unicode. I did not bother to find out whether Latin-1 has a “hole” of unrecorded characters with codes from 128 to 159, or whether Latin-1 contains the same control characters as Unicode. (I was beginning to lean towards the idea of a “hole”, but Wikipedia does not agree with me, so I am still in thought. (The author’s thoughts are incomprehensible, since the Wikipedia article clearly shows the presence of a space ; probably, at the time of writing Skit the original article, Wikipedia articles were different. - approx. transl. )) Latin-1 has a code page number of 28591, so use the
Binary streams are by nature, they read and write bytes. Everything that accepts a string should convert it to bytes in a certain way, and this conversion can be either successful for you or not. The equivalent threads for reading and writing text are the abstract classes System.IO.TextReader and System.IO.TextWriter, respectively. If you already have a stream ready, you can use the System.IO.StreamReader classes (which directly inherit
Note that this code uses
Well, those were just the basics of Unicode. There are many other nuances, some of which I have already hinted at, and I believe that people should be aware of them, even if they believe that this will never happen to them. I do not propose any general methodologies or guidelines — I’m just trying to raise your awareness of potential problems. Below is a list, and it is in no way exhaustive. It is important that you understand that most of the problems and difficulties described are in no way the fault or error of the Unicode Consortium; just as in the case of date, time, and any of the problems of internationalization, this is the “merit” of mankind, which itself has created many fundamentally complex problems over time.
These problems are described in my article devoted to .NET strings ( original , translation ).
Now that Unicode contains more than 65,536 characters, it cannot contain them all in 2 bytes. This means that a single instance of the
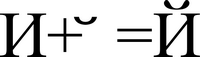
Not all characters from Unicode are displayed as an icon / picture as a result of output to the screen or paper. An underlined (accented) character can be represented as two other characters: a regular, unstretched character and the next underscore character, which is called a modifying (or combinable) character ( Combining character ). Some GUIs support modifying symbols, some are not, and the performance of your application will depend on what assumption you make.
Partly due to such things as modifying symbols, there may be several ways of representing what is in one sense one symbol. The letter "á" with stress, for example, can be represented by one character "a" without the stress and the modifying stress symbol following it, or it can be represented only by one character representing the finished letter "a" with stress. Sequences of symbols can be normalized in such a way as to use modifying symbols wherever possible, or vice versa - not to use them wherever they can be replaced with a single symbol. Should your application treat two lines containing the letter “á” with the stress, but in one represented by two characters, and in the second one as equal, or as different? What about sorting? Do third-party components and libraries that you use normalize strings, and in general, do such nuances take into account? These questions answer you.
This section ( in the original is a separate article - note of the translator ) describes what to do in very specific situations. Namely, you have some character data (simply text) in one place (usually in a database), which go through different steps / layers / components and then are displayed to the user (usually on a web page). And unfortunately for you, some characters are displayed incorrectly ( kryakozyabry ). Based on the many steps involved in your text data, a problem can arise in many places. This page will help you easily and reliably find out what and where is “broken”.
And simply speaking - read the main text of the article. You can also pay attention to the links that are given at the beginning of the article. The fact is that without basic knowledge you will be tight.
If you can understand where, perhaps, everything breaks, then this section / stage will be much easier to isolate. However, keep in mind that the problem may not be in the process of extracting and transforming text from the repository, but in the fact that already “spoiled” text was entered into the repository earlier. (I had problems with similar problems in the past, when, for example, one old application distorted the text when writing and reading it to / from the database. The joke was that the conversion errors overlapped and mutually compensated, so that the correct text was obtained. In general, the application worked fine, but it was enough to touch it - and everything fell apart.) Actions that can “spoil” the text should include selection from the database, reading from the file, transfer via a web connection and displaying text on the screen.
The first rule is: do not trust anything that logs character data as a sequence of glyphs (i.e. standard character icons). Instead, you must log the data as a set of byte character codes. For example, if I have a string containing the word "hello", then I will display it as "0068 0065 006C 006C 006F". (Using hexadecimal codes will allow you to easily check a symbol by code tables.) To do this, you need to go through all the characters in a line and output its code for each character, which is done in the method below, which displays the result in the console:
Your own logging method will be different depending on your environment, but its basis should be exactly the same as I quoted. I cited a more advanced way of debugging and logging character data in my article on strings.
The essence of my idea is to get rid of all sorts of problems with encodings, fonts, etc. This technique can be useful when working with specific Unicode characters. If you cannot correctly log hexadecimal codes of even simple ASCII text, you have big problems.
The next step is to make sure you have a test case that you can use. It is desirable to find a small set of source data on which your application is guaranteed to “fail”, make sure that you know exactly what the correct result should be, and pledge the resulting result in all problem areas.
After the problem string is logged, you need to make sure whether it is what it should be or not. This is where the Unicode code charts webpage helps you.. You can choose as a set of characters, which are sure, and search for characters in alphabetical order. Make sure every character in the string has the correct value. As soon as you find the place in your application where the stream of character data is damaged, examine this place, find out the cause of the error and correct it. Having corrected all errors, make sure that the application is working correctly.
, , « ». , . , -; , , , .
Introduction
The topic of this article is quite extensive, and do not expect from it a detailed and deep analysis of all the nuances. If you think that you are well-versed in Unicode, encodings, etc., this article may be almost or even completely useless for you. However, quite a few people do not understand the difference between binary and textual data ( binary and text ), or what character encoding is. This article was written for such people. Despite, in general, a superficial description, it touches upon some difficult points, however, this is done more so that the reader has an idea of their existence, rather than to give detailed explanations and guidelines for action.
Resources
The links below are at least as useful as this article, and maybe more useful. I myself used them when writing this article. There are a lot of useful and high-quality materials in them, and if in this article you notice any inaccuracies, then these resources should be more accurate.
- The official website of the Unicode Consortium . The most complete and accurate source of information on Unicode, which contains answers to all your questions (although you should carefully search for useful information on the site). Some of the links below lead to this site.
- Unicode Glossary . A dictionary with brief interpretations of many terms used in the discussion of character encoding, etc.
- Unicode FAQ Answers to hundreds of common questions, divided into groups.
- Unicode / Unix / Linux UTF-8 FAQ . Do not neglect this link, judging by its name - even if you are not on friendly terms with Unix / Linux, most of the information is very relevant to .NET.
- Unicode character encoding model . Provides more information about the exact interpretation of terms like "character encoding scheme", etc.
- Joel Spolsky. Mandatory minimum that every software developer should know about Unicode and character sets (No excuses are allowed) . An article that is somewhat similar to this one, but without an accent on .NET. ( translation into Russian , transfer to Habré part 1 , part 2 )
- About the kindness of Unicode . Another introductory article worth reading.
Binary and textual data are two different things.
Most modern programming languages (like some old ones) draw a clear line between binary (binary) content and symbolic (or textual) content. Although this difference is understood at the instinctive level, I still make the definition.
')
Binary (binary) data is a sequence of octets (an octet consists of 8 bits) without any natural meaning or interpretation attached to it. And even if there is an external “interpretation” of one or another set of octets as, say, an executable file or graphic image, the data itself is just a set of octets. Further, instead of the term “octet,” I will use “byte,” although, to be precise, not every byte is an octet. For example, there were computer architectures with 9-bit bytes. However, in this context, such details are not very necessary, so that further by the term "byte" I will mean exactly 8-bit byte.
Character (text) data is a sequence of characters.
The Unicode Glossary defines a character as:
- The smallest component of the written language containing semantic meaning; indicates an abstract meaning and / or form, as opposed to special forms (such as glyphs ); in code tables, some forms of visual presentation of symbols are of great importance for the reader to understand them.
- A synonym for an abstract symbol (see Definition D3 in Section 3.3, Characters and Coded Representations).
- The basic coding unit in a Unicode encoding system.
- English name for ideographic writing elements of Chinese origin.
This definition may or may not be useful for you, but in most cases you can use an intuitive understanding of a symbol, as something like some element denoting a large letter "A" or the number "1", etc. However, there are other characters that are far from being so intuitively obvious. These include modifying characters, which are intended to change other characters (for example, acute stress, it is acute ), control characters (for example, a newline character), formatting characters (invisible, but affect other characters). Text data - this is a set of characters, and this is important.
Unfortunately, in the recent past, the distinction between binary and textual data was very vague, fuzzy. For example, for programmers in C language, the terms "byte" and "character" in most cases meant the same thing. In modern platforms such as .NET and Java, where the distinction between characters and bytes is clear and fixed in the I / O libraries, old habits can have negative consequences (for example, people can try to copy the contents of a binary file by reading character strings from it will distort the contents of this file).
So what's Unicode for?
The Unicode Consortium is trying to standardize the processing of character data, including conversions from binary to text and vice versa (what is called decoding and encoding, respectively). In addition, there is a set of ISO standards (10646 in various versions) that do the same; Unicode and ISO 10646 can be considered one and the same, since they are almost completely compatible. (In theory, ISO 10646 defines a wider potential character set, but this is unlikely to ever become a problem.) Most modern programming languages and platforms, including .NET and Java, use Unicode to represent characters.
Unicode defines, among other things:
- abstract character repertoire ( abstract character repertoire ) - a set of all characters that are supported by Unicode;
- set of character codes ( coded character set ) - contains a binding of each character from the repertoire to a nonnegative integer number, called a code point;
- some forms of character encoding ( character encoding forms ) - define correspondences between code points and sequences of "code units" (simply speaking, correspondences between a code point expressed as a single integer of any length and a group of bytes encoding this number);
- some character encoding schemes ( character encoding schemes ) - define correspondences between sets of code units and serialized byte sequences.
The difference between the form of character encoding and the character encoding scheme is quite subtle, however, it takes into account the byte order ( endianness ). (For example, in the UCS-2 encoding, the sequence of code units 0xC2 0xA9 can be serialized as 0xC2 0xA9 or as 0xA9 0xC2 - this is what the character encoding scheme decides.)
The repertoire of abstract Unicode characters may contain, in theory, up to 1,114,112 characters, although many are already reserved as unsuitable, and the rest will most likely never be assigned. Each character is encoded with a nonnegative integer from 0 to 1114111 (0x10FFFF). For example, the capital A is encoded with a decimal number 65. A few years ago it was believed that all the characters "fit" in the range between 0 and 2 16 -1, which meant that any character can be represented using two bytes. Unfortunately, over time, it took more characters, which led to the emergence of the so-called. “Surrogate pair”. Everything became much more difficult with them (at least for me), and therefore most of this article will not touch them - I will briefly describe them in the “Difficult moments” section .
So what provides .NET?
Do not worry if all of the above looks weird. You should be aware of the differences described above, but in fact they do not often come to the fore. Most of your tasks will most likely “spin” around converting a certain set of bytes into some text and vice versa. In such situations, you will work with the System.Char structure (known in C # as the
char alias), the System.String class ( string in C #), and the System.Text.Encoding class.The
Char structure is the most basic character type in C #, one instance of Char represents one Unicode character and takes 2 bytes of memory, which means it can take any value from the range 0-65535. Keep in mind that not all numbers in this range are valid Unicode characters.The
String class is basically a sequence of characters. It is immutable, which means that after creating an instance of a string, you can no longer change it (an instance) - the various methods of the String class, although they look as if they change its contents, actually create and return a new string.The
System.Text.Encoding class provides a means of converting an array of bytes into a character array or string, and vice versa. This class is abstract; its various implementations are both represented in .NET and can be written by the users themselves. (The task of creating System.Text.Encoding implementation occurs quite rarely - in most cases, the classes that come with .NET are enough for you.) Encoding allows you to separately specify the encoders and decoders that handle the state between calls. This is necessary for multibyte character encoding schemes, when it is impossible to correctly decode all the bytes received from the stream into characters. For example, if a UTF-8 decoder receives two bytes of 0x41 0xC2 as input, it can return only the first character (the capital letter "A"), however, it needs the third byte to determine the second character.Embedded encoding schemes
The .NET class library contains various encoding schemes. Below is a description of these schemes and how to use them.
ASCII
ASCII is one of the most common and at the same time one of the most misunderstood character encodings. Contrary to popular misconception, ASCII is a 7-bit encoding, not an 8-bit one: there are no characters with codes (code points) greater than 127. If someone declares that he uses, for example, the code "ASCII 154", then we can assume that this someone does not understand what he does and says. However, as an excuse, he may declare something about "extended ASCII" ( extended ASCII ). So - there is no scheme called "extended ASCII". There are many 8-bit encoding schemes that are a superset for ASCII, and the term “extended ASCII” is sometimes used to designate them, which is not entirely correct. The code point of each ASCII character coincides with the code point of a similar character in Unicode: in other words, the lower case ASCII character of the Latin letter “x” and the Unicode character of the same character are denoted by the same number - 120 (0x78 in hexadecimal). The .NET class ASCIIEncoding (an instance of which can be easily obtained via the Encoding.ASCII property), in my opinion, is a bit strange, since it seems that it performs encoding by simply discarding all bits after the base 7. This means that, for example, a Unicode character 0xB5 (the sign “micro” - µ ), after encoding into ASCII and decoding back into Unicode, will turn into the character 0x35 (digit “5”). (Instead, I would prefer that some special character be output, indicating that the original character was missing in ASCII and was lost.)
UTF-8
UTF-8 is a good and common way to represent Unicode characters. Each character is encoded by a sequence of bytes in the number from one to four inclusive. (All characters with code points less than 65536 are encoded with one, two or three bytes; I did not check how .NET encodes surrogate pairs: with two sequences of 1-3 bytes or one sequence of 4 bytes.) UTF-8 can display all Unicode characters are compatible with ASCII so that any sequence of ASCII characters will be converted into UTF-8 without changes (i.e. a sequence of bytes representing the characters in ASCII and a sequence of bytes representing the same characters in UTF-8 are the same). Moreover, the first byte encoding a character is enough to determine how many more bytes encode the same character, if any. UTF-8 itself does not require a Byte order mark (BOM), although it can be used as a way of indicating that the text is in UTF-8 format. UTF-8 text containing a BOM always starts with a sequence of three bytes 0xEF 0xBB 0xBF. To encode a string in UTF-8 in .NET, simply use the Encoding.UTF8 property. In fact, in most cases you don’t even have to do this — many classes (including StreamWriter ) use UTF-8 by default, when no other encoding is explicitly specified. (Don't be mistaken, Encoding.Default does not apply here, it is completely different.) Nevertheless, I advise you to always explicitly specify the encoding in your code, if only for readability and understanding.
UTF-16 and UCS-2
UTF-16 is just the encoding in which .NET works with characters. Each character is represented by a sequence of two bytes; accordingly, the surrogate pair takes 4 bytes. The ability to use surrogate pairs is the only difference between UTF-16 and UCS-2: UCS-2 (also known simply as Unicode) does not allow surrogate pairs and can represent characters in the range 0-65535 (0-0xFFFF). UTF-16 can have a different byte order (Endianness): it can be from high to low ( big-endian ), from low to high ( little-endian ), or be machine-dependent with an optional BOM (0xFF 0xFE for little ). endian, 0xFE 0xFF for big-endian). In .NET itself, as far as I know, the problem of surrogate pairs was “hammered”, and each character in a surrogate pair is considered as an independent symbol, which results in a kind of “leveling” between UCS-2 and UTF-16. (The exact difference between UCS-2 and UTF-16 is a much deeper understanding of surrogate pairs, and I am not competent in this aspect.) UTF-16 in big-endian representation can be obtained using the Encoding.BigEndianUnicode property, and little endian - using Encoding.Unicode . Both properties return an instance of the System.Text.UnicodeEncoding class, which can also be created using various constructor overloads: here you can specify whether or not to use the BOM and what byte order to set. I suppose (although I did not test this) that when decoding binary content, the BOM present in the content overrides the byte order settings set in the encoder, so the programmer should not make any extra gestures if he decodes any content, even if the byte order and / or the presence of BOM in this content are unknown to him.
UTF-7
UTF-7, judging by my experience, is rarely used, but it allows you to transcode Unicode (probably only the first 65535 characters) into ASCII characters (not bytes!). This can be useful when working with e-mail in situations where mail gateways support only ASCII characters, or even just a subset of ASCII (for example, EBCDIC encoding). My description looks slurred because I have never climbed into the details of UTF-7 and am not going to do that in the future. If you need to use UTF-7, then you probably already know enough, and if you don’t have the absolute need to use UTF-7, then I advise you not to. An instance of a class for encoding in UTF-7 can be obtained using the Encoding.UTF7 property.
Windows / ANSI code pages
Windows Code Pages are typically single- or double-byte character sets, encoding up to 256 or 65,536 characters, respectively. Each code page has its own number, and the encoder for the code page with a known number can be obtained using the static method Encoding.GetEncoding (Int32) . In most cases, code pages are useful for working with old data, which is often stored in the default code page . The encoder for the default code page can be obtained using the Encoding.Default property. Again, avoid using code pages whenever possible. For more information, contact MSDN.
ISO-8859-1 (Latin-1)
As in ASCII, each character in the Latin-1 code page has the same code as the code for the same character in Unicode. I did not bother to find out whether Latin-1 has a “hole” of unrecorded characters with codes from 128 to 159, or whether Latin-1 contains the same control characters as Unicode. (I was beginning to lean towards the idea of a “hole”, but Wikipedia does not agree with me, so I am still in thought. (The author’s thoughts are incomprehensible, since the Wikipedia article clearly shows the presence of a space ; probably, at the time of writing Skit the original article, Wikipedia articles were different. - approx. transl. )) Latin-1 has a code page number of 28591, so use the
Encoding.GetEncoding(28591) method to get an encoder.Streams, readers and writers
Binary streams are by nature, they read and write bytes. Everything that accepts a string should convert it to bytes in a certain way, and this conversion can be either successful for you or not. The equivalent threads for reading and writing text are the abstract classes System.IO.TextReader and System.IO.TextWriter, respectively. If you already have a stream ready, you can use the System.IO.StreamReader classes (which directly inherit
TextReader ) for reading and System.IO.StreamWriter (which directly inherits TextWriter ) for writing, passing the stream to the constructor of these classes and encoding as you need. Unless you explicitly specify the encoding, UTF-8 will be applied by default. Below is a sample code that converts a file from UTF-8 to UCS-2: using System; using System.IO; using System.Text; public class FileConverter { const int BufferSize = 8096; public static void Main(string[] args) { if (args.Length != 2) { Console.WriteLine ("Usage: FileConverter <input file> <output file>"); return; } String inputFile = args[0]; String outputFile = args[1]; // TextReader using (TextReader input = new StreamReader (new FileStream (inputFile, FileMode.Open), Encoding.UTF8)) { // TextWriter using (TextWriter output = new StreamWriter (new FileStream (outputFile, FileMode.Create), Encoding.Unicode)) { // char[] buffer = new char[BufferSize]; int len; // while ( (len = input.Read (buffer, 0, BufferSize)) > 0) { output.Write (buffer, 0, len); } } } } } Note that this code uses
TextReader and TextWriter that accept streams. There are other constructor overloads that take file paths as input, so you don't need to manually open the FileStream ; I did this only as an example. There are other constructor overloads that also take the size of the buffer and the need to determine the BOM, in general, look at the documentation. And finally, if you are using .NET 2.0 and higher, it doesn’t hurt to take a look at the static class System.IO.File , which also contains many convenient methods that allow you to work with encodings.Difficult moments
Well, those were just the basics of Unicode. There are many other nuances, some of which I have already hinted at, and I believe that people should be aware of them, even if they believe that this will never happen to them. I do not propose any general methodologies or guidelines — I’m just trying to raise your awareness of potential problems. Below is a list, and it is in no way exhaustive. It is important that you understand that most of the problems and difficulties described are in no way the fault or error of the Unicode Consortium; just as in the case of date, time, and any of the problems of internationalization, this is the “merit” of mankind, which itself has created many fundamentally complex problems over time.
Culture-dependent search, sorting and so on.
These problems are described in my article devoted to .NET strings ( original , translation ).
Surrogate pairs
Now that Unicode contains more than 65,536 characters, it cannot contain them all in 2 bytes. This means that a single instance of the
Char structure cannot accept all possible characters. UTF-16 (and .NET) solves this problem by using surrogate pairs - these are two 16-bit values, where each value lies in the range from 0xD800 to 0xDFFF. In other words, two “character types” form one “real” character. (UCS-4 and UTF-32 completely solve this problem by the fact that they have a wider range of values available: each character takes 4 bytes, and this is enough for everyone.) Surrogate pairs are a headache, because it means that the string , which consists of 10 characters, in fact, can contain from 10 to 5 inclusive of "real" Unicode characters. Fortunately, most applications do not use scientific or mathematical notations and Han characters, and therefore you don’t need to worry about it.Modifying characters
Not all characters from Unicode are displayed as an icon / picture as a result of output to the screen or paper. An underlined (accented) character can be represented as two other characters: a regular, unstretched character and the next underscore character, which is called a modifying (or combinable) character ( Combining character ). Some GUIs support modifying symbols, some are not, and the performance of your application will depend on what assumption you make.
Normalization
Partly due to such things as modifying symbols, there may be several ways of representing what is in one sense one symbol. The letter "á" with stress, for example, can be represented by one character "a" without the stress and the modifying stress symbol following it, or it can be represented only by one character representing the finished letter "a" with stress. Sequences of symbols can be normalized in such a way as to use modifying symbols wherever possible, or vice versa - not to use them wherever they can be replaced with a single symbol. Should your application treat two lines containing the letter “á” with the stress, but in one represented by two characters, and in the second one as equal, or as different? What about sorting? Do third-party components and libraries that you use normalize strings, and in general, do such nuances take into account? These questions answer you.
Debugging Unicode Issues
This section ( in the original is a separate article - note of the translator ) describes what to do in very specific situations. Namely, you have some character data (simply text) in one place (usually in a database), which go through different steps / layers / components and then are displayed to the user (usually on a web page). And unfortunately for you, some characters are displayed incorrectly ( kryakozyabry ). Based on the many steps involved in your text data, a problem can arise in many places. This page will help you easily and reliably find out what and where is “broken”.
Step 1: Understand the Basics of Unicode
And simply speaking - read the main text of the article. You can also pay attention to the links that are given at the beginning of the article. The fact is that without basic knowledge you will be tight.
Step 2: Try to determine which conversions could occur.
If you can understand where, perhaps, everything breaks, then this section / stage will be much easier to isolate. However, keep in mind that the problem may not be in the process of extracting and transforming text from the repository, but in the fact that already “spoiled” text was entered into the repository earlier. (I had problems with similar problems in the past, when, for example, one old application distorted the text when writing and reading it to / from the database. The joke was that the conversion errors overlapped and mutually compensated, so that the correct text was obtained. In general, the application worked fine, but it was enough to touch it - and everything fell apart.) Actions that can “spoil” the text should include selection from the database, reading from the file, transfer via a web connection and displaying text on the screen.
Step 3: Check the data at each stage.
The first rule is: do not trust anything that logs character data as a sequence of glyphs (i.e. standard character icons). Instead, you must log the data as a set of byte character codes. For example, if I have a string containing the word "hello", then I will display it as "0068 0065 006C 006C 006F". (Using hexadecimal codes will allow you to easily check a symbol by code tables.) To do this, you need to go through all the characters in a line and output its code for each character, which is done in the method below, which displays the result in the console:
static void DumpString (string value) { foreach (char c in value) { Console.Write("{0:x4} ", (int)c); } Console.WriteLine(); } Your own logging method will be different depending on your environment, but its basis should be exactly the same as I quoted. I cited a more advanced way of debugging and logging character data in my article on strings.
The essence of my idea is to get rid of all sorts of problems with encodings, fonts, etc. This technique can be useful when working with specific Unicode characters. If you cannot correctly log hexadecimal codes of even simple ASCII text, you have big problems.
The next step is to make sure you have a test case that you can use. It is desirable to find a small set of source data on which your application is guaranteed to “fail”, make sure that you know exactly what the correct result should be, and pledge the resulting result in all problem areas.
After the problem string is logged, you need to make sure whether it is what it should be or not. This is where the Unicode code charts webpage helps you.. You can choose as a set of characters, which are sure, and search for characters in alphabetical order. Make sure every character in the string has the correct value. As soon as you find the place in your application where the stream of character data is damaged, examine this place, find out the cause of the error and correct it. Having corrected all errors, make sure that the application is working correctly.
Conclusion
, , « ». , . , -; , , , .
- Jon Skeet. Unicode and .NET
- Jon Skeet. Debugging Unicode Problems
Source: https://habr.com/ru/post/193048/
All Articles